Azure SQL 데이터베이스의 탄력적 작업
적용 대상: ![]() Azure SQL Database
Azure SQL Database
이 문서에서는 Azure SQL 데이터베이스에 대한 탄력적 작업의 기능 및 세부 정보를 검토합니다.
- 탄력적 작업 구성에 대한 자습서는 탄력적 작업 자습서를 참조하세요.
- Azure 데이터베이스 플랫폼의 자동화 개념에 대해 자세히 알아봅니다.
탄력적 작업 개요
T-SQL(Transact-SQL) 쿼리를 실행하고 유지 관리 작업을 수행하도록 하나 이상의 Azure SQL 데이터베이스에 대해 주기적으로 실행되는 탄력적 작업을 만들고 예약할 수 있습니다.
대상 데이터베이스 또는 작업이 실행되는 데이터베이스의 그룹을 정의할 수 있으며, 작업 실행을 위한 일정도 정의할 수 있습니다. 탄력적 작업의 모든 날짜와 시간은 UTC 표준 시간대를 따릅니다.
작업은 대상 데이터베이스에 로그인하는 작업을 처리합니다. 또한 데이터베이스 그룹에서 실행할 Transact-SQL 스크립트를 정의, 유지 관리 및 보존합니다.
모든 작업은 실행의 상태를 기록하고 오류가 발생하는 경우 작업을 자동으로 다시 시도합니다.
탄력적 작업을 사용하는 경우
탄력적 작업 자동화를 사용할 수 있는 몇 가지 시나리오는 다음과 같습니다:
- 관리 작업을 자동화한 다음, 주중 매일, 일정 시간 후 등에 실행되도록 예약합니다.
- 스키마 변경 내용, 자격 증명 관리를 배포합니다.
- 성능 데이터 수집 또는 테넌트(고객) 원격 분석 수집.
- 참조 데이터(모든 데이터베이스에 공통으로 적용되는 정보)를 업데이트합니다.
- Azure Blob 스토리지에서 데이터를 로드합니다.
- 사용량이 적은 시간 중과 같이 데이터베이스 컬렉션에 대해 되풀이해서 실행하려면 작업을 구성합니다.
- 지속적으로 데이터베이스 집합에서 중앙 테이블로 쿼리 결과를 수집합니다.
- 쿼리는 지속적으로 실행하고 실행할 추가 작업을 트리거하도록 구성할 수 있습니다.
- 보고에 대한 데이터 수집
- 데이터베이스의 컬렉션에서 단일 대상 테이블로 데이터를 집계합니다.
- 큰 데이터베이스 집합에 대해 더 오래 실행되는 데이터 처리 쿼리(예: 고객 원격 분석 수집) 실행. 추가 분석을 위해 결과가 단일 대상 테이블에 수집됩니다.
- 데이터 이동
- 사용자 지정 개발 솔루션, 비즈니스 자동화 또는 기타 작업 관리용입니다.
- 데이터베이스의 테이블 간에 데이터를 추출/처리/삽입하는 ETL 처리입니다.
다음과 같은 경우 탄력적 작업을 고려합니다:
- 하나 이상의 데이터베이스를 대상으로 일정에 따라 정기적으로 실행해야 하는 작업이 있어야 합니다.
- 여러 데이터베이스에서 한 번 실행해야 하는 태스크가 있어야 합니다.
- 데이터베이스의 모든 조합에 대해 작업을 실행해야 합니다: 하나 이상의 개별 데이터베이스, 서버의 모든 데이터베이스, 탄력적 풀의 모든 데이터베이스, 특정 데이터베이스를 포함하거나 제외할 수 있는 유연성이 추가된 모든 데이터베이스. 작업은 여러 서버 및 여러 사람에서 실행될 수 있으며 심지어 다른 구독의 데이터베이스에 대해서도 실행될 수 있습니다. 서버 및 풀은 런타임 시 동적으로 열거되므로 작업은 실행 시 대상 그룹에 존재하는 모든 데이터베이스에 대해 실행됩니다.
- 이는 특히 데이터베이스가 동적으로 추가/삭제되는 SaaS 고객 시나리오에서 대상 데이터베이스를 동적으로 열거할 수 없는 SQL 에이전트와 크게 구별됩니다.
