Azure SQL Database에서 애플리케이션 및 데이터베이스 성능 조정
적용 대상: ![]() Azure SQL Database
Azure SQL Database
Azure SQL Database에서 발생한 성능 문제를 발견한 경우, 이 문서는 다음과 같은 작업을 돕기 위해 작성되었습니다.
- 애플리케이션을 튜닝하고 성능을 향상시킬 수 있는 몇 가지 모범 사례를 적용합니다.
- 인덱스 및 쿼리를 변경하여 데이터 작업을 보다 효율적으로 수행할 수 있도록 데이터베이스를 튜닝합니다.
이 문서에서는 사용자가 Azure SQL Database Database Advisor 권장 사항과 자동 튜닝 권장 사항(해당되는 경우)을 이미 수행했다고 가정합니다. 또한 모니터링 및 튜닝 개요, 쿼리 저장소를 사용하여 성능 모니터링, 성능 문제 해결과 관련된 문서를 검토했다고 가정합니다. 또한 이 문서에서는 데이터베이스에 더 많은 리소스를 제공하기 위해 컴퓨팅 크기 또는 서비스 계층을 늘려 해결할 수 있는 CPU 리소스 사용률과 관련된 성능 문제가 없다고 가정합니다.
참고 항목
Azure SQL Managed Instance에서의 유사한 지침은 Azure SQL Managed Instance에서 성능을 위해 애플리케이션과 데이터베이스 튜닝을 참조하세요.
애플리케이션 튜닝
기존 온-프레미스 SQL Server에서 초기 용량 계획 프로세스는 프로덕션 애플리케이션의 실행 프로세스에서 분리된 경우가 많았습니다. 하드웨어 및 제품 라이선스를 먼저 구매한 뒤 나중에 성능 튜닝을 수행합니다. Azure SQL을 사용하는 경우 애플리케이션을 실행하고 튜닝하는 과정을 함께 사용하는 것이 좋습니다. 주문형 용량 지불 모델에서는 애플리케이션에 대해 어림짐작한 미래 성장 계획(정확하지 않은 경우가 많음)을 기준으로 과도한 프로비전을 하지 않고, 애플리케이션을 튜닝하여 현재 필요한 최소 리소스를 사용할 수 있습니다.
일부 고객은 애플리케이션을 튜닝하지 않고 대신 하드웨어 리소스를 과도하게 프로비저닝하는 것을 선택할 수 있습니다. 이 방법은 사용량이 많은 기간 동안 주요 애플리케이션을 변경하지 않고자 할 때 적합할 수 있습니다. 그러나 애플리케이션을 튜닝하면 리소스 요구 사항을 최소화하고 월별 요금을 낮출 수 있습니다.
Azure SQL Database의 애플리케이션 설계 모범 사례 및 안티패턴
Azure SQL Database 서비스 계층은 애플리케이션의 성능 안정성과 예측 가능성을 개선하도록 설계되었지만 몇 가지 모범 사례는 컴퓨팅 크기에서의 리소스를 더 잘 활용하도록 애플리케이션을 튜닝하는 데 도움이 될 수 있습니다. 많은 애플리케이션이 더 높은 단계의 컴퓨팅 크기 또는 서비스 계층으로 전환하는 것만으로도 성능이 크게 향상되지만 일부 애플리케이션은 더 높은 수준의 서비스를 활용하기 위해 추가 튜닝이 필요합니다. 성능 향상을 위해 다음과 같은 특성을 가진 애플리케이션이라면 추가적인 애플리케이션 튜닝을 고려하세요.
"채팅량이 많은" 동작으로 인해 성능이 느린 애플리케이션
채팅량이 많은 애플리케이션은 네트워크 대기 시간에 민감한 데이터 액세스 작업을 과도하게 수행합니다. 이러한 종류의 애플리케이션은 데이터베이스에 대한 데이터 액세스 작업 수를 줄이기 위해 수정이 필요할 수 있습니다. 예를 들어 임시 쿼리를 일괄 처리하거나 쿼리를 저장 프로시저로 이동하는 등의 기술을 사용하여 애플리케이션 성능을 개선할 수 있습니다. 자세한 내용은 일괄 처리 쿼리를 참조하세요.
