Apache HBase에서 Azure Cosmos DB for NoSQL 계정으로 데이터 마이그레이션
적용 대상: ![]() NoSQL
NoSQL
Azure Cosmos DB는 확장 가능하고 전 세계적으로 분산되고 완전히 관리되는 데이터베이스입니다. 데이터에 대한 짧은 대기 시간 액세스를 보장합니다. Azure Cosmos DB에 대한 자세한 내용은 개요 문서를 참조하세요. 이 문서에서는 데이터를 HBase에서 Azure Cosmos DB for NoSQL 계정으로 마이그레이션하는 방법을 안내합니다.
Azure Cosmos DB와 HBase의 차이점
마이그레이션하기 전에 Azure Cosmos DB와 HBase의 차이점을 이해해야 합니다.
리소스 모델
Azure Cosmos DB에는 다음과 같은 리소스 모델이 있습니다. 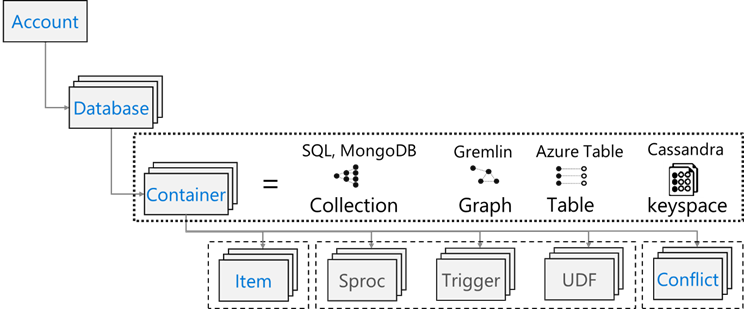
HBase에는 다음과 같은 리소스 모델이 있습니다. 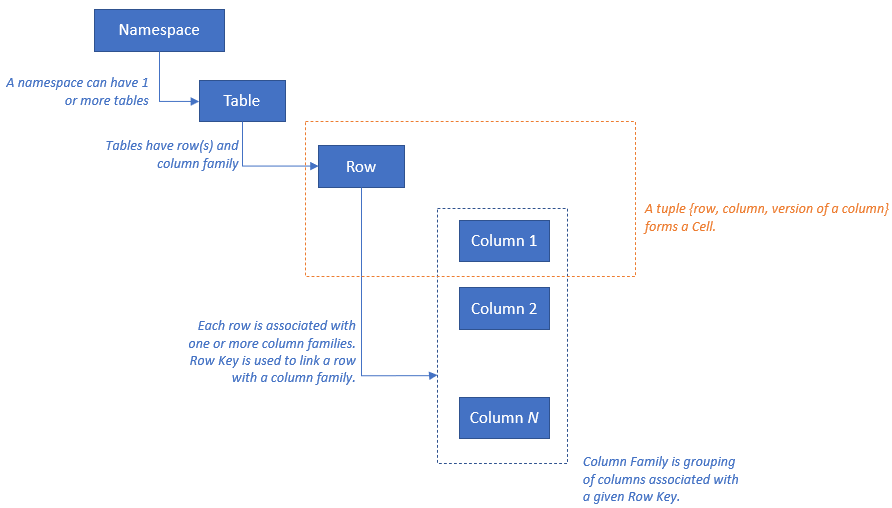
리소스 매핑
다음 표에서는 Apache HBase, Apache Phoenix 및 Azure Cosmos DB 간의 개념적 매핑을 보여 줍니다.
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| 클러스터 | 클러스터 | 어카운트 |
| 네임스페이스 | 스키마(사용하도록 설정된 경우) | 데이터베이스 |
| 테이블 | 테이블 | 컨테이너/컬렉션 |
| 열 패밀리 | 열 패밀리 | 해당 없음 |
| Row | Row | 항목/문서 |
| 버전(타임스탬프) | 버전(타임스탬프) | 해당 없음 |
| 해당 없음 | Primary Key | 파티션 키 |
| 해당 없음 | 색인 | 색인 |
| 해당 없음 | 보조 인덱스 | 보조 인덱스 |
| 해당 없음 | 보기 | 해당 없음 |
| 해당 없음 | Sequence | 해당 없음 |
데이터 구조 비교 및 차이점
Azure Cosmos DB와 HBase의 데이터 구조의 주요 차이점은 다음과 같습니다.
RowKey
HBase에서 데이터는 RowKey에 따라 저장되고, 테이블을 만드는 중에 지정된 RowKey의 범위에 따라 지역으로 가로로 분할됩니다.
다른 쪽의 Azure Cosmos DB는 지정된 파티션 키의 해시 값에 따라 데이터를 파티션에 배포합니다.
열 패밀리
HBase에서 열은 CF(열 패밀리) 내에서 그룹화됩니다.
Azure Cosmos DB(NoSQL용 API)는 데이터를 JSON 문서로 저장합니다. 따라서 JSON 데이터 구조와 연결된 모든 속성이 적용됩니다.
Timestamp
HBase는 타임스탬프를 사용하여 지정된 셀의 여러 인스턴스에 대한 버전을 관리합니다. 타임스탬프를 사용하여 다른 버전의 셀을 쿼리할 수 있습니다.
Azure Cosmos DB는 컨테이너에 대한 변경 내용의 지속적인 기록을 발생한 순서대로 추적하는 변경 피드 기능과 함께 제공됩니다. 그런 다음 변경된 문서가 수정된 순서로 정렬된 목록이 출력됩니다.
날짜 형식
HBase 데이터 형식은 RowKey, 열 패밀리: 열 이름, 타임스탬프, 값으로 구성됩니다. HBase 테이블 행의 예는 다음과 같습니다.