탄력적 작업 구성 요소
| 구성 요소 | 설명 |
|---|---|
| 탄력적 작업 에이전트 | 작업을 실행하고 관리하기 위해 만든 Azure 리소스입니다. |
| 작업 데이터베이스 | 작업 에이전트가 작업 관련 데이터, 작업 정의 등을 저장하는 데 사용하는 Azure SQL Database의 데이터베이스입니다. |
| 작업 | 작업은 둘 이상의 작업 단계로 구성된 작업 단위입니다. 작업 단계는 실행할 T-SQL 스크립트 뿐만 아니라 스크립트를 실행하는 데 필요한 기타 세부 정보를 지정합니다. |
| 대상 그룹 | 작업을 실행할 서버, 풀 및 데이터베이스의 집합입니다. |
탄력적 작업 에이전트
탄력적 작업 에이전트는 작업을 생성하고 실행하고 관리하기 위한 Azure 리소스입니다. 탄력적 작업 에이전트는 포털에서 만드는 Azure 리소스입니다(PowerShell을 사용하여 탄력적인 작업을 만들고 관리하기 및 REST API도 지원됩니다).
탄력적 작업 에이전트를 만들려면 Azure SQL Database의 기존 데이터베이스가 필요합니다. 에이전트는 이 기존 Azure SQL Database를 작업 데이터베이스로 구성합니다.
Azure Portal을 통해 작업을 시작, 비활성화 또는 취소할 수 있습니다. 또한 Azure Portal을 사용하면 작업 정의 및 실행 기록을 볼 수 있습니다.
탄력적 작업 에이전트 비용
작업 데이터베이스는 Azure SQL Database의 모든 데이터베이스와 동일한 비용이 청구됩니다. 탄력적 작업 에이전트의 비용의 경우 작업 에이전트에 대해 선택한 서비스 계층의 고정 가격 책정을 기반으로 합니다. Azure SQL Database 가격 책정 페이지를 참조 하세요.
탄력적 작업 데이터베이스
작업 데이터베이스는 작업을 정의하고 작업 실행의 기록 및 상태를 추적하는 데 사용됩니다. 작업은 대상 데이터베이스에서 실행됩니다. 작업 데이터베이스는 또한 에이전트 메타데이터, 로그, 결과, 작업 정의를 저장하는 데 사용되며, T-SQL을 사용하여 작업을 생성, 실행 및 관리하기 위해 많은 유용한 저장 프로시저 및 기타 데이터베이스 개체도 포함합니다.
현재 미리 보기의 경우 탄력적 작업 에이전트를 생성하는 데 Azure SQL 데이터베이스의 기존 데이터베이스(S1 이상)를 사용하는 것이 좋습니다.
작업 데이터베이스는 깨끗하고, 비어있는 S1 이상의 서비스 목표 Azure SQL Database여야 합니다.
작업 데이터베이스의 권장되는 서비스 개체는 S1 이상이지만 작업 단계 수, 작업 대상 수 및 작업 실행 빈도 같은 사용자 작업의 성능 요구에 따라 달라집니다.
작업 데이터베이스에 대한 작업이 예상보다 느린 경우 Azure Portal 또는 sys.dm_db_resource_stats DMV를 사용하여 속도 저하 기간 동안 작업 데이터베이스에서 데이터베이스 성능 및 리소스 사용률을 모니터링할 수 있습니다. CPU, 데이터 IO 또는 로그 쓰기와 같은 리소스의 사용률이 100%에 도달하고 속도 저하 기간과 상관 관계에 있는 경우, 작업 데이터베이스 성능이 충분히 향상될 때까지 데이터베이스를 더 높은 서비스 개체(DTU 기반 구매 모델 또는 vCore 구매 모델에서)로 증분 확장하는 것이 좋습니다.
Important
보고 및 분석을 위해 테이블에서 읽을 수 있지만 기존 개체를 수정하거나 작업 데이터베이스에 새 개체를 만들지 마세요.
탄력적 작업 및 작업 단계
작업은 일정에 따라 또는 일회성 작업으로 실행되는 작업의 단위입니다. 작업은 하나 이상의 작업 단계로 구성됩니다.
각 작업 단계는 실행할 T-SQL 스크립트, T-SQL 스크립트를 실행하는 하나 이상의 대상 그룹 및 작업 에이전트가 대상 데이터베이스에 연결해야 하는 자격 증명을 지정합니다. 각 작업 단계에는 사용자 지정 가능한 시간 제한 및 재시도 정책이 있으며, 출력 매개 변수를 선택적으로 지정할 수 있습니다.
탄력적 작업 대상
탄력적 작업은 일정에 따라 또는 요청 시 많은 데이터베이스에서 하나 이상의 T-SQL 스크립트를 병렬로 실행하는 기능을 제공합니다. 대상은 Azure SQL Database의 모든 계층일 수 있습니다.