전체 단일 컴퓨터에서 지원하지 않는 집약적인 워크로드가 있는 데이터베이스
가장 높은 단계의 프리미엄 컴퓨팅 크기의 리소스를 초과하는 데이터베이스는 워크로드를 스케일 아웃하면 도움이 될 수 있습니다. 자세한 내용은 데이터베이스 간 분할 및 기능 분할을 참조하세요.
최적이 아닌 쿼리를 포함하고 있는 애플리케이션
제대로 튜닝되지 않은 쿼리가 있는 애플리케이션은 더 큰 컴퓨팅 크기의 이점을 얻지 못할 수 있습니다. 예를 들어 WHERE 절이 없거나 인덱스가 누락되거나 통계가 오래된 쿼리가 있습니다. 이러한 애플리케이션은 표준 쿼리 성능 튜닝 기술의 이점을 얻을 수 있습니다. 자세한 내용은 아래의 인덱스 누락 및 쿼리 튜닝 및 힌팅 섹션을 참조하세요.
최적이 아닌 데이터 액세스 설계를 포함하고 있는 애플리케이션
교착 상태와 같이 본질적인 데이터 액세스 동시성 문제가 있는 애플리케이션은 더 큰 컴퓨팅 크기에서 이점을 얻을 수 없습니다. Azure 캐싱 서비스 또는 다른 캐싱 기술을 사용하여 클라이언트 쪽에서 데이터를 캐싱하여 데이터베이스에 대한 왕복을 줄이는 것이 좋습니다. 애플리케이션 계층 캐싱을 참조하세요.
Azure SQL Database에서 교착 상태가 다시 발생하지 않도록 하려면 Azure SQL Database의 교착 상태 분석 및 방지를 참조하세요.
데이터베이스 튜닝
이 섹션에서는 애플리케이션의 최고 성능을 달성하고 가능한 최소한의 컴퓨팅 크기에서도 실행할 수 있도록 데이터베이스를 튜닝하는 데 사용할 수 있는 몇 가지 기술에 대해 설명합니다. 이 기술 중 일부는 기존 SQL Server 튜닝의 모범 사례와 동일하지만 일부 기술은 Azure SQL Database에만 해당합니다. 경우에 따라 데이터베이스에 사용된 리소스를 조사하고 추가 튜닝 영역을 찾으면 기존 SQL Server 기법을 확장하여 Azure SQL Database에서도 사용할 수 있습니다.
누락된 인덱스 식별 및 추가
OLTP 데이터베이스 성능의 일반적인 문제는 물리적 데이터베이스 설계와 관련이 있습니다. 데이터베이스 스키마를 (부하 또는 데이터 볼륨에서) 대규모로 테스트하지 않고 설계 및 배송하는 경우가 많습니다. 아쉽게도 쿼리 계획의 성능은 소규모로는 괜찮을 수 있지만 프로덕션 수준의 데이터 볼륨에서는 크게 저하될 수 있습니다. 이 문제의 가장 일반적인 원인은 쿼리의 필터 또는 기타 제한을 충족하는 적절한 인덱스가 없기 때문입니다. 인덱스 누락으로 인해 인덱스 검색으로도 충분한 상황에서도 테이블 검색을 수행하는 경우가 많습니다.
이 예제에서 선택한 쿼리 계획은 검색으로도 충분한 상황에서 검사를 사용합니다.
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
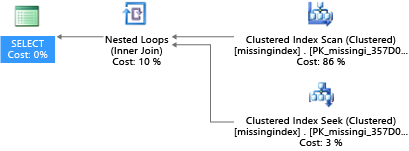
Azure SQL Database는 일반적인 인덱스 누락 조건을 찾아서 해결하는 데 도움이 될 수 있습니다. Azure SQL Database에 기본 제공되는 DMV는 인덱스가 쿼리를 실행하는 데 드는 예상 비용을 크게 줄이는 쿼리 컴파일을 살펴봅니다. 쿼리 실행 중에 데이터베이스 엔진은 각 쿼리 계획이 실행된 빈도를 추적하며, 실행 중인 쿼리 계획과 해당 인덱스가 있었던 예상 쿼리 계획 간의 예상 격차를 추적합니다. 이러한 DMV를 사용하면 물리적 데이터베이스 설계를 어떻게 변경해야 데이터베이스의 전반적 워크로드 비용과 실제 워크로드를 개선할 수 있을지 빠르게 추측할 수 있습니다.
