series_mv_ee_anomalies_fl()
이 함수 series_mv_ee_anomalies_fl() 는 scikit-learn에서 타원 봉투 모델을 적용하여 계열의 다변량 변칙을 감지하는 UDF(사용자 정의 함수)입니다. 이 모델은 다변량 데이터의 원본이 다차원 정규 분포라고 가정합니다. 함수는 계열 집합을 숫자 동적 배열, 기능 열의 이름 및 전체 계열에서 예상되는 변칙 백분율로 허용합니다. 함수는 각 계열에 대해 다차원 타원형 봉투를 작성하고 이 일반 봉투 외부에 있는 점을 변칙으로 표시합니다.
사전 요구 사항
- 클러스터에서 Python 플러그 인 을 사용하도록 설정해야 합니다. 함수에 사용되는 인라인 Python에 필요합니다.
- 데이터베이스에서 Python 플러그 인 을 사용하도록 설정해야 합니다. 함수에 사용되는 인라인 Python에 필요합니다.
Syntax
T | invoke series_mv_ee_anomalies_fl(, features_colsanomaly_col [,score_col [,anomalies_pct ]])
구문 규칙에 대해 자세히 알아보세요.
매개 변수
| 이름 | 형식 | 필수 | Description |
|---|---|---|---|
| features_cols | dynamic |
✔️ | 다변량 변칙 검색 모델에 사용되는 열의 이름을 포함하는 배열입니다. |
| anomaly_col | string |
✔️ | 검색된 변칙을 저장할 열의 이름입니다. |
| score_col | string |
변칙의 점수를 저장할 열의 이름입니다. | |
| anomalies_pct | real |
데이터에서 예상되는 변칙 비율을 지정하는 [0-50] 범위의 실수입니다. 기본값: 4%. |
함수 정의
다음과 같이 해당 코드를 쿼리 정의 함수로 포함하거나 데이터베이스에 저장된 함수로 만들어 함수를 정의할 수 있습니다.
다음 let 문을 사용하여 함수를 정의합니다. 사용 권한이 필요 없습니다.
중요
let 문은 자체적으로 실행할 수 없습니다. 그 뒤에 테이블 형식 식 문이 있어야 합니다. 의 series_mv_ee_anomalies_fl()작업 예제를 실행하려면 예제를 참조 하세요.
// Define function
let series_mv_ee_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.covariance import EllipticEnvelope
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
ellipsoid = EllipticEnvelope(contamination=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
ellipsoid.fit(dffe)
df.loc[i, anomaly_col] = (ellipsoid.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = ellipsoid.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Write your query to use the function here.
예제
다음 예제에서는 invoke 연산자를 사용하여 함수를 실행합니다.
쿼리 정의 함수를 사용하려면 포함된 함수 정의 다음에 호출합니다.
// Define function
let series_mv_ee_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.covariance import EllipticEnvelope
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
ellipsoid = EllipticEnvelope(contamination=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
ellipsoid.fit(dffe)
df.loc[i, anomaly_col] = (ellipsoid.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = ellipsoid.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Usage
normal_2d_with_anomalies
| extend anomalies=dynamic(null), scores=dynamic(null)
| invoke series_mv_ee_anomalies_fl(pack_array('x', 'y'), 'anomalies', 'scores')
| extend anomalies=series_multiply(80, anomalies)
| render timechart
출력
테이블 normal_2d_with_anomalies 3개의 시계열 집합이 포함되어 있습니다. 각 시계열에는 자정, 오전 8시 및 오후 4시에 매일 변칙이 추가된 2차원 정규 분포가 있습니다. 예제 쿼리를 사용하여 이 샘플 데이터 세트를 만들 수 있습니다.
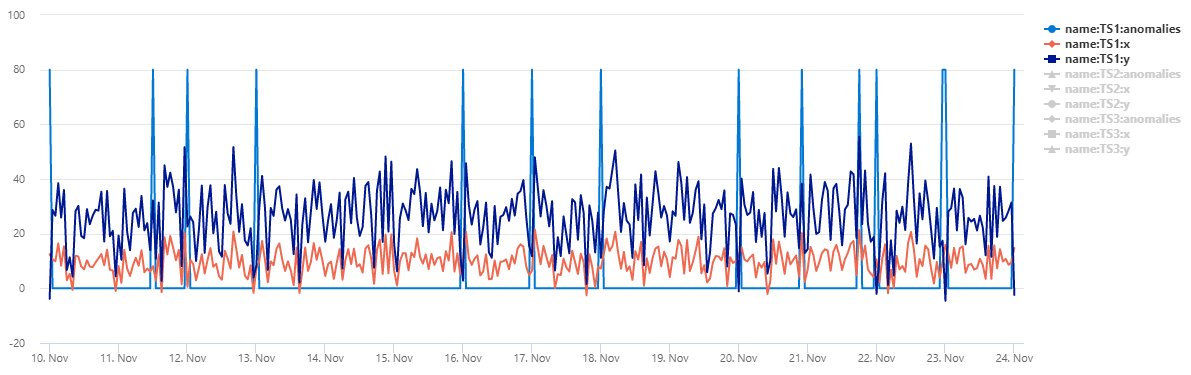
데이터를 분산형 차트로 보려면 사용 코드를 다음으로 바꿉니다.