하나 이상의 개별 데이터베이스, 서버의 모든 데이터베이스, 탄력성 풀의 모든 데이터베이스 등 모든 데이터베이스 조합에 대해 예약된 작업을 실행할 수 있으며, 특정 데이터베이스를 포함하거나 제외할 수 있는 유연성이 추가되었습니다. 작업은 여러 서버 및 여러 사람에서 실행될 수 있으며 심지어 다른 구독의 데이터베이스에 대해서도 실행될 수 있습니다. 서버 및 풀은 런타임 시 동적으로 열거되므로 작업은 실행 시 대상 그룹에 존재하는 모든 데이터베이스에 대해 실행됩니다.
다음 이미지에서는 다른 유형의 대상 그룹에 대해 작업을 실행하는 작업 에이전트를 보여줍니다:
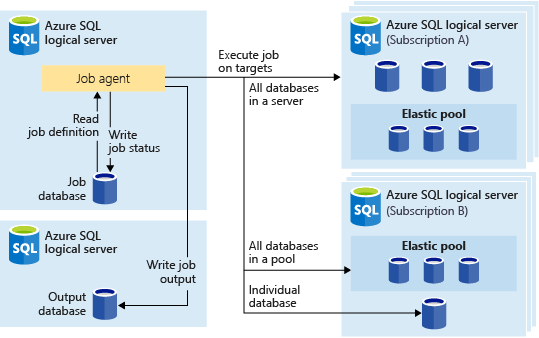
대상 그룹
대상 그룹은 작업 단계에서 실행될 데이터베이스의 집합을 정의합니다. 대상 그룹은 다음의 모든 번호와 조합을 포함할 수 있습니다:
- 논리적 SQL 서버 - 서버가 지정되면 작업 실행 시 서버에 존재하는 모든 데이터베이스 그룹의 일부가 됩니다. 작업 실행에 앞서 그룹을 열거하고 업데이트할 수 있도록
master데이터베이스 자격 증명이 제공되어야 합니다. 논리 서버에 대한 자세한 내용은 Azure SQL Database 및 Azure Synapse Analytics의 논ㄹ서버란?을 참조하세요 - 탄력적 풀 - 탄력적 풀을 지정하는 경우 작업 실행 시 탄력적인 풀에 있는 모든 데이터베이스는 그룹의 일부가 됩니다. 서버의 경우 작업 실행에 앞서 그룹을 업데이트할 수 있도록
master데이터베이스 자격 증명이 제공되어야 합니다. - 단일 데이터베이스 - 하나 이상의 개별 데이터베이스가 그룹의 일부가 되도록 지정합니다.
팁
작업 실행 시 동적 열거형은 서버 또는 풀을 포함하는 대상 그룹에서 데이터베이스의 집합을 다시 평가합니다. 동적 열거형은 작업 실행 시 서버나 풀에 존재하는 모든 데이터베이스에서 작업이 실행되는지 확인합니다. 런타임 시 데이터베이스 목록의 재평가는 풀 또는 서버 멤버 자격이 자주 변경되는 시나리오에 특히 유용합니다.
풀 및 단일 데이터베이스는 그룹에서 제외되거나 포함되는 것으로 지정할 수 있습니다. 이렇게 하면 데이터베이스의 모든 조합을 사용하여 대상 그룹을 만들 수 있습니다. 예를 들어 대상 그룹에 서버를 추가할 수 있지만 탄력적 풀에서 특정 데이터베이스를 제외합니다(또는 전체 풀을 제외).
대상 그룹은 여러 지역 및 여러 구독에서 데이터베이스를 포함할 수 있습니다. 지역 간 실행은 동일한 지역 내 실행보다 더 많은 대기 시간이 필요합니다.
다음 예제에서는 작업 실행 시 여러 대상 그룹 정의를 동적으로 열거하여 작업에서 실행할 데이터베이스를 결정하는 원리를 보여줍니다:
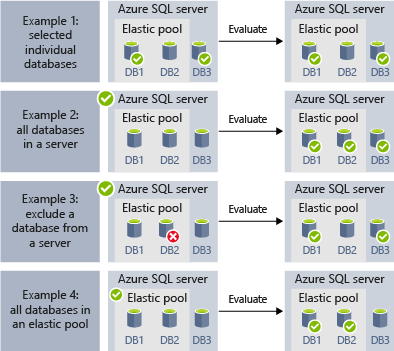
- 예제 1은 개별 데이터베이스 목록으로 구성되는 대상 그룹을 보여줍니다. 이 대상 그룹을 사용하여 작업 단계가 실행되면 작업 단계의 동작은 각 데이터베이스에서 실행됩니다.