이 쿼리를 사용하여 잠재적인 누락 인덱스를 평가할 수 있습니다.
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
이 예제의 쿼리를 통해 얻은 권장 사항:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
쿼리를 만든 후 해당 동일한 SELECT 문에서 다른 계획(스캔 대신 검색을 사용)을 선택한 다음 계획을 더 효율적으로 실행합니다.
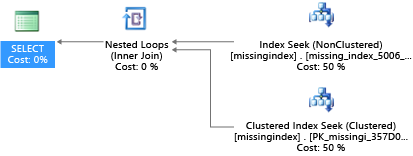
중요한 통찰력은 공유된 상용 시스템의 IO 용량은 전용 서버 시스템보다 제한적이라는 것입니다. 불필요한 IO를 최소화하여 서비스 계층의 각 컴퓨팅 크기별 리소스에서 시스템을 최대한 활용하는 것이 중요합니다. 적절한 물리적 데이터베이스 설계를 선택하면 개별 쿼리의 대기 시간을 크게 개선하고, 배율 단위당 처리되는 동시 요청의 처리량을 향상시키고, 쿼리를 충족하는 데 필요한 비용을 최소화할 수 있습니다.
누락된 인덱스 요청을 사용하여 인덱스를 조정하는 방법에 대한 자세한 내용은 누락된 인덱스 제안을 사용하여 비클러스터형 인덱스 조정을 참조하세요.
쿼리 튜닝 및 힌트
Azure SQL Database의 쿼리 최적화 프로그램은 기존 SQL Server 쿼리 최적화 프로그램과 유사합니다. 쿼리 튜닝 및 쿼리 최적화 프로그램의 추론 모델 제한 이해를 위한 대부분의 모범 사례는 Azure SQL Database에도 적용됩니다. Azure SQL Database에서 쿼리를 튜닝하는 경우 집계 리소스 요구를 줄이는 추가적인 이점이 있습니다. 애플리케이션을 더 낮은 단계의 컴퓨팅 크기로 실행할 수 있으므로 튜닝되지 않은 동급의 애플리케이션보다 더 저렴한 비용으로 실행할 수 있습니다.
SQL Server에서 일반적이며 Azure SQL Database에도 적용되는 예제는 쿼리 최적화 프로그램이 매개 변수를 "스니핑"하는 방법입니다. 컴파일하는 동안 쿼리 최적화 프로그램은 매개 변수의 현재 값을 평가하여 보다 최적의 쿼리 계획을 생성할 수 있는지 여부를 결정합니다. 이 전략은 대개 알려진 매개 변수 값을 사용하지 않고 컴파일된 계획보다 훨씬 더 빠른 쿼리 계획으로 이어질 수 있지만, 현재 이 전략은 Azure SQL Database에서 모두 불완전하게 작동합니다. (SQL Server 2022에 도입된 새로운 지능형 쿼리 성능 기능인 매개 변수 민감도 계획 최적화는 매개 변수가 있는 쿼리에 대해 캐시된 단일 계획이 모든 가능한 수신 매개 변수 값에 최적이 아닌 상황의 시나리오를 해결합니다. 현재 매개 변수 민감도 계획 최적화는 Azure SQL Database에서 사용할 수 없습니다.)
데이터베이스 엔진은 쿼리 힌트(지시문)를 지원하여 의도를 더 신중하게 지정하고 매개 변수 스니핑의 기본 동작을 재정의할 수 있도록 합니다. 특정 워크로드에 대한 기본 동작이 불완전할 때 힌트를 사용하도록 선택할 수 있습니다.
