NoSQL용 Azure Cosmos DB의 계산 속성
적용 대상: ![]() NoSQL
NoSQL
Azure Cosmos DB의 계산된 속성은 기존 항목 속성에서 파생된 값을 갖지만 항목 자체에서 지속되지는 않습니다. 계산된 속성은 그 범위가 단일 항목으로 한정되며, 쿼리에서 마치 지속형 속성인 것처럼 참조할 수 있습니다. 계산된 속성을 사용하면 복잡한 쿼리 논리를 한 번만 작성하면 여러 번 참조할 수 있습니다. 이러한 속성에 단일 인덱스를 추가할 수도 있고 성능 향상을 위해 복합 인덱스의 일부로 사용할 수도 있습니다.
참고 항목
계산된 속성에 대한 피드백이 있나요? 많은 의견 부탁드립니다. 언제든지 자유롭게 Azure Cosmos DB 엔지니어링 팀(cosmoscomputedprops@microsoft.com)과 피드백을 직접 공유해 주세요.
계산된 속성이란?
계산된 속성은 항목의 최상위 수준에 있어야 하며 경로가 중첩되면 안 됩니다. 각 계산된 속성 정의에는 이름과 쿼리의 두 가지 구성 요소가 있습니다. 이름은 계산된 속성 이름이고, 쿼리는 각 항목의 속성 값을 계산하는 논리를 정의합니다. 계산된 속성은 그 범위가 개별 항목으로 한정되므로 여러 항목의 값을 사용하거나 다른 계산된 속성을 사용할 수 없습니다. 각 컨테이너에 허용되는 최대 계산된 속성 개수는 20개입니다.
다음은 계산된 속성 정의의 예시입니다.
{
"computedProperties": [
{
"name": "cp_lowerName",
"query": "SELECT VALUE LOWER(c.name) FROM c"
}
]
}
이름 제약 조건
지속형 속성 이름과 충돌하지 않도록 계산된 속성의 이름을 지정하는 것이 좋습니다. 모든 계산된 속성 이름에 접두사 또는 접미사를 추가하면 속성 이름이 겹치지 않게 할 수 있습니다. 이 문서에서는 모든 이름 정의에 cp_ 접두사를 사용합니다.
Important
지속형 속성과 동일한 이름을 사용하여 계산된 속성을 정의해도 오류가 발생하지는 않지만, 예기치 않은 동작이 발생할 수 있습니다. 컴퓨팅 속성이 인덱싱되는지 여부에 관계없이 컴퓨팅 속성과 이름을 공유하는 지속형 속성의 값은 인덱스에 포함되지 않습니다. 쿼리는 SELECT 절에 와일드카드 프로젝션이 있는 경우 컴퓨팅 속성 대신 반환되는 지속형 속성을 제외하고 항상 지속형 속성 대신 컴퓨팅 속성을 사용합니다. 와일드카드 프로젝션에 계산된 속성이 자동으로 포함되지 않습니다.
계산된 속성 이름의 제약 조건은 다음과 같습니다.
- 모든 계산된 속성의 이름이 고유해야 합니다.
name속성 값은 계산된 속성을 참조하는 데 사용할 수 있는 최상위 속성 이름을 나타냅니다.id,_rid,_ts같은 예약된 시스템 속성 이름은 계산된 속성 이름으로 사용할 수 없습니다.- 계산된 속성 이름은 이미 인덱싱된 속성 경로와 일치하면 안 됩니다. 이 제약 조건은 다음을 포함하여 지정된 모든 인덱싱 경로에 적용됩니다.
- 포함된 경로
- 제외된 경로
- 공간 인덱스
- 복합 인덱스
쿼리 제약 조건
계산된 속성 정의의 쿼리는 구문적으로 그리고 의미적으로 유효해야 합니다. 그렇지 않으면 만들기 또는 업데이트 작업이 실패합니다. 쿼리는 컨테이너에 있는 모든 항목의 결정적 값으로 평가되어야 합니다. 쿼리는 일부 항목에 대해 정의되지 않거나 null로 평가될 수 있으며, 정의되지 않거나 null 값이 있는 계산 속성은 쿼리에서 사용할 때 정의되지 않은 값이나 null 값이 있는 지속형 속성과 동일하게 동작합니다.