- 예제 2는 서버를 대상으로 포함하는 대상 그룹을 보여 줍니다. 이 대상 그룹을 사용하여 작업 단계가 실행되면 현재 서버에 있는 데이터베이스 목록을 확인하기 위해 서버가 동적으로 열거됩니다. 작업 단계의 동작은 각 데이터베이스에서 실행됩니다.
- 예제 3은 예제 2와 비슷한 대상 그룹을 보여주지만, 개별 데이터베이스가 제외됩니다. 제외된 데이터베이스에서 작업 단계의 동작이 실행되지 않습니다.
- 예제 4는 탄력적 풀을 대상으로 포함하는 대상 그룹을 보여줍니다. 예제 2와 비슷하게, 풀에 있는 데이터베이스 목록을 확인하기 위해 런타임에 풀이 동적으로 열거됩니다.
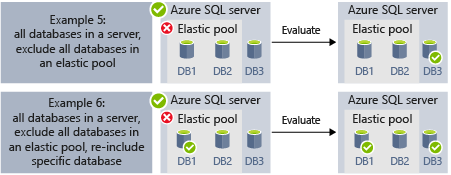
- 예제 5 및 예제 6은 포함 및 제외 규칙을 사용하여 서버, 탄력적 풀, 데이터베이스를 결합할 수 있는 고급 시나리오를 보여줍니다.
참고 항목
작업 데이터베이스 자체는 작업의 대상일 수 있습니다. 이 시나리오에서 작업 데이터베이스는 다른 대상 데이터베이스와 동일하게 처리됩니다. 작업 데이터베이스에서 작업 사용자를 만들고 충분한 권한을 부여해야 하며, 작업 사용자에 대한 데이터베이스 범위 자격 증명은 다른 대상 데이터베이스의 경우와 마찬가지로 작업 데이터베이스에도 있어야 합니다.
인증
탄력적 작업 에이전트의 모든 대상에 대해 하나의 메서드를 선택합니다. 예를 들어 단일 탄력적 작업 에이전트의 경우 데이터베이스 범위 자격 증명을 사용하도록 대상 서버 하나와 Microsoft Entra ID 인증을 사용하도록 다른 대상 서버를 구성할 수 없습니다.
탄력적 작업 에이전트는 다음 두 가지 인증 옵션을 통해 대상 그룹에서 지정한 서버/데이터베이스에 연결할 수 있습니다:
- UMI(사용자 할당 관리 ID)를 사용하여 Microsoft Entra(이전의 Azure Active Directory) 인증을 사용합니다.
- 데이터베이스 범위 자격 증명을 사용합니다.
사용자 할당 관리 ID(UMI)를 통한 인증
사용자 할당 UMI(관리 ID)를 통한 Microsoft Entra(과거 Azure Active Directory) 인증은 탄력적 작업을 Azure SQL Database에 연결하는 데 권장되는 옵션입니다. Microsoft Entra ID 지원을 통해 작업 에이전트는 UMI를 사용하여 대상 데이터베이스(데이터베이스, 서버, 탄력적 풀) 및 출력 데이터베이스에 연결할 수 있습니다.

필요에 따라 Microsoft Entra ID 연결을 통해 해당 데이터베이스에 액세스/쿼리하기 위해 탄력적 작업 데이터베이스가 포함된 논리 서버에서 Microsoft Entra ID 인증을 사용하도록 설정할 수도 있습니다. 그러나 작업 에이전트 자체는 내부 인증서 기반 인증을 사용하여 해당 작업 데이터베이스에 연결합니다.
하나의 UMI를 만들거나 기존 UMI를 사용하고 동일한 UMI를 여러 작업 에이전트에 할당할 수 있습니다. 작업 에이전트당 하나의 UMI만 지원됩니다. UMI가 작업 에이전트에 할당되면 해당 작업 에이전트는 이 ID만 사용하여 대상 데이터베이스에서 t-SQL 작업을 연결하고 실행합니다. SQL 인증은 해당 작업 에이전트의 대상 서버/데이터베이스에 대해 사용되지 않습니다.
UMI 이름은 문자 또는 숫자로 시작하고 길이는 3에서 128 사이여야 합니다. 여기에는 - 및 _ 문자가 포함될 수 있습니다.
Azure SQL 데이터베이스의 UMI에 대한 자세한 내용은 필요한 단계 및 UMI를 Azure SQL Database 논리 서버 ID로 사용하는 이점을 포함하여 Azure SQL에 대한 관리 ID를 참조하세요. 자세한 내용은 Microsoft Entra 인증 사용을 참조하세요.