다음 예제에서는 쿼리 프로세서가 성능 및 리소스 요구 사항에 대해 모두 최적이 아닌 계획을 생성하는 방법을 보여 줍니다. 또한 이 예제에서는 쿼리 힌트를 사용하면 데이터베이스에 대한 쿼리 런타임 및 리소스 요구 사항을 줄일 수 있음을 보여 줍니다.
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
설정 코드는 t1 테이블에 기울어진(또는 불규칙하게 분산된) 데이터를 만듭니다. 최적의 쿼리 계획은 선택한 매개 변수에 따라 다릅니다. 아쉽게도 계획 캐싱 동작이 가장 일반적인 매개 변수 값을 기준으로 쿼리를 다시 컴파일하지 않는 경우도 있습니다. 따라서 다른 계획이 평균적으로 더 나은 계획 선택일 수 있더라도 최적이 아닌 계획이 캐시되어 여러 값에 사용될 수 있습니다. 그런 다음 쿼리 계획은 특수한 쿼리 힌트가 있다는 점을 제외하고 동일한 두 개의 저장 프로시저를 만듭니다.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
예제의 2부를 시작하기 전에 결과 원격 분석 데이터에서 결과가 분명히 구분되도록 적어도 10분 이상 기다리는 것이 좋습니다.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
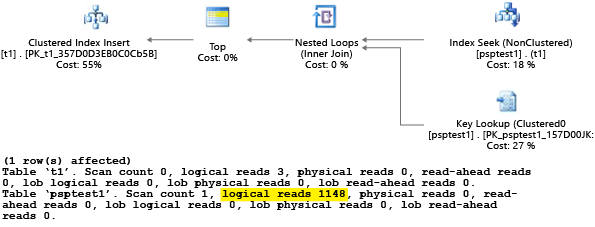
이 예제의 각 부분은 매개 변수가 있는 insert 문을 1,000번 실행하려고 시도합니다(테스트 데이터 집합으로 사용하기에 충분한 부하를 생성하기 위해). 저장 프로시저를 실행할 때 쿼리 프로세서는 첫 번째 컴파일 중에 프로시저에 전달되는 매개 변수 값을 검사합니다(매개 변수 "sniffing"). 프로세서는 매개 변수 값이 다른 경우에도 결과 계획을 캐시하고 이후 호출에 사용합니다. 최적의 계획은 모든 경우에 사용되지는 않을 수 있습니다. 경우에 따라 쿼리가 처음 컴파일된 시점의 특정 사례보다는 평균 사례에 더 적합한 계획을 선택하도록 최적화 프로그램을 안내해야 합니다. 이 예제에서 초기 계획은 매개 변수와 일치하는 각 값을 찾기 위해 모든 행을 읽는 "scan" 계획을 생성합니다.

값 1을 사용하여 절차를 실행했으므로 결과 계획은 값 1에 최적이었지만 테이블의 다른 모든 값에는 최적이 아니었습니다. 각 계획을 임의로 선택하면 계획이 더 느리게 수행되고 더 많은 리소스를 사용하기 때문에 원하는 결과가 아닐 수 있습니다.
SET STATISTICS IO를 ON으로 설정한 상태에서 테스트를 실행하면 이 예제의 논리적 스캔 작업은 백그라운드에서 수행됩니다. 계획에 의해 1,148회의 읽기가 수행되는 것을 볼 수 있습니다(평균 사례가 한 행만 반환하는 경우 비효율적).

예제의 두 번째 부분에서는 쿼리 힌트를 사용하여 컴파일 프로세스 중에 특정 값을 사용하도록 최적화 프로그램에 지시합니다. 이 경우 강제로 쿼리 프로세서가 매개 변수로 전달된 값을 무시하는 대신 UNKNOWN을 가정하게 합니다. 이는 테이블에서 평균적인 빈도가 포함된 값을 나타냅니다(기울이기 무시). 결과 계획은 이 예제의 1부에 있는 계획보다 평균적으로 더 빠르고 더 적은 리소스를 사용하는 검색 기반 계획입니다.
