중요
Azure Cosmos DB for PostgreSQL은 더 이상 새 프로젝트에 지원되지 않습니다. 새 프로젝트에는 이 서비스를 사용하지 마세요. 대신 다음 두 서비스 중 하나를 사용합니다.
99.999% SLA(가용성 서비스 수준 약정), 인스턴트 자동 크기 조정 및 여러 지역에서 자동 장애 조치(failover)를 사용하는 대규모 시나리오용으로 설계된 분산 데이터베이스 솔루션에는 NoSQL용 Azure Cosmos DB를 사용합니다.
오픈 소스 Citus 확장을 사용하여 분할된 PostgreSQL용 Azure Database for PostgreSQL의 탄력적 클러스터 기능을 사용합니다.
Azure Data Factory는 클라우드 기반 ETL 및 데이터 통합 서비스입니다. 이를 통해 데이터 기반 워크플로를 만들어 데이터를 대규모로 이동하고 변환할 수 있습니다.
Data Factory를 사용하여 서로 다른 데이터 저장소의 데이터를 수집할 수 있는 데이터 기반 워크플로(파이프라인이라고 함)를 만들고 예약할 수 있습니다. 파이프라인은 분석 및 보고를 위해 온-프레미스, Azure 또는 기타 클라우드 공급자에서 실행할 수 있습니다.
Data Factory에는 Azure Cosmos DB for PostgreSQL에 대한 데이터 싱크가 있습니다. 데이터 싱크를 사용하면 저장, 처리 및 보고를 위해 데이터(관계형, NoSQL, 데이터 레이크 파일)를 Azure Cosmos DB for PostgreSQL 테이블로 가져올 수 있습니다.
중요
Data Factory는 현재 Azure Cosmos DB for PostgreSQL에 대한 프라이빗 엔드포인트를 지원하지 않습니다.
데이터 실시간 수집용 데이터 팩토리
Azure Cosmos DB for PostgreSQL에 데이터를 수집하기 위해 Azure Data Factory를 선택하는 주요 이유는 다음과 같습니다.
- 용이성 - 데이터 이동을 조정하고 자동화하기 위한 코드 없는 시각적 환경을 제공합니다.
- 강력함 - 기본 네트워크 대역폭의 전체 용량을 최대 5GiB/s 처리량으로 사용합니다.
- 기본 제공 커넥터 - 모든 데이터 원본을 90개 이상의 기본 제공 커넥터와 통합합니다.
- 비용 효율성 - 필요에 따라 스케일링되는 종량제, 완전 관리형 서버리스 클라우드 서비스를 지원합니다.
Data Factory를 사용하는 단계
이 문서에서는 Data Factory UI(사용자 인터페이스)를 사용하여 데이터 파이프라인을 만듭니다. 데이터 팩터리의 파이프라인은 Azure Blob Storage에서 데이터베이스로 데이터를 복사합니다. 원본 및 싱크로 지원되는 데이터 저장소의 목록은 지원되는 데이터 저장소 표를 참조하세요.
Data Factory에서 복사 활동을 사용하여 온-프레미스 및 클라우드에 있는 데이터 저장소 간에 데이터를 Azure Cosmos DB for PostgreSQL로 복사할 수 있습니다. Data Factory를 처음 사용하는 경우 시작하는 방법에 대한 빠른 가이드는 다음과 같습니다.
Data Factory가 프로비전되면 Data Factory로 이동하여 Azure Data Factory Studio를 시작합니다. 다음 그림과 같이 Data Factory 홈페이지가 표시됩니다.
