v1을 사용하여 Azure Kubernetes Service 클러스터에 모델 배포
Important
이 문서에서는 Azure Machine Learning CLI(v1) 및 Python용 Azure Machine Learning SDK(v1)를 사용하여 모델을 배포하는 방법을 설명합니다. v2에 권장되는 방법은 온라인 엔드포인트를 사용하여 기계 학습 모델 배포 및 점수 매기기를 참조하세요.
Azure Machine Learning을 사용하여 AKS(Azure Kubernetes Service)에서 모델을 웹 서비스로 배포하는 방법을 알아봅니다. AKS는 대규모 프로덕션 배포에 적합합니다. 다음 기능 중 하나 이상이 필요한 경우 AKS를 사용합니다.
- 빠른 응답 시간
- 배포 서비스 자동 스케일링
- 로깅
- 모델 데이터 수집
- 인증
- TLS 종료
- 하드웨어 가속 옵션, 예: GPU 및 FPGA(필드 프로그래머블 게이트 어레이)
AKS에 배포할 때 작업 영역에 연결된 AKS 클러스터에 배포합니다. AKS 클러스터를 작업 영역에 연결하는 방법에 대한 자세한 내용은 Azure Kubernetes Service 클러스터 만들기 및 연결을 참조하세요.
Important
웹 서비스에 배포하기 전에 로컬에서 디버그하는 것이 좋습니다. 자세한 내용은 로컬 모델 배포 문제 해결을 참조하세요.
참고 항목
Azure Machine Learning 엔드포인트(v2)는 더 간단하고 향상된 배포 환경을 제공합니다. 엔드포인트는 실시간 및 일괄 처리 유추 시나리오를 둘 다 지원합니다. 엔드포인트는 컴퓨팅 유형 간에 모델 배포를 호출하고 관리할 수 있는 통합 인터페이스를 제공합니다. Azure Machine Learning 엔드포인트란?을 참조하세요.
필수 조건
Azure Machine Learning 작업 영역 자세한 내용은 Azure Machine Learning 작업 영역 만들기를 참조하세요.
작업 영역에 등록된 기계 학습 모델. 등록된 모델이 없는 경우 Azure에 기계 학습 모델 배포를 참조하세요.
Machine Learning Service에 대한 Azure CLI 확장(v1), Azure Machine Learning Python SDK 또는 Azure Machine Learning Visual Studio Code 확장.
Important
이 문서의 일부 Azure CLI 명령에서는
azure-cli-ml또는 v1(Azure Machine Learning용 확장)을 사용합니다. v1 확장에 대한 지원은 2025년 9월 30일에 종료됩니다. v1 확장은 이 날짜까지 설치하고 사용할 수 있습니다.2025년 9월 30일 이전에
ml또는 v2 확장으로 전환하는 것이 좋습니다. v2 확장에 대한 자세한 내용은 Azure ML CLI 확장 및 Python SDK v2를 참조하세요.이 문서의 Python 코드 조각에서는 다음 변수가 설정되었다고 가정합니다.
ws- 작업 영역으로 설정.model- 등록된 모델로 설정.inference_config- 모델에 대한 유추 구성으로 설정.
이러한 변수를 설정하는 방법에 대한 자세한 내용은 모델을 배포하는 방법 및 위치를 참조하세요.
이 문서의 CLI 코드 조각은 이미 inferenceconfig.json 문서를 만들었다고 가정합니다. 이 문서를 만드는 방법에 대한 자세한 내용은 Azure에 기계 학습 모델 배포를 참조하세요.
작업 영역에 연결된 AKS 클러스터. 자세한 내용은 Azure Kubernetes Service 클러스터 만들기 및 연결을 참조하세요.
- GPU 노드 또는 FPGA 노드(또는 특정 제품)에 모델을 배포하려면 특정 제품을 사용하여 클러스터를 만들어야 합니다. 보조 노드 풀을 기존 클러스터에 만들고 모델을 이 보조 노드 풀에 배포하는 것은 지원되지 않습니다.
배포 프로세스 이해
배포라는 단어는 Kubernetes와 Azure Machine Learning 모두에 사용됩니다. 이러한 두 가지 컨텍스트에서 배포의 의미는 다릅니다. Kubernetes에서 배포는 구체적인 엔터티이며, 선언적 YAML 파일을 사용하여 지정됩니다. Kubernetes 배포에는 정의된 수명 주기 및 다른 Kubernetes 엔터티(예: Pods 및 ReplicaSets)와의 구체적인 관계가 있습니다. Kubernetes란?의 문서와 비디오를 통해 Kubernetes에 대해 자세히 알아볼 수 있습니다.
