사용량이 많은 데이터베이스 안티패턴
처리를 데이터베이스 서버로 오프로드하면 데이터 저장 및 검색 요청에 응답하는 대신 코드를 실행하는 데 상당한 시간이 소요될 수 있습니다.
문제 설명
많은 데이터베이스 시스템에서 코드를 실행할 수 있습니다. 저장 프로시저 및 트리거를 예로 들 수 있습니다. 이런 처리를 데이터 가까이에서 수행하는 것이 처리를 위해 데이터를 클라이언트 애플리케이션에 전송하는 것보다 효율적인 경우가 많습니다. 하지만 이런 기능을 과도하게 사용하면 성능이 저하될 수 있으며 이유는 다음과 같습니다.
- 데이터베이스 서버가 새 클라이언트 요청을 수락하고 데이터를 가져오기보다 처리하는 데 너무 많은 시간을 소비할 수 있습니다.
- 데이터베이스는 대개 공유 리소스여서 많이 사용되는 기간에는 병목 상태가 될 수 있습니다.
- 데이터 저장소가 유료인 경우 런타임 비용이 과도해질 수 있습니다. 관리되는 데이터베이스 서비스의 경우 특히 그렇습니다. 예를 들어 Azure SQL Database는 DTU(데이터베이스 트랜잭션 단위)에 요금을 부과합니다.
- 데이터베이스는 확장 가능한 용량이 한정되어 있으며 데이터베이스를 수평 확장하기는 쉽지 않습니다. 따라서 쉽게 확장할 수 있는 VM이나 App Service 앱과 같은 컴퓨팅 리소스로 처리를 옮기는 것이 좋습니다.
이런 안티패턴이 발생하는 일반적인 이유는 다음과 같습니다.
- 데이터베이스는 리포지토리가 아닌 서비스로 간주됩니다. 애플리케이션은 데이터베이스 서버를 사용하여 데이터 형식을 지정하거나(예: XML로 변환) 문자열 데이터를 조작하거나 복잡한 계산을 수행할 수 있습니다.
- 개발자는 결과를 사용자에게 직접 표시할 수 있는 쿼리를 작성하려고 합니다. 예를 들어, 쿼리는 필드를 결합하거나 로캘에 따라 날짜, 시간 및 통화 형식을 지정할 수 있습니다.
- 개발자는 계산을 데이터베이스로 푸시하여 불필요한 가져오기 안티패턴을 수정하려고 합니다.
- 저장 프로시저는 비즈니스 논리를 캡슐화하는 데 사용됩니다. 아마도 유지 관리 및 업데이트가 더 쉽다고 간주되기 때문입니다.
다음 예제는 지정된 판매 지역에서 가장 중요한 주문을 20건 검색하고 그 결과를 XML로 형식화합니다. Transact-SQL 함수를 사용하여 데이터를 구문 분석하고 결과를 XML로 변환합니다. 전체 샘플은 여기에서 찾을 수 있습니다.
SELECT TOP 20
soh.[SalesOrderNumber] AS '@OrderNumber',
soh.[Status] AS '@Status',
soh.[ShipDate] AS '@ShipDate',
YEAR(soh.[OrderDate]) AS '@OrderDateYear',
MONTH(soh.[OrderDate]) AS '@OrderDateMonth',
soh.[DueDate] AS '@DueDate',
FORMAT(ROUND(soh.[SubTotal],2),'C')
AS '@SubTotal',
FORMAT(ROUND(soh.[TaxAmt],2),'C')
AS '@TaxAmt',
FORMAT(ROUND(soh.[TotalDue],2),'C')
AS '@TotalDue',
CASE WHEN soh.[TotalDue] > 5000 THEN 'Y' ELSE 'N' END
AS '@ReviewRequired',
(
SELECT
c.[AccountNumber] AS '@AccountNumber',
UPPER(LTRIM(RTRIM(REPLACE(
CONCAT( p.[Title], ' ', p.[FirstName], ' ', p.[MiddleName], ' ', p.[LastName], ' ', p.[Suffix]),
' ', ' ')))) AS '@FullName'
FROM [Sales].[Customer] c
INNER JOIN [Person].[Person] p
ON c.[PersonID] = p.[BusinessEntityID]
WHERE c.[CustomerID] = soh.[CustomerID]
FOR XML PATH ('Customer'), TYPE
),
(
SELECT
sod.[OrderQty] AS '@Quantity',
FORMAT(sod.[UnitPrice],'C')
AS '@UnitPrice',
FORMAT(ROUND(sod.[LineTotal],2),'C')
AS '@LineTotal',
sod.[ProductID] AS '@ProductId',
CASE WHEN (sod.[ProductID] >= 710) AND (sod.[ProductID] <= 720) AND (sod.[OrderQty] >= 5) THEN 'Y' ELSE 'N' END
AS '@InventoryCheckRequired'
FROM [Sales].[SalesOrderDetail] sod
WHERE sod.[SalesOrderID] = soh.[SalesOrderID]
ORDER BY sod.[SalesOrderDetailID]
FOR XML PATH ('LineItem'), TYPE, ROOT('OrderLineItems')
)
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC
FOR XML PATH ('Order'), ROOT('Orders')
이것은 분명히 복잡한 쿼리입니다. 나중에 살펴보겠지만 데이터베이스 서버에서 중요한 처리 리소스를 사용하는 것으로 나타납니다.
