자습서: 3부 - 프롬프트 흐름 SDK를 사용하여 사용자 지정 채팅 애플리케이션 평가 및 배포
이 자습서에서는 프롬프트 흐름 SDK(및 기타 라이브러리)를 사용하여 자습서 시리즈의 2부에서 구축한 채팅 앱을 평가하고 배포합니다. 이 3부에서는 다음을 수행하는 방법을 알아봅니다.
- 채팅 앱 응답의 품질 평가
- Azure에 채팅 앱 배포
- 배포 확인
이 자습서는 3부로 구성된 자습서 중 제3부입니다.
필수 조건
자습서 시리즈의 2부를 완료하여 채팅 애플리케이션을 빌드합니다.
Azure 구독에 역할 할당을 추가하려면 필요한 권한이 있어야 합니다. 역할 할당을 통한 권한 부여는 특정 Azure 리소스의 소유자에게만 허용됩니다. 자습서의 뒷부분에서 엔드포인트 액세스에 대한 도움말을 Azure 구독 소유자(IT 관리자)에게 요청해야 할 수 있습니다.
채팅 앱 응답의 품질 평가
이제 채팅 기록을 사용하는 것을 포함하여 채팅 앱이 쿼리에 잘 응답한다는 것을 알게 되었으므로 이제 몇 가지 다른 메트릭과 더 많은 데이터에서 채팅 앱이 어떻게 작동하는지 평가할 차례입니다.
프롬프트 흐름 평가기를 평가 데이터 세트 및 get_chat_response() 대상 함수와 함께 사용한 다음 평가 결과를 평가합니다.
평가를 실행하면 시스템 프롬프트를 개선하고 채팅 앱 응답이 어떻게 변경되고 개선되는지 관찰하는 등 논리를 개선할 수 있습니다.
평가 모델 설정
사용하려는 평가 모델을 선택합니다. 앱을 빌드하는 데 사용한 채팅 모델과 같을 수 있습니다. 평가에 다른 모델을 사용하려면 배포하거나 이미 존재하는 경우 지정해야 합니다. 예를 들어 채팅 완성에 gpt-35-turbo를 사용할 수 있지만 평가에는 더 나은 성능을 발휘할 수 있는 gpt-4를 사용하고자 할 수 있습니다.
다음과 같이 .env 파일에 평가 모델 이름을 추가합니다.
AZURE_OPENAI_EVALUATION_DEPLOYMENT=<your evaluation model deployment name>
평가 데이터 세트 만들기
예시 질문과 예상 답변(truth)이 포함된 다음 평가 데이터 세트를 사용합니다.
rag-tutorial 폴더에 eval_dataset.jsonl 파일을 만듭니다. 애플리케이션 코드 구조를 참조하세요.
다음 데이터 세트를 파일에 붙여넣습니다.
{"chat_input": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"chat_input": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"chat_input": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"chat_input": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"chat_input": "What brand is for TrailMaster tent? ", "truth": "OutdoorLiving"} {"chat_input": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"chat_input": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"chat_input": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"chat_input": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"chat_input": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"chat_input": "How long are the TrailBlaze pants under warrenty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"chat_input": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"chat_input": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
프롬프트 흐름 평가기를 사용하여 평가
이제 다음을 수행할 평가 스크립트를 정의합니다.
- 프롬프트 흐름
evals패키지에서evaluate함수 및 평가기를 가져옵니다. - 샘플
.jsonl데이터 세트를 로드합니다. - 채팅 앱 논리를 중심으로 대상 함수 래퍼를 생성합니다.
- 대상 함수를 사용하고 평가 데이터 세트를 채팅 앱의 응답과 병합하는 평가를 실행합니다.
- 채팅 앱 응답의 품질을 평가하기 위해 GPT 지원 메트릭 집합(관련성, 접지성 및 일관성)을 생성합니다.
- 결과를 로컬로 출력하고 결과를 클라우드 프로젝트에 기록합니다.
이 스크립트를 사용하면 명령줄 및 json 파일에 결과를 출력하여 결과를 로컬로 검토할 수 있습니다.
또한 이 스크립트는 UI에서 평가 실행을 비교할 수 있도록 평가 결과를 클라우드 프로젝트에 기록합니다.
rag-tutorial 폴더에 evaluate.py 파일을 만듭니다.
