동적 관리 뷰를 사용하여 성능 모니터링
적용 대상:![]() Fabric의 Azure SQL Database
Fabric의 Azure SQL Database ![]() SQL 데이터베이스
SQL 데이터베이스
동적 관리 뷰(DMV)를 사용하여 차단되거나 오래 실행되는 쿼리, 리소스 병목 현상, 최적이 아닌 쿼리 계획 등으로 인해 발생할 수 있는 워크로드 성능을 모니터링하고 성능 문제를 진단할 수 있습니다.
이 문서에서는 T-SQL을 통해 동적 관리 뷰를 쿼리하여 일반적인 성능 문제를 감지하는 방법에 대한 정보를 제공합니다. 다음과 같은 쿼리 도구를 사용할 수 있습니다.
사용 권한
Azure SQL 데이터베이스에서 컴퓨팅 크기, 배포 옵션 및 DMV의 데이터에 따라 DMV를 쿼리하는 데 VIEW DATABASE STATE, VIEW SERVER PERFORMANCE STATE 또는 VIEW SERVER SECURITY STATE 권한이 필요할 수 있습니다. 마지막 두 사용 권한은 VIEW SERVER STATE 사용 권한에 포함됩니다. 서버 상태 보기 권한은 해당 서버 역할의 멤버십을 통해 부여됩니다. 특정 DMV를 쿼리하는 데 필요한 권한을 확인하려면 동적 관리 뷰를 참조하고 DMV를 설명하는 문서를 찾습니다.
데이터베이스 사용자에게 VIEW DATABASE STATE 권한을 부여하려면 다음 쿼리를 실행하여 database_user를 데이터베이스의 사용자 본인 이름으로 바꾸세요.
GRANT VIEW DATABASE STATE TO [database_user];
논리 서버에서 login_name라는 이름의 로그인에 ##MS_ServerStateReader## 서버 역할의 멤버십을 부여하려면 master 데이터베이스에 연결한 다음 다음 쿼리를 예로 실행합니다.
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
권한 부여가 적용되려면 몇 분 정도 걸릴 수 있습니다. 자세한 내용은 서버 수준 역할의 제한 사항을 참조하세요.
리소스 사용 모니터링
다음 보기를 사용하여 데이터베이스 수준에서 리소스 사용량을 모니터링할 수 있습니다. 이러한 보기는 독립 실행형 데이터베이스 및 탄력적 풀의 데이터베이스에 적용할 수 있습니다.
다음 보기를 사용하여 Elastic Pool 수준에서 리소스 사용량을 모니터링할 수 있습니다.
Azure Portal에서 또는 쿼리 저장소를 통해 SQL Database 쿼리 성능 Insight를 사용하여 쿼리 수준에서 리소스 사용량을 모니터링할 수 있습니다.
sys.dm_db_resource_stats
모든 데이터베이스에 sys.dm_db_resource_stats 뷰를 사용할 수 있습니다. sys.dm_db_resource_stats 보기에서는 컴퓨팅 크기의 한도에 상대적인 최근 리소스 사용 데이터를 보여 줍니다. CPU, 데이터 I/O, 로그 쓰기, 작업자 스레드 및 메모리 사용량의 백분율은 15초 간격마다 기록되며 약 1시간 동안 기본 달성됩니다.
이 보기는 세분화된 리소스 사용량 데이터를 제공하므로 현재 상태 분석 또는 문제 해결을 위해서는 먼저 sys.dm_db_resource_stats을 사용합니다. 예를 들어 이 쿼리는 지난 1시간 동안의 현재 데이터베이스에 대한 평균 및 최대 리소스 사용량을 보여줍니다.
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
더 많은 쿼리를 보려면 sys.dm_db_resource_stats에서 예시를 참조하세요.
sys.resource_stats
master 데이터베이스의 sys.resource_stats 뷰에는 특정 서비스 계층 및 컴퓨팅 크기에서 데이터베이스의 성능을 모니터링하는 데 도움이 되는 추가 정보가 있습니다. 데이터는 5분마다 수집되며 약 14일 동안 유지됩니다. 이 뷰는 데이터베이스가 리소스를 사용하는 방식에 대한 장기적인 기록 분석에 유용합니다.