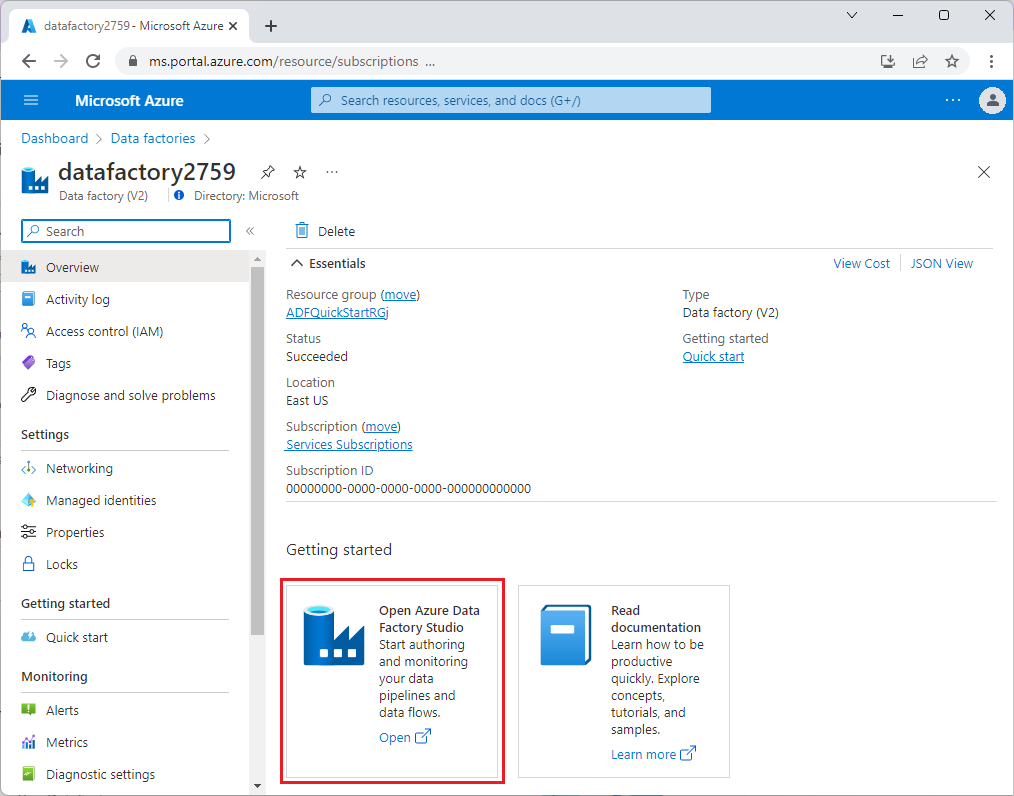
Azure Data Factory Studio 홈페이지에서 오케스트레이션을 선택합니다.
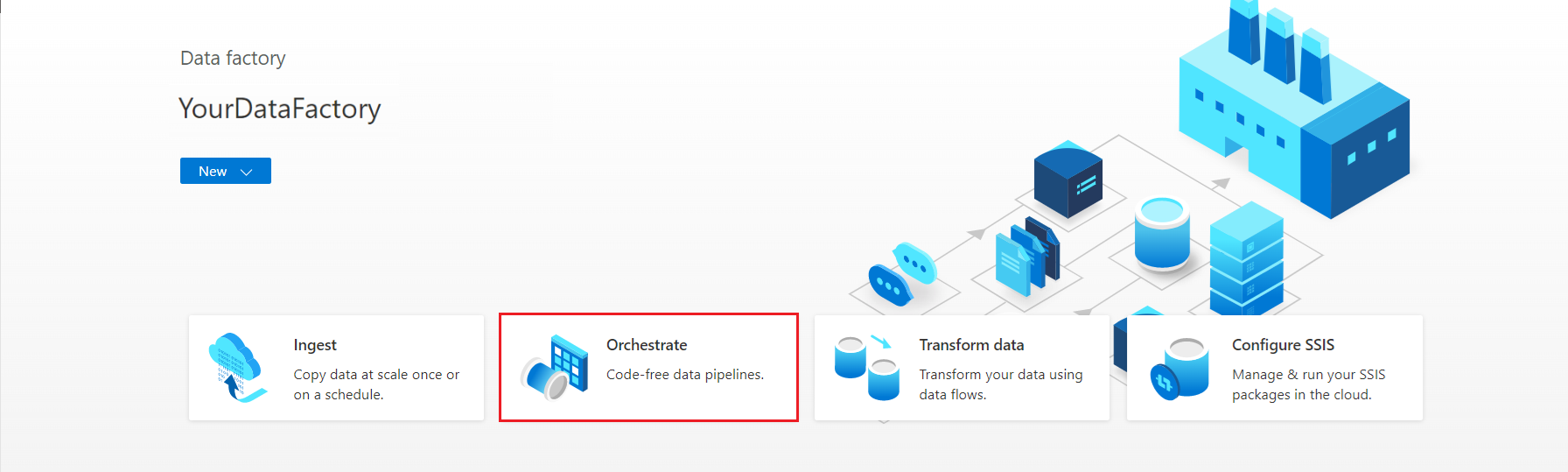
속성에서 파이프라인의 이름을 입력합니다.
활동 도구 상자에서 이동 및 변환 범주를 확장하고 데이터 복사 작업을 파이프라인 디자이너 화면으로 끌어서 놓습니다. 디자이너 창 아래쪽의 일반 탭에서 복사 활동의 이름을 입력합니다.
