Grafana는 데이터를 쿼리 및 시각화한 다음 시각화에 따라 대시보드를 만들고 공유할 수 있는 분석 플랫폼입니다. Grafana는 Azure Data Explorer 플러그 인을 제공하여 Azure Data Explorer에서 데이터에 연결하고 시각화할 수 있습니다. 플러그 인은 Azure Managed Grafana와 자체 호스팅 Grafana 모두에서 작동합니다.
이 문서에서는 Grafana에 대한 데이터 원본으로 클러스터를 구성하고 Azure Managed Grafana 및 자체 호스팅 Grafana용 Grafana 에서 데이터를 시각화하는 방법에 대해 알아봅니다. 이 문서의 예제를 따르려면 StormEvents 샘플 데이터를 수집합니다. StormEvents 샘플 데이터 세트에는 국립 환경 정보 센터의 날씨 관련 데이터가 포함되어 있습니다.
필수 조건
- Azure Managed Grafana의 경우 Azure 계정 및 Azure Managed Grafana 인스턴스입니다.
- 자체 호스팅 Grafana의 경우 운영 체제용 Grafana 버전 5.3.0 이상 및 Grafana용 Azure Data Explorer 플러그 인 입니다. Grafana 쿼리 작성기를 사용하려면 플러그 인 버전 3.0.5 이상이 필요합니다.
- Azure Data Explorer 클러스터 및 데이터베이스. 무료 클러스터를 만들거나 전체 클러스터를 만들 수 있습니다. 가장 적합한 항목을 결정하려면 기능 비교를 확인합니다.
데이터 원본 구성
Azure Data Explorer를 데이터 원본으로 구성하려면 Grafana 환경에 대한 단계를 수행합니다.
뷰어 역할에 관리 ID 추가
관리되는 Grafana는 기본적으로 각 새 작업 영역에 대해 시스템 할당 관리 ID를 만듭니다. 이를 사용하여 Azure Data Explorer 클러스터에 액세스할 수 있습니다.
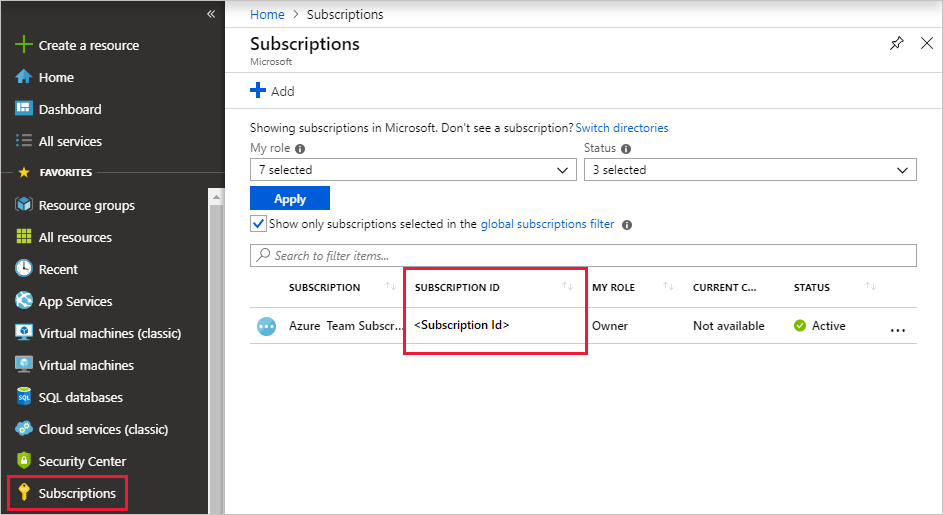
Azure Portal에서 Azure Data Explorer 클러스터로 이동합니다.
개요 섹션에서 StormEvents 샘플 데이터가 있는 데이터베이스를 선택합니다.