다음 코드를 추가합니다. 사용 사례에 맞게
dataset_path및evaluation_name을 업데이트합니다.import json import os # set environment variables before importing any other code from dotenv import load_dotenv load_dotenv() import pandas as pd from promptflow.core import AzureOpenAIModelConfiguration from promptflow.evals.evaluate import evaluate from promptflow.evals.evaluators import ( RelevanceEvaluator, GroundednessEvaluator, CoherenceEvaluator, ) # Helper methods def load_jsonl(path): with open(path, "r") as f: return [json.loads(line) for line in f.readlines()] def copilot_wrapper(*, chat_input, **kwargs): from copilot_flow.copilot import get_chat_response result = get_chat_response(chat_input) parsedResult = {"answer": str(result["reply"]), "context": str(result["context"])} return parsedResult def run_evaluation(eval_name, dataset_path): model_config = AzureOpenAIModelConfiguration( azure_deployment=os.getenv("AZURE_OPENAI_EVALUATION_DEPLOYMENT"), api_version=os.getenv("AZURE_OPENAI_API_VERSION"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), ) # Initializing Evaluators relevance_eval = RelevanceEvaluator(model_config) groundedness_eval = GroundednessEvaluator(model_config) coherence_eval = CoherenceEvaluator(model_config) output_path = "./eval_results.jsonl" result = evaluate( target=copilot_wrapper, evaluation_name=eval_name, data=dataset_path, evaluators={ "relevance": relevance_eval, "groundedness": groundedness_eval, "coherence": coherence_eval, }, evaluator_config={ "relevance": {"question": "${data.chat_input}"}, "coherence": {"question": "${data.chat_input}"}, }, # to log evaluation to the cloud AI Studio project azure_ai_project={ "subscription_id": os.getenv("AZURE_SUBSCRIPTION_ID"), "resource_group_name": os.getenv("AZURE_RESOURCE_GROUP"), "project_name": os.getenv("AZUREAI_PROJECT_NAME"), }, ) tabular_result = pd.DataFrame(result.get("rows")) tabular_result.to_json(output_path, orient="records", lines=True) return result, tabular_result if __name__ == "__main__": eval_name = "tutorial-eval" dataset_path = "./eval_dataset.jsonl" result, tabular_result = run_evaluation( eval_name=eval_name, dataset_path=dataset_path ) from pprint import pprint pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
끝의 main 함수를 통해 로컬에서 평가 결과를 볼 수 있으며 AI 스튜디오의 평가 결과 링크를 받을 수 있습니다.
평가 스크립트 실행
콘솔에서 Azure CLI를 사용하여 Azure 계정에 로그인합니다.
az login필요한 패키지를 설치합니다.
pip install promptflow-evals pip install promptflow-azure이제 평가 스크립트를 실행합니다.
python evaluate.py
평가에 프롬프트 흐름 SDK를 사용하는 방법에 대한 자세한 내용은 프롬프트 흐름 SDK를 사용한 평가를 참조하세요.
평가 출력 해석
콘솔 출력에 각 질문에 대한 답변과 요약된 메트릭이 이 깔끔한 테이블 형식으로 표시됩니다. (출력에 다른 열이 표시될 수 있습니다.)
'-----Summarized Metrics-----'
{'coherence.gpt_coherence': 4.3076923076923075,
'groundedness.gpt_groundedness': 4.384615384615385,
'relevance.gpt_relevance': 4.384615384615385}
'-----Tabular Result-----'
question ... gpt_coherence
0 Which tent is the most waterproof? ... 5
1 Which camping table holds the most weight? ... 5
2 How much does TrailWalker Hiking Shoes cost? ... 5
3 What is the proper care for trailwalker hiking... ... 5
4 What brand is the TrailMaster tent? ... 1
5 How do I carry the TrailMaster tent around? ... 5
6 What is the floor area for Floor Area? ... 3
7 What is the material for TrailBlaze Hiking Pants ... 5
8 What color do the TrailBlaze Hiking Pants come ... 5
9 Can the warranty for TrailBlaze pants be trans... ... 3
10 How long are the TrailBlaze pants under warren... ... 5
11 What is the material for PowerBurner Camping S... ... 5
12 Is France in Europe? ... 1
스크립트는 전체 평가 결과를 ./eval_results.jsonl에 기록합니다.