normal_2d_with_anomalies
| extend anomalies=dynamic(null)
| invoke series_mv_ee_anomalies_fl(pack_array('x', 'y'), 'anomalies')
| where name == 'TS1'
| project x, y, anomalies
| mv-expand x to typeof(real), y to typeof(real), anomalies to typeof(string)
| render scatterchart with(series=anomalies)
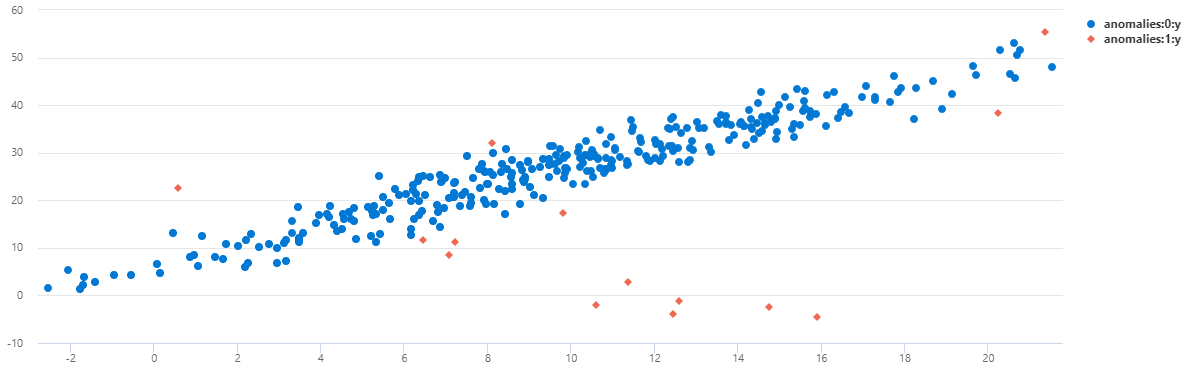
TS1에서 이 다변량 모델을 사용하여 대부분의 자정 변칙이 검색되었음을 알 수 있습니다.
샘플 데이터 세트 만들기
.set normal_2d_with_anomalies <|
//
let window=14d;
let dt=1h;
let n=toint(window/dt);
let rand_normal_fl=(avg:real=0.0, stdv:real=1.0)
{
let x =rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand();
(x - 6)*stdv + avg
};
union
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(10, 5)
| extend y=iff(hourofday(t) == 0, 2*(10-x)+7+rand_normal_fl(0, 3), 2*x+7+rand_normal_fl(0, 3)) // anomalies every midnight
| extend name='TS1'),
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(15, 3)
| extend y=iff(hourofday(t) == 8, (15-x)+10+rand_normal_fl(0, 2), x-7+rand_normal_fl(0, 1)) // anomalies every 8am
| extend name='TS2'),
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(8, 6)
| extend y=iff(hourofday(t) == 16, x+5+rand_normal_fl(0, 4), (12-x)+rand_normal_fl(0, 4)) // anomalies every 4pm
| extend name='TS3')
| summarize t=make_list(t), x=make_list(x), y=make_list(y) by name
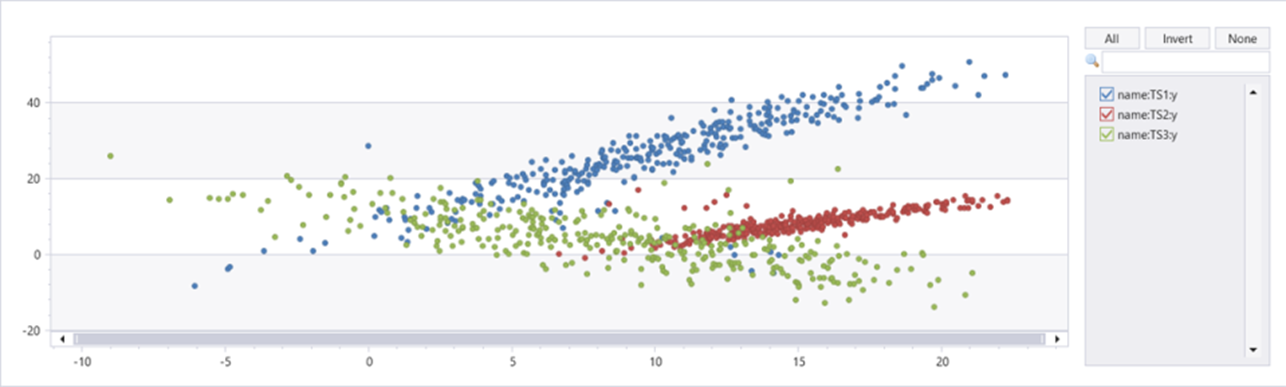
이 기능은 지원되지 않습니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기