Azure SQL Database와 관련된 sys.resource_stats 시스템 보기에서 이 효과를 볼 수 있습니다. 테스트를 실행하는 시점과 데이터가 테이블을 채우는 시점 사이에 지연이 있습니다. 이 예제에서 1부는 22:25:00 기간 중 실행되었으며 2부는 22:35:00에 실행되었습니다. 이전 기간에는 같은 시간에 (계획 효율성 개선으로 인해) 이후 기간보다 더 많은 리소스를 사용했습니다.
SELECT TOP 1000 *
FROM sys.resource_stats
WHERE database_name = 'resource1'
ORDER BY start_time DESC

참고 항목
이 예제의 볼륨은 의도적으로 작게 만들었지만 최적이 아닌 매개 변수의 영향은 특히 큰 데이터베이스에서 크게 나타날 수 있습니다. 극단적인 경우 빠르면 몇 초, 느리면 몇 시간까지 차이가 있을 수 있습니다.
sys.resource_stats을 검사하여 한 테스트용 리소스가 다른 테스트보다 더 많거나 적은 리소스를 사용하는지 확인할 수 있습니다. 데이터를 비교할 때에는 sys.resource_stats 뷰에서 두 테스트가 동일한 5분 기간에 겹치지 않도록 테스트 시간을 구분합니다. 이 연습의 목표는 사용된 리소스의 총량을 최소화하는 것이지, 최대 리소스를 최소화하는 것이 아닙니다. 일반적으로 대기 시간을 위해 코드 조각을 최적화하면 리소스 소비도 줄어듭니다. 애플리케이션에 대한 변경 내용이 꼭 필요한 것인지, 그리고 변경 내용이 애플리케이션에서 쿼리 힌트를 사용할 수 있는 사용자의 고객 경험에 부정적인 영향을 주지 않는지 확인해야 합니다.
워크로드에 반복되는 쿼리 집합이 포함된 경우 데이터베이스를 호스트하는 데 필요한 최소 리소스 크기 단위가 결정되므로 선택한 계획의 최적성을 파악하고 확인하는 것이 좋은 경우가 많습니다. 이를 확인한 후에는 가끔씩 계획을 재검사하여 성능이 저하되지 않았는지 확인하세요. 쿼리 힌트(Transact-SQL)에 대해 자세히 알아볼 수 있습니다.
Azure SQL Database의 초대형 데이터베이스 아키텍처에 대한 모범 사례
Azure SQL Database에서 단일 데이터베이스에 대한 하이퍼스케일 서비스 계층을 릴리스하기 전에는 고객이 개별 데이터베이스에 대한 용량 한도 문제에 부딪힐 수 있었습니다. 하이퍼스케일 탄력적 풀(프리뷰)은 훨씬 더 높은 스토리지 한도를 제공하지만 다른 서비스 계층의 탄력적 풀 및 풀링된 데이터베이스는 여전히 하이퍼스케일이 아닌 서비스 계층의 스토리지 용량 제한에 의해 제약을 받을 수 있습니다.
다음 두 섹션에서는 하이퍼스케일 서비스 계층을 사용할 수 없는 경우 Azure SQL Database의 초대형 데이터베이스 문제를 해결하기 위한 두 가지 옵션에 대해 설명합니다.
참고 항목
하이퍼스케일 탄력적 풀은 Azure SQL Database에 대해 프리뷰로 제공됩니다. 탄력적 풀은 Azure SQL Managed Instance, SQL Server 인스턴스 온-프레미스, Azure VM의 SQL Server 또는 Azure Synapse Analytics에서 사용할 수 없습니다.
교차-데이터베이스 분할
Azure SQL Database는 상용 하드웨어에서 실행되므로 기존 온-프레미스 SQL Server 설치보다 개별 데이터베이스의 용량 한도가 낮습니다. Azure SQL Database의 개별 데이터베이스 한도 내에서는 작업을 수행할 수 없는 경우 분할 기술을 사용해 여러 데이터베이스로 데이터베이스 작업을 분산시키는 고객도 있습니다. Azure SQL Database에서 분할 기술을 사용하는 대부분의 고객은 단일 차원의 데이터를 여러 데이터베이스에 분할합니다. 이 방법을 사용하려면 OLTP 애플리케이션이 스키마에서 하나의 행 또는 작은 행 그룹에만 적용되는 트랜잭션을 수행하는 경우가 많다는 것을 이해해야 합니다.