Important
Microsoft Entra ID 인증을 사용하는 경우 모든 대상 데이터베이스에서 해당 Microsoft Entra ID에서 jobuser 사용자를 만듭니다. 각 대상 데이터베이스에서 작업을 실행하는 데 필요한 권한을 해당 사용자에게 부여합니다.
시스템 할당 관리 ID(SMI) 사용은 지원하지 않습니다.
데이터베이스 범위 자격 증명을 통한 인증
Microsoft Entra(과거 Azure Active Directory) 인증이 권장되는 옵션이지만 데이터베이스 범위 자격 증명을 사용하여 실행 시 대상 그룹에서 지정한 데이터베이스에 연결하는 작업을 구성할 수 있습니다. 2023년 10월 이전에는 데이터베이스 범위 자격 증명이 유일한 인증 옵션이었습니다.
대상 그룹에 서버 또는 풀이 포함되어 있는 경우 이러한 데이터베이스 범위 자격 증명은 사용 가능한 데이터베이스를 열거하는 master 데이터베이스에 연결하는 데 사용됩니다.
- 데이터베이스 범위 자격 증명은 작업 데이터베이스에서 만들어야 합니다.
- 작업을 성공적으로 완료하려면 모든 대상 데이터베이스에 충분한 권한이 있는 로그인 권한이 있어야 합니다(다음 다이어그램 내
jobuser). - 대상 데이터베이스에서 만든 자격 증명(
masteruser및jobuser의 경우에LOGIN과PASSWORD)은 다음의 작업 데이터베이스에서 생성된 자격 증명의IDENTITY와SECRET과 일치해야 합니다. - 자격 증명은 작업 간에 다시 사용할 수 있고, 자격 증명 암호는 암호화되어 작업 개체에 읽기 전용 액세스 권한이 있는 사용자로부터 보호됩니다.
다음 이미지는 적절한 작업 자격 증명을 설정하고 탄력적 작업 에이전트가 데이터베이스 자격 증명을 인증으로 사용하여 대상 서버/데이터베이스의 로그인/사용자에 연결하는 방법을 이해하는 데 도움이 되도록 설계되었습니다.
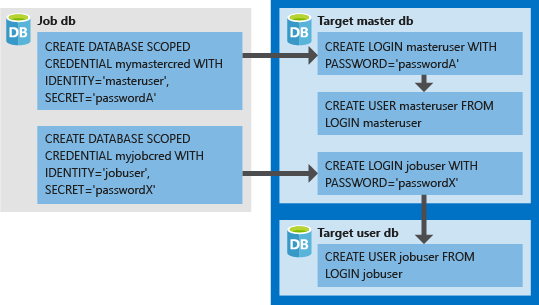
참고 항목
데이터베이스 범위 자격 증명을 사용하는 경우 모든 대상 데이터베이스에서 귀하의 jobuser 사용자를 만들어야 합니다.
탄력적 작업 프라이빗 엔드포인트
탄력적 작업 에이전트는 탄력적 작업 프라이빗 엔드포인트를 지원합니다. 탄력적 작업 프라이빗 엔드포인트를 만들면 탄력적 작업과 대상 서버 간에 프라이빗 링크가 설정됩니다. 탄력적 작업 프라이빗 엔드포인트 기능은 Azure Private Link와 다릅니다.

탄력적 작업 프라이빗 엔드포인트 기능은 대상/출력 서버에 대한 프라이빗 연결을 지원하므로 "공용 액세스 거부" 옵션을 사용하는 경우에도 작업 에이전트가 계속 연결할 수 있습니다. "Azure 서비스 및 리소스가 해당 서버에 액세스하도록 허용" 옵션을 사용하지 않도록 설정하려는 경우 프라이빗 엔드포인트를 사용할 수도 있습니다.
탄력적 작업 프라이빗 엔드포인트는 탄력적 작업 에이전트 인증의 모든 옵션을 지원합니다.
탄력적 작업 프라이빗 엔드포인트 기능을 사용하면 서비스 관리 프라이빗 엔드포인트를 선택하여 작업 에이전트와 대상/출력 서버 간에 보안 연결을 설정할 수 있습니다. 서비스 관리 프라이빗 엔드포인트는 특정 가상 네트워크 및 서브넷 내의 개인 IP 주소입니다. 작업 에이전트의 대상/출력 서버 중 하나에서 프라이빗 엔드포인트를 사용하도록 선택하면 Microsoft에서 서비스 관리 프라이빗 엔드포인트를 만듭니다. 그런 다음 이 프라이빗 엔드포인트는 작업 에이전트가 작업을 연결 및 실행하거나 해당 대상/출력 데이터베이스에 작업 출력을 작성하는 데만 사용됩니다.