문제를 해결하는 방법
처리를 데이터베이스 서버에서 다른 애플리케이션 계층으로 이동합니다. 이상적으로는 데이터베이스가 RDBMS의 집계와 같이 최적화된 기능만을 사용하여 데이터 액세스 작업을 수행하도록 데이터베이스를 제한해야 합니다.
예를 들어, 이전 Transact-SQL 코드는 처리할 데이터만 검색하는 명령문으로 대체될 수 있습니다.
SELECT
soh.[SalesOrderNumber] AS [OrderNumber],
soh.[Status] AS [Status],
soh.[OrderDate] AS [OrderDate],
soh.[DueDate] AS [DueDate],
soh.[ShipDate] AS [ShipDate],
soh.[SubTotal] AS [SubTotal],
soh.[TaxAmt] AS [TaxAmt],
soh.[TotalDue] AS [TotalDue],
c.[AccountNumber] AS [AccountNumber],
p.[Title] AS [CustomerTitle],
p.[FirstName] AS [CustomerFirstName],
p.[MiddleName] AS [CustomerMiddleName],
p.[LastName] AS [CustomerLastName],
p.[Suffix] AS [CustomerSuffix],
sod.[OrderQty] AS [Quantity],
sod.[UnitPrice] AS [UnitPrice],
sod.[LineTotal] AS [LineTotal],
sod.[ProductID] AS [ProductId]
FROM [Sales].[SalesOrderHeader] soh
INNER JOIN [Sales].[Customer] c ON soh.[CustomerID] = c.[CustomerID]
INNER JOIN [Person].[Person] p ON c.[PersonID] = p.[BusinessEntityID]
INNER JOIN [Sales].[SalesOrderDetail] sod ON soh.[SalesOrderID] = sod.[SalesOrderID]
WHERE soh.[TerritoryId] = @TerritoryId
AND soh.[SalesOrderId] IN (
SELECT TOP 20 SalesOrderId
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC)
ORDER BY soh.[TotalDue] DESC, sod.[SalesOrderDetailID]
그런 다음, 애플리케이션이 .NET Framework System.Xml.Linq API를 사용하여 결과를 XML로 형식화합니다.
// Create a new SqlCommand to run the Transact-SQL query
using (var command = new SqlCommand(...))
{
command.Parameters.AddWithValue("@TerritoryId", id);
// Run the query and create the initial XML document
using (var reader = await command.ExecuteReaderAsync())
{
var lastOrderNumber = string.Empty;
var doc = new XDocument();
var orders = new XElement("Orders");
doc.Add(orders);
XElement lineItems = null;
// Fetch each row in turn, format the results as XML, and add them to the XML document
while (await reader.ReadAsync())
{
var orderNumber = reader["OrderNumber"].ToString();
if (orderNumber != lastOrderNumber)
{
lastOrderNumber = orderNumber;
var order = new XElement("Order");
orders.Add(order);
var customer = new XElement("Customer");
lineItems = new XElement("OrderLineItems");
order.Add(customer, lineItems);
var orderDate = (DateTime)reader["OrderDate"];
var totalDue = (Decimal)reader["TotalDue"];
var reviewRequired = totalDue > 5000 ? 'Y' : 'N';
order.Add(
new XAttribute("OrderNumber", orderNumber),
new XAttribute("Status", reader["Status"]),
new XAttribute("ShipDate", reader["ShipDate"]),
... // More attributes, not shown.
