Azure SQL Database의 하이퍼스케일 탄력적 풀 개요
적용 대상: ![]() Azure SQL Database
Azure SQL Database
이 문서에서는 Azure SQL Database의 하이퍼스케일 탄력적 풀에 대한 개요를 제공합니다.
Azure SQL Database의 탄력적 풀을 사용하면 SaaS(Software-as-a-Service) 개발자는 정해진 예산 내에서 데이터베이스 그룹의 가격/성능 비율을 최적화하는 동시에 각 데이터베이스에 성능 탄력성을 제공할 수 있습니다. Azure SQL Database 하이퍼스케일 탄력적 풀은 하이퍼스케일 데이터베이스에 공유 리소스 모델을 도입합니다.
Azure CLI 또는 PowerShell을 사용하여 데이터베이스를 만들거나, 확장하거나, 하이퍼스케일 탄력적 풀로 이동하는 예제는 명령줄 도구를 사용하여 하이퍼스케일 탄력적 풀 작업을 검토하세요
참고 항목
하이퍼스케일용 탄력적 풀은 현재 미리 보기로 제공합니다.
개요
하이퍼스케일 데이터베이스를 탄력적 풀에 배포하여 풀 내 데이터베이스 간에 리소스를 공유하고 각기 다른 사용량 패턴을 가진 여러 데이터베이스를 보유하는 비용을 최적화합니다.
하이퍼스케일 데이터베이스와 함께 탄력적 풀을 사용하는 시나리오:
- 할당된 스토리지 크기와 관계없이 예측 가능한 시간 동안 탄력적 풀에 할당한 컴퓨팅 리소스를 확장 또는 축소해야 하는 경우.
- 하나 이상의 읽기 확장 복제본 추가하여 탄력적 풀에 할당한 컴퓨팅 리소스를 확장하려는 경우.
- 더 적은 컴퓨팅 리소스를 사용하는 경우에도 쓰기 집약적인 워크로드에 높은 트랜잭션 로그 처리량을 사용하려는 경우.
하이퍼스케일이 아닌 데이터베이스를 하이퍼스케일 탄력적 풀에 추가하면 데이터베이스가 하이퍼스케일 서비스 계층으로 변환됩니다.
아키텍처
일반적으로 독립 실행형 하이퍼스케일 데이터베이스의 아키텍처는 컴퓨팅, 스토리지("페이지 서버") 및 로그("로그 서비스")라는 세 가지의 독립적인 기본 구성 요소로 구성됩니다. 하이퍼스케일 데이터베이스의 탄력적 풀을 만들 때 풀 내 데이터베이스는 컴퓨팅 및 로그 리소스를 공유합니다. 또한 고가용성을 구성하기로 한 경우 각 고가용성 풀은 컴퓨팅 및 로그 리소스의 동등하고 독립적인 집합으로 만듭니다.
다음은 하이퍼스케일 데이터베이스를 위한 탄력적 풀의 아키텍처를 설명합니다.
- 하이퍼스케일 탄력적 풀은 기본 하이퍼스케일 데이터베이스를 호스팅하는 기본 풀로 구성되며, 구성된 경우 최대 4개의 추가 고가용성 풀로 구성됩니다.
- 기본 탄력적 풀에서 호스팅하는 기본 하이퍼스케일 데이터베이스는 SQL Server 데이터베이스 엔진(sqlservr.exe) 컴퓨팅 프로세스, vCore, 메모리 및 SSD 캐시를 공유합니다.
- 기본 풀에 고가용성을 구성하면 기본 풀의 데이터베이스를 위한 읽기 전용 데이터베이스 복제본을 포함한 추가 고가용성 풀을 만들게 됩니다. 각 기본 풀은 최대 4개의 고가용성 복제본 풀을 가질 수 있습니다. 각 고가용성 풀은 풀의 모든 보조 읽기 전용 데이터베이스를 위해 컴퓨팅, SSD 캐시 및 메모리 리소스를 공유합니다.
- 기본 탄력적 풀의 하이퍼스케일 데이터베이스는 모두 동일한 로그 서비스를 공유합니다. 고가용성 풀의 데이터베이스에는 쓰기 워크로드가 없으므로 로그 서비스를 활용하지 않습니다.