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001Azure Cosmos DB for NoSQL에서 JSON 개체는 데이터 형식을 나타냅니다. 파티션 키는 문서의 필드에 있으며, 컬렉션에 대한 파티션 키인 필드를 설정합니다. Azure Cosmos DB에는 열 패밀리 또는 버전에 사용되는 타임스탬프 개념이 없습니다. 이전에 강조한 대로 컨테이너에서 수행된 변경 내용을 추적/기록할 수 있는 변경 피드 지원이 있습니다. 문서의 예는 다음과 같습니다.
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
팁
HBase는 데이터를 바이트 배열에 저장하므로 2바이트 문자가 포함된 데이터를 Azure Cosmos DB로 마이그레이션하려면 데이터가 UTF-8로 인코딩되어야 합니다.
일관성 모델
HBase는 엄격하게 일관된 읽기 및 쓰기를 제공합니다.
Azure Cosmos DB는 5가지 잘 정의된 일관성 수준을 제공합니다. 각 수준은 가용성 및 성능 절충안을 제공합니다. 가장 강력한 수준에서 가장 약한 수준으로 지원되는 일관성 수준은 다음과 같습니다.
- 강력
- 제한된 부실
- 세션
- 일관적인 접두사
- 최종
크기 조정
HBase
HBase의 엔터프라이즈 규모 배포의 경우 마스터, 지역 서버; 및 ZooKeeper에서 대부분의 크기 조정을 구동합니다. 분산 애플리케이션과 마찬가지로 HBase는 스케일 아웃하도록 설계되었습니다. HBase 성능은 주로 HBase RegionServers의 크기에 따라 구동됩니다. 크기 조정은 주로 HBase에 저장해야 하는 데이터 세트의 처리량과 크기라는 두 가지 주요 요구 사항에 따라 구동됩니다.
Azure Cosmos DB
Azure Cosmos DB는 Microsoft의 PaaS 제품이며, 기본 인프라 배포 세부 정보는 최종 사용자로부터 추상화됩니다. Azure Cosmos DB 컨테이너가 프로비전되면 Azure 플랫폼에서 지정된 워크로드의 성능 요구 사항을 지원하기 위해 기본 인프라(컴퓨팅, 스토리지, 메모리, 네트워킹 스택)를 자동으로 프로비전합니다. 모든 데이터베이스 작업 비용은 Azure Cosmos DB에서 정규화되며, RU(요청 단위)로 표시됩니다.
워크로드에서 사용하는 RU를 예측하려면 다음 요인을 고려합니다.
RU 크기 조정 연습을 지원하는 데 사용할 수 있는 용량 계산기가 있습니다.
또한 Azure Cosmos DB에서 자동 크기 조정 프로비전 처리량을 사용하여 데이터베이스 또는 컨테이너 처리량(RU/초)의 크기를 자동으로 즉시 조정할 수 있습니다. 처리량의 크기는 워크로드 가용성, 대기 시간, 처리량 또는 성능에 영향을 주지 않고 사용량에 따라 조정됩니다.
데이터 배포
HBase HBase는 RowKey에 따라 데이터를 정렬합니다. 그런 다음, 데이터를 지역으로 분할하고 RegionServers에 저장합니다. 자동 분할은 분할 정책에 따라 지역을 가로로 분할합니다. 이는 hbase.hregion.max.filesize HBase 매개 변수에 할당된 값(기본값은 10GB)을 통해 제어됩니다. 지정된 RowKey가 있는 HBase의 행은 항상 한 지역에 속합니다. 또한 데이터는 각 열 패밀리에 대해 디스크에서 구분됩니다. 이렇게 하면 HFile에서 I/O를 읽고 격리할 때 필터링할 수 있습니다.
Azure Cosmos DB Azure Cosmos DB는 분할을 사용하여 데이터베이스의 개별 컨테이너의 크기를 조정합니다. 분할은 컨테이너의 항목을 "논리 파티션"이라고 하는 특정 하위 집합으로 나눕니다. 논리 파티션은 컨테이너의 각 항목과 연결된 "파티션 키"의 값에 따라 구성됩니다. 논리 파티션의 모든 항목에는 동일한 파티션 키 값이 있습니다. 각 논리 파티션은 최대 20GB의 데이터를 보유할 수 있습니다.
실제 파티션에는 각각 데이터 복제본과 Azure Cosmos DB 데이터베이스 엔진 인스턴스가 포함됩니다. 이 구조는 데이터의 내구성과 가용성을 높이고 처리량은 로컬 물리 파티션 간에 균등하게 분할됩니다. 물리적 파티션은 자동으로 만들어지고 구성되지만 크기, 위치 또는 포함된 논리적 파티션은 제어할 수 없습니다. 논리 파티션은 실제 파티션 간에 분할되지 않습니다.
HBase RowKey와 마찬가지로 파티션 키 디자인은 Azure Cosmos DB에 중요합니다. HBase의 RowKey는 데이터를 정렬하고 연속 데이터를 저장하는 방식으로 작동하며, Azure Cosmos DB의 파티션 키는 데이터를 해시 배포하므로 다른 메커니즘입니다. HBase를 사용하는 애플리케이션이 HBase에 대한 데이터 액세스 패턴에 최적화된다고 가정하면 동일한 RowKey를 파티션 키에 사용하더라도 좋은 성능 결과를 얻을 수 없습니다. HBase에서 정렬되는 데이터임을 고려하면 Azure Cosmos DB 복합 인덱스가 유용할 수 있습니다. 이는 둘 이상의 필드에서 ORDER BY 절을 사용하려는 경우에 필요합니다. 또한 복합 인덱스를 정의하여 많은 동등 및 범위 쿼리의 성능을 향상시킬 수 있습니다.