var fullName = string.Join(" ",
reader["CustomerTitle"],
reader["CustomerFirstName"],
reader["CustomerMiddleName"],
reader["CustomerLastName"],
reader["CustomerSuffix"]
)
.Replace(" ", " ") //remove double spaces
.Trim()
.ToUpper();
customer.Add(
new XAttribute("AccountNumber", reader["AccountNumber"]),
new XAttribute("FullName", fullName));
}
var productId = (int)reader["ProductID"];
var quantity = (short)reader["Quantity"];
var inventoryCheckRequired = (productId >= 710 && productId <= 720 && quantity >= 5) ? 'Y' : 'N';
lineItems.Add(
new XElement("LineItem",
new XAttribute("Quantity", quantity),
new XAttribute("UnitPrice", ((Decimal)reader["UnitPrice"]).ToString("C")),
new XAttribute("LineTotal", RoundAndFormat(reader["LineTotal"])),
new XAttribute("ProductId", productId),
new XAttribute("InventoryCheckRequired", inventoryCheckRequired)
));
}
// Match the exact formatting of the XML returned from SQL
var xml = doc
.ToString(SaveOptions.DisableFormatting)
.Replace(" />", "/>");
}
}
참고
이 코드는 다소 복잡합니다. 새 애플리케이션의 경우 serialization 라이브러리를 사용하는 것이 좋습니다. 하지만 이 경우 개발 팀이 기존 애플리케이션을 리팩터링한다고 가정하기 때문에 메서드가 원래 코드와 정확히 같은 형식을 반환해야 합니다.
고려 사항
많은 데이터베이스 시스템은 특정 유형의 데이터 처리(예: 대규모 데이터 세트에 대한 집계 값 계산)를 수행하도록 고도로 최적화되어 있습니다. 이러한 유형의 처리를 데이터베이스 외부로 이동하지 마십시오.
처리를 재배치하면 데이터베이스가 네트워크를 통해 훨씬 더 많은 데이터를 전송하게 되므로 재배치하지 마십시오. 불필요한 가져오기 안티패턴을 참조하세요.
처리를 애플리케이션 계층으로 이동하면 추가 작업을 처리하도록 해당 계층을 확장해야 할 수도 있습니다.
문제를 감지하는 방법
사용량이 많은 데이터베이스의 증상에는 데이터베이스에 액세스하는 작업의 처리량과 응답 시간이 불균형적으로 감소하는 증상이 포함됩니다.
다음 단계를 수행하면 문제를 식별하는 데 도움이 될 수 있습니다.
성능 모니터링을 사용하여 프로덕션 시스템이 데이터베이스 활동을 수행하는 데 얼마나 많은 시간을 소비하는지 확인합니다.
이 기간 동안 데이터베이스가 수행한 작업을 검사합니다.
특정 작업이 너무 많은 데이터베이스 활동을 유발한 것으로 의심되는 경우 통제된 환경에서 부하 테스트를 수행합니다. 각 테스트는 가변적인 사용자 로드와 의심스러운 작업을 혼합하여 실행해야 합니다. 부하 테스트에서 원격 분석 데이터를 검사하여 데이터베이스가 어떻게 사용되는지 관찰합니다.
데이터베이스 활동이 처리량은 많은 것으로 드러나지만 데이터 트래픽이 적다면 소스 코드를 검토하여 처리가 다른 곳에서 더 잘 수행될 수 있는지 판단합니다.
데이터베이스 활동량이 작거나 응답 시간이 비교적 빠르다면 사용량이 많은 데이터베이스가 성능 문제일 가능성이 낮습니다.
예제 진단
다음 섹션에서는 이러한 단계를 앞에서 설명한 애플리케이션 예제에 적용합니다.
데이터베이스 활동 볼륨 모니터링
다음 그래프는 동시 사용자 최대 50명의 단계 부하를 사용하여 애플리케이션 예제에 부하 테스트를 실행한 결과를 보여줍니다. 요청 볼륨은 빠르게 한도에 도달하여 그 수준에 머무르고 평균 응답 시간은 꾸준히 증가합니다. 두 메트릭에 로그 눈금 간격이 사용되었습니다.