다음 그래프는 P2 컴퓨팅 크기를 가진 프리미엄 데이터베이스의 CPU 리소스 사용량을 일주일 동안 시간대별로 보여줍니다. 이 그래프는 월요일부터 5일의 근무일과 애플리케이션 사용량이 훨씬 적은 주말까지 표시되어 있습니다.
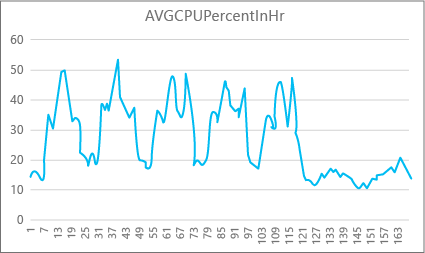
데이터에 따르면 이 데이터베이스는 현재 P2 컴퓨팅 크기에 비해 CPU 사용량이 50%를 약간 넘는 최대 CPU 부하가 화요일 정오에 있습니다. 애플리케이션의 리소스 프로필에서 CPU가 가장 지배적인 요인인 경우 항상 워크로드를 충족하는 데 적합한 컴퓨팅 크기는 P2임을 판단할 수 있습니다. 애플리케이션이 시간이 지남에 따라 증가할 것으로 예상되는 경우 애플리케이션이 성능 수준 제한에 도달하지 않도록 추가 리소스 버퍼를 사용하는 것이 좋습니다. 컴퓨팅 크기를 늘리면 특히 대기 시간이 중요한 환경에서 데이터베이스가 요청을 효과적으로 처리하므로 충분한 능력을 갖고 있지 않은 경우 발생할 수 있는 고객에게 보이는 오류를 방지하는 데 도움이 될 수 있습니다.
다른 애플리케이션 유형에서는 동일한 그래프를 다르게 해석할 수 있습니다. 예를 들어 애플리케이션이 매일 급여 데이터를 처리하려고 하고 차트가 동일하다면, 이러한 종류의 "일괄 작업" 모델은 P1 컴퓨팅 크기에서 잘 작동할 수 있습니다. P1 컴퓨팅 크기는 100 DTU이고, 이에 반해 P2 컴퓨팅 크기는 200 DTU입니다. P1 컴퓨팅 크기는 P2 컴퓨팅 크기의 절반 성능을 제공합니다. 따라서 P2에서의 CPU 사용량 50%는 P1에서의 CPU 사용량 100%와 같습니다. 애플리케이션에 시간 제한이 없는 경우, 작업이 오늘 안에 완료된다면 완료되는 데 2시간이 걸리든 2.5시간이 걸리든 중요하지 않을 수 있습니다. 이 범주에 속하는 애플리케이션은 아마도 P1 컴퓨팅 크기를 사용할 수 있을 것입니다. 하루 중 리소스 사용량이 낮은 시간대가 있다는 사실을 활용할 수 있습니다. 즉, "최고" 시간대의 작업을 하루 중 사용량이 낮은 시간대 중 하나로 나눌 수 있습니다. 작업이 매일 제 시간에 완료될 수 있다면 P1 컴퓨팅 크기는 이러한 종류의 애플리케이션에 적합할 수 있으며 비용을 절감할 수 있습니다.
데이터베이스 엔진은 각 논리 서버의 master 데이터베이스의 sys.resource_stats 보기에서 각 활성 데이터베이스에 대해 사용된 리소스 정보를 노출합니다. 보기의 데이터는 5분 간격으로 집계됩니다. 이 데이터가 테이블에 표시되는 데 몇 분이 걸릴 수 있으므로 sys.resource_stats는 실시간에 가까운 분석보다는 기록 분석에 더 유용합니다. sys.resource_stats 보기를 쿼리하여 데이터베이스의 최근 기록을 확인하고 필요할 때 선택한 컴퓨팅 크기가 원하는 성능을 제공했는지 여부를 검증합니다.
참고 항목
다음 예제에서 sys.resource_stats을 쿼리하려면 master 데이터베이스에 연결되어 있어야 합니다.
이 예제에서는 sys.resource_stats의 데이터를 보여줍니다.
