적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric0>데이터 팩터리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure Data Factory. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric
데이터 흐름은 Azure Data Factory 파이프라인과 Azure Synapse Analytics 파이프라인 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 접하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
정렬 변환을 사용하면 현재 데이터 스트림의 들어오는 행을 정렬할 수 있습니다. 개별 열을 선택하고 오름차순이나 내림차순으로 정렬할 수 있습니다.
참고 항목
데이터 흐름 매핑은 여러 노드 및 파티션에 데이터를 분산하는 Spark 클러스터에서 실행됩니다. 후속 변환에서 데이터를 다시 분할하는 경우 데이터가 다시 섞여 정렬이 흐트러질 수 있습니다. 데이터 흐름에서 정렬 순서를 유지하는 가장 좋은 방법은 변환의 최적화 탭에서 단일 파티션을 설정하고 가능한 한 싱크에 가깝게 정렬 변환을 유지하는 것입니다.
구성
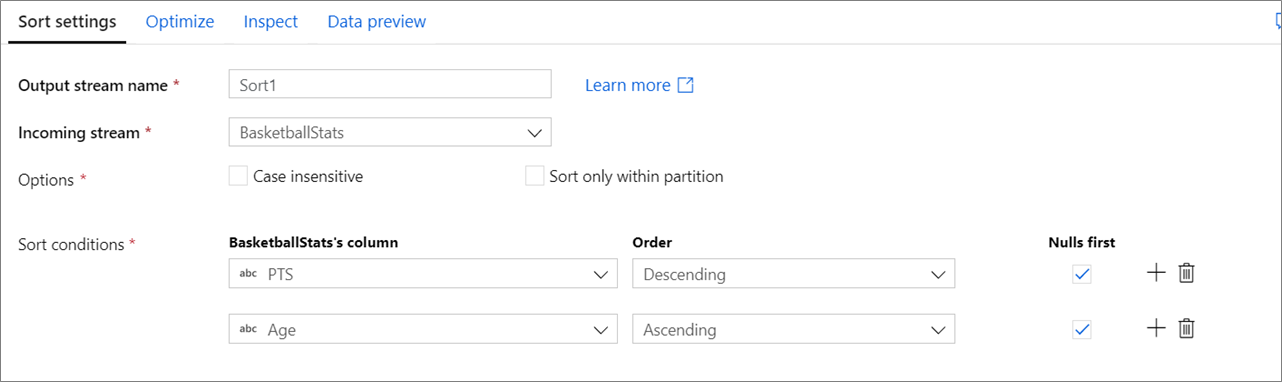
대/소문자 구분: 문자열 또는 텍스트 필드를 정렬할 때 대/소문자를 구분할지 여부
파티션 내에서만 정렬: 데이터 흐름이 Spark에서 실행될 때 각 데이터 스트림은 파티션으로 나누어집니다. 해당 설정은 전체 데이터 스트림을 정렬하지 않고 들어오는 파티션 내에서만 데이터를 정렬합니다.
정렬 조건: 정렬할 열과 해당 정렬을 진행할 순서를 선택합니다. 순서는 정렬 우선 순위를 결정합니다. 데이터 스트림의 시작 부분 또는 끝 부분에 Null을 표시할지 여부를 선택합니다.
계산 열
정렬을 적용하기 전에 열 값을 수정하거나 추출하려면 열 위로 마우스를 이동하고 “계산 열”을 선택합니다. 그러면 식 작성기가 열 값을 사용하는 대신 정렬 작업에 대한 식을 만듭니다.
데이터 흐름 스크립트
구문
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
예시
위의 정렬 구성에 대한 데이터 흐름 스크립트는 아래 코드 조각에 나와 있습니다.
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
관련 콘텐츠
정렬 후 집계 변환을 사용하는 것이 좋습니다.