데이터 레이크는 대량의 데이터를 네이티브, 원시 형식으로 보관하는 스토리지 리포지토리입니다. 데이터 레이크 저장소는 크기가 테라바이트 및 페타바이트 데이터로 크기 조정되도록 최적화되어 있습니다. 데이터는 일반적으로 여러 다양한 원본에서 제공되며 구조적, 반구조적 또는 비구조적 데이터를 포함할 수 있습니다. 데이터 레이크를 사용하면 모든 항목을 원래의 변형되지 않은 상태로 저장할 수 있습니다. 이 메서드는 수집 시 데이터를 변환하고 처리하는 기존 데이터 웨어하우스와 다릅니다.
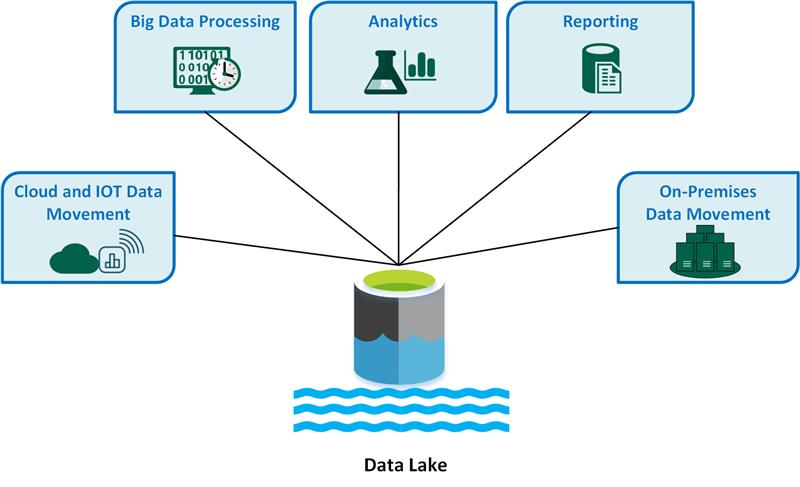
주요 데이터 레이크 사용 사례는 다음과 같습니다.
- 클라우드 및 IoT(사물 인터넷) 데이터 이동
- 빅 데이터 처리.
- 분석.
- 보고.
- 온-프레미스 데이터 이동.
데이터 레이크의 다음과 같은 장점을 고려합니다.
데이터 레이크는 원시 형식으로 데이터를 저장하기 때문에 데이터를 삭제하지 않습니다. 이 기능은 데이터에서 얻을 수 있는 인사이트를 미리 알 수 없기 때문에 빅 데이터 환경에서 특히 유용합니다.
사용자는 데이터를 탐색하고 직접 쿼리를 만들 수 있습니다.
데이터 레이크는 기존의 ETL(추출, 변환, 로드) 도구보다 더 빠를 수 있습니다.
데이터 레이크는 비정형 및 반구조화된 데이터를 저장할 수 있으므로 데이터 웨어하우스보다 더 유연합니다.
완전한 데이터 레이크 솔루션은 스토리지과 처리로 구성됩니다. Data Lake Storage는 다양한 셰이프 및 데이터 크기의 내결함성, 무한 확장성 및 높은 처리량 수집을 위해 설계되었습니다. 데이터 레이크 처리에는 이러한 목표를 통합할 수 있고 대규모 데이터 레이크에 저장된 데이터에 대해 작동할 수 있는 하나 이상의 처리 엔진이 포함됩니다.
데이터 레이크를 사용해야 하는 경우
데이터 탐색, 데이터 분석 및 기계 학습에 데이터 레이크를 사용하는 것이 좋습니다.
데이터 레이크는 데이터 웨어하우스의 데이터 원본 역할을 할 수 있습니다. 이 메서드를 사용하는 경우 Data Lake는 원시 데이터를 수집한 다음 구조화된 쿼리 가능한 형식으로 변환합니다. 일반적으로 이 변환은 데이터를 수집 및 변환하는 ELT(추출, 로드, 변환) 파이프라인을 사용합니다. 관계형 원본 데이터는 ETL 프로세스를 통해 데이터 웨어하우스로 직접 이동하여 데이터 레이크를 건너뛸 수 있습니다.