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
다음 예제는 sys.resource_stats 카탈로그 뷰를 사용하여 데이터베이스가 리소스를 사용하는 방법에 대한 정보를 가져올 수 있는 다양한 방법을 보여 줍니다.
사용자 데이터베이스
userdb1의 지난 주 리소스 사용량을 확인하고자 할 때 이 쿼리를 실행하여 자신의 데이터베이스 이름으로 대체할 수 있습니다.SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;워크로드가 컴퓨팅 크기에 얼마나 적합한지 평가하려면 리소스 메트릭의 각 측면(CPU, 데이터 I/O, 로그 쓰기, 작업자 수, 세션 수)까지 집중 분석해야 합니다. 다음은 데이터베이스가 프로비저닝된 각 컴퓨팅 크기에 대해 이러한 리소스 메트릭의 평균값 및 최댓값을 보고하기 위해
sys.resource_stats을 사용하는 수정된 쿼리입니다.SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;각 리소스 메트릭의 평균값 및 최댓값에 대한 이 정보를 사용하여 선택한 컴퓨팅 크기에 워크로드가 얼마나 적합한지 평가할 수 있습니다. 일반적으로
sys.resource_stats의 평균 값은 목표 크기를 정하는 기준으로 사용될 수 있습니다.DTU 구매 모델 데이터베이스의 경우:
예를 들어 S2 컴퓨팅 크기와 함께 표준 서비스 계층을 사용할 수 있습니다. CPU와 I/O 읽기 및 쓰기의 평균 사용 백분율은 40% 미만, 평균 작업자 수는 50명 미만, 평균 세션 수는 200개 미만입니다. 워크로드가 S1 컴퓨팅 크기에 적합할 수 있습니다. 데이터베이스가 작업자 및 세션 제한에 적합한지 여부는 쉽게 확인할 수 있습니다. 데이터베이스가 더 낮은 컴퓨팅 크기에 적합한지 확인하려면 더 낮은 컴퓨팅 크기의 DTU 수를 현재 컴퓨팅 크기의 DTU 수로 나눈 다음 그 결과에 100을 곱합니다.
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40결과는 두 컴퓨팅 크기 간의 상대적 성능 차이를 백분율로 나타낸 값입니다. 리소스 사용량이 이 비율을 초과하지 않으면 워크로드가 더 낮은 컴퓨팅 크기에 적합할 수 있습니다. 그러나 리소스 사용량 값의 모든 범위를 살펴보고 데이터베이스 워크로드가 더 낮은 컴퓨팅 크기에 얼마나 자주 적합한지 백분율로 결정해야 합니다. 다음 쿼리는 이 예에서 계산된 40%의 임계값을 기준으로 리소스 규격당 적합률을 출력합니다.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;데이터베이스 서비스 계층에 따라 워크로드가 더 낮은 컴퓨팅 크기에 적합한지 여부를 결정할 수 있습니다. 데이터베이스 워크로드 목표가 99.9%이고 앞의 쿼리가 세 가지 리소스 차원에 대해 99.9%보다 큰 값을 반환할 경우 워크로드는 더 낮은 단계의 컴퓨팅 크기에 적합할 가능성이 높습니다.
적합률을 살펴보면 목표를 충족하기 위해 더 높은 단계의 컴퓨팅 크기로 이동해야 하는지 여부를 알 수 있습니다. 예를 들어 지난 한 주 동안의 샘플 데이터베이스에 대한 CPU 사용량은 다음과 같습니다.
평균 CPU 비율 최대 CPU 비율 24.5 100.00 평균 CPU는 컴퓨팅 크기 한도의 약 4분의 1이며 데이터베이스의 컴퓨팅 크기에 적합합니다.
