이 참조 아키텍처에서는 Azure Databricks를 사용하여 추천 모델을 학습시킨 다음, Azure Cosmos DB, Azure Machine Learning, AKS(Azure Kubernetes Service)를 사용하여 API로 배포하는 방법을 보여줍니다. 이 아키텍처의 참조 구현은 GitHub 에서 실시간 권장 사항 API 빌드를 참조하세요.
아키텍처
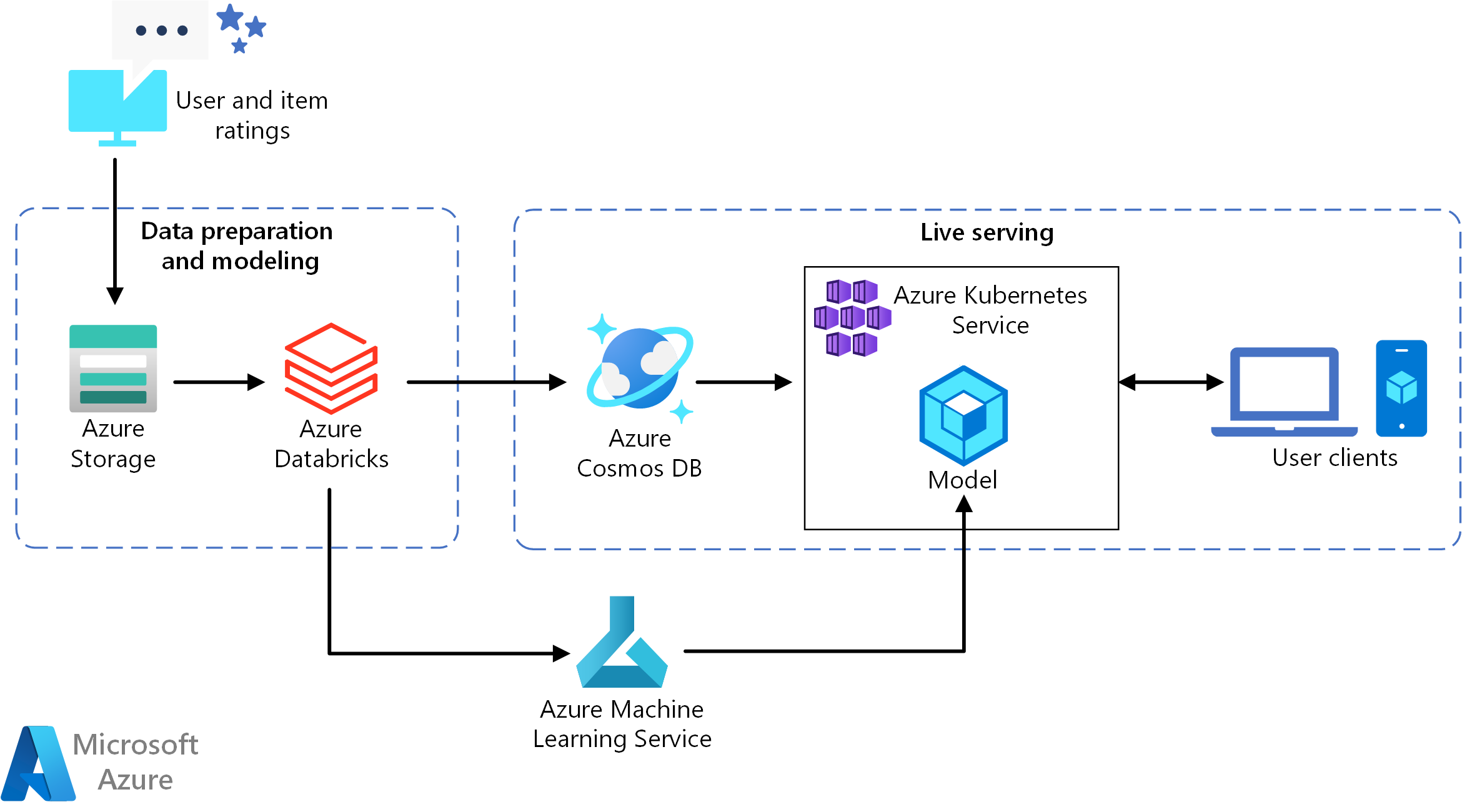
이 아키텍처의 Visio 파일을 다운로드합니다.
