Azure Cosmos DB for Apache Cassandra의 일반적인 문제 해결
적용 대상: ![]() Cassandra
Cassandra
Azure Cosmos DB의 API for Cassandra는 오픈 소스 Apache Cassandra 데이터베이스에 대한 유선 프로토콜 지원을 제공하는 호환성 레이어입니다.
이 문서에서는 Azure Cosmos DB for Apache Cassandra를 사용하는 애플리케이션에 대한 일반적인 오류 및 솔루션을 설명합니다. 오류가 나열되지 않고 Cassandra에서 지원되는 작업을 실행할 때 오류가 발생하는 경우 기본 Apache Cassandra를 사용할 때 오류가 표시되지 않으면 Azure 지원 요청을 만듭니다.
참고 항목
완전 관리형 클라우드 기본 서비스인 Azure Cosmos DB는 API for Cassandra에 대한 가용성, 처리량 및 일관성을 보장합니다. 또한 API for Cassandra는 유지 관리 부담이 없는 플랫폼 작업 및 가동 중지 시간이 0인 패치를 용이하게 합니다.
이러한 보장은 Apache Cassandra의 이전 구현에서 불가능하므로 많은 API for Cassandra 백 엔드 작업이 Apache Cassandra와 다릅니다. 일반적인 오류를 방지하는 데 도움이 되는 특정 설정 및 방법을 사용하는 것이 좋습니다.
NoNodeAvailableException
이 오류는 가능한 원인 및 내부 예외를 많이 포함하는 최상위 래퍼 예외이며, 대부분은 클라이언트와 관련이 있을 수 있습니다.
일반적인 원인 및 해결 방법:
Azure LoadBalancers의 유휴 시간 제한: 이 문제는
ClosedConnectionException로 나타날 수도 있습니다. 이 문제를 해결하려면 드라이버에서 연결 유지 설정을 설정하고(Java 드라이버에 연결 유지 사용 참조), 운영 체제에서 연결 유지 설정을 늘리거나, Azure Load Balancer에서 유휴 시간 제한을 조정합니다.클라이언트 애플리케이션 리소스 소모: 클라이언트 컴퓨터에 요청을 완료하는 데 충분한 리소스가 있는지 확인합니다.
호스트에 연결할 수 없음
"호스트에 연결할 수 없음, 60만 밀리초 내에 다시 시도 예약" 오류가 표시될 수 있습니다.
이 오류는 클라이언트 쪽에서 SNAT(원본 네트워크 주소 변환)이 고갈된 경우에 발생할 수 있습니다. 아웃바운드 연결에 대한 SNAT의 단계에 따라 이 문제를 처리합니다.
Azure 부하 분산 디바이스에는 기본적으로 4분의 유휴 시간 제한이 있는 유휴 시간 제한 문제가 발생할 수도 있습니다. 부하 분산 디바이스 유휴 시간 제한을 참조하세요. Java 드라이버에 대해 연결 유지를 사용하도록 설정하고 운영 체제의 keepAlive 간격을 4분 미만으로 설정합니다.
예외를 처리하는 더 많은 방법은 NoHostAvailableException 문제 해결을 참조하세요.
OverloadedException(Java)
사용된 총 요청 단위 수가 keyspace 또는 테이블에서 프로비전한 요청 단위 수보다 높기 때문에 요청이 제한됩니다.
Azure Portal에서 keyspace 또는 테이블에 할당된 처리량의 크기를 조정하거나(Azure Cosmos DB for Apache Cassandra 계정 탄력적으로 스케일링 참조) 재시도 정책을 구현하는 것을 고려하세요.
Java의 경우, v3.x 드라이버 및 v4.x 드라이버에 대한 재시도 샘플을 참조하세요. 또한 Azure Cosmos DB Cassandra Extensions for Java를 참조하세요.
충분한 처리량에도 불구하고 OverloadedException 발생
요청 볼륨 또는 사용된 요청 단위 비용에 대한 충분한 처리량이 프로비전된 경우에도 시스템이 제한 요청으로 간주됩니다. 두 가지의 가능한 원인이 있습니다.
스키마 수준 작업: API for Cassandra는 스키마 수준 작업에 대한 시스템 처리량 예산(CREATE TABLE, ALTER TABLE, DROP TABLE)을 구현합니다. 이 예산은 프로덕션 시스템의 스키마 작업에 충분해야 합니다. 그러나 스키마 수준 작업이 많은 경우에는 이 제한을 초과할 수 있습니다.
예산이 사용자 제어되지 않으므로 실행하는 스키마 작업의 수를 줄이는 것이 좋습니다. 이 동작으로 문제가 해결되지 않거나 워크로드에 적합하지 않은 경우 Azure 지원 요청을 만듭니다.