DTU 구매 모델 및 vCore 구매 모델 데이터베이스의 경우:
최댓값은 데이터베이스가 컴퓨팅 크기 한도에 도달했음을 나타냅니다. 더 높은 단계의 컴퓨팅 크기로 전환해야 하나요? 워크로드가 100%에 도달하는 횟수를 살펴보고 이를 데이터베이스 워크로드 목표와 비교하세요.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;이러한 백분율은 워크로드가 현재 컴퓨팅 크기에서 맞는 샘플의 수입니다. 이 쿼리가 세 가지 리소스 차원 중 하나라도 99.9% 미만의 값을 반환하는 경우 샘플링된 평균 워크로드가 한도를 초과한 것입니다. 한 단계 높은 컴퓨팅 크기로 전환하거나 애플리케이션 튜닝 기술을 사용하여 데이터베이스의 부하를 줄이는 것을 고려하세요.
sys.dm_elastic_pool_resource_stats
적용 대상:![]() Azure SQL Database만 해당
Azure SQL Database만 해당
마찬가지로 sys.dm_db_resource_statssys.dm_elastic_pool_resource_stats Azure SQL Database 탄력적 풀에 대한 최신 및 세분화된 리소스 사용량 현황 데이터를 제공합니다. 특정 데이터베이스가 아닌 전체 풀에 대한 리소스 사용량 현황 데이터를 제공하기 위해 Elastic Pool의 모든 데이터베이스에서 보기를 쿼리할 수 있습니다. 이 DMV에서 보고한 백분율 값은 Elastic Pool의 한도에 해당합니다. 이 값은 풀의 데이터베이스에 대한 한도보다 높을 수 있습니다.
이 예제에서는 지난 15분 동안의 현재 Elastic Pool에 대한 요약된 리소스 사용 현황 데이터를 보여 줍니다.
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
리소스 사용 현황이 상당한 기간 동안 100%에 도달하면 동일한 Elastic Pool의 개별 데이터베이스에 대한 리소스 사용 현황을 검토하여 각 데이터베이스가 풀 수준 리소스 사용 현황에 얼마나 기여하는지 확인해야 할 수 있습니다.
sys.elastic_pool_resource_stats
적용 대상:![]() Azure SQL Database만 해당
Azure SQL Database만 해당
sys.resource_stats와 마찬가지로 master 데이터베이스의 sys.elastic_pool_resource_stats는 논리 서버의 모든 Elastic Pool에 대한 과거 리소스 사용 현황 데이터를 제공합니다. 사용량 추세 분석을 포함하여 지난 14일간의 기록 모니터링에 sys.elastic_pool_resource_stats를 사용할 수 있습니다.
이 예제에서는 현재 논리 서버의 모든 Elastic Pool에 대해 지난 7일 동안의 요약된 리소스 사용 현황 데이터를 보여 줍니다. master 데이터베이스에서 쿼리를 실행합니다.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
동시 요청
현재 동시 요청 수를 보려면 사용자 데이터베이스에서 이 쿼리를 실행하세요.
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
이는 단일 시점의 스냅샷일 뿐입니다. 워크로드 및 동시 요청 요구 사항을 더 깊이 이해하려면 시간 변화에 따라 여러 샘플을 수집해야 합니다.
평균 요청 속도
이 예에서는 일정 기간 동안 데이터베이스 또는 Elastic Pool의 데이터베이스에 대한 평균 요청 속도를 찾는 방법을 보여 줍니다. 이 예에서는 기간이 30초로 설정되어 있습니다. WAITFOR DELAY 문을 수정하여 조정할 수 있습니다. 사용자 데이터베이스에서 이 쿼리를 실행합니다. 데이터베이스가 Elastic Pool에 있고 충분한 권한이 있는 경우 결과에 Elastic Pool의 다른 데이터베이스가 포함됩니다.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
현재 세션
현재 활성 세션 수를 보려면 데이터베이스에서 이 쿼리를 실행하세요.
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
이 쿼리는 지정 시간 수를 반환합니다. 시간 변화에 따라 여러 샘플을 수집하면 세션 사용 현황을 가장 잘 이해할 수 있습니다.
최근 요청, 세션 및 작업자 기록
이 예에서는 데이터베이스 또는 Elastic Pool의 데이터베이스에 대한 요청, 세션 및 작업자 스레드의 최근 사용 기록을 반환합니다. 각 행은 데이터베이스의 특정 시점에 리소스 사용 현황의 스냅샷을 나타냅니다. requests_per_second 열은 snapshot_time로 끝나는 시간 간격 동안의 평균 요청 속도입니다. 데이터베이스가 Elastic Pool에 있고 충분한 권한이 있는 경우 결과에 Elastic Pool의 다른 데이터베이스가 포함됩니다.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
데이터베이스 및 개체 크기 계산
다음 쿼리는 데이터베이스의 데이터 크기(메가바이트)를 반환합니다.