이 참조 아키텍처는 사용자에게 상위 10개의 동영상 추천을 제공할 수 있는 실시간 추천 서비스 API를 학습시키고 배포하는 데 사용됩니다.
데이터 흐름
- 사용자 동작을 추적합니다. 예를 들어, 사용자가 동영상을 평가하거나 제품 또는 뉴스 기사를 클릭할 때 백 엔드 서비스가 이를 기록할 수 있습니다.
- 사용 가능한 데이터 원본에서 Azure Databricks로 데이터를 로드합니다.
- 데이터를 준비하고 학습 및 테스트 집합으로 분할하여 모델을 학습시킵니다. (이 가이드에서는 데이터 분할 옵션을 설명합니다.)
- Spark Collaborative Filtering 모델을 데이터에 맞춥니다.
- 등급 및 순위 메트릭을 사용하여 모델의 품질을 평가합니다. 이 가이드에서는 추천 시스템을 평가하는 데 기준으로 사용할 수 있는 메트릭에 대한 세부 정보를 제공합니다.
- 사용자별 상위 10개 추천 항목을 미리 계산하고 Azure Cosmos DB에 캐시로 저장합니다.
- API를 컨테이너화하고 배포하는 Machine Learning API를 사용하여 AKS에 API 서비스를 배포합니다.
- 백 엔드 서비스가 사용자로부터 요청을 받으면 AKS에서 호스팅되는 추천 API를 호출하여 상위 10개 추천 항목을 가져와 사용자에게 표시합니다.
구성 요소
- Azure Databricks. Databricks는 입력 데이터를 준비하고 추천 모델에게 Spark 클러스터를 학습시키는 데 사용되는 개발 환경입니다. Azure Databricks는 또한 데이터 처리 또는 기계 학습 작업을 위해 노트북에서 실행하고 공동 작업을 수행할 수 있는 대화형 작업 영역을 제공합니다.
- AKS(Azure Kubernetes Service). AKS는 Kubernetes 클러스터에서 기계 학습 모델 서비스 API를 배포하고 운영하는 데 사용됩니다. AKS는 컨테이너화된 모델을 호스팅하고, 처리량 요구 사항에 맞는 확장성, ID 및 액세스 관리, 로깅 및 상태 모니터링을 제공합니다.
- Azure Cosmos DB. Azure Cosmos DB는 각 사용자를 위한 상위 10개 추천 동영상을 저장하는 데 사용되는 글로벌 분산 데이터베이스 서비스입니다. Azure Cosmos DB는 특정 사용자를 위한 상위 추천 항목을 읽을 때 대기 시간이 짧으므로(99%의 확률로 10ms) 이러한 시나리오에 매우 적합합니다.
- 기계 학습. 이 서비스는 기계 학습 모델을 추적 및 관리하고, 이러한 모델을 패키징하여 확장 가능한 AKS 환경에 배포하는 데 사용됩니다.
- Microsoft 추천 시스템. 이 오픈 소스 리포지토리에는 사용자가 추천 시스템 빌드, 평가, 운영을 시작하는 데 도움이 되는 유틸리티 코드와 샘플이 포함되어 있습니다.
시나리오 정보
이 아키텍처는 제품, 동영상, 뉴스 추천 등 대부분의 추천 엔진 시나리오에 맞게 일반화할 수 있습니다.
잠재적인 사용 사례
시나리오: 한 미디어 조직에서 사용자에게 동영상 추천을 제공하려고 합니다. 이 조직에서는 개인 맞춤형 추천을 제공하여 클릭률 증가, 웹 사이트 참여 증가, 사용자 만족도 증가를 포함한 몇 가지 비즈니스 목표를 충족합니다.