탄력적 작업 프라이빗 엔드포인트는 Azure Portal을 통해 만들고 허용할 수 있습니다. 프라이빗 링크를 통해 연결된 대상 서버는 다른 지역 및 구독에서도 Azure의 어디에나 있을 수 있습니다. 이 통신을 사용하려면 원하는 각 대상 서버와 작업 출력 서버에 대한 프라이빗 엔드포인트를 만들어야 합니다.
탄력적 작업에 대한 새 서비스 관리 프라이빗 엔드포인트를 구성하는 자습서는 Azure SQL 탄력적 작업 프라이빗 엔드포인트 구성을 참조하세요.
탄력적 작업 프라이빗 엔드포인트에 대한 요구 사항
- 탄력적 작업 프라이빗 엔드포인트를 사용하려면 작업 에이전트와 대상 서버/데이터베이스가 모두 Azure(동일 또는 다른 지역)에서 호스팅되고 동일한 클라우드 유형(예: 둘 다 퍼블릭 클라우드 또는 둘 다 정부 클라우드)에서 호스팅되어야 합니다.
Microsoft.Network리소스 공급자는 작업 에이전트와 대상/출력 서버의 호스트 구독에 등록해야 합니다.- 탄력적 작업 프라이빗 엔드포인트는 대상/출력 서버별로 만들어집니다. 탄력적 작업 에이전트가 이를 사용하려면 먼저 승인을 받아야 합니다. 이 작업은 해당 논리 서버 또는 선호하는 클라이언트의 네트워킹 창을 통해 수행할 수 있습니다. 그러면 탄력적 작업 에이전트가 프라이빗 연결을 사용하여 해당 서버의 모든 데이터베이스에 연결할 수 있습니다.
- 탄력적 작업 에이전트에서 작업 데이터베이스로의 연결은 프라이빗 엔드포인트를 사용하지 않습니다. 작업 에이전트 자체는 내부 인증서 기반 인증을 사용하여 해당 작업 데이터베이스에 연결합니다. 작업 데이터베이스를 대상 그룹 멤버로 추가하는 경우 한 가지 주의해야 할 사항입니다. 그런 다음 필요에 따라 프라이빗 엔드포인트로 설정해야 하는 일반 대상으로 동작합니다.
탄력적 작업 데이터베이스 사용 권한
작업 에이전트 생성 동안 스키마, 테이블 및 jobs_reader라는 역할이 작업 데이터베이스에서 만들어집니다. 역할은 다음과 같은 사용 권한으로 생성되며, 작업 모니터링을 위해 관리자에게 보다 정교한 액세스 제어를 제공하도록 설계되었습니다. 관리이스트래터는 사용자에게 작업 데이터베이스의 jobs_reader 역할에 추가하여 작업 실행을 모니터링하는 기능을 제공할 수 있습니다.
| 역할 이름 | jobs 스키마 권한 |
jobs_internal 스키마 권한 |
|---|---|---|
jobs_reader |
SELECT |
None |
주의
작업 데이터베이스의 내부 카탈로그 뷰(예: jobs.target_group_members)를 업데이트해서는 안 됩니다. 이러한 카탈로그 뷰를 수동으로 변경하면 작업 데이터베이스가 손상되어 오류가 발생할 수 있습니다. 이러한 보기는 읽기 전용 쿼리만을 위한 것입니다. 작업 데이터베이스의 저장 프로시저를 사용하여 jobs.sp_add_target_group_member같은 대상 그룹/멤버를 추가/삭제할 수 있습니다.
Important
작업 데이터베이스에 대한 승급된 액세스 권한을 부여하기 전에 보안 영향을 고려하세요. 작업을 만들거나 편집할 수 있는 권한이 있는 악의적인 사용자는 해당 악의적인 사용자의 제어 아래 저장된 자격 증명을 사용하는 작업을 만들거나 편집할 수 있으며, 이는 악의적인 사용자가 자격 증명의 암호 또는 악의적인 명령 실행을 사용하는 것을 허용할 수 있습니다.
탄력적 작업 모니터링
탄력적 작업 에이전트는 작업 상태 알림에 대한 Azure Alerts와 통합되어 작업 실행의 상태 및 기록을 모니터링하기 위한 솔루션을 간소화합니다.
또한 Azure Portal에는 탄력적 작업 및 작업 모니터링을 지원하기 위한 새로운 추가 기능이 있습니다. 탄력적 작업 에이전트의 개요 페이지에는 다음 스크린샷과 같이 가장 최근의 작업 실행이 표시됩니다.

