빠른 시작: Azure Portal을 사용하여 Azure Cosmos DB for NoSQL 계정 만들기
적용 대상: ![]() NoSQL
NoSQL
이 빠른 시작에서는 Azure Portal에서 Azure Cosmos DB for NoSQL 계정을 새로 만듭니다. 그런 다음, Azure Portal 내에서 데이터 탐색기 환경을 사용하여 필요한 모든 설정을 구성하는 데이터베이스와 컨테이너를 만듭니다. 마지막으로 컨테이너에 샘플 데이터를 추가하고 기본 쿼리를 실행합니다.
필수 조건
- 활성 구독이 있는 Azure 계정. 체험 계정을 만듭니다.
거래처 만들기
새 Azure Cosmos DB for NoSQL 계정을 만들어 시작하세요.
Azure Portal에 로그인합니다(https://portal.azure.com).
전역 검색 창에 Azure Cosmos DB를 입력합니다.
서비스 내에서 Azure Cosmos DB를 선택합니다.

Azure Cosmos DB 창에서 만들기를 선택한 다음 Azure Cosmos DB for NoSQL을 선택합니다.


기본 창에서 다음 옵션을 구성한 다음 검토 + 만들기를 선택합니다.
값 구독 Azure 구독 선택 리소스 그룹 새 리소스 그룹을 만들거나 기존 리소스 그룹을 선택합니다. 거래처 이름 전역적으로 고유한 이름 입력 가용성 영역 사용 안 함 위치 구독에 대해 지원되는 Azure 지역 선택 
팁
지정하지 않은 옵션은 기본값으로 그대로 둘 수 있습니다. 또한 총 계정 처리량을 초당 요청 단위(RU/s) 1,000개로 제한하고 무료 계층을 활성화하여 비용을 최소화하도록 계정을 구성할 수도 있습니다.
검토 + 만들기 창에서 계정 유효성 검사가 성공적으로 완료될 때까지 기다린 다음 만들기를 선택합니다.

포털이 자동으로 배포 창으로 이동합니다. 배포가 완료될 때가지 기다립니다.

배포가 완료되면 리소스로 이동을 선택하여 새 Azure Cosmos DB for NoSQL 계정으로 이동합니다.


데이터베이스 및 컨테이너 만들기
그런 다음 데이터 탐색기를 사용하여 포털 내에서 데이터베이스와 컨테이너를 만듭니다.
계정 리소스 창의 서비스 메뉴에서 데이터 탐색기를 선택합니다..

데이터 탐색기 창에서 새 컨테이너 옵션을 선택합니다.
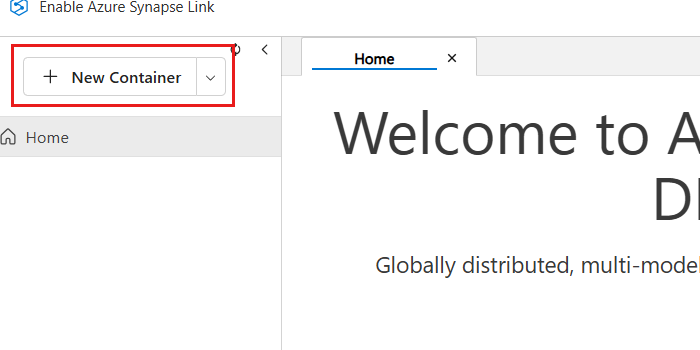
새 컨테이너 대화 상자에서 다음 값을 구성한 후 확인을 선택합니다.
값 데이터베이스 새로 만들기 데이터베이스 ID cosmicworks컨테이너 간에 처리량 공유 선택하지 마세요. 컨테이너 ID employees파티션 키 department/name컨테이너 처리량(자동 크기 조정) Autoscale 컨테이너 최대 RU/s 1000
이름이 demo.bicepparam 또는 (
demo.bicepparam)인 새 파일을 만듭니다.데이터 탐색기의 계층 구조에서 새로 만든 데이터베이스 및 컨테이너를 관찰합니다.

팁
필요에 따라 컨테이너 노드를 확장하여 추가 속성 및 구성 설정을 관찰할 수 있습니다.
샘플 데이터 추가 및 쿼리
마지막으로 데이터 탐색기를 사용하여 샘플 항목을 만든 다음, 컨테이너에 기본 쿼리를 실행합니다.
데이터 탐색기 트리에서 직원 컨테이너의 노드를 확장합니다. 그런 다음 항목 옵션을 선택합니다.

데이터 탐색기의 메뉴에서 새 항목을 선택합니다.

이제, 직원 컨테이너의 새 항목에 대해 다음 JSON을 삽입한 다음 저장을 선택합니다.
{ "id": "aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb", "name": { "first": "Kai", "last": "Carter" }, "email": "<kai@adventure-works.com>", "department": { "name": "Logistics" } }
데이터 탐색기의 메뉴에서 새 SQL 쿼리를 선택합니다.

이제 대소문자를 구분하지 않는 검색을 사용하여
logistics부서의 모든 항목을 가져오려면 다음 NoSQL 쿼리를 삽입합니다. 그런 다음 쿼리는 출력의 형식을 구조적 JSON 개체로 지정합니다. 쿼리 실행을 선택하여 쿼리를 실행합니다.SELECT VALUE { "name": CONCAT(e.name.last, " ", e.name.first), "department": e.department.name, "emailAddresses": [ e.email ] } FROM employees e WHERE STRINGEQUALS(e.department.name, "logistics", true)
쿼리에서 JSON 배열 출력을 관찰합니다.
[ { "name": "Carter Kai", "department": "Logistics", "emailAddresses": [ "kai@adventure-works.com" ] } ]