데이터 레이크는 변환 또는 스키마 정의 없이 많은 양의 관계형 및 비관계형 데이터를 유지할 수 있으므로 이벤트 스트리밍 또는 IoT 시나리오에서 데이터 레이크 저장소를 사용할 수 있습니다. 데이터 레이크는 짧은 대기 시간에 대량의 작은 쓰기를 처리할 수 있으며 대규모 처리량에 최적화되어 있습니다.
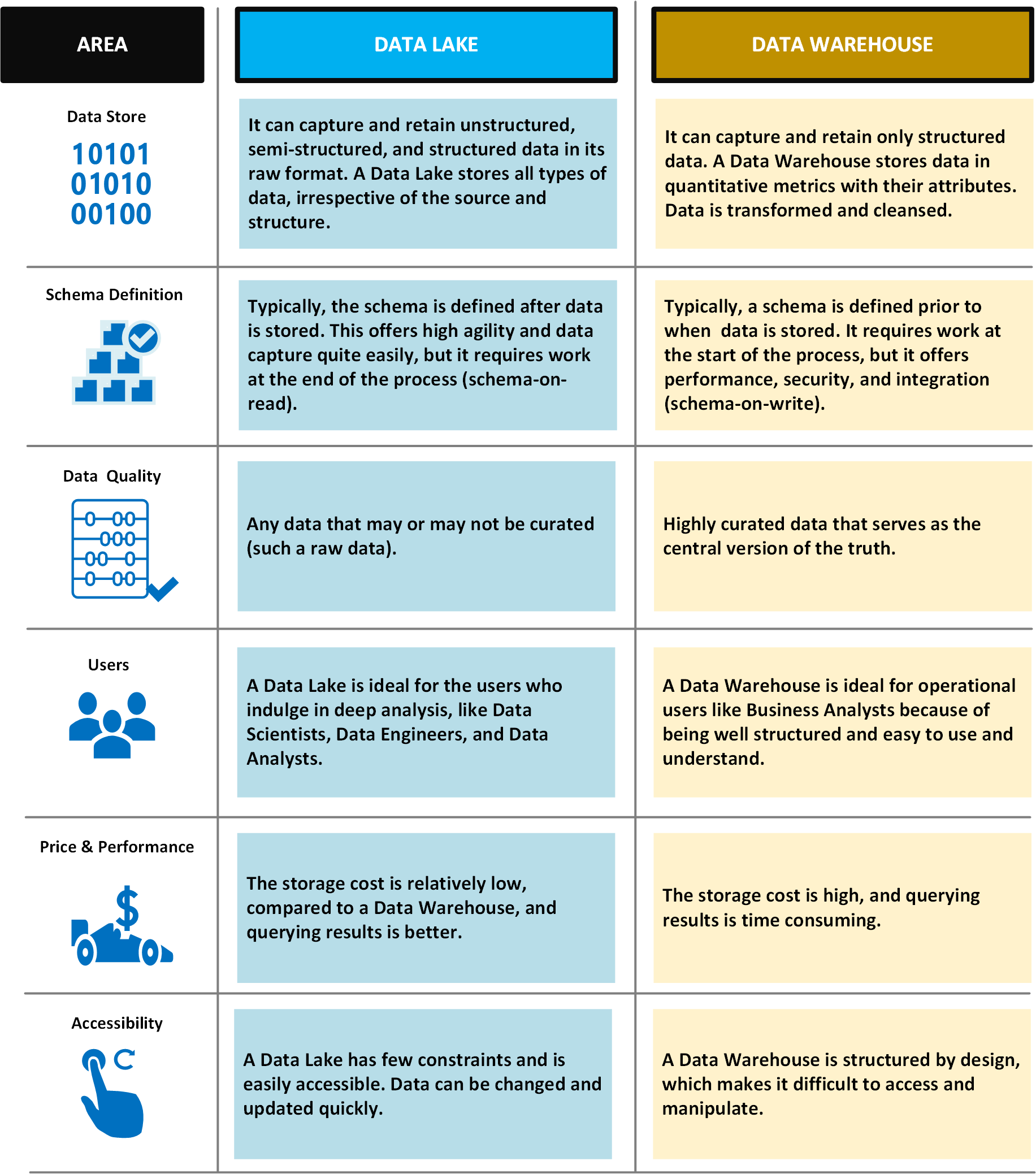
다음 표에서는 데이터 레이크와 데이터 웨어하우스를 비교합니다.