Azure Machine Learning에서 "배포"는 프로젝트 리소스를 제공하고 정리하는 보다 일반적인 의미로 사용됩니다. Azure Machine Learning에서 배포의 일부로 간주되는 단계는 다음과 같습니다.
- 프로젝트 폴더에 파일 압축(.amlignore 또는 .gitignore에 지정된 항목 무시)
- 컴퓨팅 클러스터 스케일 업(Kubernetes 관련)
- dockerfile을 컴퓨팅 노드로 다운로드 또는 빌드(Kubernetes 관련)
- 시스템에서 다음 해시가 계산됩니다.
- 기본 이미지
- 사용자 지정 docker 단계(사용자 지정 Docker 기본 이미지를 사용하여 모델 배포 참조)
- conda 정의 YAML (Azure Machine Learning에서 소프트웨어 환경 만들기 및 사용 참조)
- 시스템은 작업 영역 ACR(Azure Container Registry) 조회에서 이 해시를 키로 사용합니다.
- 찾을 수 없는 경우 전역 ACR에서 일치하는 항목을 찾습니다.
- 찾을 수 없는 경우 시스템은 캐시되고 작업 영역 ACR에 푸시되는 새 이미지를 빌드합니다.
- 시스템에서 다음 해시가 계산됩니다.
- 압축된 프로젝트 파일을 컴퓨팅 노드의 임시 스토리지에 다운로드
- 프로젝트 파일 압축 풀기
python <entry script> <arguments>를 실행하는 컴퓨팅 노드- ./outputs에 기록된 로그, 모델 파일 및 기타 파일을 작업 영역과 연결된 스토리지 계정에 저장
- 컴퓨팅 스케일 다운(임시 스토리지 제거 포함)(Kubernetes 관련)
Azure Machine Learning 라우터
들어오는 유추 요청을 배포된 서비스로 라우팅하는 프런트 엔드 구성 요소(azureml-fe)는 필요에 따라 자동으로 스케일링됩니다. azureml-fe의 스케일링은 AKS 클러스터 용도 및 크기(노드 수)에 기반합니다. 클러스터 용도 및 노드는 AKS 클러스터를 만들거나 연결할 때 구성됩니다. azureml-fe 서비스는 클러스터당 하나이며, 여러 Pod에서 실행될 수 있습니다.
Important
dev-test(으)로 구성된 클러스터를 사용하는 경우 자체 스케일러를 사용하지 않도록 설정됩니다. FastProd/DenseProd 클러스터의 경우에도 Self-Scaler는 원격 분석에 필요한 것으로 표시될 때만 사용하도록 설정됩니다.- Azure Machine Learning은 시스템 컨테이너를 포함하여 컨테이너에서 로그를 자동으로 업로드하거나 저장하지 않습니다. 포괄적인 디버깅의 경우 AKS 클러스터에 대해 Container Insights를 사용하도록 설정하는 것이 좋습니다. 이렇게 하면 필요할 때 AML 팀과 컨테이너 로그를 저장, 관리 및 공유할 수 있습니다. 이 경우 AML은 azureml-fe와 관련된 문제에 대한 지원을 보장할 수 없습니다.
- 최대 요청 페이로드는 100MB입니다.
Azureml-fe는 더 많은 코어를 사용하도록 스케일 업(세로)하고 더 많은 포드를 사용하도록 스케일 아웃(가로)합니다. 스케일 업을 결정할 때는 들어오는 유추 요청을 라우팅하는 데 걸리는 시간이 사용됩니다. 이 시간이 임계값을 초과하면 스케일 업이 발생합니다. 들어오는 요청을 라우팅하는 데 걸리는 시간이 임계값을 계속 초과하면 스케일 아웃이 발생합니다.
스케일 다운 및 스케일 인하는 경우에는 CPU 사용량이 사용됩니다. CPU 사용량 임계값에 도달하면 프런트 엔드가 먼저 스케일 다운됩니다. CPU 사용량이 스케일 인 임계값으로 떨어지면 스케일 인 작업이 발생합니다. 스케일 업 및 스케일 아웃은 사용 가능한 클러스터 리소스가 충분한 경우에만 발생합니다.