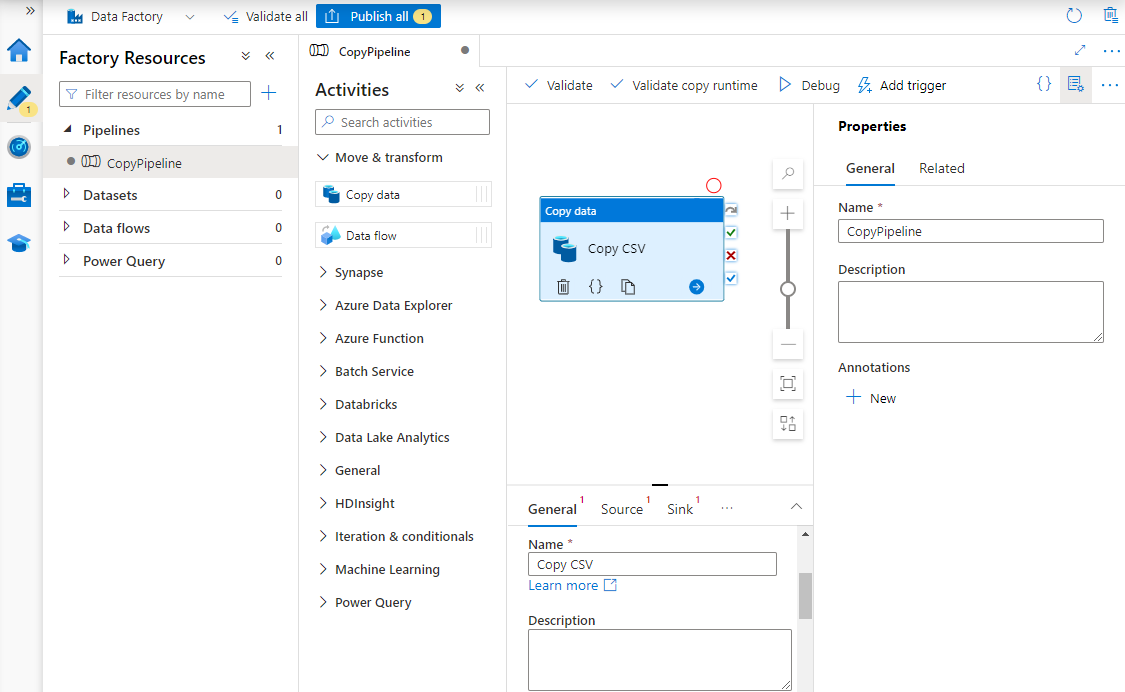
원본을 구성합니다.
활동 페이지에서 원본 탭을 선택합니다. 새로 만들기를 선택하여 원본 데이터 세트를 만듭니다.
새 데이터 세트 대화 상자에서 Azure Blob Storage를 선택한 다음, 계속을 선택합니다.
데이터 형식 형식을 선택한 다음 계속을 선택합니다.
속성 설정 페이지의 연결된 서비스에서 새로 만들기를 선택합니다.
새 연결된 서비스 페이지에서 연결된 서비스의 이름을 입력하고 스토리지 계정 이름 목록에서 스토리지 계정을 선택합니다.
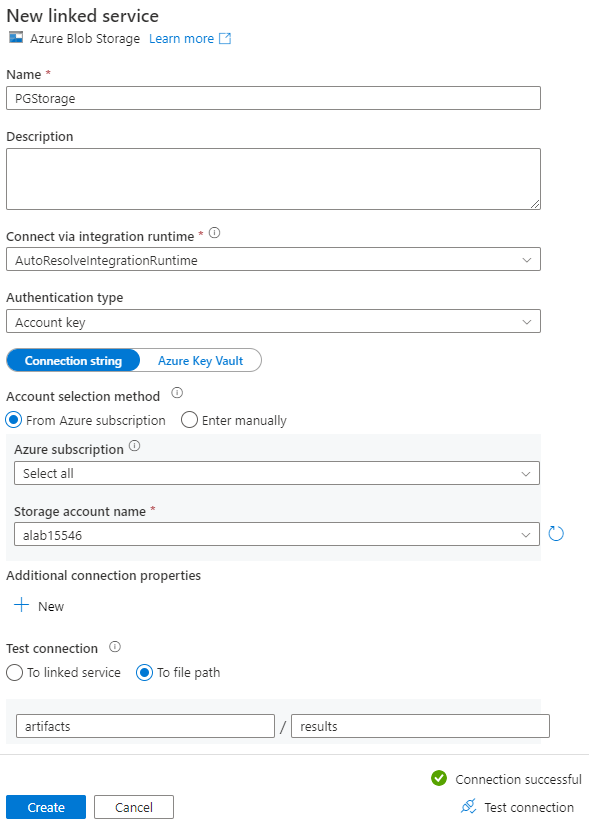
연결 테스트에서 파일 경로에를 선택하고 연결할 컨테이너 및 디렉터리를 입력한 다음, 연결 테스트를 선택합니다.