참고 항목
이제 Azure SQL Database는 분할을 지원하는 라이브러리를 제공합니다. 자세한 내용은 Elastic Database 클라이언트 라이브러리 개요를 참조하세요.
예를 들어 데이터베이스에 고객 이름, 주문, 주문 세부 정보가 있는 경우(예: AdventureWorks 데이터베이스), 고객을 관련 주문 및 주문 세부 정보로 그룹화하여 이 데이터를 여러 데이터베이스로 분할할 수 있습니다. 그러면 고객의 데이터가 개별 데이터베이스에 유지된다는 것을 보장할 수 있습니다. 애플리케이션은 데이터베이스 간에 서로 다른 고객을 분할하여 여러 데이터베이스에 부하를 효과적으로 분산합니다. 분할을 통해 고객은 최대 데이터베이스 크기 한도에 도달하지 않을 뿐만 아니라, 개별 데이터베이스가 해당 서비스 계층 한도에 맞는 한 Azure SQL Database는 다른 컴퓨팅 크기의 한도보다 훨씬 큰 워크로드를 처리할 수도 있게 됩니다.
데이터베이스 분할은 솔루션의 총 리소스 용량을 줄이지는 않지만 여러 데이터베이스에 분산된 초대형 솔루션을 지원하는 데 매우 효과적입니다. 각 데이터베이스는 리소스 요구사항이 높고 초대형인 "효과적인" 데이터베이스를 지원하기 위해 서로 다른 컴퓨팅 크기로 실행할 수 있습니다.
기능 분할
사용자는 개별 데이터베이스 내에 여러 기능을 결합하는 경우가 많습니다. 예를 들어 애플리케이션에 저장소의 인벤토리를 관리하는 논리가 있는 경우 해당 데이터베이스에는 인벤토리, 구매 주문 추적, 저장 프로시저, 월말 보고를 관리하는 인덱싱된 또는 구체화된 뷰와 관련된 논리가 있을 수 있습니다. 이 기법을 사용하면 데이터베이스에서 백업과 같은 작업을 쉽게 관리할 수 있지만 애플리케이션의 모든 기능에서 최고 부하를 처리할 수 있도록 하드웨어 규모를 늘려야 합니다.
Azure SQL Database 내에서 확장형 아키텍처를 사용하는 경우 애플리케이션의 다양한 기능을 여러 데이터베이스로 분할하는 것이 유리합니다. 이 기술을 사용하면 각 애플리케이션이 독립적으로 확장됩니다. 애플리케이션 사용량이 많아지면(데이터베이스의 부하 증가) 관리자가 애플리케이션 내의 각 기능에 대해 독립적인 컴퓨팅 크기를 선택할 수 있습니다. 이 아키텍처에서 한도에 도달할 경우 여러 시스템으로 부하를 분산하여 단일 상용 시스템이 처리할 수 있는 것보다 크게 애플리케이션을 확장할 수 있습니다.
일괄 처리 쿼리
임시 쿼리를 대량으로 빈번하게 사용하여 데이터에 액세스하는 애플리케이션의 경우 애플리케이션 계층과 데이터베이스 계층 간 네트워크 통신에서 많은 응답 시간이 사용됩니다. 애플리케이션과 데이터베이스가 동일한 데이터 센터 내에 있는 경우에도 데이터 액세스 작업 수가 많으면 그 사이의 네트워크 대기 시간이 커질 수 있습니다. 데이터 액세스 작업에 대한 네트워크 왕복을 줄이려면 임시 쿼리를 일괄 처리하거나 저장 프로시저로 컴파일하는 옵션을 사용하는 것이 좋습니다. 임시 쿼리를 일괄 처리할 경우 복수 쿼리를 하나의 큰 일괄 처리로 한 번에 데이터베이스에 보낼 수 있습니다. 임시 쿼리를 저장 프로시저로 컴파일하는 경우 일괄 처리하는 것과 동일한 결과를 얻을 수 있습니다. 또한 저장 프로시저를 사용하면 데이터베이스에서 쿼리 계획을 캐싱할 가능성이 높아져서 저장 프로시저를 다시 사용할 수 있다는 이점도 있습니다.