가용성
HBase HBase는 마스터, 지역 서버 및 ZooKeeper로 구성됩니다. 단일 클러스터의 고가용성은 각 구성 요소를 중복하여 달성할 수 있습니다. 지역 중복을 구성하면 HBase 클러스터를 여러 물리적 데이터 센터에 배포하고 복제를 사용하여 여러 클러스터를 동기화 상태로 유지할 수 있습니다.
Azure Cosmos DB Azure Cosmos DB에는 클러스터 구성 요소 중복과 같은 구성이 필요하지 않습니다. 고가용성, 일관성 및 대기 시간에 대한 포괄적인 SLA를 제공합니다. 자세한 내용은 Azure Cosmos DB에 대한 SLA를 참조하세요.
데이터 안정성
HBase HBase는 HDFS(Hadoop 분산 파일 시스템)를 기반으로 하며, HDFS에 저장된 데이터는 세 번 복제됩니다.
Azure Cosmos DB Azure Cosmos DB는 주로 두 가지 방법으로 고가용성을 제공합니다. 먼저 Azure Cosmos DB에서 데이터를 Azure Cosmos DB 계정 내에 구성된 지역 간에 복제합니다. 다음으로 Azure Cosmos DB에서 4개의 데이터 복제본을 해당 지역에 보관합니다.
마이그레이션 전 고려 사항
시스템 종속성
이 계획 측면은 Azure Cosmos DB로 마이그레이션되는 HBase 인스턴스에 대한 업스트림 및 다운스트림 종속성을 이해하는 데 중점을 둡니다.
다운스트림 종속성의 예는 HBase에서 데이터를 읽는 애플리케이션일 수 있습니다. Azure Cosmos DB에서 읽으려면 이러한 종속성을 리팩터링해야 합니다. 마이그레이션의 일환으로 고려해야 하는 사항은 다음과 같습니다.
종속성 평가 질문 - 현재 HBase 시스템이 독립 구성 요소인가요? 또는 다른 시스템의 프로세스를 호출하거나, 다른 시스템의 프로세스에서 호출하거나, 디렉터리 서비스를 사용하여 액세스하나요? 다른 중요한 프로세스가 HBase 클러스터에서 작동하나요? 마이그레이션의 영향을 확인하려면 이러한 시스템 종속성을 명확히 설명해야 합니다.
온-프레미스 HBase 배포에 대한 RPO 및 RTO
오프라인 및 온라인 마이그레이션
성공적인 데이터 마이그레이션을 위해 데이터베이스를 사용하는 비즈니스의 특성을 이해하고 이를 수행하는 방법을 결정해야 합니다. 시스템을 완전히 종료하고 데이터 마이그레이션을 수행하고 대상에서 시스템을 다시 시작할 수 있는 경우 오프라인 마이그레이션을 선택합니다. 또한 데이터베이스가 항상 사용 중이고 오랜 가동 중단을 허용할 수 없는 경우 온라인 마이그레이션을 고려합니다.
참고 항목
이 문서에서는 오프라인 마이그레이션만 다룹니다.
오프라인 데이터 마이그레이션을 수행하는 경우 현재 실행 중인 HBase의 버전과 사용 가능한 도구에 따라 달라집니다. 자세한 내용은 데이터 마이그레이션 섹션을 참조하세요.
성능 고려 사항
이 계획 측면은 HBase의 성능 목표를 이해한 다음, 이를 Azure Cosmos DB 의미 체계로 변환하는 것입니다. 예를 들어 HBase에서 "X" IOPS를 달성하려면 Azure Cosmos DB에서 얼마나 많은 요청 단위(RU/초)가 필요할까요? HBase와 Azure Cosmos DB 간에 차이점이 있습니다. 이 연습에서는 HBase의 성능 목표가 Azure Cosmos DB로 변환되는 방법에 대한 보기를 구축하는 데 중점을 둡니다. 이 경우 크기 조정 연습이 구동됩니다.
질문:
- HBase 배포에는 읽기가 많나요? 아니면 쓰기가 많나요?
- 읽기와 쓰기 간의 분할은 무엇인가요?
- 목표 IOPS에서 백분위수로 표현하는 것은 무엇인가요?
- 데이터를 HBase에 로드하는 데 사용되는 애플리케이션은 무엇이고, 어떻게 사용되나요?
- HBase에서 데이터를 읽는 데 사용되는 애플리케이션은 무엇이고, 어떻게 사용되나요?
정렬된 데이터를 요청하는 쿼리를 실행하면 데이터가 RowKey에 따라 정렬되므로 HBase에서 결과를 빠르게 반환합니다. 그러나 Azure Cosmos DB에는 이러한 개념이 없습니다. 성능을 최적화하기 위해 필요에 따라 복합 인덱스를 사용할 수 있습니다.
배포 고려 사항
Azure Portal 또는 Azure CLI를 사용하여 Azure Cosmos DB for NoSQL을 배포할 수 있습니다. 마이그레이션 대상이 Azure Cosmos DB for NoSQL이므로 배포할 때 API에 대한 "NoSQL"을 매개 변수로 선택합니다. 또한 가용성 요구 사항에 따라 지역 중복성, 다중 지역 쓰기 및 가용성 영역을 설정합니다.
네트워크 고려 사항
Azure Cosmos DB에는 세 가지 기본 네트워크 옵션이 있습니다. 첫 번째는 공용 IP 주소를 사용하고 IP 방화벽(기본값)을 사용하여 액세스를 제어하는 구성입니다. 두 번째는 공용 IP 주소를 사용하고 특정 가상 네트워크(서비스 엔드포인트)의 특정 서브넷에서만 액세스를 허용하는 구성입니다. 세 번째는 개인 IP 주소를 사용하여 개인 네트워크에 조인하는 구성(프라이빗 엔드포인트)입니다.