또한 콘솔에는 Azure AI 스튜디오 프로젝트에서 평가 결과를 볼 수 있는 링크가 있습니다.
참고 항목
ERROR:asyncio:Unclosed client session이 표시될 수 있습니다. 이 메시지는 무시해도 괜찮으며 평가 결과에 영향을 주지 않습니다.
AI 스튜디오에서 평가 결과 보기
평가 실행이 완료되면 링크로 이동하여 Azure AI 스튜디오의 평가 페이지에서 평가 결과를 확인합니다.

개별 행을 보고, 행당 메트릭 점수를 확인하며, 검색된 전체 컨텍스트/문서를 볼 수도 있습니다. 이러한 메트릭은 평가 결과를 해석하고 디버깅하는 데 유용할 수 있습니다.

AI 스튜디오의 평가 결과에 대한 자세한 내용은 AI 스튜디오에서 평가 결과를 보는 방법을 참조하세요.
이제 채팅 앱이 정상 작동함을 확인했으므로 애플리케이션을 배포할 준비가 되었습니다.
Azure에 채팅 앱 배포
이제 외부 애플리케이션이나 웹 사이트에서 사용할 수 있도록 이 채팅 앱을 관리형 엔드포인트에 배포하겠습니다.
배포 스크립트는 다음을 수행합니다.
- 관리형 온라인 엔드포인트 만들기
- 흐름을 모델로 정의
- 환경 변수가 있는 해당 엔드포인트의 관리형 환경에 흐름 배포
- 모든 트래픽을 해당 배포로 라우팅
- Azure AI 스튜디오에서 배포를 보고 테스트하는 링크 출력
배포는 흐름 폴더에 지정된 requirement.txt를 사용하는 빌드 컨텍스트(Dockerfile)를 정의하고 배포된 환경에 환경 변수도 설정하므로 채팅 앱이 프로덕션 환경에서도 로컬에서와 동일하게 실행된다는 것을 확신할 수 있습니다.
배포를 위한 빌드 컨텍스트(Dockerfile)
배포된 환경에는 빌드 컨텍스트가 필요하므로 배포된 환경에 대한 Dockerfile을 정의해 보겠습니다. 배포 스크립트는 이 Dockerfile을 기반으로 환경을 만듭니다. copilot_flow 폴더에 다음 Dockerfile을 만듭니다.
FROM mcr.microsoft.com/azureml/promptflow/promptflow-runtime:latest
COPY ./requirements.txt .
RUN pip install -r requirements.txt
관리형 엔드포인트에 채팅 앱 배포
Azure의 관리형 엔드포인트에 애플리케이션을 배포하려면 온라인 엔드포인트를 만들고, 해당 엔드포인트에서 배포를 만든 다음, 모든 트래픽을 해당 배포로 라우팅합니다.
배포를 만드는 과정 중에 copilot_flow 폴더는 모델로 패키지되고 클라우드 환경이 구축됩니다. 엔드포인트는 Microsoft Entra ID 인증을 사용하여 설정됩니다. 코드에서 또는 Azure AI 스튜디오의 엔드포인트 세부 정보 페이지에서 원하는 인증 모드를 업데이트할 수 있습니다.
Important
애플리케이션을 Azure의 관리형 엔드포인트에 배포하면 선택한 인스턴스 유형에 따라 관련 컴퓨팅 비용이 발생합니다. 관련 비용에 대해 알고 있는지, 지정한 인스턴스 유형에 대한 할당량이 있는지 확인하세요. 온라인 엔드포인트에 대해 자세히 알아보세요.
rag-tutorial 폴더에 deploy.py 파일을 만듭니다. 다음 코드를 추가합니다.