계산된 속성 쿼리 정의에 대한 제한 사항은 다음과 같습니다.
- 쿼리에서 루트 항목 참조를 나타내는 FROM 절을 지정해야 합니다. 지원되는 FROM 절의 예는 다음과
FROM cFROM root cFROM MyContainer c같습니다. - 쿼리의 프로젝션에 VALUE 절을 사용해야 합니다.
- 쿼리는 JOIN을 포함할 수 없습니다.
- 쿼리는 비결정적 스칼라 식을 사용할 수 없습니다. 비결정적 스칼라 식의 예는 GetCurrentDateTime, GetCurrentTimeStamp, GetCurrentTicks 및 RAND입니다.
- 쿼리는 WHERE, GROUP BY, ORDER BY, TOP, DISTINCT, OFFSET LIMIT, EXISTS, ALL, LAST, FIRST 및 NONE 절을 사용할 수 없습니다.
- 쿼리에 스칼라 하위 쿼리를 포함할 수 없습니다.
- 집계 함수, 공간 함수, 비결정적 함수 및 UDF(사용자 정의 함수)는 지원되지 않습니다.
계산된 속성 만들기
계산된 속성을 만든 후에는 Azure Portal의 모든 SDK(소프트웨어 개발 키트) 및 Azure Data Explorer를 비롯한 모든 방법을 사용하여 속성을 참조하는 쿼리를 실행할 수 있습니다.
| 지원되는 버전 | 주의 | |
|---|---|---|
| .NET SDK v3 | >= 3.34.0-preview | 계산된 속성은 현재 미리 보기 패키지 버전에서만 사용할 수 있습니다. |
| Java SDK v4 | >= 4.46.0 | 계산된 속성은 현재 미리 보기 버전으로 제공됩니다. |
| Python SDK | >= v4.5.2b5 | 계산된 속성은 현재 미리 보기 버전으로 제공됩니다. |
SDK를 사용하여 계산된 속성 만들기
계산된 속성이 정의된 새 컨테이너를 만들 수도 있고, 기존 컨테이너에 계산된 속성을 추가할 수도 있습니다.
다음은 새 컨테이너에 계산된 속성을 만드는 방법의 예입니다.
ContainerProperties containerProperties = new ContainerProperties("myContainer", "/pk")
{
ComputedProperties = new Collection<ComputedProperty>
{
new ComputedProperty
{
Name = "cp_lowerName",
Query = "SELECT VALUE LOWER(c.name) FROM c"
}
}
};
Container container = await client.GetDatabase("myDatabase").CreateContainerAsync(containerProperties);
다음은 기존 컨테이너의 계산된 속성을 업데이트하는 방법의 예입니다.
var container = client.GetDatabase("myDatabase").GetContainer("myContainer");
// Read the current container properties
var containerProperties = await container.ReadContainerAsync();
// Make the necessary updates to the container properties
containerProperties.Resource.ComputedProperties = new Collection<ComputedProperty>
{
new ComputedProperty
{
Name = "cp_lowerName",
Query = "SELECT VALUE LOWER(c.name) FROM c"
},
new ComputedProperty
{
Name = "cp_upperName",
Query = "SELECT VALUE UPPER(c.name) FROM c"
}
};
// Update the container with changes
await container.ReplaceContainerAsync(containerProperties);
팁
컨테이너 속성을 업데이트할 때마다 이전 값을 덮어쓰게 됩니다. 기존 계산된 속성이 있고 새 계산된 속성을 추가하려는 경우 컬렉션에 새 계산된 속성과 기존 계산된 속성을 모두 추가해야 합니다.
데이터 탐색기를 사용하여 계산된 속성 만들기
데이터 탐색기를 사용하여 컨테이너에 대한 계산 속성을 만들 수 있습니다.
데이터 탐색기에서 기존 컨테이너를 엽니다.
컨테이너의 설정 섹션으로 이동합니다. 그런 다음 * 계산 속성 하위 섹션으로 이동합니다.