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
다음 쿼리는 데이터베이스의 개별 개체 크기(MB)를 반환합니다.
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
CPU 성능 문제 식별
이 섹션은 상위 CPU 소비자인 개별 쿼리를 식별하는 데 도움이 됩니다.
CPU 사용량이 장시간 80% 이상인 경우 CPU 문제가 현재 발생 중인지 또는 과거에 발생했는지에 관계없이 다음 문제 해결 단계를 고려하세요. 이 섹션의 단계에 따라 CPU를 가장 많이 사용하는 쿼리를 사전에 식별하고 이를 조정할 수도 있습니다. 경우에 따라 CPU 사용량을 줄이면 데이터베이스 및 Elastic Pool을 축소하고 비용을 절감할 수 있습니다.
문제 해결 단계는 독립 실행형 데이터베이스 및 Elastic Pool의 데이터베이스에 대해 동일합니다. 사용자 데이터베이스에서 모든 쿼리를 실행합니다.
CPU 문제가 현재 발생 중인 경우
지금 문제가 발생하는 경우 다음과 같은 두 가지 시나리오가 있을 수 있습니다.
점증적으로 CPU 사용량이 높은 개별 쿼리가 많음
다음 쿼리를 사용하여 쿼리 해시별로 상위 쿼리를 식별할 수 있습니다:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
CPU를 사용하는 장기 실행 쿼리가 여전히 실행 중
다음 쿼리를 사용하여 이러한 쿼리를 식별합니다.
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
CPU 문제가 과거에 발생한 경우
과거에 문제가 발생했고 근본 원인을 분석하려면 쿼리 저장소를 사용합니다. 데이터베이스 액세스 권한이 있는 사용자는 T-SQL을 사용하여 쿼리 저장소 데이터를 쿼리할 수 있습니다. 기본적으로 쿼리 저장소는 1시간 간격으로 집계 쿼리 통계를 캡처합니다.
CPU 사용량이 많은 쿼리에 대한 작업을 살펴보려면 다음 쿼리를 사용합니다. 이 쿼리는 CPU 사용량이 많은 상위 15개 쿼리를 반환합니다. 지난 2시간이 아닌 다른 기간을 보려면
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()를 변경해야 합니다.-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;문제가 있는 쿼리를 파악한 후에는 CPU 사용률을 줄이기 위해 해당 쿼리를 튜닝해야 합니다. 또는 문제를 해결하기 위해 데이터베이스 또는 Elastic Pool의 컴퓨팅 크기를 늘리도록 선택할 수 있습니다.
Azure SQL Database에서의 CPU 성능 처리에 관한 자세한 내용은 Azure SQL Database의 높은 CPU 진단 및 문제 해결을 참조합니다.
I/O 성능 문제 식별
스토리지 입출력(I/O) 성능 문제를 식별할 때 가장 많이 발생하는 대기 유형은 다음과 같습니다.
PAGEIOLATCH_*데이터 파일 I/O 문제(
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP포함). 대기 유형 이름에 IO가 있으면 I/O 문제를 가리키는 것입니다. 페이지 래치 대기 이름에 IO가 없으면 스토리지 성능과 관련이 없는 다른 유형의 문제(예:tempdb경합)를 가리킵니다.WRITE_LOG트랜잭션 로그 I/O 문제.
I/O 문제가 현재 발생 중인 경우
sys.dm_exec_requests 또는 sys.dm_os_waiting_tasks를 사용하여 wait_type 및 wait_time을 확인합니다.
데이터 및 로그 I/O 사용량 식별
다음 쿼리를 사용하여 데이터 및 로그 I/O 사용량을 식별합니다.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
sys.dm_db_resource_stats 사용 예제에 대한 자세한 내용은 이 문서의 뒷부분에 있는 리소스 사용 모니터링 섹션을 참조하세요.
I/O 제한에 도달하는 경우 두 가지 옵션이 있습니다.