데이터 기울이기: 처리량이 API for Cassandra에서 프로비저닝되는 경우 실제 파티션 간에 균등하게 분할되고 각 실제 파티션에는 상한이 있습니다. 특정 파티션에서 많은 양의 데이터를 삽입하거나 쿼리하는 경우 해당 테이블에 대해 많은 양의 전체 처리량(요청 단위)을 프로비전하는 경우에도 속도가 제한될 수 있습니다.
데이터 모델을 검토하고 핫 파티션을 유발할 수 있는 과도한 기울이기가 없는지 확인합니다.
일시적인 연결 오류(Java)
연결이 예기치 않게 삭제되거나 제한 시간이 초과되었습니다.
Java용 Apache Cassandra 드라이버는 ExponentialReconnectionPolicy 및 ConstantReconnectionPolicy의 두 가지 기본 다시 연결 정책을 제공합니다. 기본값은 ExponentialReconnectionPolicy입니다. 그러나 Azure Cosmos DB for Apache Cassandra의 경우 2초 지연 시간이 있는 ConstantReconnectionPolicy를 사용하는 것이 좋습니다.
Java 4.x 드라이버에 대한 설명서, Java 3.x 드라이버에 대한 설명서 또는 Java 드라이버에 대한 다시 연결 정책 구성 예제를 참조하세요.
부하 분산 정책에 오류 발생
다음과 유사한 코드를 사용하여 Java DataStax 드라이버의 v3. x에서 부하 분산 정책을 구현했을 수 있습니다.
cluster = Cluster.builder()
.addContactPoint(cassandraHost)
.withPort(cassandraPort)
.withCredentials(cassandraUsername, cassandraPassword)
.withPoolingOptions(new PoolingOptions() .setConnectionsPerHost(HostDistance.LOCAL, 1, 2)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32000).setMaxQueueSize(Integer.MAX_VALUE))
.withSSL(sslOptions)
.withLoadBalancingPolicy(DCAwareRoundRobinPolicy.builder().withLocalDc("West US").build())
.withQueryOptions(new QueryOptions().setConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM))
.withSocketOptions(getSocketOptions())
.build();
withLocalDc()의 값이 접점 데이터 센터와 일치하지 않으면 간헐적 오류(com.datastax.driver.core.exceptions.NoHostAvailableException: All host(s) tried for query failed (no host was tried))가 발생할 수 있습니다.
CosmosLoadBalancingPolicy를 구현합니다. 이러한 작업을 수행하려면 다음 코드를 사용하여 DataStax를 업그레이드해야 할 수 있습니다.
LoadBalancingPolicy loadBalancingPolicy = new CosmosLoadBalancingPolicy.Builder().withWriteDC("West US").withReadDC("West US").build();
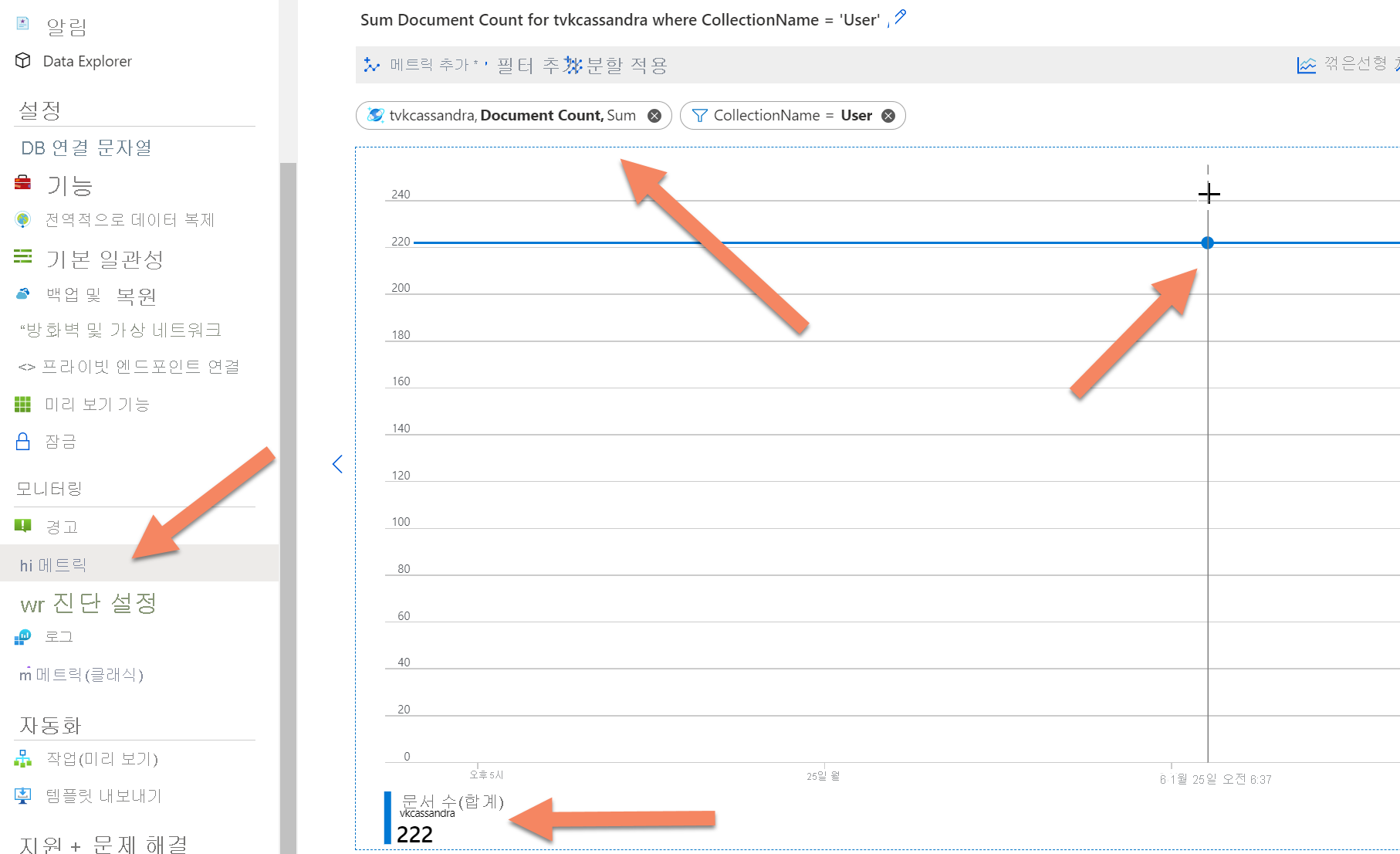
큰 규모의 테이블에서 개수가 실패합니다.