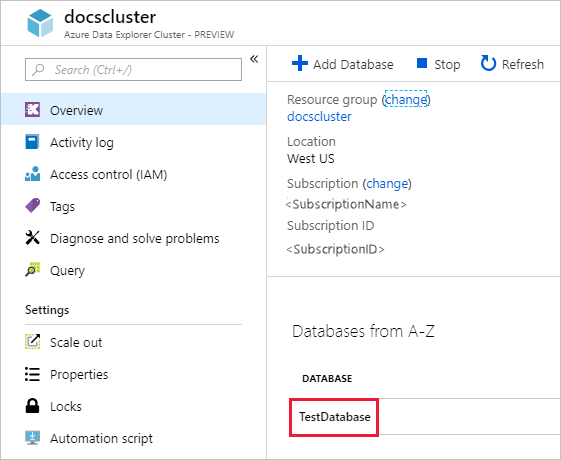
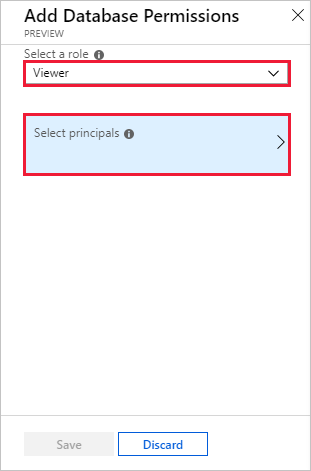
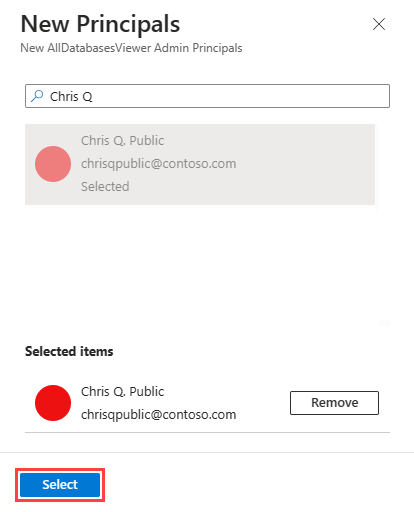
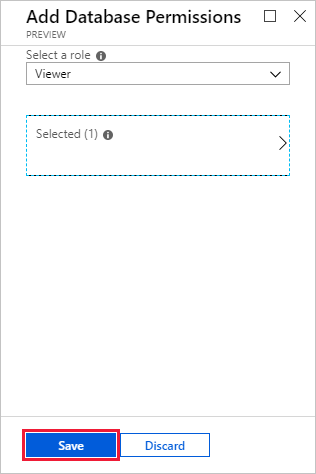
권한 뷰어 추가>를>선택합니다.
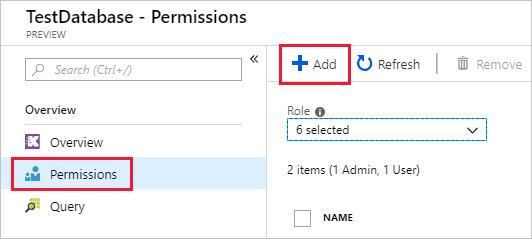
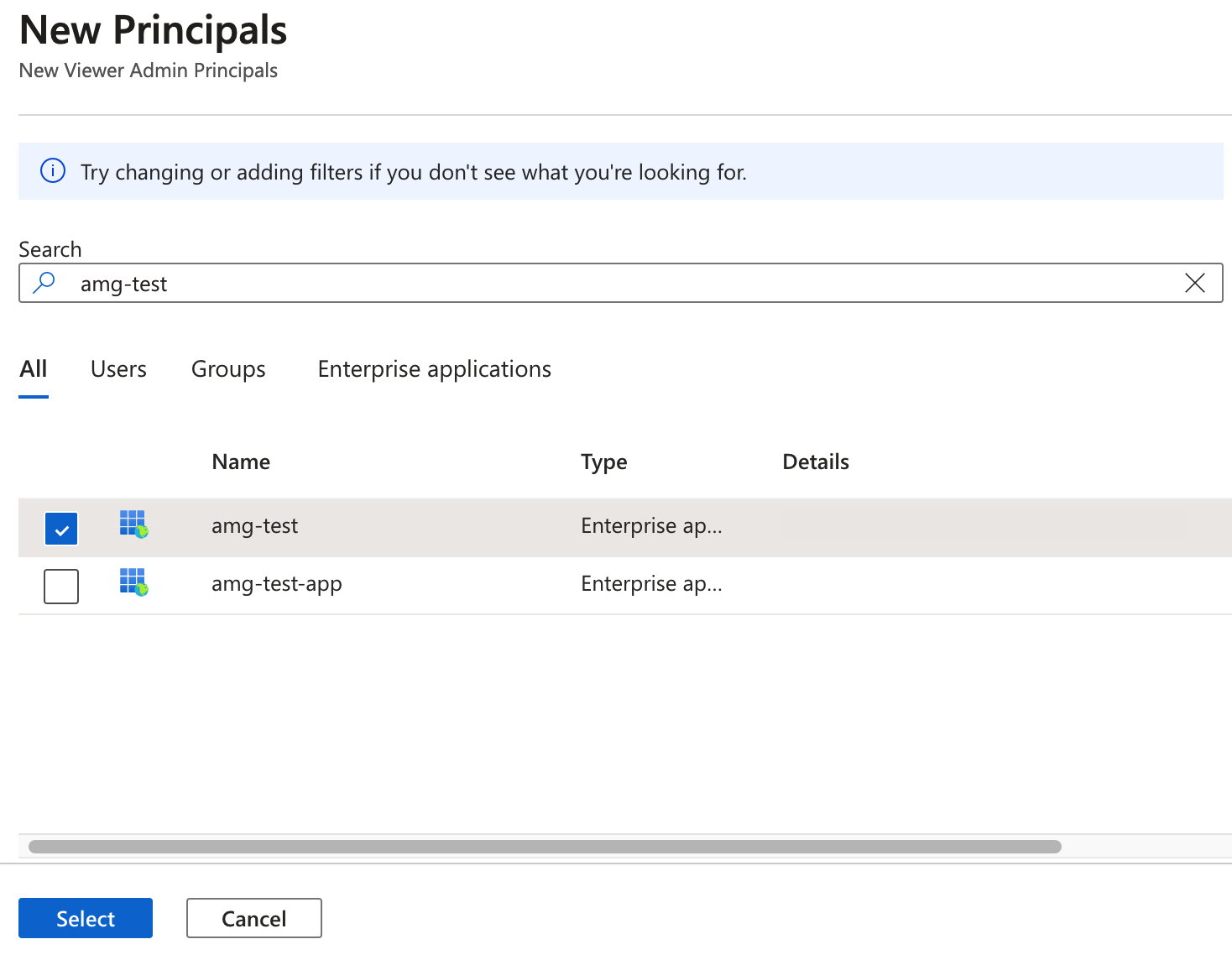
검색 상자에 관리되는 Grafana 작업 영역 이름을 입력합니다.
검색 결과에서 작업 영역 이름과 일치하는 결과를 선택한 다음 선택을 선택합니다.
Azure Data Explorer를 Grafana 데이터 원본으로 설정