- 각 하이퍼스케일 데이터베이스에는 고유한 페이지 서버 집합이 있으며, 이러한 페이지 서버는 기본 풀의 기본 데이터베이스와 고가용성 풀의 모든 보조 복제본 데이터베이스 간에 공유합니다.
- 지역에서 복제된 보조 하이퍼스케일 데이터베이스는 다른 탄력적 풀 내에 배치할 수 있습니다.
- 데이터베이스 연결 문자열에서
ApplicationIntent=ReadOnly를 지정하면 고가용성 풀 중 하나의 읽기 전용 복제본 데이터베이스로 라우팅됩니다.
다음 다이어그램은 하이퍼스케일 데이터베이스를 위한 탄력적 풀의 아키텍처를 보여줍니다.
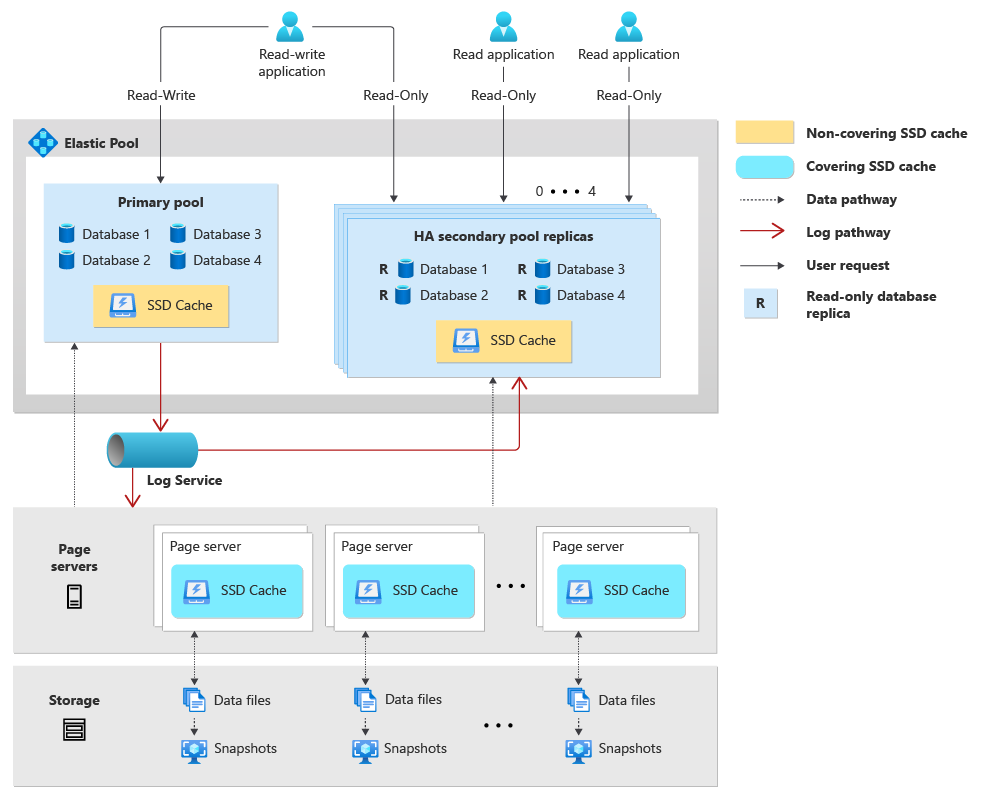
하이퍼스케일 탄력적 풀 데이터베이스 관리
동일한 명령을 사용하여 풀링한 하이퍼스케일 데이터베이스를 다른 서비스 계층의 풀링된 데이터베이스로 관리할 수 있습니다. 하이퍼스케일 탄력적 풀을 만들 때 버전에 Hyperscale을 지정하기만 하면 됩니다.
유일한 차이점은 기존 하이퍼스케일 탄력적 풀의 고가용성(H/A) 복제본 수를 수정하는 기능입니다. 수행할 작업:
- Azure PowerShell Set-AzSqlElasticPool 명령의
HighAvailabilityReplicaCount매개 변수를 사용합니다. - Azure CLI az sql elastic-pool update 명령의
--ha-replicas매개 변수를 사용합니다.
다음 클라이언트 도구를 사용하여 탄력적 풀에서 하이퍼스케일 데이터베이스를 관리할 수 있습니다.
