불필요한 가져오기 안티패턴
안티패턴은 스트레스 상황에서 소프트웨어 또는 애플리케이션을 중단시킬 수 있는 일반적인 설계 결함이며 간과해서는 안 됩니다. 불필요한 가져오기 안티패턴에서는 비즈니스 작업에 필요한 것보다 더 많은 데이터를 검색하여 불필요한 I/O 오버헤드가 발생하고 응답성이 저하되는 경우가 많습니다.
불필요한 가져오기 안티패턴의 예
이 안티패턴은 애플리케이션이 필요할 수 있는 모든 데이터를 조회하여 I/O 요청을 최소화하려고 하는 경우 발생할 수 있습니다. 이는 종종 번잡한 I/O 안티패턴을 과도하게 보정한 결과입니다. 예를 들어 애플리케이션이 데이터베이스의 모든 제품에 대한 세부정보를 가져올 수 있습니다. 그러나 사용자는 해당 세부정보의 일부만 필요하며(일부는 고객에게 유용하지 않을 수 있음) 아마도 모든 제품을 동시에 볼 필요는 없을 것입니다. 사용자가 전체 카탈로그를 탐색한다 하더라도 예를 들어 결과를 한 번에 20개씩 보여 주는 페이지로 나누는 것이 좋습니다.
이 문제의 또 다른 원인은 좋지 않은 프로그래밍 또는 설계 관행을 따르는 것입니다. 예를 들어 다음 코드는 Entity Framework를 사용하여 모든 제품의 전체 세부정보를 가져옵니다. 그런 다음 결과를 필터링하여 필드의 일부만 반환하고 나머지는 버립니다. 전체 샘플은 여기에서 찾을 수 있습니다.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
다음 예제에서 애플리케이션은 데이터베이스 대신 수행할 수 있는 집계를 수행합니다. 이 애플리케이션은 판매한 모든 주문에 대한 모든 기록을 가져온 다음 해당 레코드에 대한 합계를 계산하여 총 매출을 계산합니다. 전체 샘플은 여기에서 찾을 수 있습니다.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
다음 예제에서는 Entity Framework가 LINQ to Entities를 사용하는 방법 때문에 발생하는 미묘한 문제를 보여 줍니다.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
애플리케이션은 일주일 이상 오래된 SellStartDate의 제품을 찾으려고 합니다. 대부분의 경우 LINQ to Entities는 where 절을 데이터베이스에서 실행되는 SQL 문으로 변환합니다. 그러나 이 경우 LINQ to Entities는 AddDays 메서드를 SQL에 매핑할 수 없습니다. 그 대신에 Product 테이블의 모든 행이 반환되며 그 결과가 메모리에서 필터링됩니다.
AsEnumerable 호출이 바로 문제가 있다는 힌트입니다. 이 메서드는 결과를 IEnumerable 인터페이스로 변환합니다. IEnumerable은 필터링을 지원하지만 이 필터링은 데이터베이스가 아닌 클라이언트 쪽에서 수행됩니다. 기본적으로 LINQ to Entities는 IQueryable을 사용하여 필터링 책임을 데이터 원본에 넘깁니다.
불필요한 가져오기 안티패턴을 해결하는 방법
금세 오래되거나 삭제될 수 있는 대량의 데이터를 가져오지 않고 수행 중인 작업에 필요한 데이터만 가져옵니다.
테이블의 모든 열을 가져와서 필터링하는 대신에 데이터베이스에서 필요한 열을 선택합니다.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
마찬가지로 애플리케이션 메모리가 아닌 데이터베이스에서 집계를 수행합니다.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Entity Framework를 사용하는 경우 LINQ 쿼리가 IEnumerable이 아닌 IQueryable 인터페이스를 사용하여 확인되도록 합니다. 데이터 원본에 매핑할 수 있는 함수만 사용하여 쿼리를 조정해야 할 수 있습니다. 앞의 예제를 리팩터링하여 쿼리에서 AddDays 메서드를 제거하면 데이터베이스에서 필터링을 수행할 수 있습니다.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
고려 사항
경우에 따라 데이터를 행 분할하여 성능을 개선할 수 있습니다. 서로 다른 작업이 데이터의 서로 다른 특성에 액세스하는 경우 행 분할로 경합을 줄일 수 있습니다. 흔히 대부분의 작업은 데이터의 작은 하위 집합에 대해 실행되므로 이러한 부하 분산으로 성능이 개선될 수 있습니다. 데이터 분할을 참조하세요.