컨테이너에 대한 계산 속성 정의 JSON을 편집합니다. 이 예제에서 이 JSON은 구분 기호를 사용하여
-소매 제품의 문자열을 분할SKU하는 계산 속성을 정의하는 데 사용됩니다.[ { "name": "cp_splitSku", "query": "SELECT VALUE StringSplit(p.sku, \"-\") FROM products p" } ]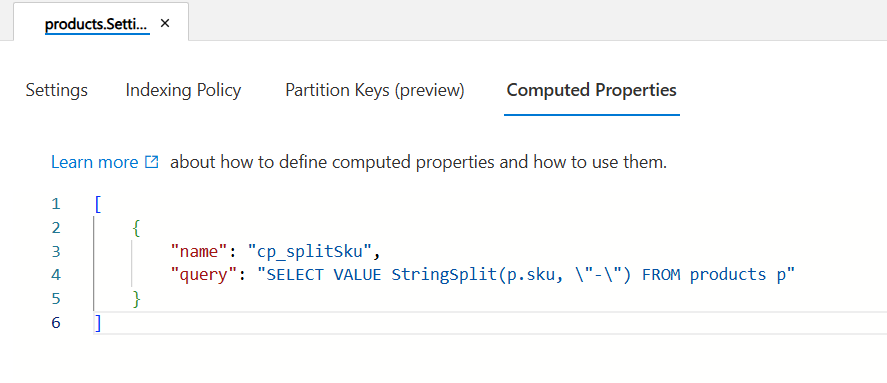
계산된 속성을 저장 합니다.
쿼리에서 계산된 속성 사용
지속형 속성을 참조하는 방식과 동일한 방식으로 쿼리에서 계산된 속성을 참조할 수 있습니다. 인덱싱되지 않은 계산된 속성의 값은 런타임 중에 계산된 속성 정의를 사용하여 평가됩니다. 계산된 속성이 인덱싱되는 경우 인덱스는 지속형 속성에 사용되는 방식과 동일한 방식으로 사용되며, 계산된 속성은 필요에 따라 평가됩니다. 최상의 가성비를 얻을 수 있도록 계산된 속성에 인덱스를 추가하는 것이 좋습니다.
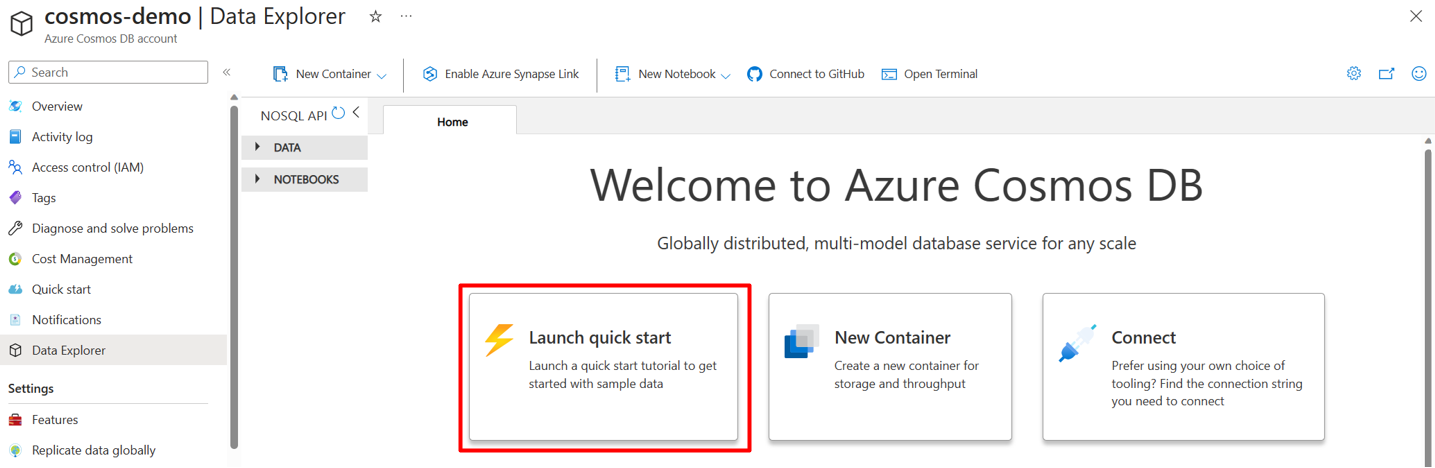
다음 예제에서는 Azure Portal의 Data Explorer에서 제공하는 빠른 시작 제품 데이터 세트를 사용합니다. 시작하려면 빠른 시작 실행을 선택하고 새 컨테이너에 데이터 세트를 로드합니다.