만들기를 선택하여 구성을 저장합니다.
속성 설정 화면에서 확인을 선택합니다.
싱크를 구성합니다.
활동 페이지에서 싱크 탭을 선택합니다. 새로 만들기를 선택하여 싱크 데이터 세트를 만듭니다.
새 데이터 세트 대화 상자에서 Azure Database for PostgreSQL을 선택한 다음 계속을 선택합니다.
속성 설정 페이지의 연결된 서비스에서 새로 만들기를 선택합니다.
새 연결된 서비스 페이지에서 연결된 서비스의 이름을 입력하고 계정 선택 방법에서 수동 입력을 선택합니다.
정규화된 도메인 이름 필드에 클러스터의 코디네이터 이름을 입력합니다. Azure Cosmos DB for PostgreSQL 클러스터의 개요 페이지에서 코디네이터의 이름을 복사할 수 있습니다.
코디네이터에 직접 연결하려면 포트 필드에 기본 포트 5432를 그대로 두고, 관리되는 PgBouncer 포트에 연결하려면 포트 6432로 바꿉니다.
클러스터에 데이터베이스 이름을 입력하고 연결하기 위한 자격 증명을 제공합니다.
암호화 방법 드롭다운 목록에서 SSL을 선택합니다.
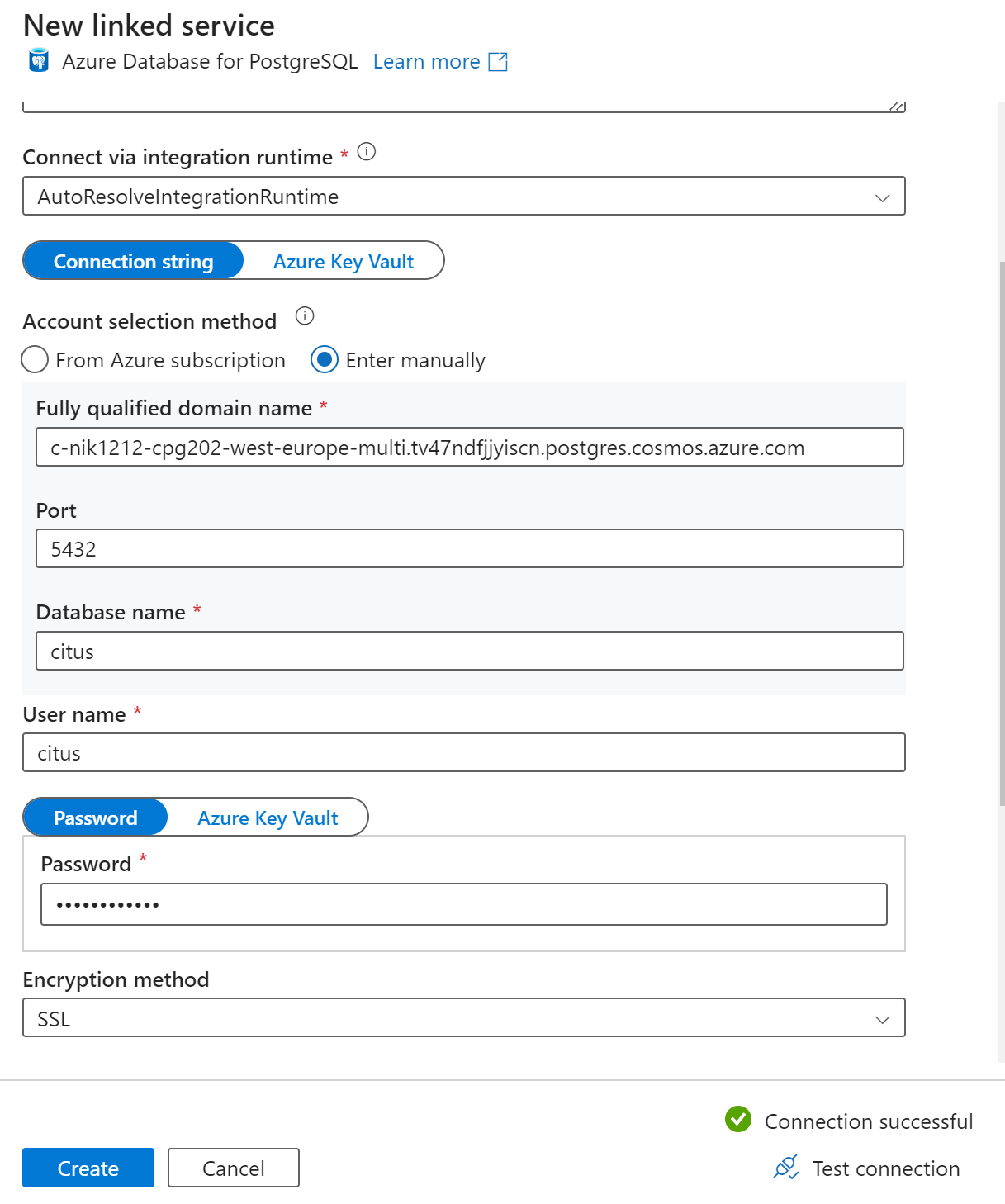
싱크 구성의 유효성을 검사하려면 패널 하단에서 연결 테스트를 선택합니다.