바인딩되지 않은 쿼리를 지원해야 하는 작업의 경우 페이지 매김을 구현하고 한 번에 제한된 수의 엔터티만 가져옵니다. 예를 들어 고객이 제품 카탈로그를 검색하는 경우 결과를 한 번에 한 페이지씩 표시할 수 있습니다.
가능하면 데이터 저장소에 기본 제공되는 기능을 이용합니다. 예를 들어 SQL Database는 대개 집계 함수를 제공합니다.
집계 같은 특정 기능을 지원하지 않는 데이터 원본을 사용하는 경우 계산된 결과를 다른 곳에 저장하고 레코드가 추가되거나 업데이트될 때 값을 업데이트할 수 있으므로 애플리케이션이 필요할 때마다 값을 다시 계산할 필요가 없습니다.
요청이 다수의 필드를 검색하는 것으로 보이면 소스 코드를 검토하여 이 필드가 모두 필요한지 여부를 결정합니다. 경우에 따라 이러한 요청은 잘못 설계된
SELECT *쿼리의 결과입니다.마찬가지로 다수의 엔터티를 검색하는 요청은 애플리케이션이 데이터를 올바르게 필터링하지 않는다는 신호일 수 있습니다. 이러한 엔터티가 모두 필요한지 확인합니다. 가능하면 데이터베이스 쪽 필터링을 사용합니다. 예를 들어 SQL의
WHERE절을 사용합니다.데이터베이스에서 오프로딩을 수행하는 방법이 항상 최선의 옵션은 아닙니다. 이 전략은 데이터베이스가 그렇게 하도록 설계되거나 최적화된 경우에만 사용합니다. 대부분의 데이터베이스 시스템은 특정 기능에 대해 고도로 최적화되지만 범용 애플리케이션 엔진으로 작동하도록 설계되어 있지 않습니다. 자세한 내용은 사용량이 많은 데이터베이스 안티패턴을 참조하세요.
불필요한 가져오기 안티패턴을 검색하는 방법
불필요한 가져오기의 증상에는 높은 대기 시간과 낮은 처리량이 있습니다. 데이터를 데이터 원본에서 검색하는 경우 경합이 증가할 확률도 있습니다. 응답 시간이 길어지거나 서비스 시간 초과로 인해 장애가 발생하면 최종 사용자가 보고할 가능성이 높습니다. 이러한 장애는 HTTP 500(내부 서버) 오류 또는 HTTP 503(서비스를 사용할 수 없음) 오류를 반환할 수 있습니다. 웹 서버의 이벤트 로그를 검사하세요. 오류의 원인과 상황에 대한 자세한 정보가 포함되어 있을 수 있습니다.
이 안티패턴 및 가져온 일부 원격 분석의 증상은 모놀리식 지속성 안티패턴과 매우 비슷할 수 있습니다.
다음 단계를 수행하면 원인을 식별하는 데 도움이 될 수 있습니다.
- 부하 테스트, 프로세스 모니터링 또는 다른 계측 데이터 수집 방법을 수행하여 느린 워크로드 또는 트랜잭션을 식별합니다.
- 시스템에서 보여 주는 동작 패턴을 관찰합니다. 초당 트랜잭션 수 또는 사용자 볼륨 측면에서 특정 한계가 있습니까?
- 느린 워크로드의 인스턴스와 동작 패턴의 상관성을 확인합니다.