스케일 업 또는 스케일 다운 시 azureml-fe Pod가 다시 시작되어 cpu/메모리 변경 내용을 적용합니다. 다시 시작은 추론 요청에 영향을 주지 않습니다.
AKS 추론 클러스터에 대한 연결 요구 사항 이해
Azure Machine Learning이 AKS 클러스터를 만들거나 연결할 때 AKS 클러스터는 다음 두 가지 네트워크 모델 중 하나로 배포됩니다.
- Kubenet 네트워킹 - 네트워크 리소스는 일반적으로 AKS 클러스터가 배포될 때 만들어지고 구성됩니다.
- Azure CNI(Container Networking Interface) 네트워킹 - AKS 클러스터가 기존 가상 네트워크 리소스 및 구성에 연결됩니다.
Kubenet 네트워킹의 경우 Azure Machine Learning 서비스에 적절하게 네트워크를 만들고 구성합니다. CNI 네트워킹의 경우 연결 요구 사항을 이해하고 AKS 추론에 대한 DNS 확인 및 아웃바운드 연결을 확인해야 합니다. 예를 들어 방화벽을 사용하여 네트워크 트래픽을 차단할 수 있습니다.
다음 다이어그램에서는 AKS 추론에 대한 연결 요구 사항을 보여 줍니다. 검은색 화살표는 실제 통신을 나타내고 파란색 화살표는 도메인 이름을 나타냅니다. 이러한 호스트에 대한 항목을 방화벽 또는 사용자 지정 DNS 서버에 추가해야 할 수 있습니다.
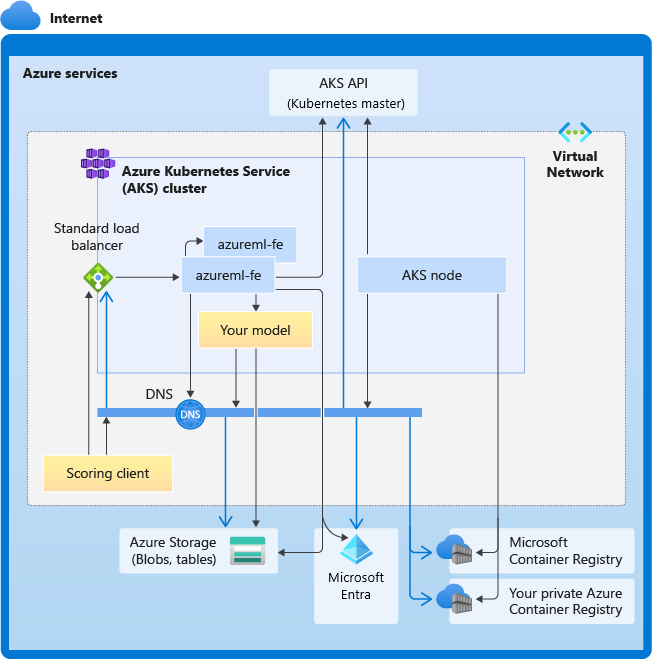
일반적인 AKS 연결 요구 사항은 AKS에서 Azure Firewall을 사용하여 네트워크 트래픽 제한을 참조하세요.
방화벽 뒤에서 Azure Machine Learning Services에 액세스하려면 인바운드 및 아웃바운드 네트워크 트래픽 구성을 참조하세요.
전체 DNS 확인 요구 사항
기존 가상 네트워크 내의 DNS 확인은 사용자가 제어합니다. 예를 들면 방화벽 또는 사용자 지정 DNS 서버가 있습니다. 다음 호스트에 연결할 수 있어야 합니다.
| 호스트 이름 | 사용 대상 |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API 서버 |
mcr.microsoft.com |
MCR(Microsoft Container Registry) |
<ACR name>.azurecr.io |
ACR(Azure Container Registry) |
<account>.table.core.windows.net |
Azure Storage 계정(테이블 스토리지) |
<account>.blob.core.windows.net |
Azure Storage 계정(Blob 스토리지) |
api.azureml.ms |
Microsoft Entra 인증 |
ingest-vienna<region>.kusto.windows.net |
원격 분석 업로드를 위한 Kusto 엔드포인트 |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
엔드포인트 도메인 이름(Azure Machine Learning으로 자동 생성된 경우). 사용자 지정 도메인 이름을 사용한 경우에는 이 항목이 필요하지 않습니다. |
시간순으로 정렬된 연결 요구 사항
AKS 만들기 또는 연결 과정에서 Azure Machine Learning 라우터(Azure Machine Learning-fe)는 AKS 클러스터에 배포됩니다. Azure Machine Learning 라우터를 배포하려면 AKS 노드가 다음을 수행할 수 있어야 합니다.