과제
대량의 데이터: 방대한 양의 원시 및 비정형 데이터를 관리하는 것은 복잡하고 리소스 집약적일 수 있으므로 강력한 인프라와 도구가 필요합니다.
잠재적인 병목 상태: 데이터 처리는 특히 많은 양의 데이터와 다양한 데이터 형식이 있는 경우 지연 및 비효율성을 초래할 수 있습니다.
데이터 손상 위험: 부적절한 데이터 유효성 검사 및 모니터링은 데이터 손상의 위험을 초래하여 데이터 레이크의 무결성을 손상시킬 수 있습니다.
품질 관리 문제: 다양한 데이터 원본 및 형식으로 인해 적절한 데이터 품질이 어려운 문제입니다. 엄격한 데이터 거버넌스 사례를 구현해야 합니다.
성능 문제: 데이터 레이크가 증가함에 따라 쿼리 성능이 저하되어 스토리지 및 처리 전략을 최적화해야 합니다.
기술 선택
Azure에서 포괄적인 Data Lake 솔루션을 빌드하는 경우 다음 기술을 고려합니다.
Azure Data Lake Storage 는 Azure Blob Storage와 데이터 레이크 기능을 결합하여 Apache Hadoop 호환 액세스, 계층 구조 네임스페이스 기능 및 효율적인 빅 데이터 분석을 위한 향상된 보안을 제공합니다.
Azure Databricks 는 데이터를 처리, 저장, 분석 및 수익을 창출하는 데 사용할 수 있는 통합 플랫폼입니다. ETL 프로세스, 대시보드, 보안, 데이터 탐색, 기계 학습 및 생성 AI를 지원합니다.
Azure Synapse Analytics 는 즉각적인 비즈니스 인텔리전스 및 기계 학습 요구 사항에 맞게 데이터를 수집, 탐색, 준비, 관리 및 제공하는 데 사용할 수 있는 통합 서비스입니다. 대규모 데이터 세트를 효율적으로 쿼리하고 분석할 수 있도록 Azure 데이터 레이크와 긴밀하게 통합됩니다.
Azure Data Factory 는 데이터 기반 워크플로를 만든 다음 데이터 이동 및 변환을 오케스트레이션하고 자동화하는 데 사용할 수 있는 클라우드 기반 데이터 통합 서비스입니다.
Microsoft Fabric 은 데이터 엔지니어링, 데이터 과학, 데이터 웨어하우징, 실시간 분석 및 비즈니스 인텔리전스를 단일 솔루션으로 통합하는 포괄적인 데이터 플랫폼입니다.
기여자
Microsoft에서 이 문서를 유지 관리합니다. 원래 다음 기여자가 작성했습니다.
주요 작성자
- Avijit Prasad | 클라우드 컨설턴트
비공개 LinkedIn 프로필을 보려면 LinkedIn에 로그인합니다.
다음 단계
- OneLake란?
- Data Lake Storage 소개
- Azure Data Lake Analytics 설명서
- 교육: Data Lake Storage 소개
- Hadoop 및 Azure Data Lake Storage 통합
- Data Lake Storage 및 Blob Storage에 연결
- Azure Data Factory를 사용하여 Data Lake Storage에 데이터 로드