- 사용 중인 데이터 저장소를 식별합니다. 각 데이터 원본에 대해 낮은 수준의 원격 분석을 실행하여 작업의 동작을 관찰합니다.
- 이러한 데이터 원본을 참조하는 느리게 실행되는 쿼리를 식별합니다.
- 느리게 실행되는 쿼리에 대해 리소스별 분석을 수행하고 데이터가 사용 및 소비되는 방법을 확인합니다.
다음과 같은 증상을 찾습니다.
- 동일한 리소스 또는 데이터 저장소에 대한 대규모 I/O 요청이 자주 발생합니다.
- 공유 리소스 또는 데이터 저장소의 경합.
- 네트워크를 통해 대용량의 데이터를 자주 수신하는 작업.
- I/O가 완료될 때까지 대기하면서 상당한 시간을 소비하는 애플리케이션 및 서비스.
예제 진단
다음 섹션은 이러한 단계를 앞의 예제에 적용합니다.
느린 워크로드 식별
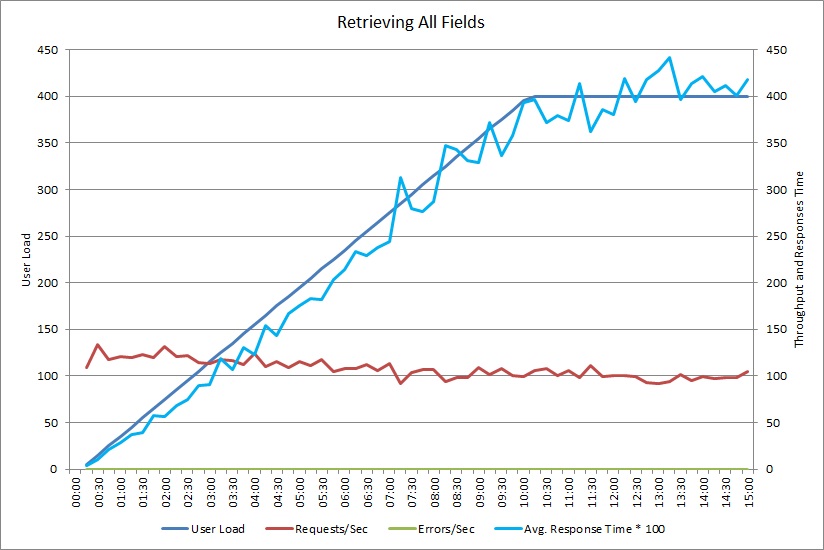
이 그래프는 앞에 나온 GetAllFieldsAsync 메서드를 실행하는 최대 400명의 동시 사용자를 시뮬레이션한 부하 테스트의 성능 결과를 보여 줍니다. 처리량은 부하가 증가함에 따라 서서히 줄어듭니다. 평균 응답 시간은 워크로드가 증가함에 따라 증가합니다.
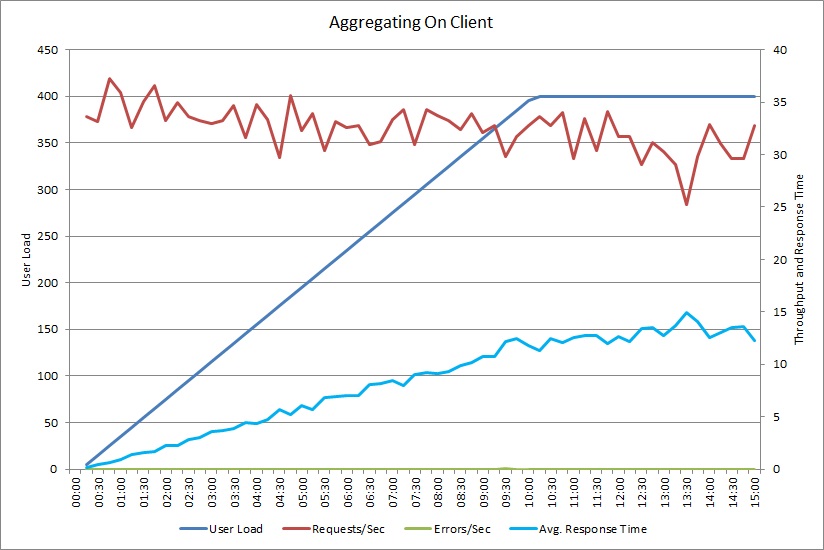
AggregateOnClientAsync 작업에 대한 부하 테스트도 유사한 패턴을 보여 줍니다. 요청의 양은 비교적 안정적입니다. 평균 응답 시간은 워크로드에 따라 증가하지만 이전 그래프보다 더 서서히 증가합니다.