- AKS API 서버에 대한 DNS 확인
- MCR에 대한 DNS 확인(Azure Machine Learning 라우터용 docker 이미지를 다운로드하는 데 필요)
- 아웃바운드 연결이 필요한 MCR에서 이미지 다운로드
azureml-fe가 배포된 직후 시작을 시도하며 이를 위해서는 다음을 수행해야 합니다.
- AKS API 서버에 대한 DNS 확인
- AKS API 서버를 쿼리하여 다른 인스턴스 검색(여러 Pod 서비스임)
- 다른 인스턴스에 연결
azureml-fe가 시작된 후 제대로 작동하려면 다음 연결이 필요합니다.
- Azure Storage에 연결하여 동적 구성 다운로드
- Microsoft Entra 인증 서버 api.azureml.ms에 대한 DNS를 확인하고 배포된 서비스가 Microsoft Entra 인증을 사용할 때 이와 통신합니다.
- AKS API 서버를 쿼리하여 배포된 모델 검색
- 배포된 모델 POD와 통신
모델 배포 시 성공적인 모델 배포를 위해 AKS 노드는 다음을 수행할 수 있어야 합니다.
- 고객의 ACR에 대한 DNS 확인
- 고객의 ACR에서 이미지 다운로드
- 모델이 저장된 Azure Blob에 대한 DNS 확인
- Azure Blob에서 모델 다운로드
모델이 배포되고 서비스가 시작되면 azureml-fe는 AKS API를 사용하여 모델을 자동으로 검색하고 요청을 라우팅할 준비가 됩니다. 모델 POD와 통신할 수 있어야 합니다.
참고 항목
배포된 모델에 연결이 필요한 경우(예: 외부 데이터베이스, 기타 REST 서비스 쿼리 또는 BLOB 다운로드) 해당 서비스에 대한 DNS 확인 및 아웃바운드 통신을 모두 사용하도록 설정해야 합니다.
AKS에 배포
AKS에 모델을 배포하려면 필요한 컴퓨팅 리소스를 설명하는 배포 구성을 만듭니다. 예를 들어 코어 수 및 메모리입니다. 모델 및 웹 서비스를 호스트하는 데 필요한 환경을 설명하는 유추 구성도 필요합니다. 유추 구성을 만드는 방법에 대한 자세한 내용은 모델을 배포하는 방법 및 위치를 참조하세요.
참고 항목
배포할 모델 수는 배포당(컨테이너당) 모델 1,000개로 제한됩니다.
적용 대상:  Python SDK azureml v1
Python SDK azureml v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
이 예제에 사용된 클래스, 메서드 및 매개 변수에 대한 자세한 내용은 다음 참조 문서를 확인하세요.
자동 확장
적용 대상: Python SDK azureml v1
Azure Machine Learning 모델 배포에 대한 자동 스케일링을 처리하는 구성 요소는 azureml-fe이며, 이것은 스마트 요청 라우터입니다. 모든 유추 요청이 여기를 거치기 때문에, 여기에는 배포된 모델을 자동으로 스케일링하는 데 필요한 데이터가 있습니다.
Important
모델 배포에 Kubernetes HPA(Horizontal Pod Autoscaler)를 사용하도록 설정하지 마세요. 그러면 두 가지 자동 스케일링 구성 요소가 서로 경쟁하게 됩니다. Azureml-fe는 Azure Machine Learning에 의해 배포된 모델을 자동 스케일링하도록 설계되었으며, HPA는 CPU 사용량 또는 사용자 지정 메트릭 구성과 같은 일반 메트릭에서 모델 사용률을 추측하거나 대략적으로 추정해야 합니다.
Azureml-fe는 AKS 클러스터의 노드 수를 스케일링하지 않습니다. 예상치 못한 비용 증가로 이어질 수 있기 때문입니다. 대신 물리적 클러스터 경계 내에서 모델의 복제본 수를 스케일링합니다. 클러스터 내 노드 수를 스케일링해야 하는 경우 클러스터를 수동으로 스케일링하거나 AKS 클러스터 자동 스케일러를 구성할 수 있습니다.