이 솔루션은 소매업, 미디어 및 엔터테인먼트 산업에 최적화되어 있습니다.
고려 사항
이러한 고려 사항은 워크로드의 품질을 향상시키는 데 사용할 수 있는 일단의 지침 원칙인 Azure Well-Architected Framework의 핵심 요소를 구현합니다. 자세한 내용은 Microsoft Azure Well-Architected Framework를 참조하세요.
Azure Databricks에서 Spark 모델의 채점 일괄 처리는 Spark 및 Azure Databricks를 사용하여 예약된 채점 일괄 처리 프로세스를 실행하는 참조 아키텍처를 설명합니다. 새 권장 사항을 생성하려면 이 방법을 사용하는 것이 좋습니다.
성능 효율성
성능 효율성은 사용자가 배치된 요구 사항을 효율적인 방식으로 충족하기 위해 워크로드의 크기를 조정할 수 있는 기능입니다. 자세한 내용은 성능 효율성 핵심 요소 개요를 참조하세요.
실시간 추천 항목에서 성능은 주된 고려 사항입니다. 추천 항목은 일반적으로 웹 사이트에서 사용자 요청의 중요 경로에 속하기 때문입니다.
AKS와 Azure Cosmos DB의 조합은 이러한 아키텍처가 최소한의 오버헤드로 중간 규모 워크로드에 추천 항목을 제공하는 데 좋은 시작점이 되도록 합니다. 동시 사용자가 200명인 부하 테스트에서 이 아키텍처는 약 60ms의 평균 대기 시간으로 추천 항목을 제공하고, 초당 180개 요청을 처리할 수 있습니다. 이 부하 테스트는 기본 배포 구성(Azure Cosmos DB용으로 프로비전된 vCPU 12개, 메모리 42GB, 초당 요청 단위(RU) 11,000개를 지원하는 D3 v2 AKS 클러스터 3개)을 대상으로 실행되었습니다.
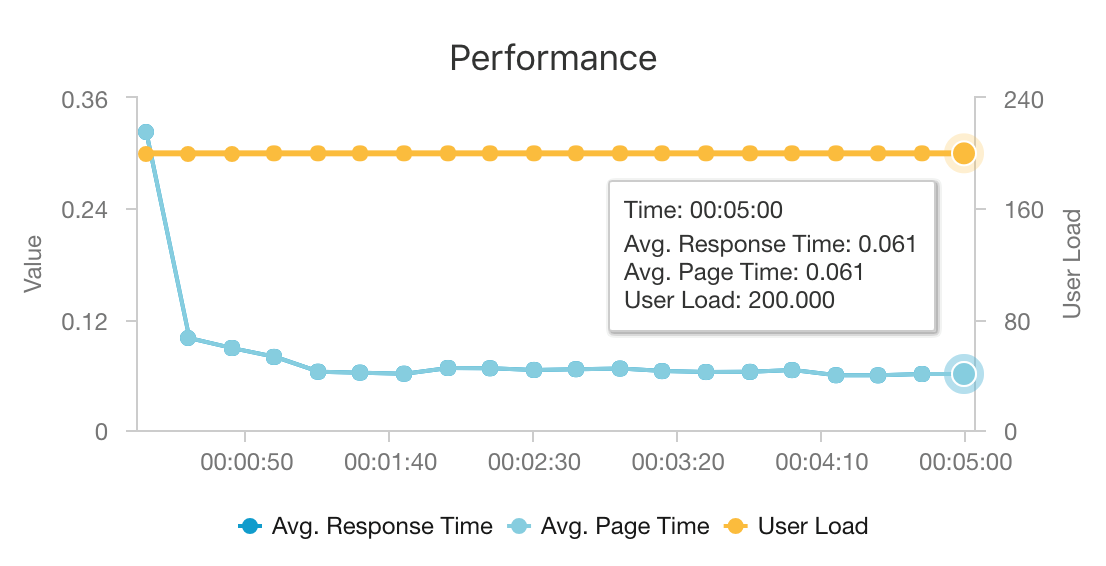
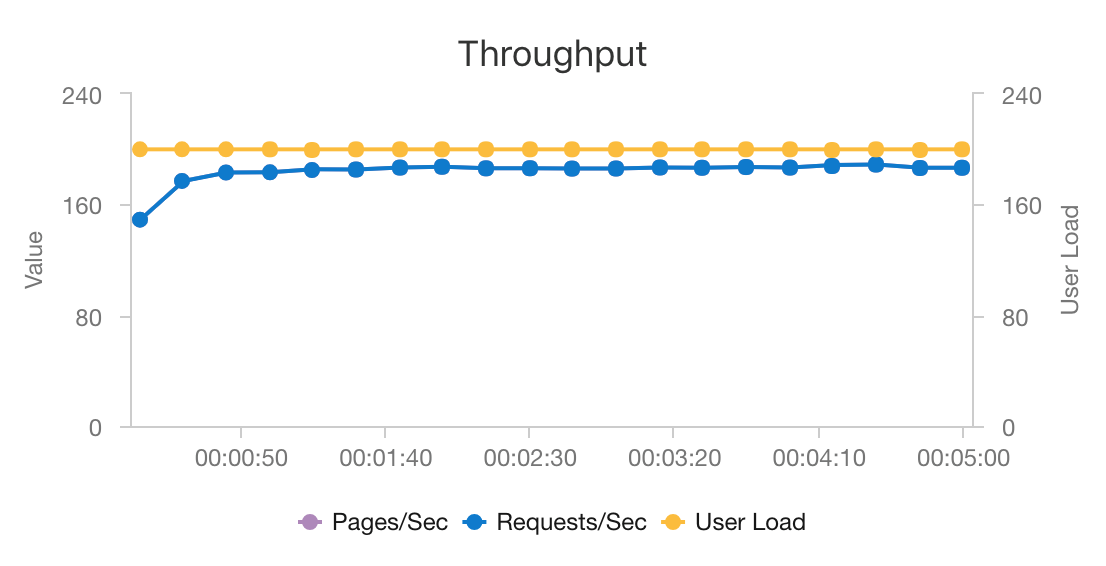