느린 워크로드와 동작 패턴의 상관성을 확인합니다.
높은 사용량의 일반적인 기간과 느린 성능 간의 상관성을 확인하면 문제 영역이 나타날 수 있습니다. 느린 실행이 의심되는 기능의 성능 프로필을 면밀히 검토하여 앞서 수행한 부하 테스트와 일치하는지 여부를 결정합니다.
단계별 사용자 부하를 사용하여 동일한 기능을 부하 테스트하여 성능이 크게 저하되거나 완전히 장애를 일으키는 지점을 찾습니다. 해당 지점이 예상한 실제 사용률의 경계 이내인 경우 기능이 구현된 방법을 검사합니다.
시스템이 스트레스를 받을 때 수행되지 않고 시간에 민감하지 않고 다른 중요한 작업의 성능에 부정적인 영향을 미치지 않는다면 느린 작업이 반드시 문제인 것은 아닙니다. 예를 들어 월간 작업 통계 작성은 오래 실행되는 작업일 수 있지만 이 작업은 아마 일괄 처리 프로세스로 수행되고 낮은 우선 순위의 작업으로 실행될 수 있습니다. 반면에 제품 카탈로그를 쿼리하는 고객은 중요한 비즈니스 작업입니다. 이처럼 중요한 작업에서 생성된 원격 분석에 초점을 맞추고 사용량이 많은 기간 동안 성능이 어떻게 변화하는지 확인합니다.
느린 워크로드의 데이터 원본 식별
서비스가 데이터 검색 방법 때문에 성능이 저하되는 것으로 의심되는 경우 애플리케이션이 사용하는 리포지토리와 어떻게 상호작용하는지 조사합니다. 실시간 시스템을 모니터링하여 성능이 저하된 기간 동안 액세스되는 원본을 확인합니다.
각 데이터 원본에 대해 시스템을 계측하여 다음 정보를 수집합니다.
- 각 데이터 저장소가 액세스되는 빈도.
- 데이터 저장소에 들어오고 나가는 데이터의 양.
- 이러한 작업의 타이밍, 특히 요청의 대기 시간.
- 전형적인 부하에서 각 데이터 저장소에 액세스하는 동안 발생하는 오류의 특성 및 비율.
이 정보를 애플리케이션에서 클라이언트에 반환하는 데이터의 양과 비교합니다. 데이터 저장소에서 반환하는 데이터 양과 클라이언트에 반환되는 데이터 양의 비율을 추적합니다. 큰 차이가 있는 경우 애플리케이션이 필요하지 않은 데이터를 가져오는지 여부를 조사하여 결정합니다.
실시간 시스템을 관찰하고 각 사용자 요청의 수명 주기를 추적하면 이 데이터를 포착할 수 있습니다. 또는 일련의 합성 워크로드를 모델링하고 테스트 시스템에 대해 실행할 수 있습니다.