세 가지 네트워크 옵션에 대한 자세한 내용은 다음 문서를 참조하세요.
기존 데이터 평가
데이터 검색
기존 HBase 클러스터에서 정보를 미리 수집하여 마이그레이션하려는 데이터를 식별합니다. 이렇게 하면 마이그레이션 방법을 식별하고, 마이그레이션할 테이블을 결정하고, 해당 테이블 내의 구조를 이해하고, 데이터 모델을 구축하는 방법을 결정하는 데 도움이 될 수 있습니다. 예를 들어 수집하는 세부 정보는 다음과 같습니다.
- HBase 버전
- 마이그레이션 대상 테이블
- 열 패밀리 정보
- 테이블 상태
다음 명령은 hbase 셸 스크립트를 사용하여 위의 세부 정보를 수집하고 운영 컴퓨터의 로컬 파일 시스템에 저장하는 방법을 보여 줍니다.
HBase 버전 가져오기
hbase version -n > hbase-version.txt
출력:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
테이블 목록 가져오기
HBase에 저장된 테이블 목록을 가져올 수 있습니다. default가 아닌 네임스페이스를 만든 경우 "네임스페이스: 테이블" 형식으로 출력됩니다.
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
출력:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
마이그레이션할 테이블 식별
마이그레이션할 테이블 이름을 지정하여 테이블의 열 패밀리에 대한 세부 정보를 가져옵니다.
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
출력:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
테이블의 열 패밀리 및 해당 설정 가져오기
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
출력:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
힙 메모리의 크기, 지역 수, 요청 수와 같은 유용한 크기 조정 정보를 클러스터 상태로 가져오고, 압축/비압축 데이터의 크기를 테이블 상태로 가져올 수 있습니다.
HBase 클러스터에서 Apache Phoenix를 사용하는 경우 Phoenix에서도 데이터를 수집해야 합니다.
- 마이그레이션 대상 테이블
- 테이블 스키마
- 인덱스
- 기본 키
클러스터에서 Apache Phoenix에 연결
sqlline.py ZOOKEEPER/hbase-unsecure
테이블 목록 가져오기
!tables
테이블 세부 정보 가져오기
!describe <Table Name>
인덱스 세부 정보 가져오기
!indexes <Table Name>
기본 키 세부 정보 가져오기
!primarykeys <Table Name>
데이터 마이그레이션
마이그레이션 옵션
데이터를 오프라인으로 마이그레이션하는 다양한 방법이 있지만 여기에서는 Azure Data Factory를 사용하는 방법을 소개합니다.
| 솔루션 | 원본 버전 | 고려 사항 |
|---|---|---|
| Azure Data Factory | HBase 2 미만 | 쉽게 설정할 수 있습니다. 대규모 데이터 세트에 적합합니다. HBase 2 이상은 지원하지 않습니다. |
| Apache Spark | 모든 버전 | 모든 HBase 버전을 지원합니다. 대규모 데이터 세트에 적합합니다. Spark 설정이 필요합니다. |
| Azure Cosmos DB 대량 실행기 라이브러리가 있는 사용자 지정 도구 | 모든 버전 | 라이브러리를 사용하여 사용자 지정 데이터 마이그레이션 도구를 만드는 데 가장 유연합니다. 설정하는 데 더 많은 노력이 필요합니다. |
다음 순서도에서는 몇 가지 조건을 사용하여 사용 가능한 데이터 마이그레이션 방법에 도달합니다.
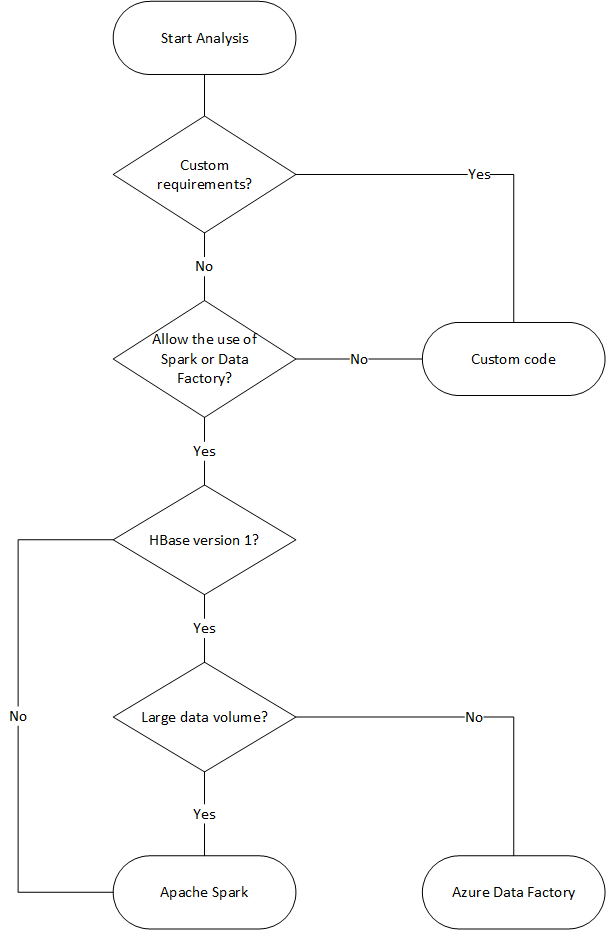
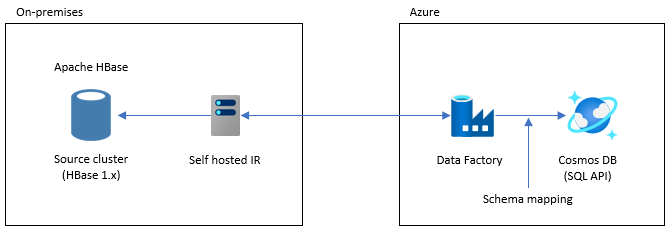
Data Factory를 사용하여 마이그레이션
이 옵션은 큰 데이터 세트에 적합합니다. Azure Cosmos DB 대량 실행기 라이브러리가 사용됩니다. 검사점이 없으므로 마이그레이션 중에 문제가 발생하면 마이그레이션 프로세스를 처음부터 다시 시작해야 합니다. 또한 Data Factory의 자체 호스팅 통합 런타임을 사용하여 온-프레미스 HBase에 연결하거나, Data Factory를 관리형 VNET에 배포하고 VPN 또는 ExpressRoute를 통해 온-프레미스 네트워크에 연결할 수 있습니다.