자동 스케일링은 AKS 웹 서비스에 대해 autoscale_target_utilization, autoscale_min_replicas, autoscale_max_replicas를 설정하여 제어할 수 있습니다. 다음 예는 자동 스케일링을 사용하도록 설정하는 방법을 보여줍니다.
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
스케일 업 또는 다운 결정은 현재 컨테이너 복제본의 사용률에 기반합니다. 사용 중인(요청을 처리하는) 복제본 수를 현재 복제본의 총 수로 나눈 값이 현재 사용률입니다. 이 수가 autoscale_target_utilization을 초과하면 더 많은 복제본이 생성됩니다. 이보다 낮으면 복제본이 감소됩니다. 기본적으로 목표 사용률은 70%입니다.
복제본 추가에 대한 결정은 열성적이고 빠릅니다(약 1초). 복제본 제거에 대한 결정은 보수적입니다(약 1분).
필요한 복제본은 다음 코드를 사용하여 계산할 수 있습니다.
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
autoscale_target_utilization, autoscale_max_replicas, autoscale_min_replicas 설정에 대한 자세한 내용은 AksWebservice 모듈 참조를 확인하세요.
웹 서비스 인증
Azure Kubernetes Service에 배포할 때 키 기반 인증이 기본적으로 사용하도록 설정되어 있습니다. 토큰 기반 인증을 사용하도록 설정할 수도 있습니다. 토큰 기반 인증을 위해서는 클라이언트가 Microsoft Entra 계정을 사용하여 배포된 서비스에 요청하는 데 사용되는 인증 토큰을 요청해야 합니다.
인증을 사용하지 않도록 설정하려면 배포 구성을 만들 때 auth_enabled=False 매개 변수를 설정합니다. 다음 예제에서는 SDK를 사용하여 인증을 사용하지 않도록 설정합니다.
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
클라이언트 애플리케이션에서 인증하는 방법에 대한 정보는 웹 서비스로 배포된 Azure Machine Learning 모델 사용을 참조하세요.
키로 인증
키 인증을 사용하도록 설정한 경우 get_keys 메서드를 사용하여 기본 및 보조 인증 키를 검색할 수 있습니다.
primary, secondary = service.get_keys()
print(primary)
Important
키를 다시 생성해야 하는 경우 service.regen_key를 사용합니다.
토큰으로 인증
토큰 인증을 사용하도록 설정하려면 배포를 만들거나 업데이트할 때 token_auth_enabled=True 매개 변수를 설정합니다. 다음 예제에서는 SDK를 사용하여 토큰 인증을 사용하도록 설정합니다.
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
토큰 인증을 사용하도록 설정하면 get_token 메서드를 사용하여 JWT 토큰 및 이 토큰의 만료 시간을 검색할 수 있습니다.
token, refresh_by = service.get_token()
print(token)
Important
토큰의 refresh_by 시간 이후 새 토큰을 요청해야 합니다.
Microsoft는 AKS 클러스터와 동일한 지역에 Azure Machine Learning 작업 영역을 만들 것을 강력히 권장합니다. 토큰으로 인증하기 위해 웹 서비스는 Azure Machine Learning 작업 영역이 생성되는 지역을 호출합니다. 작업 영역의 지역을 사용할 수 없는 경우에는 클러스터가 작업 영역과 다른 지역에 있더라도 웹 서비스에 대한 토큰을 가져올 수 없습니다. 따라서 작업 영역의 지역을 다시 사용할 수 있을 때까지 사실상 토큰 기반 인증을 사용할 수 없습니다. 또한 클러스터 지역과 작업 영역의 지역 간 거리가 멀수록 토큰을 가져오는 데 시간이 오래 걸립니다.
토큰을 검색하려면 Azure Machine Learning SDK 또는 az ml service get-access-token 명령을 사용해야 합니다.
취약성 검색
클라우드용 Microsoft Defender는 하이브리드 클라우드 워크로드 전반에 걸쳐 통합 보안 관리 및 고급 위협 보호를 제공합니다. Microsoft Defender for Cloud가 리소스를 검색하도록 허용하고 권장 사항을 따라야 합니다. 자세한 내용은 컨테이너용 Microsoft Defender의 컨테이너 보안을 참조하세요.
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기