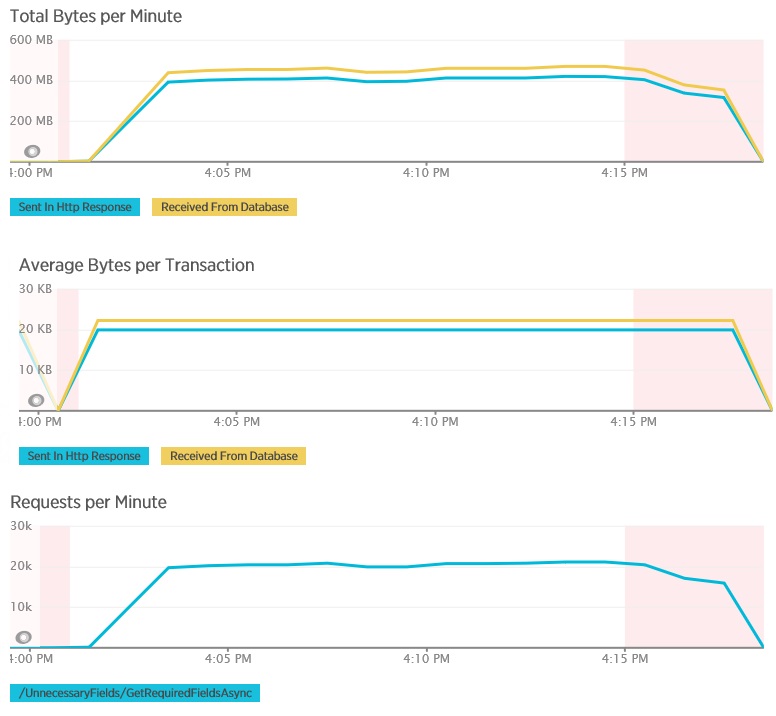
다음 그래프에서는 GetAllFieldsAsync 메서드의 부하 테스트 중에 New Relic APM을 사용하여 캡처한 원격 분석을 보여 줍니다. 데이터베이스에서 수신된 데이터 양과 해당 HTTP 응답 간의 차이에 주목합니다.
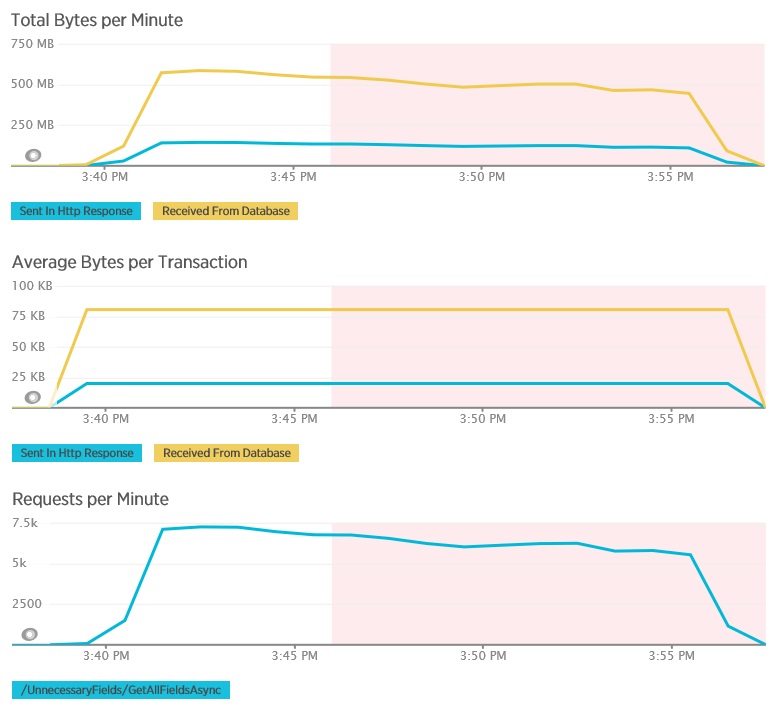
각 요청에 대해 데이터는 80,503바이트를 반환했지만 클라이언트에 대한 응답은 19,855바이트만 포함했으며, 이는 데이터베이스 응답 크기의 약 25%에 해당합니다. 클라이언트에서 반환되는 데이터의 크기는 형식에 따라 달라질 수 있습니다. 이 부하 테스트의 경우 클라이언트는 JSON 데이터를 요청했습니다. XML(표시되지 않음)을 사용한 별도의 테스트에서는 응답 크기가 35,655바이트였으며, 이는 데이터베이스 응답 크기의 44%에 해당합니다.