Data Factory의 복사 작업은 HBase를 데이터 원본으로 지원합니다. 자세한 내용은 Azure Data Factory를 사용하여 HBase에서 데이터 복사 문서를 참조하세요.
Azure Cosmos DB(NoSQL용 API)를 데이터 대상으로 지정할 수 있습니다. 자세한 내용은 Azure Data Factory를 사용하여 Azure Cosmos DB(NoSQL용 API)에서 데이터 복사 및 변환 문서를 참조하세요.
Apache Spark를 사용하여 마이그레이션 - Apache HBase 커넥터 및 Cosmos DB Spark 커넥터
다음은 데이터를 Azure Cosmos DB로 마이그레이션하는 예입니다. HBase 2.1.0 및 Spark 2.4.0이 동일한 클러스터에서 실행된다고 가정합니다.
Apache Spark – Apache HBase 커넥터 리포지토리는 Apache Spark - Apache HBase 커넥터에서 찾을 수 있습니다.
Azure Cosmos DB Spark 커넥터의 경우 빠른 시작 가이드를 참조하고 Spark 버전에 적합한 라이브러리를 다운로드합니다.
hbase-site.xml을 Spark 구성 디렉터리에 복사합니다.
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/Spark HBase 커넥터 및 Azure Cosmos DB Spark 커넥터를 사용하여 spark -shell을 실행합니다.
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarSpark 셸이 시작되면 다음과 같이 Scala 코드를 실행합니다. HBase에서 데이터를 로드하는 데 필요한 라이브러리를 가져옵니다.
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._HBase 테이블에 대한 Spark 카탈로그 스키마를 정의합니다. 여기서 네임스페이스는 "default"이고 테이블 이름은 "Contacts"입니다. 행 키는 키로 지정됩니다. 열, 열 패밀리 및 열은 Spark의 카탈로그에 매핑됩니다.
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMargin다음으로 HBase Contacts 테이블에서 데이터를 DataFrame으로 가져오는 메서드를 정의합니다.
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }정의된 메서드를 사용하여 DataFrame을 만듭니다.
val df = withCatalog(catalog)그런 다음, Azure Cosmos DB Spark 커넥터를 사용하는 데 필요한 라이브러리를 가져옵니다.
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.Config데이터를 Azure Cosmos DB에 쓰도록 설정합니다.
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.com:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))DataFrame 데이터를 Azure Cosmos DB에 씁니다.
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
고속으로 병렬로 쓰므로 성능이 높습니다. 반면 Azure Cosmos DB 쪽에서 RU/초를 모두 소모할 수 있습니다.
Phoenix
Phoenix는 Data Factory 데이터 원본으로 지원됩니다. 자세한 단계는 다음 문서를 참조하세요.
코드 마이그레이션
이 섹션에서는 Azure Cosmos DB for NoSQL과 HBase에서 애플리케이션을 만드는 것의 차이점에 대해 설명합니다. 여기의 예제에서는 Apache HBase 2.x API 및 Azure Cosmos DB Java SDK v4를 사용합니다.
이러한 HBase의 샘플 코드는 HBase의 공식 설명서에서 설명하는 코드를 기반으로 합니다.
여기에 제공되는 Azure Cosmos DB용 코드는 Azure Cosmos DB for NoSQL: Java SDK v4 예제 설명서를 기반으로 합니다. 설명서에서 전체 코드 예제에 액세스할 수 있습니다.
여기에는 코드 마이그레이션에 대한 매핑이 표시되지만, 이러한 예제에 사용된 HBase RowKey 및 Azure Cosmos DB 파티션 키가 항상 잘 설계된 것은 아닙니다. 마이그레이션 원본의 실제 데이터 모델에 따라 설계합니다.
연결 설정
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
데이터베이스/테이블/컬렉션 만들기
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
행/문서 만들기
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
Azure Cosmos DB는 데이터 모델을 통해 형식 안전성을 제공합니다. ‘Family’라는 데이터 모델을 사용합니다.
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
위는 코드의 일부입니다. 전체 코드 예제를 참조하세요.
Family 클래스를 사용하여 문서를 정의하고 항목을 삽입합니다.
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
행/문서 읽기
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
데이터 업데이트
HBase
HBase의 경우 append 메서드 및 checkAndPut 메서드를 사용하여 값을 업데이트합니다. 추가는 현재 값의 끝에 원자성으로 값을 추가하는 프로세스이며 checkAndPut은 현재 값을 예상 값과 원자성으로 비교하고 일치하는 경우에만 업데이트합니다.
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
Azure Cosmos DB에서 업데이트는 Upsert 작업으로 처리됩니다. 즉, 문서가 없으면 삽입됩니다.
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
행/문서 삭제
HBase
HBase에는 값에 따라 행을 선택하는 직접 삭제 방법이 없습니다. ValueFilter 등과 조합하여 삭제 프로세스를 구현했을 수 있습니다. 다음 예제에서 삭제할 행은 RowKey에 따라 지정됩니다.
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
문서 ID별 삭제 방법은 아래와 같습니다.