일부 애플리케이션은 쓰기 집약적입니다. 쓰기를 일괄 처리하는 방법을 고려하여 데이터베이스에서 총 IO 부하를 줄일 수 있는 경우도 있습니다. 저장 프로시저 및 임시 일괄 처리에서 자동 커밋 트랜잭션 대신 명시적 트랜잭션을 사용하는 것만큼 간단한 경우가 많습니다. 사용 가능한 다양한 기법을 평가하려면 Azure에서 데이터베이스 애플리케이션의 일괄 처리 기법을 참조하세요. 자체 워크로드를 실험하여 일괄 처리에 적합한 모델을 찾으세요. 모델의 트랜잭션 일관성 보증이 조금 다를 수 있다는 것을 이해해야 합니다. 리소스 사용을 최소화하는 올바른 워크로드를 찾으려면 일관성과 성능 사이의 올바른 조합을 찾아야 합니다.
애플리케이션 계층 캐싱
일부 데이터베이스 애플리케이션에는 읽기 작업이 많은 워크로드가 포함되어 있습니다. 캐싱 계층을 통해 데이터베이스의 부하를 줄이고 Azure SQL Database를 사용하여 데이터베이스를 지원하는 데 필요한 컴퓨팅 크기를 줄일 수 있습니다. Azure Cache for Redis를 사용하면 읽기 작업이 많은 워크로드에서 데이터를 한 번만(또는 구성 방식에 따라 애플리케이션 계층 머신당 한 번만) 읽고 해당 데이터를 데이터베이스 외부에 저장할 수 있습니다. 이 방법은 데이터베이스 부하(CPU 및 읽기 IO)를 줄이는 방법이지만 캐시에서 읽는 데이터가 데이터베이스의 데이터와 동기화되지 않을 수 있으므로 트랜잭션 일관성에 영향을 줄 수 있습니다. 많은 애플리케이션에서 어느 정도의 불일치는 허용 가능하지만 모든 워크로드가 그런 것은 아닙니다. 애플리케이션 계층 캐싱 전략을 구현하기 전에 애플리케이션 요구 사항을 완전히 이해해야 합니다.
구성 및 설계 팁 가져오기
Azure SQL Database를 사용하는 경우 Azure SQL Database에서 데이터베이스 구성 및 설계를 개선하기 위한 오픈 소스 T-SQL 스크립트를 실행할 수 있습니다. 스크립트는 요청 시 데이터베이스를 분석하고 데이터베이스 성능 및 상태를 개선하기 위한 팁을 제공합니다. 일부 팁은 모범 사례에 따라 구성 및 운영 변경을 제안하는 반면, 다른 팁은 고급 데이터베이스 엔진 기능을 사용하도록 설정하는 등 워크로드에 적합한 디자인 변경을 권장합니다.
스크립트에 대해 자세히 알아보고 시작하려면 Azure SQL 팁 wiki 페이지를 방문하세요.
관련 콘텐츠
- DTU 기반 구매 모델에 대해 자세히 알아봅니다.
- vCore 기반 구매 모델에 대해 자세히 알아봅니다.
- Azure 탄력적 풀이란?을 참조하세요.
- 탄력적 풀을 고려하는 경우를 살펴봅니다.
- 동적 관리 뷰를 사용하여 성능 모니터링을 읽어보세요.
- Azure SQL Database의 높은 CPU 진단 및 문제 해결에 대해 알아봅니다.
- 누락된 인덱스 제안으로 비클러스터형 인덱스 조정
- 동영상: Azure SQL Database 데이터 로드 모범 사례
- Azure Monitor로 Azure SQL Database 모니터링하기
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기