다음은 항목의 예입니다.
{
"id": "aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb",
"categoryId": "bbbbbbbb-1111-2222-3333-cccccccccccc",
"categoryName": "Bikes, Touring Bikes",
"sku": "BK-T79U-50",
"name": "Touring-1000 Blue, 50",
"description": "The product called \"Touring-1000 Blue, 50\"",
"price": 2384.07,
"tags": [
{
"id": "cccccccc-2222-3333-4444-dddddddddddd",
"name": "Tag-61"
}
],
"_rid": "n7AmAPTJ480GAAAAAAAAAA==",
"_self": "dbs/n7AmAA==/colls/n7AmAPTJ480=/docs/n7AmAPTJ480GAAAAAAAAAA==/",
"_etag": "\"01002683-0000-0800-0000-6451fb4b0000\"",
"_attachments": "attachments/",
"_ts": 1683094347
}
프로젝션
계산된 속성을 프로젝션해야 하는 경우 계산된 속성을 명시적으로 참조해야 합니다. SELECT *와 같은 와일드카드 프로젝션은 모든 지속형 속성을 반환하지만, 계산된 속성을 포함하지는 않습니다.
다음은 name 속성을 소문자로 변환하는 계산된 속성 정의의 예입니다.
{
"name": "cp_lowerName",
"query": "SELECT VALUE LOWER(c.name) FROM c"
}
이 속성을 쿼리에서 프로젝션할 수 있습니다.
SELECT
c.cp_lowerName
FROM
c
WHERE 절
계산된 속성은 지속형 속성처럼 필터 조건자에서 참조할 수 있습니다. 필터에 계산된 속성을 사용하는 경우 관련 단일 인덱스 또는 복합 인덱스를 추가하는 것이 좋습니다.
다음은 20% 가격 할인을 계산하는 계산된 속성 정의의 예입니다.
{
"name": "cp_20PercentDiscount",
"query": "SELECT VALUE (c.price * 0.2) FROM c"
}
할인이 50달러 미만인 제품만 반환하도록 이 속성을 필터링할 수 있습니다.
SELECT
c.price - c.cp_20PercentDiscount as discountedPrice,
c.name
FROM
c
WHERE
c.cp_20PercentDiscount < 50.00
GROUP BY 절
지속형 속성과 마찬가지로, 계산된 속성은 GROUP BY 절에서 참조할 수 있으며 가급적이면 인덱스를 사용합니다. 관련 단일 인덱스 또는 복합 인덱스를 추가하면 최상의 성능을 얻을 수 있습니다.
다음은 categoryName 속성에서 각 항목의 기본 범주를 찾는 계산된 속성 정의의 예입니다.
{
"name": "cp_primaryCategory",
"query": "SELECT VALUE SUBSTRING(c.categoryName, 0, INDEX_OF(c.categoryName, ',')) FROM c"
}
다음과 같이 cp_primaryCategory로 그룹화하면 각 기본 범주의 항목 수를 가져올 수 있습니다.
SELECT
COUNT(1),
c.cp_primaryCategory
FROM
c
GROUP BY
c.cp_primaryCategory
팁
계산된 속성을 사용하지 않고도 이 쿼리를 수행할 수 있지만, 계산된 속성을 사용하면 cp_primaryCategory를 인덱싱할 수 있으므로 쿼리 작성 방법이 대폭 간소화되고 성능이 향상됩니다. SUBSTRING() 및 INDEX_OF()는 둘 다 컨테이너의 모든 항목을 전체 검사해야 하지만, 계산된 속성을 인덱싱하면 전체 쿼리를 인덱스로 처리할 수 있습니다. 전체 검사 대신 인덱스로 쿼리를 처리할 수 있으면 성능이 향상되고 RU(쿼리 요청 단위) 비용이 낮아집니다.