관리되는 Grafana 작업 영역에는 Azure Data Explorer 플러그 인이 미리 설치되어 있습니다.
Azure Portal에서 관리되는 Grafana 작업 영역으로 이동합니다.
개요에서 엔드포인트 링크를 선택하여 Grafana UI를 엽니다.
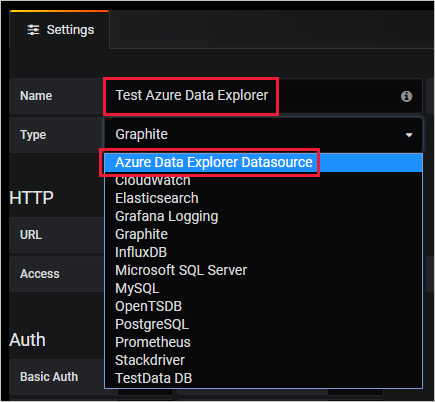
Grafana의 왼쪽 메뉴에서 기어 아이콘을 선택합니다. 그런 다음, 데이터 원본을 선택합니다.
Azure Data Explorer 데이터 원본을 선택합니다.
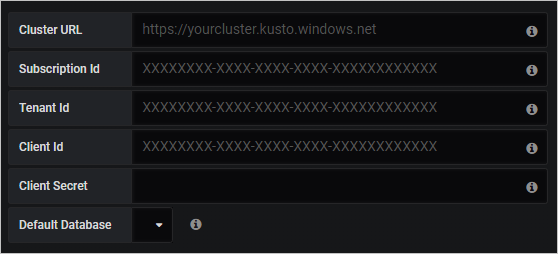
연결 세부 정보에 Azure Data Explorer 클러스터 URL을 입력합니다.