- 컴퓨팅 크기 또는 서비스 계층 업그레이드
- 가장 많은 I/O를 사용하는 쿼리를 식별하여 튜닝
쿼리 저장소를 사용하여 버퍼 관련 I/O 확인
I/O 관련 대기 시간별로 상위 쿼리를 식별하려면 다음 쿼리 저장소 쿼리를 사용하여 지난 2시간 동안의 추적된 활동을 볼 수 있습니다.
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
avg_physical_io_reads 및 avg_num_physical_io_reads 열에 큰 값이 있는 쿼리에 초점을 맞춘 sys.query_store_runtime_stats 보기를 사용할 수도 있습니다.
WRITELOG 대기에 대한 총 로그 I/O 보기
대기 유형이 WRITELOG면 다음 쿼리를 사용하여 총 로그 I/O를 문별로 봅니다.
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
tempdb 성능 문제 식별
tempdb 문제와 관련된 일반 대기 유형은 PAGELATCH_*입니다(PAGEIOLATCH_* 아님). 그러나 PAGELATCH_* 대기는 항상 tempdb 경합이 있다는 의미가 아닙니다. 이 대기는 동일한 데이터 페이지를 대상으로 하는 동시 요청으로 인해 사용자 개체 데이터 페이지 경합이 있다는 의미일 수도 있습니다. tempdb 경합을 추가로 확인하려면 sys.dm_exec_requests를 사용하여 wait_resource 값이 2:x:y로 시작하는지 확인합니다. 여기서 2는 tempdb 데이터베이스 ID, x는 파일 ID, y는 페이지 ID입니다.
tempdb 경합의 경우 tempdb를 사용하는 애플리케이션 코드를 줄이거나 다시 쓰는 것이 일반적인 방법입니다. 일반적인 tempdb 사용 영역은 다음과 같습니다.
- 임시 테이블
- 테이블 변수
- 테이블 반환 매개 변수
- 정렬, 해시 조인 및 스풀을 사용하는 쿼리 계획이 있는 쿼리
자세한 내용은 Azure SQL의 tempdb를 참조하세요.
Elastic Pool의 모든 데이터베이스는 동일한 tempdb 데이터베이스를 공유합니다. 한 데이터베이스의 높은 tempdb 공간 사용률이 동일한 Elastic Pool의 다른 데이터베이스에 영향을 줄 수 있습니다.
테이블 변수 및 임시 테이블을 사용하는 상위 쿼리
테이블 변수 및 임시 테이블을 사용하는 상위 쿼리를 식별하려면 다음 쿼리를 사용합니다.
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
장기 실행 트랜잭션 식별
장기 실행 트랜잭션을 식별하려면 다음 쿼리를 사용합니다. 장기 실행 트랜잭션은 PVS(영구 버전 저장소) 정리를 방해합니다. 자세한 내용은 가속 데이터베이스 복구 문제 해결을 참조하세요.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
메모리 부여 대기 성능 문제 식별
상위 대기 유형이 RESOURCE_SEMAPHORE인 경우, 충분히 큰 메모리 허가를 받을 때까지 쿼리 실행을 시작할 수 없는 메모리 허가 대기 문제가 발생할 수 있습니다.
RESOURCE_SEMAPHORE 대기가 가장 긴 대기인지 확인
다음 쿼리를 사용하여 RESOURCE_SEMAPHORE 대기가 가장 긴 대기인지 확인합니다. 또한 최근 기록에서 RESOURCE_SEMAPHORE의 대기 시간 순위가 상승하고 있는지도 알 수 있습니다. 메모리 부여 대기 문제 해결에 대한 자세한 내용은 SQL Server에서 메모리 부여로 인한 성능 저하 또는 메모리 부족 문제 해결을 참조하세요.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
메모리를 많이 사용하는 문 식별
Azure SQL Database에서 메모리 부족 오류가 발생하면 sys.dm_os_out_of_memory_events를 검토합니다. 자세한 내용은 Azure SQL Database에서 메모리 부족 오류 문제 해결을 참조하세요.
먼저 다음 스크립트를 수정하여 start_time 및 end_time 관련 값을 업데이트합니다. 그런 다음, 다음 쿼리를 실행하여 메모리를 많이 사용하는 문을 식별합니다.