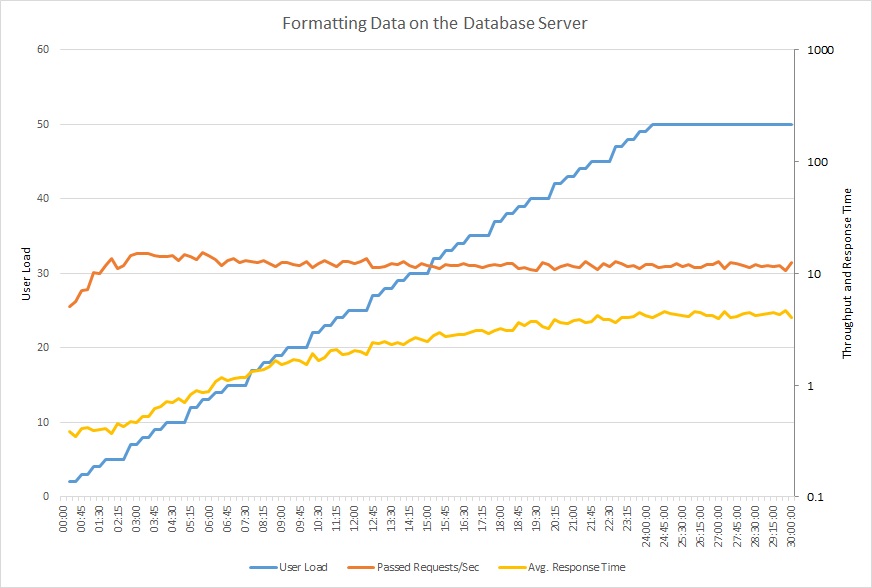
이 선 그래프는 사용자 로드, 초당 요청 수 및 평균 응답 시간을 보여 줍니다. 그래프에 따르면 부하가 증가함에 따라 응답 시간이 증가합니다.
다음 그래프는 CPU 사용률과 DTU를 서비스 할당량의 백분율로 나타냅니다. DTU는 데이터베이스가 수행하는 처리량을 측정한 값을 제공합니다. 이 그래프에서 CPU와 DTU 사용률 모두 100%에 신속하게 도달합니다.
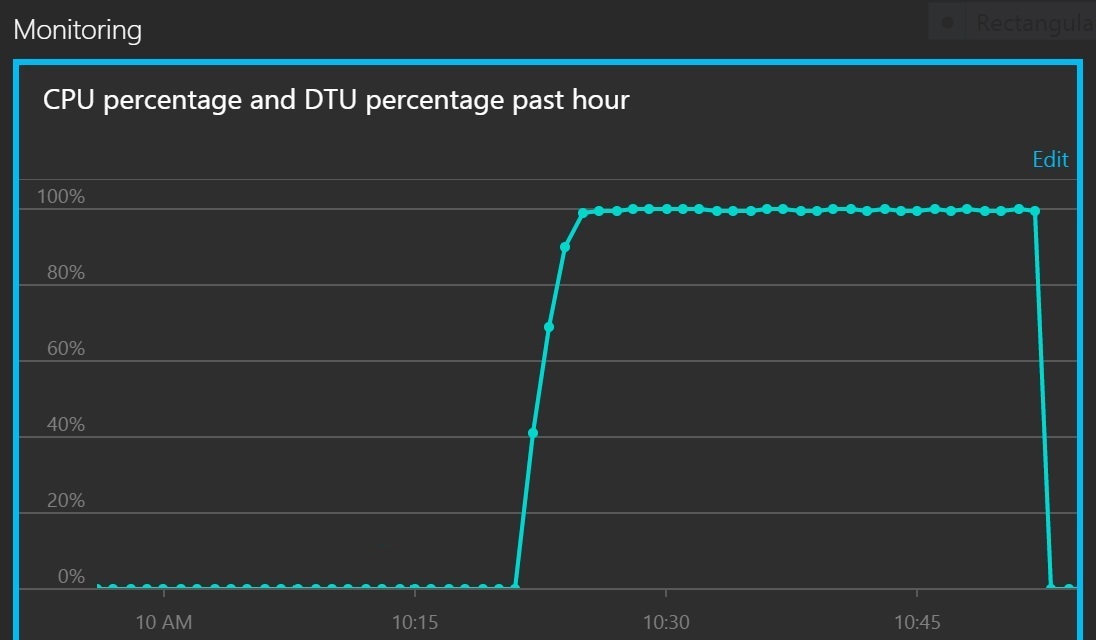
이 선 그래프는 시간 경과에 따른 CPU 백분율 및 DTU 백분율을 보여 줍니다. 그래프에 따르면 두 백분율이 모두 빠르게 100%에 도달합니다.
데이터베이스가 수행한 작업 검사
데이터베이스가 수행한 작업은 처리가 아니라 실제 데이터 액세스 작업이므로 데이터베이스를 사용하고 있을 때 실행 중인 SQL 문을 이해하는 것이 중요합니다. 시스템을 모니터링하여 SQL 트래픽을 캡처하고 SQL 작업과 애플리케이션 요청의 상관 관계를 지정합니다.
데이터베이스 작업이 처리가 포함되지 않은 순수한 데이터 액세스 작업인 경우에는 불필요한 가져오기가 문제일 수 있습니다.