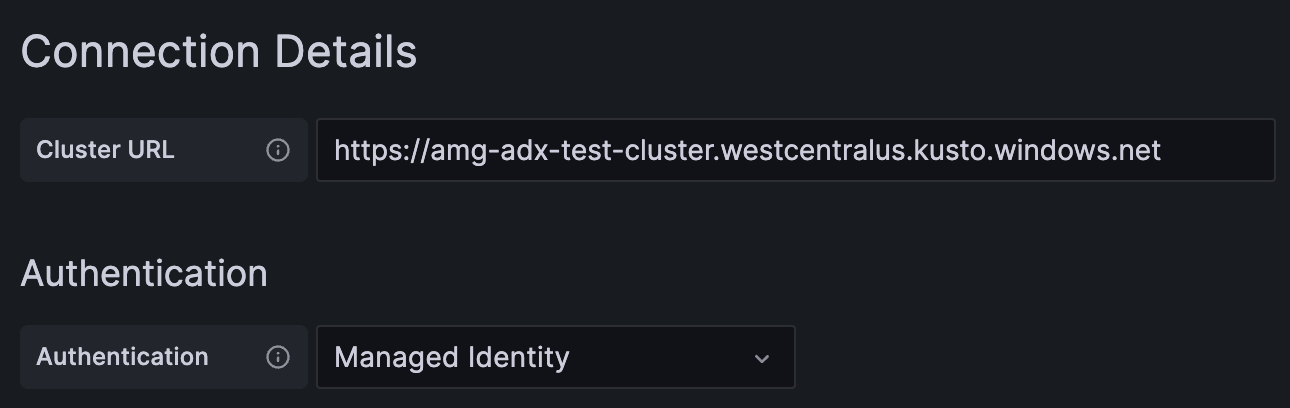
저장 및 테스트를 선택합니다.



데이터 시각화
Azure Data Explorer를 Grafana의 데이터 원본으로 구성했습니다. 이제 데이터를 시각화할 차례입니다.
다음 기본 예제에서는 쿼리 작성기 모드와 쿼리 편집기의 원시 모드를 모두 사용합니다. 데이터 세트에 대해 실행할 다른 쿼리의 예는 Azure Data Explorer에 대한 쓰기 쿼리를 보는 것이 좋습니다.
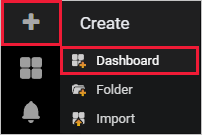
Grafana의 왼쪽 메뉴에서 더하기 아이콘을 선택합니다. 그런 다음 대시보드를 선택합니다.
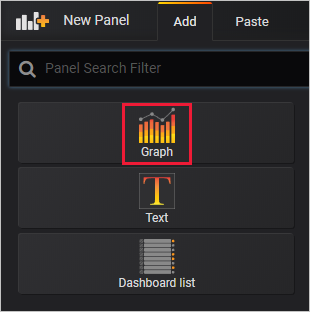
추가 탭에서 그래프를 선택합니다.
그래프 창에서 패널 제목>편집을 선택합니다.
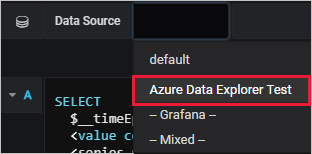
창 아래쪽에서 데이터 원본을 선택한 다음, 구성한 데이터 원본을 선택합니다.
쿼리 작성기 모드
쿼리 작성기 모드를 사용하여 쿼리를 정의합니다.
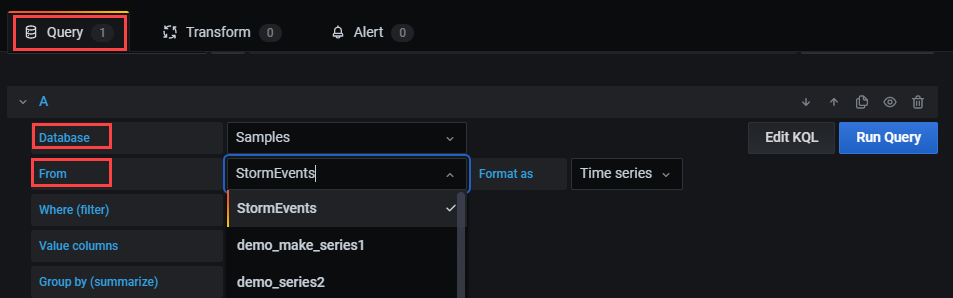
데이터 원본 아래에서 데이터베이스를 선택하고 드롭다운 목록에서 데이터베이스를 선택합니다.
드롭다운 목록에서 [선택]을 선택하고 테이블을 선택합니다.