Azure Portal, Azure CLI, PowerShell 및 REST API를 사용하여 Azure Monitor 경고 규칙을 만들 수 있습니다. 실패한 탄력적 작업 메트릭은 탄력적 작업 실행에 대한 경고를 모니터링하고 수신하는 좋은 시작점입니다. 또한 Azure Alert 시설에서 SMS 또는 전자 메일과 같은 구성 가능한 작업을 통해 경고를 받도록 선택할 수 있습니다. 자세한 내용은 Azure Portal을 사용하여 Azure SQL Database에 대한 경고 만들기를 참조하세요.
샘플은 탄력적 작업 생성, 구성 및 관리를 참조해 주세요.
작업 출력
각 대상 데이터베이스에서 작업 단계의 결과는 자세히 레코드되며, 스크립트 출력은 지정된 테이블로 캡처될 수 있습니다. 작업에서 반환된 모든 데이터를 저장하려면 데이터베이스를 지정할 수 있습니다.
작업 기록
테이블 jobs.job_executions(을)를 쿼리하여 작업 데이터베이스에서 탄력적 작업 실행 기록을 봅니다. 시스템 정리 작업은 45일 이상된 실행 기록을 제거합니다. 45일 미만의 기록을 수동으로 제거하려면 작업 데이터베이스에서 sp_purge_jobhistory 저장 프로시저를 실행합니다.
작업 상태
테이블 jobs.job_executions를 쿼리하여 작업 데이터베이스에서 탄력적 작업 실행을 모니터링할 수 있습니다.
모범 사례
탄력적 데이터베이스 작업을 사용할 때 다음 모범 사례를 고려합니다.
보안 모범 사례
- API 사용을 신뢰할 수 있는 개인으로 제한합니다.
- 자격 증명은 작업 단계를 수행하는 데 필요한 최소한의 권한만 있어야 합니다. 자세한 정보는 권한 부여 및 사용 권한을 참조하세요.
- 서버 및/또는 풀 대상 그룹 멤버를 사용할 경우 작업 실행 전에 서버 및/또는 풀의 데이터베이스 목록을 확장하는 데 사용되는 데이터베이스를 보려면/나열하려면
master데이터베이스에 대한 권한이 있는 별도 자격 증명을 만들 것을 강력히 제안합니다.
탄력적 작업 성능
탄력적 작업은 장기 실행 작업이 완료되기를 기다리는 동안 최소한의 컴퓨팅 리소스를 사용합니다.
작업(동시 작업자 수)에 대한 원하는 실행 시간 및 데이터베이스의 대상 그룹 크기에 따라 에이전트는 작업 데이터베이스의 다른 양의 성능 및 컴퓨팅을 요구합니다(대상 및 작업 수가 많아질수록 필요한 컴퓨팅 양도 더 많아집니다).
동시 용량 계층
2023년 10월부터 탄력적 작업 에이전트는 용량을 늘릴 수 있도록 여러 계층의 성능을 제공합니다.
용량 증가는 작업 에이전트가 연결하여 작업을 시작할 수 있는 총 동시 대상 데이터베이스 수를 나타냅니다. 작업 실행을 위한 더 많은 동시 대상 연결을 위해 작업 에이전트의 계층을 기본 JA100 계층에서 업그레이드합니다. 이 계층은 100개의 동시 대상 연결로 제한됩니다.
대부분의 환경에서는 언제든지 100개 미만의 동시 작업이 필요하므로 JA100이 기본값입니다.
| 탄력적 작업 에이전트 계층 | 최대 동시 작업 |
|---|---|
JA100 |
100 |
JA200 |
200 |
JA400 |
400 |
JA800 |
800 |
작업 대상을 사용하여 작업 에이전트의 동시성 용량 계층을 초과하면 일부 대상 데이터베이스/서버에 대한 큐 지연이 발생합니다. 예를 들어 JA100 계층에서 대상이 110인 작업을 시작하면 다른 대상이 완료될 때까지 10개의 대상이 시작을 기다립니다.
탄력적 작업 에이전트의 계층 또는 서비스 목표는 Azure Portal, PowerShell 또는 작업 에이전트 REST API를 통해 수정할 수 있습니다. 예를 들어 작업 에이전트 크기 조정을 참조하세요.
탄력적 풀에 대한 작업 영향 제한
Azure SQL 데이터베이스 탄력적 풀에서 데이터베이스에 대해 작업을 실행할 때 리소스에 작업 부하를 주지 않도록 하려면 작업이 동시에 실행될 수 있는 데이터베이스의 수를 제한하도록 작업을 구성할 수 있습니다.
T-SQL에서 sp_add_jobstep 저장 프로시저의 @max_parallelism 매개 변수를 설정하여 하나의 작업에서 동시에 실행하는 데이터베이스의 수를 설정합니다.