만들기를 선택하여 구성을 저장합니다.
속성 설정 화면에서 확인을 선택합니다.
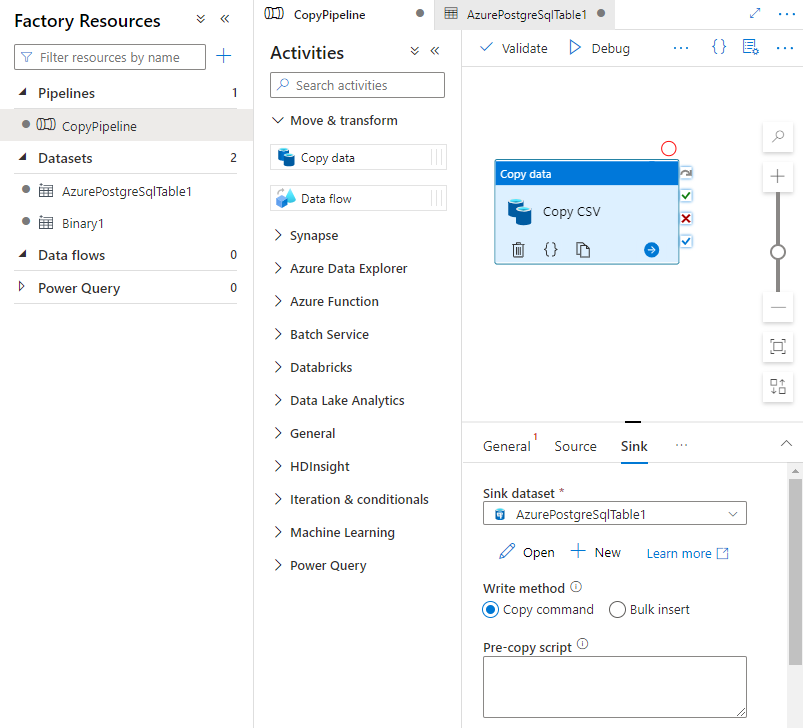
작업 페이지의 싱크 탭에서 싱크 데이터 세트 드롭다운 목록 옆에 있는 열기를 선택하고 데이터를 수집하려는 대상 클러스터에서 테이블 이름을 선택합니다.
쓰기 방법에서 복사 명령을 선택합니다.
캔버스 위의 도구 모음에서 유효성 검사를 선택하여 파이프라인 설정의 유효성을 검사합니다. 오류를 수정하고 유효성을 재검사하고 파이프라인이 성공적으로 유효성 검사되었는지 확인합니다.
도구 모음에서 디버그를 선택하여 파이프라인을 실행합니다.