이제 테이블이 정의되었으므로 데이터를 필터링합니다.
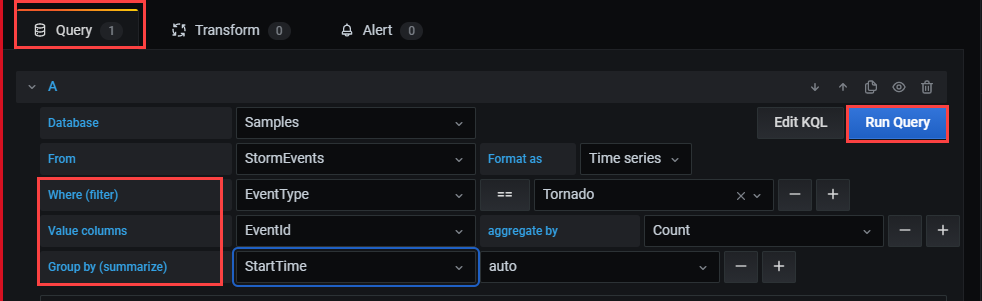
- 테이블에서 하나 이상의 열을 선택하려면 위치(필터)의 오른쪽을 선택합니다+.
- 각 필터에 대해 해당 연산자를 사용하여 값을 정의합니다. 이 선택은 Kusto 쿼리 언어 where 연산자를 사용하는 것과 비슷합니다.
테이블에 표시할 값을 선택합니다.
값 열의 오른쪽에서 선택하여 + 창에 표시할 값 열을 선택합니다.
각 값 열에 대해 집계 형식을 설정합니다.
하나 이상의 값 열을 설정할 수 있습니다. 이 선택은 summarize 연산자를 사용하는 것과 같습니다.
그룹화 기준(요약)의 오른쪽에서 선택하여 + 값을 그룹으로 정렬하는 데 사용할 하나 이상의 열을 선택합니다. 이 선택은 연산자의 그룹 식과
summarize동일합니다.쿼리 실행을 선택합니다.
팁
쿼리 작성기에서 설정을 마무리하는 동안 Kusto 쿼리 언어 쿼리가 만들어집니다. 이 쿼리는 그래픽 쿼리 편집기를 사용하여 생성한 논리를 보여줍니다.
KQL 편집을 선택하여 원시 모드로 이동합니다. Kusto 쿼리 언어 유연성과 기능을 사용하여 쿼리를 편집합니다.
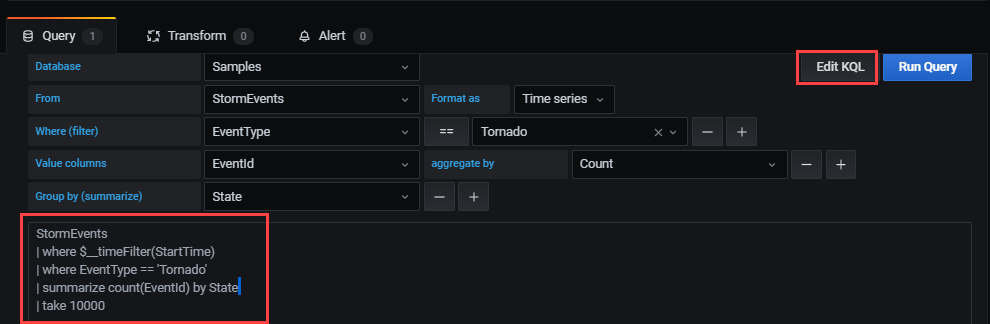
원시 모드
원시 모드를 사용하여 쿼리를 편집합니다.
쿼리 창에서 다음 쿼리를 붙여넣은 다음 실행을 선택합니다. 쿼리는 샘플 데이터 세트에 대한 일별 이벤트 수를 버킷합니다.
StormEvents | summarize event_count=count() by bin(StartTime, 1d)
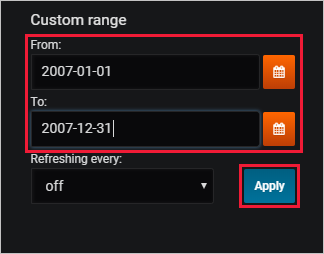
그래프는 지난 6시간 동안의 데이터로 범위가 지정되기 때문에(기본적으로) 결과를 표시하지 않습니다. 상단 메뉴에서 지난 6시간을 선택합니다.