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
행/문서 쿼리
HBase HBase를 사용하면 검사를 사용하여 여러 행을 검사할 수 있습니다. Filter를 사용하여 자세한 검사 조건을 지정할 수 있습니다. HBase 기본 제공 필터 유형은 클라이언트 요청 필터를 참조하세요.
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
필터 작업
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
테이블/컬렉션 삭제
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
기타 고려 사항
HBase 클러스터는 HBase 워크로드 및 MapReduce, Hive, Spark 등에서 사용할 수 있습니다. 현재 HBase와 다른 워크로드가 있는 경우 해당 워크로드도 마이그레이션해야 합니다. 자세한 내용은 각 마이그레이션 가이드를 참조하세요.
- MapReduce
- HBase
- Spark
서버 쪽 프로그래밍
HBase는 몇 가지 서버 쪽 프로그래밍 기능을 제공합니다. 이러한 기능을 사용하는 경우 해당 처리도 마이그레이션해야 합니다.
HBase
-
HBase에서 다양한 필터를 기본적으로 사용할 수 있지만 사용자 지정 필터를 구현할 수도 있습니다. HBase에서 기본적으로 사용할 수 있는 필터가 요구 사항을 충족하지 않는 경우 사용자 지정 필터를 구현할 수 있습니다.
-
보조 프로세서는 지역 서버에서 사용자 고유의 코드를 실행할 수 있는 프레임워크입니다. 보조 프로세서를 사용하면 클라이언트 쪽에서 실행한 처리를 서버 쪽에서 수행할 수 있으며 처리에 따라 더 효율적으로 수행할 수 있습니다. 보조 프로세서에는 관찰자 및 엔드포인트의 두 가지 유형이 있습니다.
관찰자
- 관찰자는 특정 작업 및 이벤트를 연결합니다. 이는 임의 처리를 추가하는 함수이며, RDBMS 트리거와 비슷한 기능입니다.
엔드포인트
- 엔드포인트는 HBase RPC를 확장하는 기능이며, RDBMS 저장 프로시저와 비슷한 함수입니다.
Azure Cosmos DB
-
- Azure Cosmos DB 저장 프로시저는 JavaScript로 작성되며, Azure Cosmos DB 컨테이너에서 항목 만들기, 업데이트, 읽기, 쿼리 및 삭제와 같은 작업을 수행할 수 있습니다.
-
- 트리거는 데이터베이스의 작업에 대해 지정할 수 있습니다. 데이터베이스 항목이 변경되기 전에 실행되는 사전 트리거와 데이터베이스 항목이 변경된 후에 실행되는 사후 트리거의 두 가지 메서드가 제공됩니다.
-
- Azure Cosmos DB를 사용하면 UDF(사용자 정의 함수)를 정의할 수 있습니다. UDF는 JavaScript로도 작성할 수 있습니다.
저장 프로시저 및 트리거는 수행하는 작업의 복잡성에 따라 RU를 사용합니다. 서버 쪽 처리를 개발하는 경우 각 작업에서 사용하는 RU 양을 더 잘 이해하기 위해 필요한 사용량을 확인합니다. 자세한 내용은 Azure Cosmos DB의 요청 단위 및 Azure Cosmos DB에서 요청 비용 최적화를 참조하세요.
서버 쪽 프로그래밍 매핑
| HBase | Azure Cosmos DB | 설명 |
|---|---|---|
| 사용자 지정 필터 | WHERE 절 | Azure Cosmos DB의 WHERE 절에서 사용자 지정 필터를 통해 구현된 처리를 수행할 수 없는 경우 UDF를 조합하여 사용합니다. |
| 보조 프로세서(관찰자) | 트리거 | 관찰자는 특정 이벤트 전후에 실행되는 트리거입니다. 관찰자가 사전 및 사후 호출을 지원하는 것처럼 Azure Cosmos DB의 트리거도 사전 및 사후 트리거를 지원합니다. |
| 보조 프로세서(엔드포인트) | 저장 프로시저 | 엔드포인트는 각 지역에 대해 실행되는 서버 쪽 데이터 처리 메커니즘입니다. 이는 RDBMS 저장 프로시저와 비슷합니다. Azure Cosmos DB 저장 프로시저는 JavaScript를 사용하여 작성됩니다. 저장 프로시저를 통해 Azure Cosmos DB에서 수행할 수 있는 모든 작업에 대한 액세스를 제공합니다. |
참고 항목
HBase에서 구현된 처리에 따라 Azure Cosmos DB에서 다른 매핑 및 구현이 필요할 수 있습니다.
보안
데이터 보안은 고객 및 데이터베이스 공급자의 공동 책임입니다. 온-프레미스 솔루션의 경우 고객은 엔드포인트 보호에서 실제 하드웨어 보안까지 모든 것을 제공해야 하며, 이는 쉬운 작업이 아닙니다. Azure Cosmos DB와 같은 PaaS 클라우드 데이터베이스 공급자를 선택하면 고객 참여가 감소합니다. Azure Cosmos DB는 Azure 플랫폼에서 실행되므로 HBase와 다른 방식으로 향상될 수 있습니다. 보안을 위해 추가 구성 요소를 Azure Cosmos DB에 설치할 필요가 없습니다. 다음 검사 목록을 사용하여 데이터베이스 시스템 보안 구현을 마이그레이션하는 것이 좋습니다.