Azure Cosmos DB는 턴키 글로벌 배포 및 앱의 모든 데이터베이스 요구 사항을 충족하는 유용성 때문에 권장됩니다. 대기 시간을 약간 줄이려면 Azure Cosmos DB 대신 Azure Cache for Redis를 사용하여 조회를 제공하는 것이 좋습니다. Azure Cache for Redis는 백 엔드 저장소의 데이터에 크게 의존하는 시스템의 성능을 개선할 수 있습니다.
확장성
Spark를 사용할 계획이 없거나 분산이 필요 없는 소규모 워크로드를 보유하고 있을 경우 Azure Databricks 대신 DSVM(Data Science Virtual Machine)을 사용하는 것이 좋습니다. DSVM은 기계 학습 및 데이터 과학을 위한 딥 러닝 프레임워크 및 도구를 사용하는 Azure 가상 머신입니다. Azure Databricks와 마찬가지로 DSVM에서 만든 모델도 Machine Learning을 통해 AKS에서 서비스로 운영할 수 있습니다.
학습 중에는 Azure Databricks에 대규모 고정 크기의 Spark 클러스터를 프로비전하거나 자동 크기 조정을 구성합니다. 자동 크기 조정을 사용할 경우 Databricks가 클러스터의 부하를 모니터링하고 필요 시 규모를 확장하거나 축소합니다. 대규모의 데이터가 있고 데이터 준비나 모델링 작업에 걸리는 시간을 줄이려는 경우 대규모 클러스터를 프로비전하거나 확장하세요.
성능 및 처리량 요구 사항에 맞게 AKS 클러스터를 확장하세요. 클러스터를 완전히 활용할 수 있게 Pod 수를 확장하고, 서비스의 필요에 맞게 클러스터의 노드를 확장하도록 유의하세요. AKS 클러스터에서 자동 크기 조정을 설정할 수도 있습니다. 자세한 내용은 Deploy a model to an Azure Kubernetes Service cluster(Azure Kubernetes Service 클러스터에 모델 배포)를 참조하세요.