- Azure PowerShell: Az.Sql.3.11.0 이상. PowerShell AzureRM.Sql은 지원하지 않습니다.
- Azure CLI: Az 버전 2.40.0 이상.
- Transact-SQL(T-SQL) 시작: SSMS(SQL Server Management Studio) v18.12.1 또는 Azure Data Studio v1.39.1.
하이퍼스케일이 아닌 데이터베이스를 하이퍼스케일 탄력적 풀로 변환
데이터베이스를 하이퍼스케일로 변환할 때 기존 하이퍼스케일 탄력적 풀에 데이터베이스를 추가할 수 있습니다. 이러한 변환의 경우 하이퍼스케일 탄력적 풀이 원본 데이터베이스와 동일한 논리 서버에 존재해야 합니다.
데이터베이스를 하이퍼스케일 탄력적 풀로 변환할 때 하이퍼스케일 탄력적 풀당 최대 데이터베이스 수를 알고 있어야 합니다.
T-SQL을 사용하여 하이퍼스케일이 아닌 데이터베이스를 하이퍼스케일 탄력적 풀로 변환
T-SQL 명령을 사용하여 여러 범용 데이터베이스를 변환하고 이를 hsep1이라는 기존 하이퍼스케일 탄력적 풀에 추가할 수 있습니다.
ALTER DATABASE gpepdb1 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb2 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb3 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb4 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
이 예제에서는 SERVICE_OBJECTIVE 대상이 하이퍼스케일 탄력적 풀임을 지정하여 범용에서 하이퍼스케일로의 변환을 암시적으로 요청합니다. 위 명령은 각각 해당하는 범용 데이터베이스를 하이퍼스케일로 변환하기 시작합니다. 이러한 ALTER DATABASE 명령은 신속하게 반환하며 변환이 끝나기를 기다리지 않습니다. 보이는 예제에서는 범용에서 하이퍼스케일로의 4가지 변환을 병렬로 진행하게 됩니다.
sys.dm_operation_status 동적 관리 뷰를 쿼리하여 이러한 백그라운드 변환 작업의 상태를 모니터링할 수 있습니다.
PowerShell을 사용하여 하이퍼스케일이 아닌 데이터베이스를 하이퍼스케일 탄력적 풀로 변환
PowerShell 명령을 사용하여 여러 범용 데이터베이스를 변환하고 이를 hsep1이라는 기존 하이퍼스케일 탄력적 풀에 추가할 수 있습니다. 예를 들어 다음 샘플 스크립트는 다음 단계를 수행합니다.
- Get-AzSqlElasticPoolDatabase cmdlet을 사용하여
gpep1이라는 범용 탄력적 풀의 모든 데이터베이스를 나열합니다. Where-Objectcmdlet은 목록을gpepdb로 시작하는 데이터베이스 이름으로만 필터링합니다.- 각 데이터베이스를 대상으로 Set-AzSqlDatabase cmdlet은 변환을 시작합니다. 이 경우
hsep1이라는 대상 하이퍼스케일 탄력적 풀을 지정하여 하이퍼스케일 서비스 계층으로의 변환을 암시적으로 요청합니다.-AsJob매개 변수를 사용하면 각Set-AzSqlDatabase요청을 병렬로 실행할 수 있습니다. 변환을 하나씩 실행하려는 경우-AsJob매개 변수를 제거할 수 있습니다.
$dbs = Get-AzSqlElasticPoolDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -ElasticPoolName "gpep1"
$dbs | Where-Object { $_.DatabaseName -like "gpepdb*" } | % { Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -DatabaseName ($_.DatabaseName) -ElasticPoolName "hsep1" -AsJob }
sys.dm_operation_status 동적 관리 뷰 외에도 Get-AzSqlDatabaseActivity PowerShell cmdlet을 사용하여 이러한 백그라운드 변환 작업의 상태를 모니터링할 수 있습니다.
리소스 한계
다음은 탄력적 풀 내에서 하이퍼스케일 데이터베이스 작업을 지원하는 제한을 나열합니다.
- 지원하는 하드웨어 세대: 표준 시리즈(Gen5), 프리미엄 시리즈 및 프리미엄 시리즈 메모리 최적화.