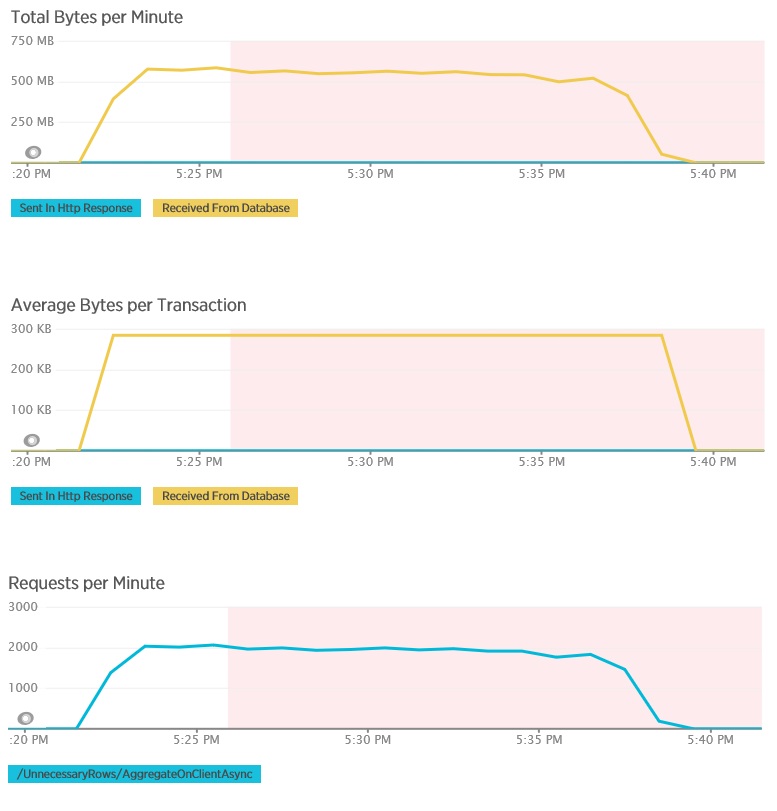
AggregateOnClientAsync 메서드에 대한 부하 테스트는 더 극단적인 결과를 보여 줍니다. 이 경우 각 테스트는 데이터베이스에서 280Kb가 넘는 데이터를 검색하는 쿼리를 수행했지만 JSON 응답은 불과 14바이트였습니다. 이처럼 큰 차이는 해당 메서드가 대량의 데이터에서 집계한 결과를 계산하기 때문입니다.
느린 쿼리 식별 및 분석
가장 많은 리소스를 사용하고 실행 시간이 가장 오래 걸리는 데이터베이스 쿼리를 찾습니다. 많은 데이터베이스 작업에 대한 시작 및 완료 시간을 찾는 계측을 추가할 수 있습니다. 또한 많은 데이터 저장소는 쿼리가 수행되고 최적화되는 방법에 관한 심층 정보를 제공합니다. 예를 들어 Azure SQL Database 관리 포털의 쿼리 성능 창에서 쿼리를 선택하고 자세한 런타임 성능 정보를 볼 수 있습니다. 다음은 GetAllFieldsAsync 작업에서 생성된 쿼리입니다.