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
상위 10개 활성 메모리 부여 식별
다음 쿼리를 사용하여 상위 10개의 활성 메모리 부여를 식별합니다.
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
연결 모니터링
sys.dm_exec_connections 뷰를 사용하여 특정 데이터베이스에 설정된 연결에 관한 정보 및 각 연결의 세부 정보를 검색할 수 있습니다. 데이터베이스가 Elastic Pool에 있고 충분한 권한이 있는 경우, 이 보기는 Elastic Pool의 모든 데이터베이스에 대한 연결 집합을 반환합니다. 또한 sys.dm_exec_sessions 뷰는 모든 활성 사용자 연결 및 내부 작업에 대한 정보를 검색할 때 유용합니다.
현재 세션 보기
다음 쿼리는 현재 연결 및 세션에 대한 정보를 검색합니다. 모든 연결 및 세션을 보려면 WHERE 절을 제거합니다.
데이터베이스에 대한 VIEW DATABASE STATE 권한이 있는 경우에만 sys.dm_exec_requests 및 sys.dm_exec_sessions 보기를 실행할 때 데이터베이스에서 실행 중인 모든 세션을 볼 수 있습니다. 그렇지 않으면 현재 세션만 볼 수 있습니다.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
쿼리 성능 모니터링
느리거나 오래 실행되는 쿼리는 상당한 시스템 리소스를 소모할 수 있습니다. 이 섹션에서는 sys.dm_exec_query_stats 동적 관리 뷰를 사용하여 동적 관리 뷰를 통해 몇 가지 일반적인 쿼리 성능 문제를 감지하는 방법을 보여 줍니다. 이 뷰에는 캐시된 계획 내에 쿼리 문당 하나의 행이 포함되며 행의 수명은 계획 자체에 연결되어 있습니다. 캐시에서 계획이 제거되면 뷰에서도 해당 행이 제거됩니다. 예를 들어 OPTION (RECOMPILE)가 사용되어 쿼리에 캐시된 계획이 없는 경우 이 보기의 결과에는 해당 쿼리가 표시되지 않습니다.
CPU 시간별 상위 쿼리 찾기
다음 예제는 실행당 평균 CPU 시간을 기준으로 상위 15개 쿼리에 대한 정보를 반환합니다. 이 예제에서는 쿼리 해시에 따라 쿼리를 집계하므로 논리적으로 동등한 쿼리가 누적 리소스 사용량별로 그룹화됩니다.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
누적 CPU 시간에 대한 쿼리 계획 모니터링
또한 비효율적인 쿼리 계획 때문에 CPU 사용량이 증가할 수 있습니다. 다음 예제에서는 최근 기록에서 가장 많은 누적 CPU를 사용하는 쿼리를 확인합니다.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
차단된 쿼리 모니터링
느린 속도로 또는 장시간 실행하는 쿼리는 과도한 리소스 소비를 유발할 수 있으며 차단된 쿼리로 인한 결과일 수 있습니다. 차단의 원인으로 부실한 애플리케이션 디자인, 잘못된 쿼리 계획, 유용한 인덱스 부족 등이 있습니다.
sys.dm_tran_locks 뷰를 사용하여 데이터베이스의 현재 잠금 활동에 대한 정보를 가져올 수 있습니다. 코드 예제를 보려면 sys.dm_tran_locks를 참조하세요. 차단 문제 해결에 대한 자세한 내용은 Azure SQL 차단 문제 이해 및 해결을 참조하세요.
교착 상태 모니터링
경우에 따라 둘 이상의 쿼리가 서로를 차단하여 교착 상태가 발생할 수 있습니다.
확장 이벤트 추적을 만들어 교착 상태 이벤트를 캡처한 다음 쿼리 저장소에서 관련 쿼리 및 해당 실행 계획을 찾을 수 있습니다. 자세한 내용은 AdventureWorksLT에서 교착 상태 발생 랩을 포함하여 Azure SQL Database의 교착 상태 분석 및 방지를 참조하세요. 교착 상태에 빠질 수 있는 리소스에서 해당 유형에 대해 자세히 알아보세요.