StormEvents 샘플 데이터 세트에 포함된 연도인 2007을 포함하는 사용자 지정 범위를 지정합니다. 그런 다음 적용을 선택합니다.
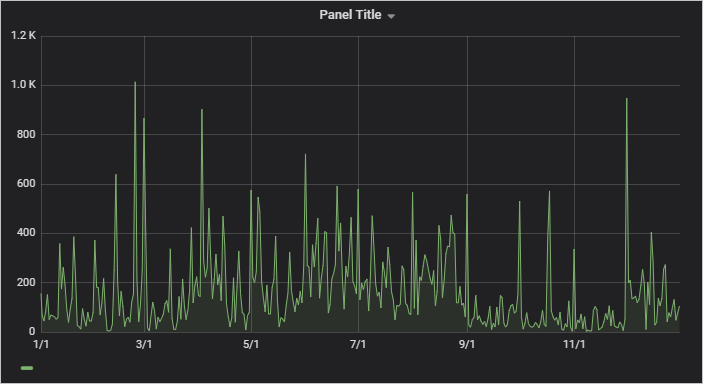
이제 그래프에서는 일별로 버킷된 2007년의 데이터를 보여줍니다.
위쪽 메뉴에서 저장 아이콘
 을 선택합니다.
을 선택합니다.
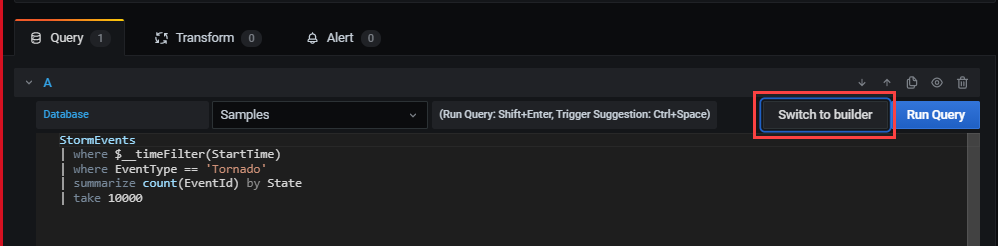
쿼리 작성기 모드로 전환하려면 작성기로 전환을 선택합니다. Grafana는 쿼리 작성기에서 쿼리를 사용 가능한 논리로 변환합니다. 쿼리 작성기 논리가 제한되어 있으므로 쿼리에 대한 수동 변경 내용이 손실될 수 있습니다.
경고 만들기
홈 대시보드에서 경고>알림 채널을 선택하여 새 알림 채널을 만듭니다.
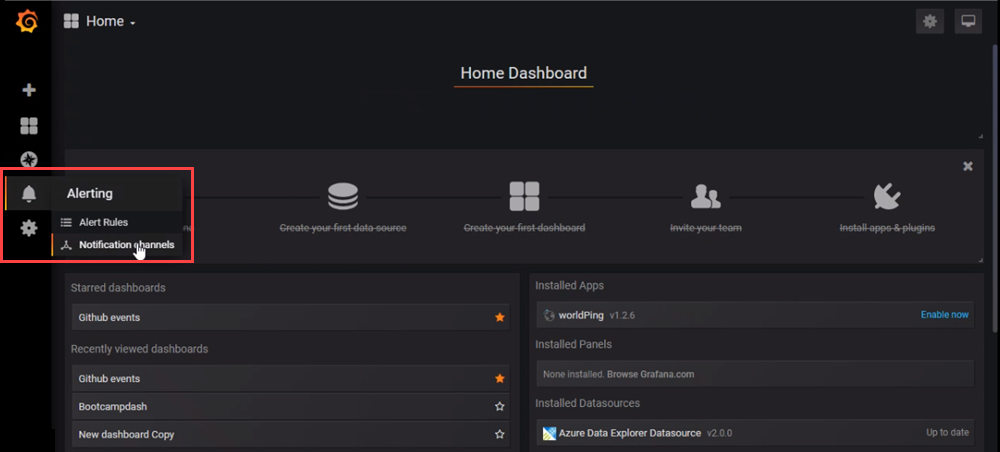
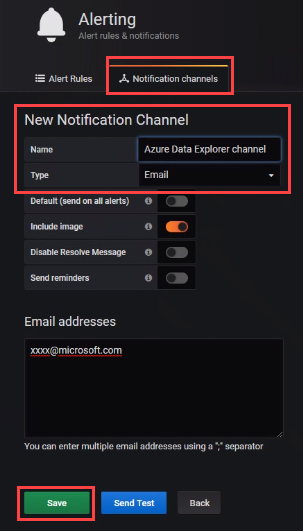
새 알림 채널 아래에 이름을 입력하고 입력한 다음 저장을 선택합니다.