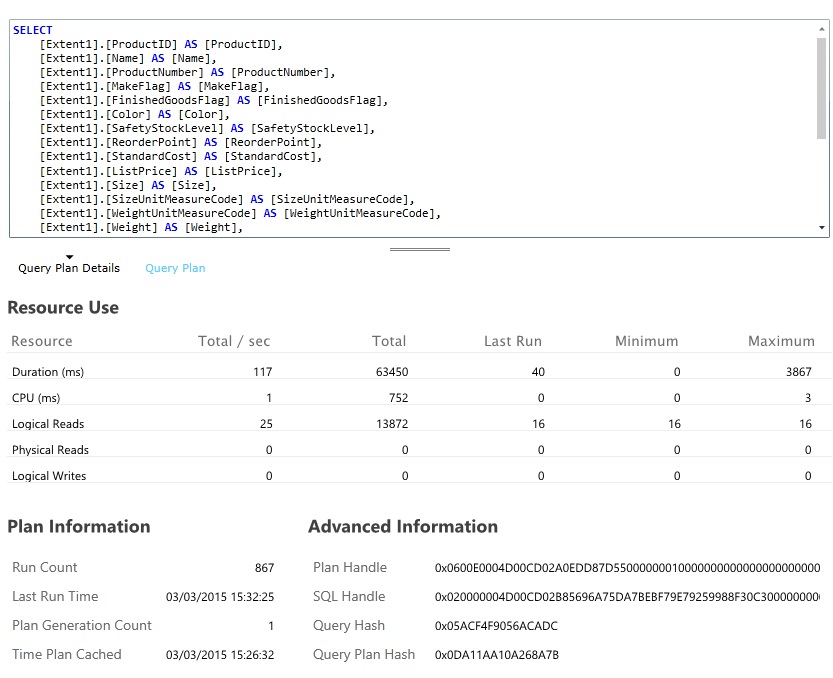
솔루션 구현 및 결과 확인
GetRequiredFieldsAsync 메서드를 데이터베이스 쪽의 SELECT 문을 사용하도록 변경하면 부하 테스트에서 다음과 같은 결과를 표시했습니다.
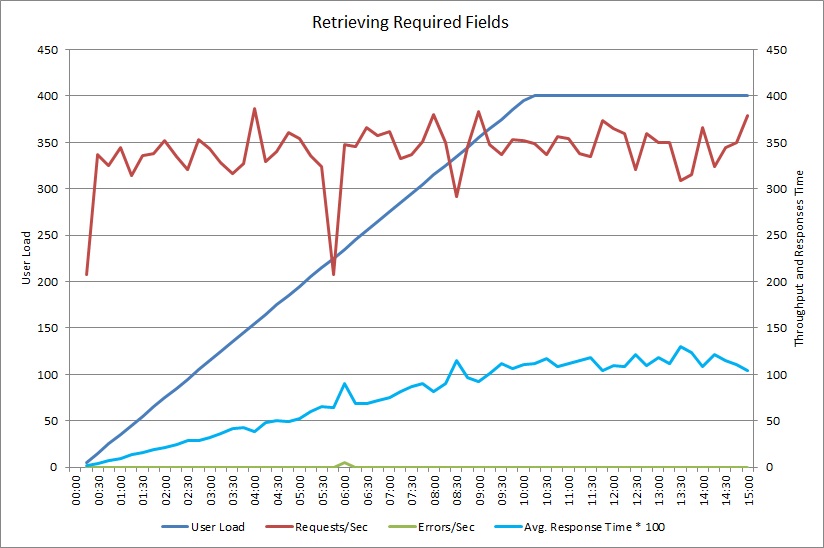
이 부하 테스트는 전과 동일한 배포 및 동시 사용자 수 400명의 동일한 시뮬레이션 워크로드를 사용했습니다. 그래프가 훨씬 더 낮은 대기 시간을 표시합니다. 응답 시간은 부하에 따라 약 1.3초까지 증가하며, 이는 앞의 경우 4초와 비교하여 더 짧습니다. 처리량도 이전의 초당 요청 100개에 비해 350개로 더 높습니다. 데이터베이스에 검색된 데이터 양은 이제 HTTP 응답 메시지의 크기와 거의 일치합니다.
AggregateOnDatabaseAsync 메서드를 사용한 부하 테스트에서 다음 결과를 생성합니다.