import os
from dotenv import load_dotenv
load_dotenv()
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
BuildContext,
)
client = MLClient(
DefaultAzureCredential(),
os.getenv("AZURE_SUBSCRIPTION_ID"),
os.getenv("AZURE_RESOURCE_GROUP"),
os.getenv("AZUREAI_PROJECT_NAME"),
)
endpoint_name = "tutorial-endpoint"
deployment_name = "tutorial-deployment"
endpoint = ManagedOnlineEndpoint(
name=endpoint_name,
properties={
"enforce_access_to_default_secret_stores": "enabled" # for secret injection support
},
auth_mode="aad_token", # using aad auth instead of key-based auth
)
# Get the directory of the current script
script_dir = os.path.dirname(os.path.abspath(__file__))
# Define the path to the directory, appending the script directory to the relative path
copilot_path = os.path.join(script_dir, "copilot_flow")
deployment = ManagedOnlineDeployment(
name=deployment_name,
endpoint_name=endpoint_name,
model=Model(
name="copilot_flow_model",
path=copilot_path, # path to promptflow folder
properties=[ # this enables the chat interface in the endpoint test tab
["azureml.promptflow.source_flow_id", "basic-chat"],
["azureml.promptflow.mode", "chat"],
["azureml.promptflow.chat_input", "chat_input"],
["azureml.promptflow.chat_output", "reply"],
],
),
environment=Environment(
build=BuildContext(
path=copilot_path,
),
inference_config={
"liveness_route": {
"path": "/health",
"port": 8080,
},
"readiness_route": {
"path": "/health",
"port": 8080,
},
"scoring_route": {
"path": "/score",
"port": 8080,
},
},
),
instance_type="Standard_DS3_v2",
instance_count=1,
environment_variables={
"PRT_CONFIG_OVERRIDE": f"deployment.subscription_id={client.subscription_id},deployment.resource_group={client.resource_group_name},deployment.workspace_name={client.workspace_name},deployment.endpoint_name={endpoint_name},deployment.deployment_name={deployment_name}",
"AZURE_OPENAI_ENDPOINT": os.getenv("AZURE_OPENAI_ENDPOINT"),
"AZURE_SEARCH_ENDPOINT": os.getenv("AZURE_SEARCH_ENDPOINT"),
"AZURE_OPENAI_API_VERSION": os.getenv("AZURE_OPENAI_API_VERSION"),
"AZURE_OPENAI_CHAT_DEPLOYMENT": os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT"),
"AZURE_OPENAI_EVALUATION_DEPLOYMENT": os.getenv(
"AZURE_OPENAI_EVALUATION_DEPLOYMENT"
),
"AZURE_OPENAI_EMBEDDING_DEPLOYMENT": os.getenv(
"AZURE_OPENAI_EMBEDDING_DEPLOYMENT"
),
"AZUREAI_SEARCH_INDEX_NAME": os.getenv("AZUREAI_SEARCH_INDEX_NAME"),
},
)
# 1. create endpoint
created_endpoint = client.begin_create_or_update(
endpoint
).result() # result() means we wait on this to complete
# 2. create deployment
created_deployment = client.begin_create_or_update(deployment).result()
# 3. update endpoint traffic for the deployment
endpoint.traffic = {deployment_name: 100} # 100% of traffic
client.begin_create_or_update(endpoint).result()
Important
엔드포인트 및 배포 이름은 Azure 지역 내에서 고유해야 합니다. 엔드포인트 또는 배포 이름이 이미 존재한다는 오류가 발생하면 다른 이름을 사용하세요.
배포 세부 정보 출력
배포 스크립트 끝에 다음 줄을 추가하여 평가 결과를 로컬로 보고 스튜디오 링크를 가져옵니다.
def get_ai_studio_url_for_deploy(
client: MLClient, endpoint_name: str, deployment_name
) -> str:
studio_base_url = "https://ai.azure.com"
deployment_url = f"{studio_base_url}/projectdeployments/realtime/{endpoint_name}/{deployment_name}/detail?wsid=/subscriptions/{client.subscription_id}/resourceGroups/{client.resource_group_name}/providers/Microsoft.MachineLearningServices/workspaces/{client.workspace_name}&deploymentName={deployment_name}"
return deployment_url
print("\n ~~~Deployment details~~~")
print(f"Your online endpoint name is: {endpoint_name}")
print(f"Your deployment name is: {deployment_name}")
print("\n ~~~Test in the Azure AI Studio~~~")
print("\n Follow this link to your deployment in the Azure AI Studio:")
print(
get_ai_studio_url_for_deploy(
client=client, endpoint_name=endpoint_name, deployment_name=deployment_name
)
)
이제 다음을 사용하여 스크립트를 실행합니다.
python deploy.py
참고 항목
배포를 완료하는 데 10분 이상 걸릴 수 있습니다. 기다리는 동안 다음 단계에 따라 엔드포인트에 대한 액세스 권한을 할당하는 것이 좋습니다.
