시스템 테이블을 사용하여 작업 비용 모니터링
Important
이 기능은 공개 미리 보기 상태입니다. 카탈로그에 표시 system 하려면 스키마를 사용하도록 설정해야 합니다. 자세한 내용은 시스템 테이블 스키마 사용을 참조 하세요.
이 문서에서는 시스템 테이블을 사용하여 계정의 작업 비용을 모니터링하는 방법에 대한 예제를 제공합니다.
이러한 쿼리는 작업 컴퓨팅 및 서버리스 컴퓨팅에서 실행되는 작업에 대한 비용만 계산합니다. SQL 웨어하우스에서 실행되는 작업 및 다목적 컴퓨팅은 작업으로 청구되지 않으므로 비용 특성에서 제외됩니다.
참고 항목
이러한 쿼리는 현재 작업 영역의 클라우드 지역 외부에 있는 작업 영역에서 레코드를 반환하지 않습니다. 현재 지역 외부의 작업 영역에서 작업 비용을 모니터링하려면 해당 지역에 배포된 작업 영역에서 이러한 쿼리를 실행합니다.
비용 관찰 대시보드
작업 비용 모니터링을 시작하려면 Github에서 다음 비용 관찰 대시보드를 다운로드합니다. 작업 비용 및 상태 관찰 대시보드를 참조하세요.
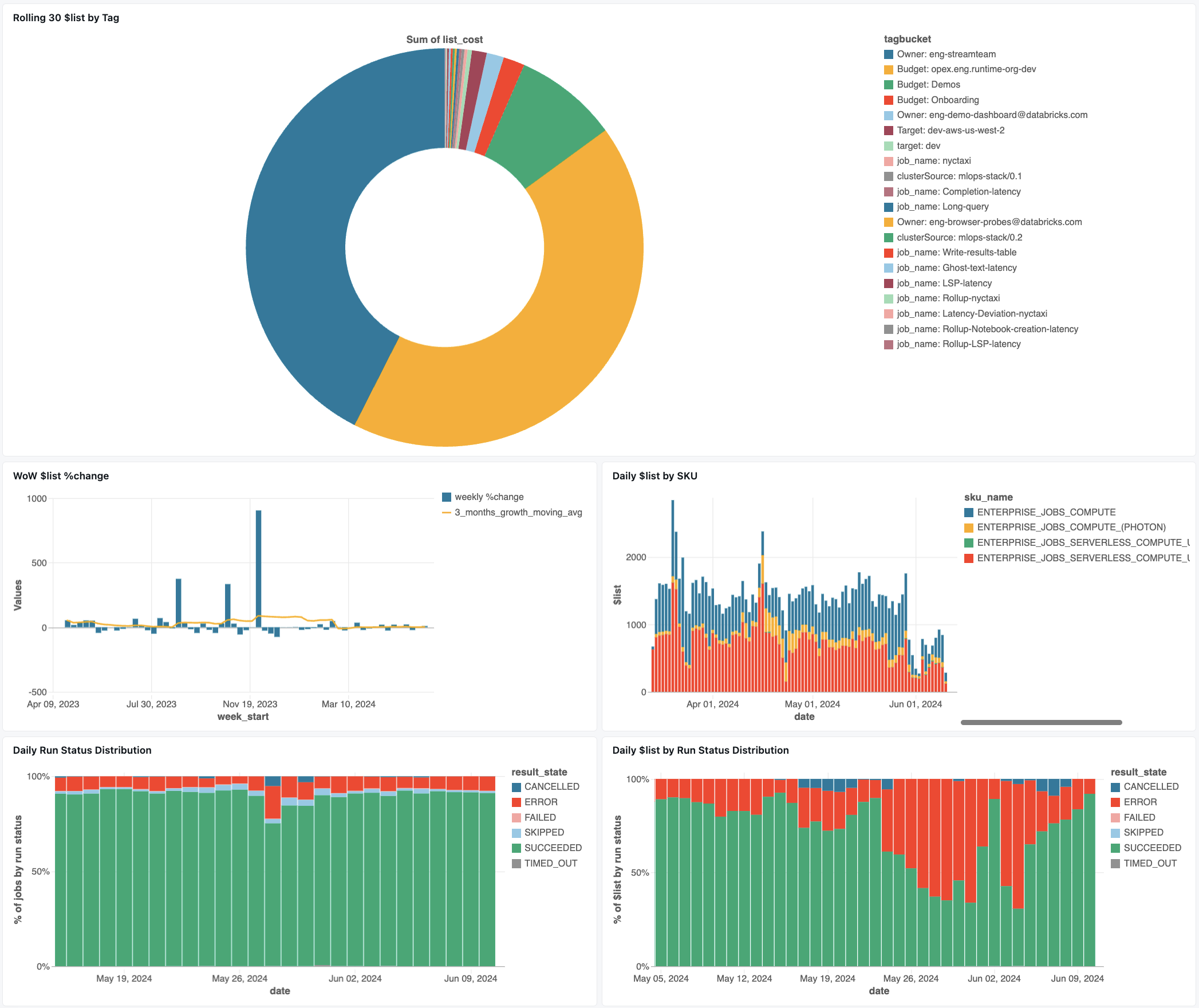
JSON 파일을 다운로드한 후 대시보드를 작업 영역으로 가져옵니다. 대시보드 가져오기에 대한 지침은 대시보드 파일 가져오기를 참조하세요.