- 풀당 최대 vCore 수: 서비스 수준 목표에 따라 80~128개의 vCore.
- 데이터베이스당 지원하는 최대 데이터 크기: 100TB.
- 풀의 데이터베이스에 지원하는 최대 총 데이터 크기: 100TB.
- 데이터베이스당 지원하는 최대 트랜잭션 로그 처리량: 100MB.
- 풀의 데이터베이스에 지원하는 최대 총 트랜잭션 로그 처리량: 131.25MB/초.
- 각 하이퍼스케일 탄력적 풀에는 최대 25개의 데이터베이스가 있을 수 있습니다.
자세한 내용은 표준 시리즈, 프리미엄 시리즈 및 프리미엄 시리즈 메모리 최적화를 위한 하이퍼스케일 탄력적 풀의 리소스 제한을 참조하세요.
참고 항목
성능 프로필, 지원하는 기능 및 게시된 제한은 기능이 미리 보기 상태인 동안 변경될 수 있습니다. 따라서 워크로드의 정기적인 기능, 성능 및 크기 조정 테스트를 통해 사용 사례의 유효성을 검사하는 것이 가장 좋습니다.
제한 사항
다음 제한 사항을 고려하세요.
- 하이퍼스케일이 아닌 기존 탄력적 풀을 하이퍼스케일 버전으로 변경하는 것은 지원하지 않습니다. 변환 섹션에서는 사용할 수 있는 몇 가지 대안을 제공합니다.
- 하이퍼스케일 탄력적 풀의 버전을 하이퍼스케일이 아닌 버전으로 변경하는 것은 지원하지 않습니다.
- 하이퍼스케일 탄력적 풀에 있는 적격 데이터베이스를 "역방향 마이그레이션"하려면 먼저 이를 하이퍼스케일 탄력적 풀에서 제거해야 합니다. 그런 다음 독립 실행형 하이퍼스케일 데이터베이스를 범용 독립 실행형 데이터베이스로 "역방향 마이그레이션"할 수 있습니다.
- 하이퍼스케일 서비스 계층의 경우 영역 중복 지원은 데이터베이스 또는 탄력적 풀을 만드는 동안에만 지정할 수 있으며 리소스를 프로비전한 후에는 수정할 수 없습니다. 자세한 내용은 가용성 영역 지원으로 Azure SQL Database 마이그레이션을 참조하세요.
- 하이퍼스케일 탄력적 풀에 명명된 복제본을 추가하는 것은 지원하지 않습니다. 하이퍼스케일 데이터베이스의 명명된 복제본을 하이퍼스케일 탄력적 풀에 추가하려고 하면
UnsupportedReplicationOperation오류가 발생하게 됩니다. 대신 명명된 복제본 단일 하이퍼스케일 데이터베이스로 만듭니다.
영역 중복 탄력적 풀 고려 사항
영역 중복 하이퍼스케일 탄력적 풀에 대한 몇 가지 고려 사항은 다음과 같습니다.
참고 항목
영역 중복이 있는 하이퍼스케일 탄력적 풀을 현재 미리 보기로 제공합니다. 자세한 내용은 블로그 게시물: 영역 중복이 있는 하이퍼스케일 탄력적 풀을 참조하세요.
- 영역 중복 스토리지 중복(ZRS 또는 GZRS)이 있는 데이터베이스만 영역 중복을 사용하여 하이퍼스케일 탄력적 풀에 추가할 수 있습니다.
- 영역 중복 하이퍼스케일 탄력적 풀에 추가하려면 영역 중복 및 영역 중복 백업 스토리지(ZRS 또는 GZRS)를 사용하여 독립 실행형 하이퍼스케일 데이터베이스를 만들어야 합니다. 영역 중복이 없는 하이퍼스케일 데이터베이스의 경우 영역 중복 옵션을 사용하도록 설정된 새 하이퍼스케일 데이터베이스로 데이터를 전송합니다. 데이터베이스 복사, 특정 시점 복원 또는 지역 복제본을 사용하여 클론을 만들어야 합니다. 자세한 내용은 재배포(하이퍼스케일)를 참조하세요.
- 하이퍼스케일 데이터베이스를 한 탄력적 풀에서 다른 탄력적 풀로 이동하려면 영역 중복 및 영역 중복 백업 스토리지 설정이 일치해야 합니다.