배포가 완료되면 배포를 테스트할 수 있는 Azure AI 스튜디오 배포 페이지로 연결되는 링크가 표시됩니다.
배포 확인
Azure AI 스튜디오에서 애플리케이션을 테스트하는 것이 좋습니다. 배포된 엔드포인트를 로컬로 테스트하려는 경우 사용자 지정 코드로 호출할 수 있습니다.
다음 단계에 필요한 엔드포인트 이름을 확인합니다.
Azure OpenAI 리소스에 대한 엔드포인트 액세스 권한
Azure 구독 소유자(IT 관리자일 수 있는 사용자)에게 이 섹션에 대한 도움을 요청해야 할 수 있습니다.
애플리케이션이 배포되기를 기다리는 동안 사용자 또는 관리자가 엔드포인트에 역할 기반 액세스를 할당할 수 있습니다. 이러한 역할을 사용하면 로컬에서와 마찬가지로 배포된 환경에서 키 없이 애플리케이션을 실행할 수 있습니다.
이전에 Microsoft Entra ID 인증을 사용하여 리소스에 액세스할 수 있는 특정 역할을 계정에 제공했습니다. 이제 Cognitive Services OpenAI 사용자 역할과 동일한 엔드포인트를 할당합니다.
참고 항목
이 단계는 빠른 시작에서 Azure OpenAI Service를 사용하기 위해 사용자 ID에 역할을 할당한 방법과 유사합니다.
사용 중인 Azure AI 서비스 리소스에 대한 액세스 권한을 자신에게 부여하려면 다음을 수행합니다.
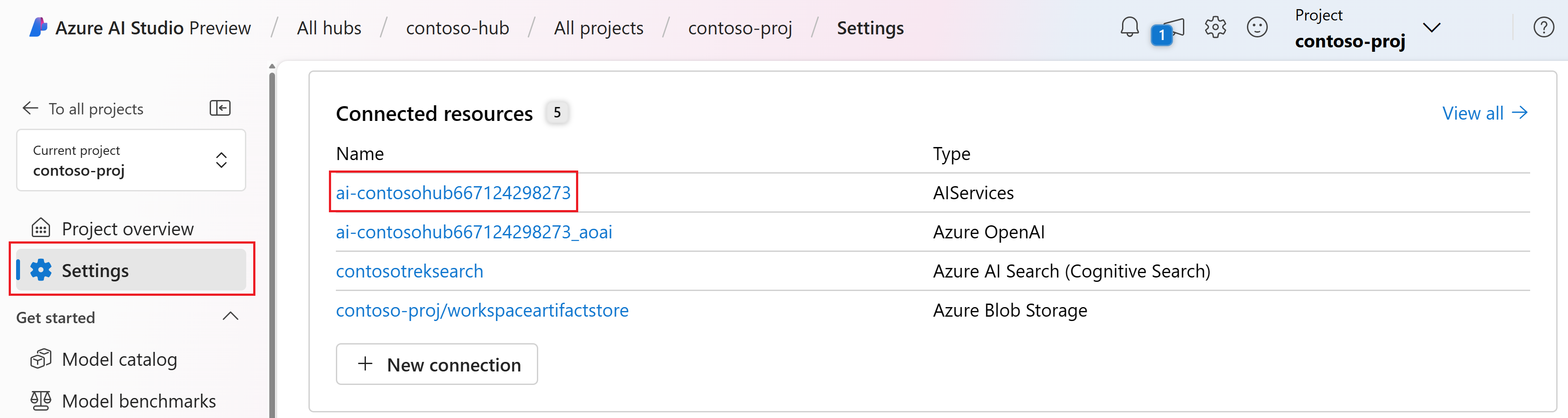
AI 스튜디오에서 프로젝트로 이동하여 왼쪽 창에서 설정을 선택합니다.
연결된 리소스 섹션에서 AIServices 형식의 연결 이름을 선택합니다.
참고 항목
AIServices 연결이 표시되지 않으면 대신 Azure OpenAI 연결을 사용합니다.