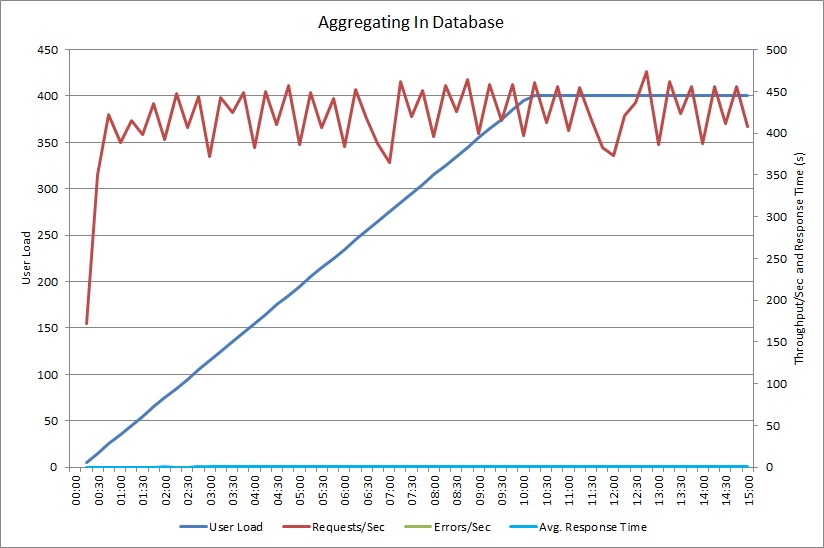
이제 평균 응답 시간이 최소화되었습니다. 이는 주로 데이터베이스에서의 I/O가 대폭 감소했기 때문에 성능이 크게 개선된 결과입니다.
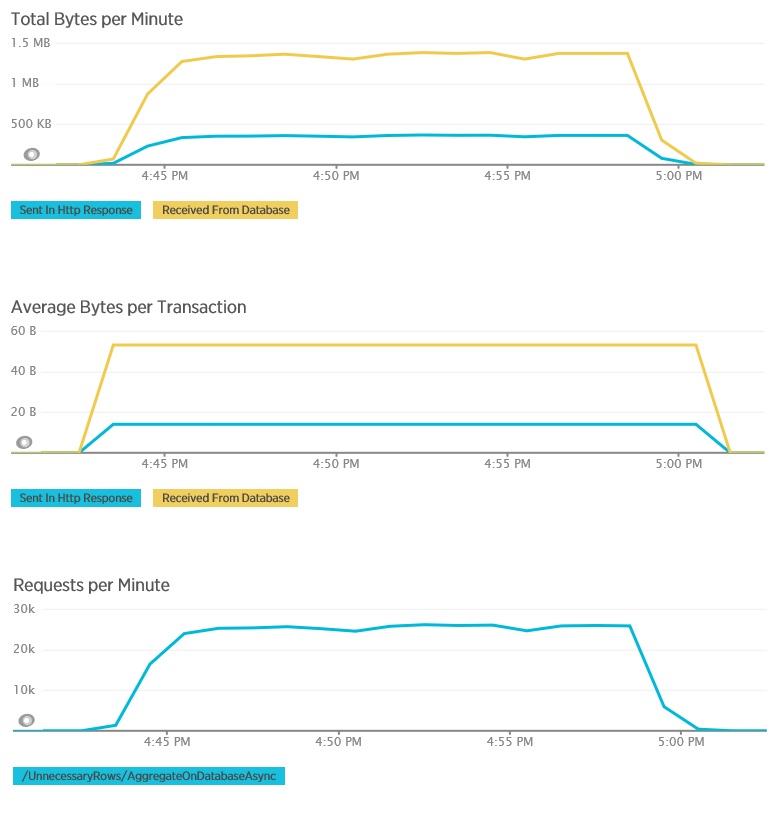
다음은 AggregateOnDatabaseAsync 메서드에 대한 해당 원격 분석 데이터입니다. 데이터베이스에서 검색한 데이터의 양은 트랜잭션당 280Kb 이상에서 53바이트로 대폭 감소했습니다. 결과적으로 분당 최대 지속 요청 수는 약 2,000에서 25,000 이상으로 증가했습니다.
관련 참고 자료
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기