ORDER BY 절
지속형 속성과 마찬가지로, 계산된 속성을 ORDER BY 절에서 참조할 수 있으며 쿼리가 성공하려면 계산된 속성을 인덱싱해야 합니다. 계산된 속성을 사용하면 복잡한 논리 또는 시스템 함수의 결과를 ORDER BY할 수 있으며, Azure Cosmos DB를 사용할 때 여러 가지 새로운 쿼리 시나리오가 열립니다.
다음은 _ts 값에서 월을 가져오는 계산된 속성 정의의 예입니다.
{
"name": "cp_monthUpdated",
"query": "SELECT VALUE DateTimePart('m', TimestampToDateTime(c._ts*1000)) FROM c"
}
cp_monthUpdated를 ORDER BY하려면 먼저 인덱싱 정책에 추가해야 합니다. 인덱싱 정책을 업데이트한 후에는 계산된 속성을 기준으로 정렬할 수 있습니다.
SELECT
*
FROM
c
ORDER BY
c.cp_monthUpdated
계산된 속성 인덱싱
계산된 속성은 기본적으로 인덱싱되지 않으며 인덱싱 정책에서 와일드카드 경로가 적용되지 않습니다. 지속형 속성에 인덱스를 추가하는 방식과 동일한 방식으로 인덱싱 정책에서 계산된 속성에 단일 인덱스 또는 복합 인덱스를 추가할 수 있습니다. 모든 계산된 속성에 관련 인덱스를 추가하는 것이 좋습니다. 이러한 인덱스는 성능을 높이고 RU(요청 단위)를 줄이는 데 도움이 되므로 권장됩니다. 계산된 속성이 인덱싱되면 항목 쓰기 작업 중에 실제 값을 평가하여 인덱스 용어를 생성하고 유지합니다.
계산된 속성을 인덱싱할 때 다음과 같은 사항을 고려해야 합니다.
- 포함된 경로, 제외된 경로 및 복합 인덱스 경로에 계산 속성을 지정할 수 있습니다.
- 계산된 속성에는 공간 인덱스가 정의되어 있을 수 없습니다.
- 계산된 속성 경로 아래의 와일드카드 경로는 일반 속성과 마찬가지로 작동합니다.
- 제거 및 인덱싱된 속성의 관련 인덱스도 삭제해야 합니다.
참고 항목
모든 계산된 속성은 항목의 최상위 수준에서 정의됩니다. 경로는 항상 /<computed property name>입니다.
팁
컨테이너 속성을 업데이트할 때마다 이전 값을 덮어쓰게 됩니다. 기존 계산된 속성이 있고 새 계산된 속성을 추가하려는 경우 컬렉션에 새 계산된 속성과 기존 계산된 속성을 모두 추가해야 합니다.
참고 항목
인덱싱된 계산 속성의 정의가 수정되면 자동으로 다시 인덱싱되지 않습니다. 수정된 계산 속성을 인덱싱하려면 먼저 인덱스에서 계산된 속성을 삭제해야 합니다. 그런 다음 다시 인덱싱이 완료되면 계산된 속성을 인덱스 정책에 다시 추가합니다.
계산된 속성을 삭제하려면 먼저 인덱스 정책에서 제거해야 합니다.
계산된 속성에 대한 단일 인덱스 추가
계산된 속성 cp_myComputedProperty에 대한 단일 인덱스를 추가하는 방법은 다음과 같습니다.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
},
{
"path": "/cp_myComputedProperty/?"
}
],
"excludedPaths": [
{
"path": "/\"_etag\"/?"
}
]
}
계산된 속성에 대한 복합 인덱스 추가
계산된 속성 cp_myComputedProperty 및 지속형 속성 myPersistedProperty에 대한 복합 인덱스를 추가하는 방법은 다음과 같습니다.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/\"_etag\"/?"
}
],
"compositeIndexes": [
[
{
"path": "/cp_myComputedProperty"
},
{
"path": "/path/to/myPersistedProperty"
}
]
]
}
요청 단위 사용 이해
컨테이너에 계산된 속성을 추가해도 RU가 사용되지 않습니다. 계산된 속성이 정의된 컨테이너에 쓰기 작업을 수행하면 RU가 약간 증가할 수 있습니다. 계산된 속성이 인덱싱되면 계산된 속성의 인덱싱 및 평가 비용을 반영하여 쓰기 작업의 RU가 증가합니다.