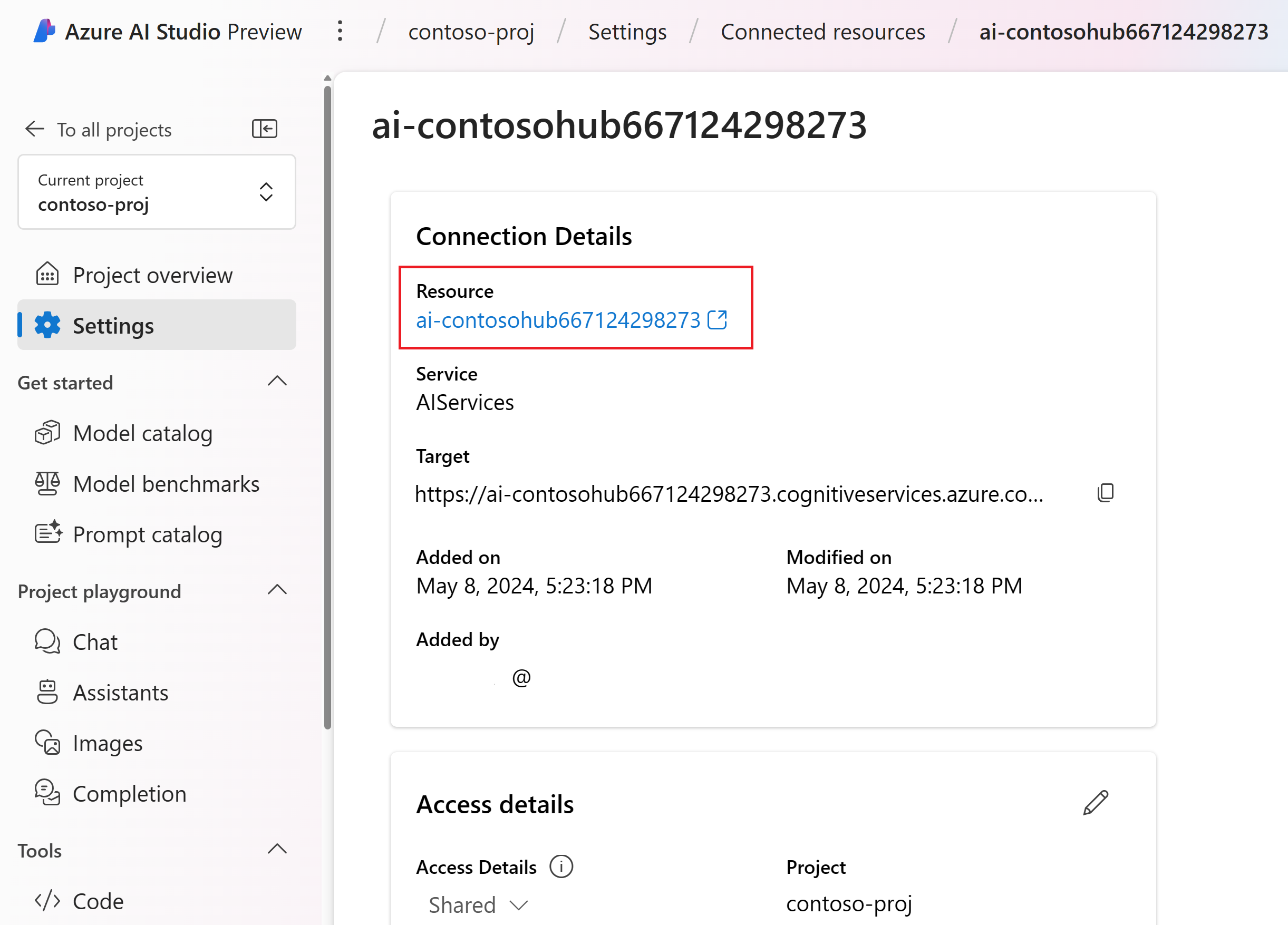
리소스 세부 정보 페이지에서 리소스 제목 아래의 링크를 선택하여 Azure Portal에서 AI 서비스 리소스를 엽니다.