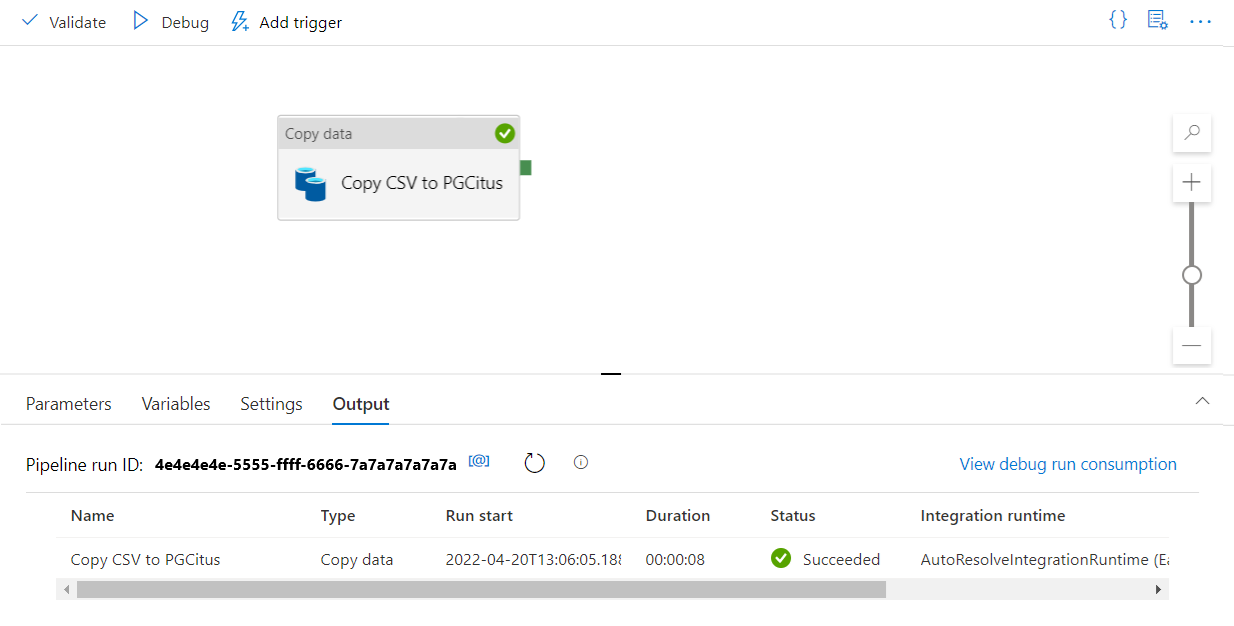
파이프라인이 성공적으로 실행되면 위쪽 도구 모음에서 모두 게시를 선택합니다. 이 작업은 사용자가 만든 엔터티(데이터 세트 및 파이프라인)를 Data Factory에 게시합니다.
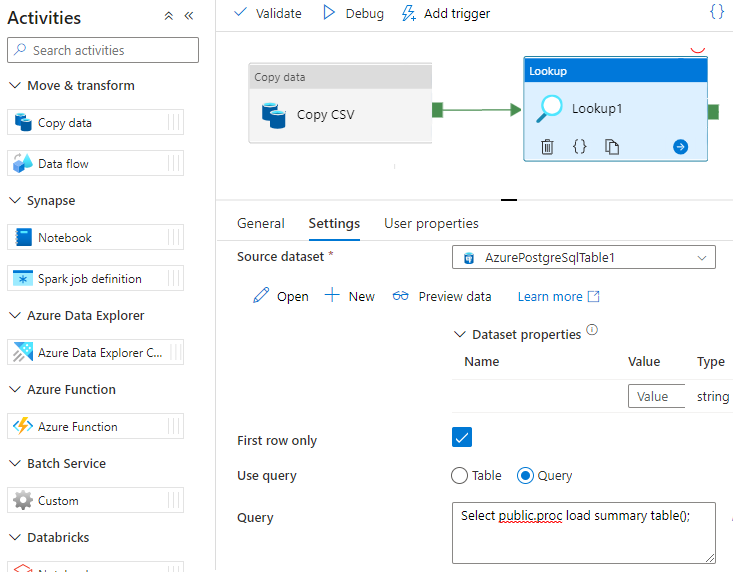
Data Factory에서 저장 프로시저 호출
일부 특정 시나리오에서는 저장 프로시저/함수를 호출하여 집계된 데이터를 준비 테이블에서 요약 테이블로 푸시할 수 있습니다. Data Factory는 Azure Cosmos DB for PostgreSQL에 대한 저장 프로시저 작업을 제공하지 않지만, 해결 방법으로 쿼리와 함께 조회 활동을 사용하여 아래와 같이 저장 프로시저를 호출할 수 있습니다.
다음 단계
- Azure Cosmos DB for PostgreSQL을 사용하여 실시간 대시보드를 만드는 방법을 알아봅니다.
- 워크로드를 Azure Cosmos DB for PostgreSQL로 이동하는 방법 알아보기