- 다른 하이퍼스케일이 아닌 서비스 계층에서 영역 중복이 있는 하이퍼스케일 탄력적 풀로 데이터베이스를 변환하려면 다음을 수행합니다.
- Azure Portal을 통해 먼저 영역 중복 및 ZRS(영역 중복 백업 스토리지)를 모두 사용하도록 설정합니다. 그런 다음 영역 중복 하이퍼스케일 탄력적 풀에 데이터베이스를 추가할 수 있습니다.
- PowerShell을 통해 먼저 영역 중복을 사용하도록 설정합니다. 그런 다음 Set-AzSqlDatabase를 사용하여
-BackupStorageRedundancy매개 변수를 영역 중복 백업 스토리지(ZRS 또는 GZRS)를 지정하는 데 사용하는지 확인합니다.
알려진 문제
| 문제 | 추천 |
|---|---|
하이퍼스케일이 아닌 많은 데이터베이스를 하이퍼스케일 탄력적 풀에 추가할 때 Could not perform the operation because server would exceed the allowed Database Throughput Unit quota of 54000. (Code: ServerDtuQuotaExceeded) 오류가 발생할 수 있습니다. 메시지는 DTU(데이터베이스 처리량 단위)를 참조하지만 각 논리 서버에 적용되는 공유 DTU/vCore 할당량과 관련이 있습니다. 이 문제는 vCore가 개별 데이터베이스 수준에서 잘못 계산되는 결함으로 인해 발생합니다. |
다음은 문제를 해결하는 몇 가지 옵션입니다. • 하이퍼스케일 탄력적 풀에 데이터베이스를 한 번에 하나씩 추가합니다. • 하이퍼스케일 탄력적 풀에 데이터베이스를 추가하기 전에 먼저 데이터베이스를 독립 실행형 하이퍼스케일 DB로 변환합니다. • 여기에 설명된 대로 서버 수준 할당량 증가를 요청합니다. |
영역 중복 하이퍼스케일 탄력적 풀에서 다른 지역의 영역 중복 하이퍼스케일 탄력적 풀로 데이터베이스에 대한 지역에서 복제를 설정하면 Provisioning of zone redundant Hyperscale database with local backup redundancy is not supported. Zone redundant Hyperscale databases must use either zone or geo zone backup redundancy 오류와 함께 실패합니다. 이 오류는 두 번째 하이퍼스케일 탄력적 풀이 영역 중복이거나 동일한 지역에 있는 경우 발생하지 않습니다. |
이 문제를 해결하려면 Azure PowerShell을 사용하고 명령줄 New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false에서 비영역 중복을 명시적으로 지정할 수 있습니다. |
| 영역 중복 하이퍼스케일 탄력적 풀에서 다른 지역의 영역 중복 하이퍼스케일 탄력적 풀이 있는 장애 조치(failover) 그룹에 데이터베이스를 추가하면 내부적으로 실패하지만 작업이 진행되지 않고 실행 중인 것처럼 보일 수 있습니다. SSMS와 같은 도구를 사용할 때 지역 보조 데이터베이스를 볼 수 있지만 지역 보조 데이터베이스에 연결하여 사용할 수는 없습니다. 장애 조치(failover) 그룹은 지역 보조 데이터베이스에 대해 "시드 0%" 상태를 표시할 수 있습니다. 두 번째 하이퍼스케일 탄력적 풀이 영역 중복인 경우에는 이 문제가 발생하지 않습니다. | 이 문제를 해결하려면 명령줄 New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false에서 비영역 중복성을 명시적으로 지정하여 Azure PowerShell을 사용하여 장애 조치(failover) 그룹 외부에서 지역에서 복제를 설정하세요. 그런 다음 데이터베이스를 장애 조치(failover) 그룹에 추가할 수 있습니다. |
드물게 하이퍼스케일 데이터베이스를 탄력적 풀로 이동/복원/복사하려고 할 때 45122 - This Hyperscale database cannot be added into an elastic pool at this time. In case of any questions, please contact Microsoft support 오류가 발생할 수 있습니다. |
이 제한은 구현 관련 세부 정보 때문입니다. 이 오류가 문제가 되면 지원 인시던트를 제출하고 도움을 요청하세요. |
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기