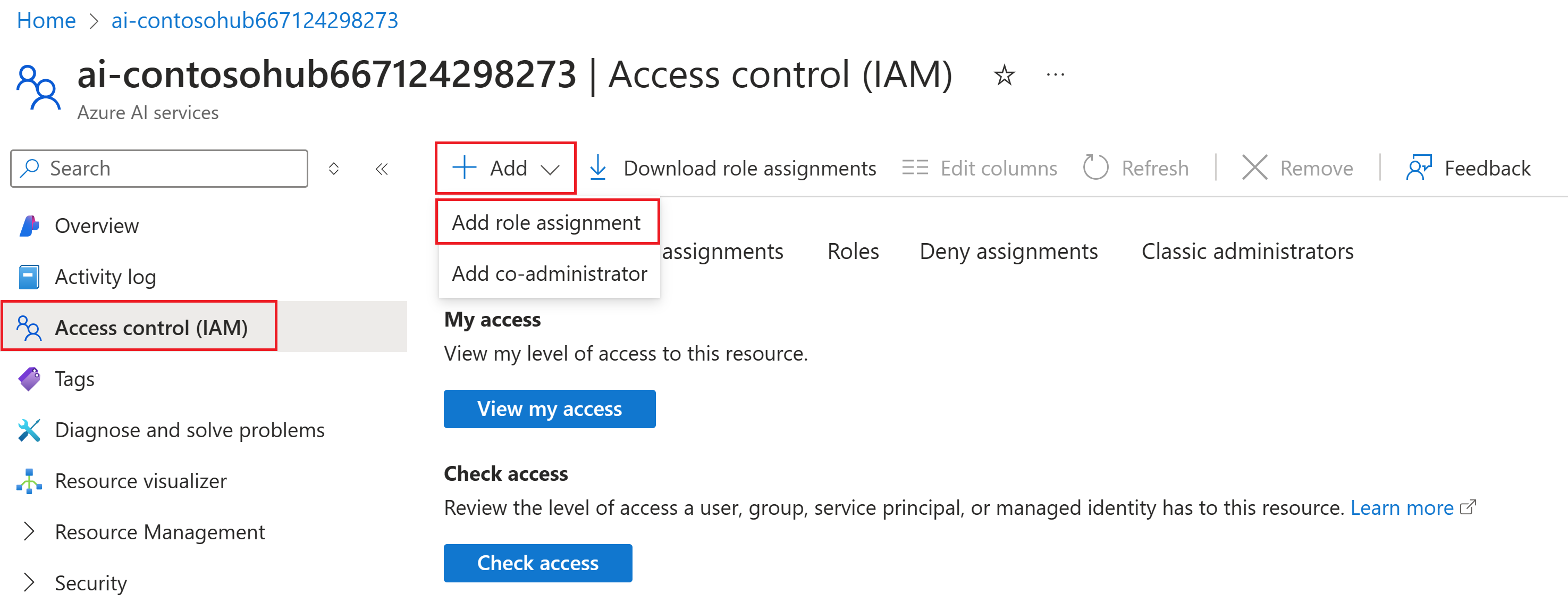
Azure Portal의 왼쪽 페이지에서 액세스 제어(IAM)>+ 추가>역할 할당 추가를 선택합니다.
Cognitive Services OpenAI 사용자 역할을 검색한 후 선택합니다. 그런 후 다음을 선택합니다.
관리 ID를 선택합니다. 그런 다음, 멤버 선택을 선택합니다.
구성원 선택 창이 열리면 관리 ID에 대한 기계 학습 온라인 엔드포인트를 선택한 다음, 엔드포인트 이름을 검색합니다. 엔드포인트를 선택한 다음 선택을 선택합니다.

마법사를 계속 진행하고 검토 + 할당을 선택하여 역할 할당을 추가합니다.



참고 항목
액세스 권한이 전파되는 데 몇 분 정도 걸릴 수 있습니다. 다음 단계에서 테스트할 때 권한 없음 오류가 발생하면 몇 분 후에 다시 시도하세요.
Azure AI 검색 리소스에 대한 엔드포인트 액세스
Azure 구독 소유자(IT 관리자일 수 있는 사용자)에게 이 섹션에 대한 도움을 요청해야 할 수 있습니다.