| 보안 제어 | HBase | Azure Cosmos DB |
|---|---|---|
| 네트워크 보안 및 방화벽 설정 | 네트워크 디바이스와 같은 보안 기능을 사용하여 트래픽을 제어합니다. | 인바운드 방화벽에서 정책 기반 IP 기반 액세스 제어를 지원합니다. |
| 사용자 인증 및 세분화된 사용자 제어 | Apache Ranger와 같은 보안 구성 요소와 LDAP를 결합하여 세분화된 액세스 제어입니다. | 계정 기본 키를 사용하여 각 데이터베이스에 대한 사용자 및 권한 리소스를 만듭니다. Microsoft Entra ID를 사용하여 데이터 요청을 인증할 수도 있습니다. 이렇게 하면 세분화된 RBAC 모델을 사용하여 데이터 요청에 대한 권한을 부여할 수 있습니다. |
| 지역별 오류에 대해 전역으로 데이터를 복제하는 기능 | HBase의 복제를 사용하여 원격 데이터 센터에서 데이터베이스 복제본을 만듭니다. | Azure Cosmos DB는 구성이 없는 글로벌 배포를 수행하므로, 단추를 선택하면 Azure에서 데이터를 전 세계의 데이터 센터에 복제할 수 있습니다. 보안 측면에서 글로벌 복제는 데이터가 로컬 오류로부터 보호되도록 합니다. |
| 데이터 센터 간의 장애 조치(failover) 기능 | 장애 조치(failover)를 직접 구현해야 합니다. | 데이터를 여러 데이터 센터에 복제하고, 해당 지역의 데이터 센터가 오프라인으로 전환되면 Azure Cosmos DB에서 작업을 자동으로 작동을 롤오버합니다. |
| 데이터 센터 내에서 로컬 데이터 복제 | HDFS 메커니즘을 사용하면 여러 복제본을 단일 파일 시스템 내의 노드에 사용할 수 있습니다. | Azure Cosmos DB는 고가용성을 유지하기 위해 단일 데이터 센터 내에서도 데이터를 자동으로 복제합니다. 일관성 수준을 직접 선택할 수 있습니다. |
| 자동 데이터 백업 | 자동 백업 함수가 없습니다. 데이터 백업을 직접 구현해야 합니다. | Azure Cosmos DB는 정기적으로 백업되어 지역 중복 스토리지에 저장됩니다. |
| 중요한 데이터 보호 및 격리 | 예를 들어 Apache Ranger를 사용하는 경우 Ranger 정책을 사용하여 정책을 테이블에 적용할 수 있습니다. | 개인 및 기타 중요한 데이터를 특정 컨테이너 및 읽기/쓰기로 분리하거나 읽기 전용 액세스를 특정 사용자로 제한할 수 있습니다. |
| 공격 모니터링 | 타사 제품을 사용하여 구현해야 합니다. | 감사 로깅 및 활동 로그를 사용하여 계정에서 정상 및 비정상적인 활동을 모니터링할 수 있습니다. |
| 공격에 대응 | 타사 제품을 사용하여 구현해야 합니다. | Azure 지원에 문의하고 잠재적인 공격을 보고하면 5단계 인시던트 응답 프로세스가 시작됩니다. |
| 지오-펜스 데이터가 데이터 관리 제한을 준수하는 기능 | 각 국가/지역의 제한 사항을 확인하고 직접 구현해야 합니다. | 소버린 지역(독일, 중국, US Gov 등)에 대한 데이터 거버넌스를 보장합니다. |
| 보호된 데이터 센터에서 서버의 물리적 보호 | 시스템이 있는 데이터 센터에 따라 달라집니다. | 최신 인증 목록은 글로벌 Azure 규정 준수 사이트를 참조하세요. |
| 인증 | Hadoop 배포에 따라 달라집니다. | Azure 규정 준수 설명서 참조 |
모니터링
HBase는 일반적으로 클러스터 메트릭 웹 UI 또는 Ambari, Cloudera Manager 또는 기타 모니터링 도구를 사용하여 클러스터를 모니터링합니다. Azure Cosmos DB를 사용하면 Azure 플랫폼에 기본 제공되는 모니터링 메커니즘을 사용할 수 있습니다. Azure Cosmos DB 모니터링에 대한 자세한 내용은 Azure Cosmos DB 모니터링을 참조하세요.
환경에서 이메일과 같은 방식으로 경고를 보내는 HBase 시스템 모니터링을 구현하는 경우 Azure Monitor 경고로 바꿀 수 있습니다. Azure Cosmos DB 계정에 대한 메트릭 또는 활동 로그 이벤트에 기반한 경고를 받을 수 있습니다.
Azure Monitor의 경고에 대한 자세한 내용은 Azure Monitor를 사용하여 Azure Cosmos DB에 대한 경고 만들기를 참조하세요.
또한 Azure Monitor에서 수집할 수 있는 Azure Cosmos DB 메트릭 및 로그 형식을 참조하세요.
백업 및 재해 복구
Backup
HBase의 백업을 얻을 수 있는 여러 가지 방법이 있습니다. 예를 들어 스냅샷, 내보내기, CopyTable, HDFS 데이터의 오프라인 백업 및 기타 사용자 지정 백업이 있습니다.
Azure Cosmos DB는 데이터베이스 작업의 성능이나 가용성에 영향을 주지 않는 주기적 간격으로 데이터를 자동으로 백업합니다. 백업은 Azure 스토리지에 저장되며, 필요한 경우 데이터를 복구하는 데 사용할 수 있습니다. Azure Cosmos DB 백업에는 두 가지 유형이 있습니다.
재해 복구
HBase는 내결함성 있는 분산 시스템이지만 데이터 센터 수준 오류 시 백업 위치에서 장애 조치(failover)가 필요한 경우 스냅샷, 복제 등을 사용하여 재해 복구를 구현해야 합니다. HBase 복제는 리더-팔로워, 리더-리더 및 순환의 세 가지 복제 모델로 설정할 수 있습니다. 원본 HBase에서 재해 복구를 구현하는 경우 Azure Cosmos DB에서 재해 복구를 구성하고 시스템 요구 사항을 충족하는 방법을 이해해야 합니다.