Azure Cosmos DB 성능을 관리하려면 초당 필요한 읽기 수를 측정하고, 필요한 초당 RU 수(처리량)를 프로비전하세요. 분할 및 수평 확장에 대한 모범 사례를 따르세요.
비용 최적화
비용 최적화는 불필요한 비용을 줄이고 운영 효율성을 높이는 방법을 찾는 것입니다. 자세한 내용은 비용 최적화 핵심 요소 개요를 참조하세요.
이 시나리오의 주요 비용 동인은 다음과 같습니다.
- 학습에 필요한 Azure Databricks 클러스터 크기.
- 성능 요구 사항을 충족하는 데 필요한 AKS 클러스터 크기.
- 성능 요구 사항에 맞게 프로비전된 Azure Cosmos DB RU.
Spark 클러스터를 사용하지 않을 때 자주 재학습시키지 않고 끄는 방법으로 Azure Databricks 비용을 관리하세요. AKS 및 Azure Cosmos DB 비용은 사이트의 처리량 및 성능 요구 사항과 관련이 있으며, 사이트로 들어오는 트래픽의 양에 따라 확장 및 축소됩니다.
시나리오 배포
이 아키텍처를 배포하려면 설치 문서의 Azure Databricks 지침을 따릅니다. 간단히 설명하면 지침에 따라 다음을 수행해야 합니다.
- Azure Databricks 작업 영역 만들기
- Azure Databricks에서 다음 구성을 사용하여 새 클러스터를 만듭니다.
- 클러스터 모드: 표준
- Databricks Runtime 버전: 4.3(Apache Spark 2.3.1, Scala 2.11 포함)
- Python 버전: 3
- 드라이버 유형: Standard_DS3_v2
- 작업자 유형: Standard_DS3_v2(필요한 경우 최소 및 최대)
- 자동 종료: (필요에 따라)
- Spark 구성: (필요에 따라)
- 환경 변수: (필요에 따라)
- Azure Databricks 작업 영역 내에서 개인용 액세스 토큰을 만듭니다. 자세한 내용은 Azure Databricks 인증 설명서를 참조하세요.
- 스크립트(예: 로컬 컴퓨터)를 실행할 수 있는 환경에 Microsoft Recommenders 리포지토리를 복제합니다.
- 빠른 설치 설치 지침에 따라 Azure Databricks에 관련 라이브러리를 설치합니다.
- 빠른 설치 설치 지침에 따라 운영화를 위해 Azure Databricks를 준비합니다.
- ALS Movie Operationalization Notebook을 작업 영역으로 가져옵니다. Azure Databricks 작업 영역에 로그인한 후 다음을 수행합니다.
- 작업 영역 왼쪽에서 홈을 클릭합니다.
- 홈 디렉터리에서 공백을 마우스 오른쪽 단추로 클릭합니다. 가져오기를 선택합니다.
- URL을 선택하고 다음을
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb텍스트 필드에 붙여넣습니다. - 가져오기를 클릭합니다.
- Azure Databricks 내에서 Notebook을 열고 구성된 클러스터를 연결합니다.
- Notebook을 실행하여 특정 사용자를 위한 상위 10개 동영상 추천 항목을 제공하는 추천 API를 만드는 데 필요한 Azure 리소스를 만듭니다.
참가자
Microsoft에서 이 문서를 유지 관리합니다. 원래 다음 기여자가 작성했습니다.
주요 작성자:
- Miguel Fierro | 수석 데이터 과학자 관리자
- Nikhil Joglekar | 제품 관리자, Azure 알고리즘 및 데이터 과학
비공개 LinkedIn 프로필을 보려면 LinkedIn에 로그인합니다.
다음 단계
- 실시간 추천 API 빌드
- Azure Databricks란?
- Azure Kubernetes Service
- Azure Cosmos DB 시작
- Azure Machine Learning이란 무엇인가요?