많은 수의 행에 대해 select count(*) from table을 실행하면 서버 시간이 초과됩니다.
로컬 CQLSH 클라이언트를 사용하는 경우 --connect-timeout 또는 --request-timeout 설정을 변경합니다. cqlsh: CQL 셸을 참조하세요.
수가 계속해서 제한 시간이 초과되면 Azure Portal의 메트릭 탭으로 이동하고 메트릭 document count를 선택한 다음, 데이터베이스 또는 컬렉션에 대한 필터(Azure Cosmos DB 테이블의 아날로그)를 추가하여 Azure Cosmos DB 백 엔드 원격 분석에서 레코드 수를 가져올 수 있습니다. 그런 다음, 레코드 수를 계산할 특정 시점에 대해 결과 그래프를 마우스로 가리킬 수 있습니다.
Java 드라이버에 대한 다시 연결 정책 구성
버전 3.x
Java 드라이버 버전 3.x의 경우 클러스터 개체를 만들 때 다시 연결 정책을 구성합니다.
import com.datastax.driver.core.policies.ConstantReconnectionPolicy;
Cluster.builder()
.withReconnectionPolicy(new ConstantReconnectionPolicy(2000))
.build();
버전 4.x
Java 드라이버 버전 4.x의 경우 reference.conf 파일의 설정을 재정의하여 다시 연결 정책을 구성합니다.
datastax-java-driver {
advanced {
reconnection-policy{
# The driver provides two implementations out of the box: ExponentialReconnectionPolicy and
# ConstantReconnectionPolicy. We recommend ConstantReconnectionPolicy for API for Cassandra, with
# base-delay of 2 seconds.
class = ConstantReconnectionPolicy
base-delay = 2 second
}
}
Java 드라이버에 대해 연결 유지를 사용하도록 설정
버전 3.x
Java 드라이버의 버전 3.x의 경우 클러스터 개체를 만들 때 연결 유지를 설정하고 운영 체제에서 연결 유지를 사용하도록 설정해야 합니다.
import java.net.SocketOptions;
SocketOptions options = new SocketOptions();
options.setKeepAlive(true);
cluster = Cluster.builder().addContactPoints(contactPoints).withPort(port)
.withCredentials(cassandraUsername, cassandraPassword)
.withSocketOptions(options)
.build();
버전 4.x
Java 드라이버의 버전 4.x의 경우 reference.conf의 설정을 재정의하여 연결 유지를 설정한 후 운영 체제에서 연결 유지를 사용하도록 설정해야 합니다.
datastax-java-driver {
advanced {
socket{
keep-alive = true
}
}
다음 단계
- Azure Cosmos DB for Apache Cassandra에서 지원되는 기능에 대해 알아봅니다.
- 기본 Apache Cassandra에서 Azure Cosmos DB for Apache Cassandra로 마이그레이션하는 방법에 대해 알아봅니다.