솔루션 구현 및 결과 확인
다음 그래프는 업데이트된 코드를 사용한 부하 테스트를 보여줍니다. 처리량이 초당 요청이 400건 이상으로 이전의 12보다 상당히 높습니다. 평균 응답 시간도 0.1초를 살짝 넘어 4초 이상에 비해 훨씬 적습니다.
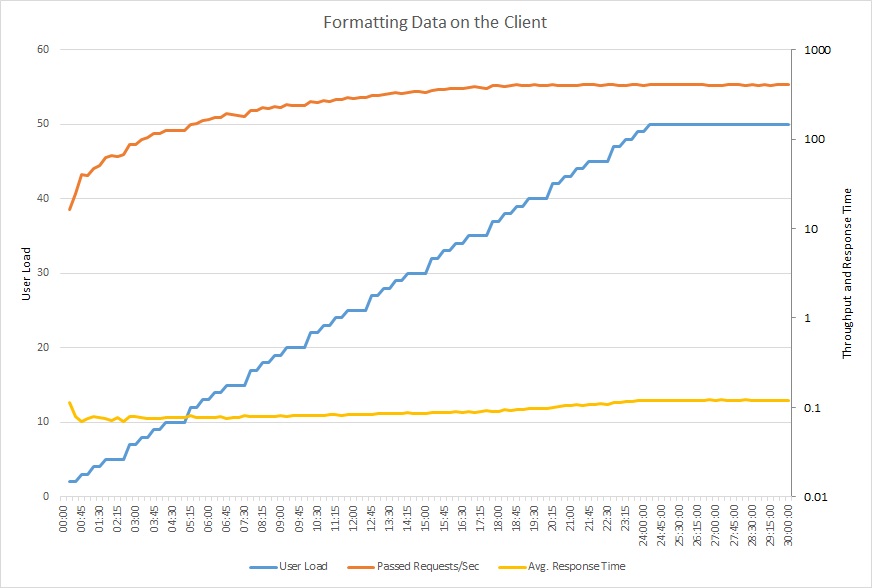
이 선 그래프는 사용자 로드, 초당 요청 수 및 평균 응답 시간을 보여 줍니다. 그래프에 따르면 부하 테스트 전체에서 응답 시간이 거의 일정하게 유지되고 있습니다.
CPU 및 DTU 사용률을 보면 처리량 증가에도 불구하고 시스템이 포화 상태에 도달하는데 더 오래 걸렸습니다.
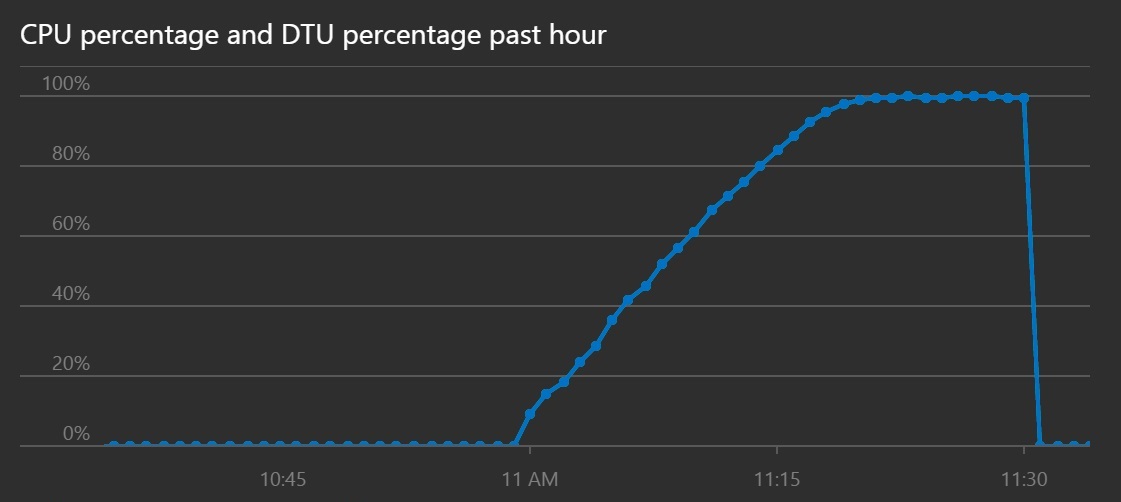
이 선 그래프는 시간 경과에 따른 CPU 백분율 및 DTU 백분율을 보여 줍니다. 그래프에 따르면 CPU 및 DTU가 100%에 도달하는 데 있어 이전보다 더 오래 걸립니다.
관련 참고 자료
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기