대시보드의 드롭다운 목록에서 편집을 선택합니다.
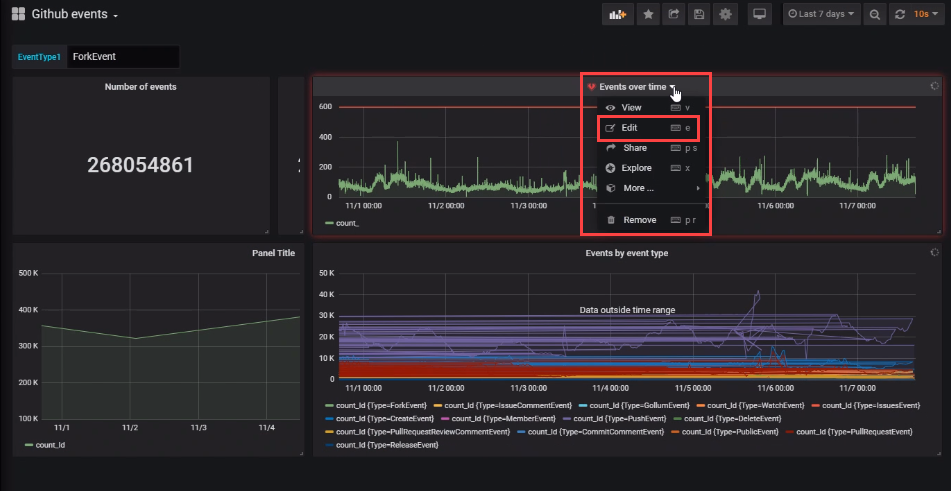
경고 벨 아이콘을 선택하여 경고 창을 엽니다. 경고 만들기를 선택한 다음 경고에 대한 속성을 완료합니다.
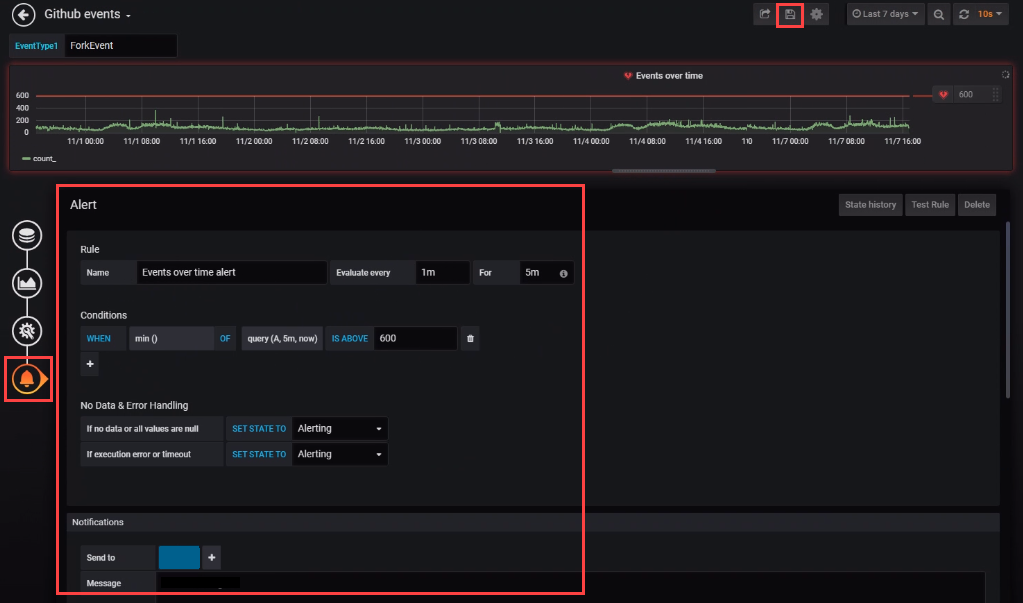
대시보드 저장 아이콘을 선택하여 변경 내용을 저장합니다.