Azure Cosmos DB는 기본 제공 재해 복구 기능이 있는 전역적으로 분산된 데이터베이스입니다. DB 데이터를 Azure 지역에 복제할 수 있습니다. 일부 지역에서 오류가 발생하면 Azure Cosmos DB에서 데이터베이스를 고가용성으로 유지할 수 있습니다.
지역 오류가 발생하는 경우 단일 지역을 사용하는 Azure Cosmos DB 계정에서 가용성이 손실될 수 있습니다. 항상 고가용성을 보장하기 위해 둘 이상의 지역을 구성하는 것이 좋습니다. 또한 쓰기 및 읽기에 대한 고가용성을 보장하기 위해 여러 쓰기 지역이 있는 둘 이상의 지역으로 확장하도록 Azure Cosmos DB 계정을 구성할 수 있습니다. 여러 쓰기 지역으로 구성된 다중 지역 계정의 경우 Azure Cosmos DB 클라이언트에서 지역 간 장애 조치(failover)를 검색하고 처리합니다. 이는 순간적이며 애플리케이션에서 변경할 필요가 없습니다. Azure Cosmos DB에 대한 재해 복구가 포함된 가용성 구성은 이 방식으로 달성할 수 있습니다. 앞에서 설명한 대로 HBase 복제는 세 가지 모델로 설정할 수 있지만, Azure Cosmos DB는 단일 쓰기 및 다중 쓰기 지역을 구성하여 SLA 기반 가용성으로 설정할 수 있습니다.
고가용성에 대한 자세한 내용은 Azure Cosmos DB에서 고가용성을 제공하는 방법을 참조하세요.
자주 묻는 질문
Azure Cosmos DB에서 다른 API 대신 NoSQL용 API로 마이그레이션하는 이유는 무엇인가요?
NoSQL용 API는 인터페이스, 서비스 SDK 클라이언트 라이브러리 측면에서 최상의 엔드투엔드 환경을 제공합니다. Azure Cosmos DB로 롤아웃된 새 기능은 NoSQL용 API 계정에서 처음 사용할 수 있습니다. 또한 NoSQL용 API는 분석을 지원하고, 프로덕션 및 분석 워크로드 간에 성능 분리를 제공합니다. 최신 기술을 사용하여 앱을 빌드하려면 NoSQL용 API를 사용하는 것이 좋습니다.
HBase RowKey를 Azure Cosmos DB 파티션 키에 할당할 수 있나요?
있는 그대로 최적화되지 않을 수 있습니다. HBase에서 데이터는 지정된 RowKey로 정렬되고, Region(지역)에 저장되며, 고정 크기로 구분됩니다. 이는 Azure Cosmos DB의 분할과 다르게 작동합니다. 따라서 워크로드의 특성에 따라 데이터를 더 효율적으로 분산하기 위해 키를 다시 설계해야 합니다. 자세한 내용은 배포 섹션을 참조하세요.
HBase에서는 데이터가 RowKey에 따라 정렬되지만, Azure Cosmos DB에서는 키에 따라 분할됩니다. Azure Cosmos DB에서 정렬 및 배치를 달성하려면 어떻게 해야 하나요?
Azure Cosmos DB에서는 복합 인덱스를 추가하여 데이터를 오름차순 또는 내림차순으로 정렬함으로써 같음 및 범위 쿼리의 성능을 향상시킬 수 있습니다. 배포 섹션 및 제품 설명서의 복합 인덱스를 참조하세요.
분석 처리는 Hive 또는 Spark를 사용하여 HBase 데이터에서 실행됩니다. Azure Cosmos DB에서 현대화하려면 어떻게 해야 하나요?
Azure Cosmos DB 분석 저장소를 사용하여 운영 데이터를 다른 열 저장소에 자동으로 동기화할 수 있습니다. 열 저장소 형식은 최적화된 방식으로 실행되는 대규모 분석 쿼리에 적합하므로 이러한 쿼리의 대기 시간이 향상됩니다. Azure Synapse Link를 사용하면 Azure Synapse Analytics에서 Azure Cosmos DB 분석 저장소로 직접 연결하여 ETL이 없는 HTAP 솔루션을 구축할 수 있습니다. 이렇게 하면 운영 데이터에 대한 거의 실시간 대규모 분석을 수행 할 수 있습니다. Synapse Analytics는 Azure Cosmos DB 분석 저장소에서 Apache Spark 및 서버리스 SQL 풀을 지원합니다. 이 기능을 활용하여 분석 처리를 마이그레이션 할 수 있습니다. 자세한 내용은 분석 저장소를 참조하세요.
사용자가 HBase에서 Azure Cosmos DB에 대해 타임스탬프 쿼리를 사용하려면 어떻게 해야 하나요?
Azure Cosmos DB에는 HBase와 동일한 타임스탬프 버전 관리 기능이 없을 수도 있습니다. 그러나 Azure Cosmos DB는 변경 피드에 액세스하는 기능을 제공하고 이를 버전 관리에 활용할 수 있습니다.
모든 버전/변경 내용을 별도의 항목으로 저장합니다.
변경 피드를 읽어 변경 내용을 병합/통합하고 "_ts" 필드를 통해 필터링하여 적절한 작업을 다운스트림으로 트리거합니다. 또한 이전 버전의 데이터의 경우 TTL을 사용하여 이전 버전을 만료시킬 수 있습니다.
다음 단계
성능 테스트를 수행하려면 Azure Cosmos DB를 사용하여 성능 및 확장성 테스트 문서를 참조하세요.
코드를 최적화하려면 Azure Cosmos DB 성능 팁 문서를 참조하세요.
Java Async V3 SDK, SDK 참조 GitHub 리포지토리를 살펴보세요.