Idempotent 스크립트
탄력적 작업의 T-SQL 스크립트는 idempotent여야 합니다. Idempotent는 스크립트가 성공한 경우를 나타내고 다시 실행하면 동일한 결과가 발생합니다. 일시적인 네트워크 문제로 인해 스크립트가 실패할 수 있습니다. 이 경우 작업에서 중지하기 전에 스크립트 실행을 미리 설정된 횟수 만큼 자동으로 다시 시도합니다. idempotent 스크립트는 성공적으로 두 번(이상) 실행된 경우에도 동일한 결과를 포함합니다.
간단한 방법은 만들기 전에 개체의 존재 여부를 테스트하는 것입니다. 다음은 가상의 예입니다:
IF NOT EXISTS (SELECT * FROM sys.objects WHERE [name] = N'some_object')
print 'Object does not exist'
-- Create the object
ELSE
print 'Object exists'
-- If it exists, drop the object before recreating it.
마찬가지로 스크립트는 논리적으로 테스트하고 발견된 모든 조건을 고려하여 성공적으로 실행할 수 있어야 합니다.
제한 사항
탄력적 작업 서비스에 대한 현재 제한 사항입니다. Microsift는 이러한 제한 사항을 최대한 많이 제거하기 위해 적극적으로 노력하고 있습니다.
| 문제 | 설명 |
|---|---|
| 장애 조치(failover)/새 Azure 지역으로 이동한 후 새 지역에서 탄력적 작업을 다시 만들고 시작해야 합니다. | 탄력적 작업 서비스는 모든 작업 에이전트 및 작업 메타데이터를 작업 데이터베이스에 저장합니다. Azure 리소스를 새 Azure 지역으로 장애 조치(failover)하거나 이동하면 작업 데이터베이스, 작업 에이전트 및 작업 메타데이터도 새 Azure 지역으로 이동합니다. 그러나 탄력적 작업 에이전트는 컴퓨팅 전용 리소스이며 새 지역에서 작업을 다시 실행하기 전에 새 지역에서 명시적으로 다시 만들고 시작해야 합니다. 시작되면 탄력적 작업 에이전트는 이전에 정의된 작업 일정에 따라 새 지역에서 작업 실행을 다시 시작합니다. |
| 작업 데이터베이스의 과도한 감사 로그 | 탄력적 작업 에이전트는 작업 데이터베이스를 지속적으로 폴링하여 새 작업 및 기타 CRUD 작업의 도착을 확인합니다. 작업 데이터베이스가 있는 서버에서 감사를 사용하도록 설정하면 작업 데이터베이스에서 많은 수의 감사 로그가 생성될 수 있습니다. 조건자 식과 함께 Set-AzSqlServerAudit 명령을 사용하여 이러한 감사 로그를 필터링하여 완화할 수 있습니다.예제: Set-AzSqlServerAudit -ResourceGroupName "ResourceGroup01" -ServerName "Server01" -BlobStorageTargetState Enabled -StorageAccountResourceId "/subscriptions/7fe3301d-31d3-4668-af5e-211a890ba6e3/resourceGroups/resourcegroup01/providers/Microsoft.Storage/storageAccounts/mystorage" -PredicateExpression "database_principal_name <> '##MS_JobAccount##'"이 명령은 작업 데이터베이스 감사 로그로의 작업 에이전트만 필터링하고 모든 대상 데이터베이스 감사 로그로의 작업 에이전트는 필터링하지 않습니다. |
| 하이퍼스케일 데이터베이스를 작업 데이터베이스로 사용 | 하이퍼스케일 데이터베이스를 작업 데이터베이스로 사용하는 것은 지원되지 않습니다. 그러나 탄력적 작업은 Azure SQL Database의 다른 데이터베이스와 동일한 방식으로 하이퍼스케일 데이터베이스를 대상으로 삼을 수 있습니다. |
| 서버리스 데이터베이스 및 탄력적 작업으로 자동 일시 중지. | 자동 일시 중지 사용 서버리스 데이터베이스는 작업 데이터베이스로 지원되지 않습니다. 탄력적 작업의 대상인 서버리스 데이터베이스는 자동 일시 중지를 지원하며, 작업 연결을 통해 다시 시작됩니다. |
| BACPAC 파일로 작업 데이터베이스 내보내기 | 작업 데이터베이스를 BACPAC 파일로 내보내는 것은 지원되지 않습니다. 작업 데이터베이스가 포함된 SQL Server를 내보내야 하는 경우 서버를 내보내기 전에 먼저 작업 데이터베이스를 삭제해야 합니다. |