검색 인덱스 데이터 기여자 역할을 Azure AI 검색 서비스에 할당한 방식과 마찬가지로 엔드포인트에 대해 동일한 역할을 할당해야 합니다.
Azure AI 스튜디오에서 설정을 선택하고 연결된 Azure AI 검색 서비스로 이동합니다.
링크를 선택하여 리소스 요약을 엽니다. 요약 페이지에서 링크를 선택하여 Azure Portal에서 리소스를 엽니다.
Azure Portal의 왼쪽 페이지에서 액세스 제어(IAM)>+ 추가>역할 할당 추가를 선택합니다.

검색 인덱스 데이터 기여자 역할을 검색한 후 선택합니다. 그런 후 다음을 선택합니다.
관리 ID를 선택합니다. 그런 다음, 멤버 선택을 선택합니다.
구성원 선택 창이 열리면 관리 ID에 대한 기계 학습 온라인 엔드포인트를 선택한 다음, 엔드포인트 이름을 검색합니다. 엔드포인트를 선택한 다음 선택을 선택합니다.

마법사를 계속 진행하고 검토 + 할당을 선택하여 역할 할당을 추가합니다.
참고 항목
액세스 권한이 전파되는 데 몇 분 정도 걸릴 수 있습니다. 다음 단계에서 테스트할 때 권한 없음 오류가 발생하면 몇 분 후에 다시 시도하세요.
AI 스튜디오에서 배포 테스트
배포가 완료되면 간편하게 배포로 이동할 수 있는 링크가 표시됩니다. 링크를 사용하지 않는 경우 프로젝트의 배포 탭으로 이동하여 새 배포를 선택합니다.

테스트 탭을 선택하고 채팅 인터페이스에서 질문해 봅니다.
예를 들어 "Trailwalker 하이킹 신발에 방수 기능이 있어?"를 입력하고 Enter 키를 누릅니다.

응답이 돌아오면 배포가 확인됩니다.
오류가 발생하면 로그 탭을 선택하여 자세한 내용을 확인합니다.
참고 항목
권한 없음 오류가 발생한다면 엔드포인트 액세스 권한이 아직 적용되지 않았을 수 있습니다. 몇 분 후에 다시 시도해 보십시오.
배포된 채팅 앱을 로컬로 호출
로컬로 배포를 확인하려면 Python 스크립트를 통해 호출할 수 있습니다.
다음을 수행할 스크립트를 정의합니다.
- 채점 URL에 보낼 잘 구성된 요청을 생성합니다.
- 요청을 게시하고 응답을 처리합니다.
다음 코드를 사용하여 rag-tutorial 폴더에 invoke-local.py 파일을 만듭니다. 사용 사례에 맞게 query 및 endpoint_name(또한 필요에 따라 기타 매개 변수)을 수정합니다.
import os
from dotenv import load_dotenv
load_dotenv()
import requests
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
query = "Are the trailwalker shoes waterproof?"
endpoint_name = "tutorial-endpoint"
client = MLClient(
DefaultAzureCredential(),
os.getenv("AZURE_SUBSCRIPTION_ID"),
os.getenv("AZURE_RESOURCE_GROUP"),
os.getenv("AZUREAI_PROJECT_NAME"),
)
scoring_url = client.online_endpoints.get(endpoint_name).scoring_uri
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {client._credential.get_token('https://ml.azure.com').token}",
"Accept": "application/json",
}
response = requests.post(
scoring_url,
headers=headers,
json={"chat_input": query},
)
(print(response.json()["reply"]))
콘솔에 쿼리에 대한 채팅 앱 답변이 표시됩니다.
참고 항목
권한 없음 오류가 발생한다면 엔드포인트 액세스 권한이 아직 적용되지 않았을 수 있습니다. 몇 분 후에 다시 시도해 보십시오.
리소스 정리
불필요한 Azure 비용이 발생하지 않도록 하려면 이 자습서에서 만든 리소스가 더 이상 필요하지 않은 경우 삭제해야 합니다. 리소스를 관리하려면 Azure Portal을 사용할 수 있습니다.
관련 콘텐츠
- 프롬프트 흐름에 대해 자세히 알아보기
- RAG를 구현하는 샘플 채팅 앱 애플리케이션은 Azure-Samples/rag-data-openai-python-promptflow를 참조하세요.