지난 7~14일 동안 지출이 가장 높은 일자리
이 쿼리는 지난 2주 동안 목록 비용 지출이 가장 많이 증가한 작업을 식별합니다.
with job_run_timeline_with_cost as (
SELECT
t1.*,
t1.usage_metadata.job_id as job_id,
t1.identity_metadata.run_as as run_as,
t1.usage_quantity * list_prices.pricing.default AS list_cost
FROM system.billing.usage t1
INNER JOIN system.billing.list_prices list_prices
ON
t1.cloud = list_prices.cloud AND
t1.sku_name = list_prices.sku_name AND
t1.usage_start_time >= list_prices.price_start_time AND
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is NULL)
WHERE
t1.sku_name LIKE '%JOBS%' AND
t1.usage_metadata.job_id IS NOT NULL AND
t1.usage_metadata.job_run_id IS NOT NULL AND
t1.usage_date >= CURRENT_DATE() - INTERVAL 14 DAY
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
t2.name
,t1.workspace_id
,t1.job_id
,t1.sku_name
,t1.run_as
,Last7DaySpend
,Last14DaySpend
,last7DaySpend - last14DaySpend as Last7DayGrowth
,try_divide( (last7DaySpend - last14DaySpend) , last14DaySpend) * 100 AS Last7DayGrowthPct
FROM
(
SELECT
workspace_id,
job_id,
run_as,
sku_name,
SUM(list_cost) AS spend
,SUM(CASE WHEN usage_end_time BETWEEN date_add(current_date(), -8) AND date_add(current_date(), -1) THEN list_cost ELSE 0 END) AS Last7DaySpend
,SUM(CASE WHEN usage_end_time BETWEEN date_add(current_date(), -15) AND date_add(current_date(), -8) THEN list_cost ELSE 0 END) AS Last14DaySpend
FROM job_run_timeline_with_cost
GROUP BY ALL
) t1
LEFT JOIN most_recent_jobs t2 USING (workspace_id, job_id)
ORDER BY
Last7DayGrowth DESC
LIMIT 100
지난 30일 동안 가장 비싼 일자리
이 쿼리는 지난 30일 동안 지출이 가장 많은 작업을 식별합니다.
with list_cost_per_job as (
SELECT
t1.workspace_id,
t1.usage_metadata.job_id,
COUNT(DISTINCT t1.usage_metadata.job_run_id) as runs,
SUM(t1.usage_quantity * list_prices.pricing.default) as list_cost,
first(identity_metadata.run_as, true) as run_as,
first(t1.custom_tags, true) as custom_tags,
MAX(t1.usage_end_time) as last_seen_date
FROM system.billing.usage t1
INNER JOIN system.billing.list_prices list_prices on
t1.cloud = list_prices.cloud and
t1.sku_name = list_prices.sku_name and
t1.usage_start_time >= list_prices.price_start_time and
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is null)
WHERE
t1.sku_name LIKE '%JOBS%'
AND t1.usage_metadata.job_id IS NOT NULL
AND t1.usage_date >= CURRENT_DATE() - INTERVAL 30 DAY
GROUP BY ALL
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
t2.name,
t1.job_id,
t1.workspace_id,
t1.runs,
t1.run_as,
SUM(list_cost) as list_cost,
t1.last_seen_date
FROM list_cost_per_job t1
LEFT JOIN most_recent_jobs t2 USING (workspace_id, job_id)
GROUP BY ALL
ORDER BY list_cost DESC
가장 비싼 작업은 지난 30일 동안 실행됩니다.
이 쿼리는 지난 30일 동안 지출이 가장 많은 작업 실행을 식별합니다.
with list_cost_per_job_run as (
SELECT
t1.workspace_id,
t1.usage_metadata.job_id,
t1.usage_metadata.job_run_id as run_id,
SUM(t1.usage_quantity * list_prices.pricing.default) as list_cost,
first(identity_metadata.run_as, true) as run_as,
first(t1.custom_tags, true) as custom_tags,
MAX(t1.usage_end_time) as last_seen_date
FROM system.billing.usage t1
INNER JOIN system.billing.list_prices list_prices on
t1.cloud = list_prices.cloud and
t1.sku_name = list_prices.sku_name and
t1.usage_start_time >= list_prices.price_start_time and
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is null)
WHERE
t1.sku_name LIKE '%JOBS%'
AND t1.usage_metadata.job_id IS NOT NULL
AND t1.usage_metadata.job_run_id IS NOT NULL
AND t1.usage_date >= CURRENT_DATE() - INTERVAL 30 DAY
GROUP BY ALL
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
t1.workspace_id,
t2.name,
t1.job_id,
t1.run_id,
t1.run_as,
SUM(list_cost) as list_cost,
t1.last_seen_date
FROM list_cost_per_job_run t1
LEFT JOIN most_recent_jobs t2 USING (workspace_id, job_id)
GROUP BY ALL
ORDER BY list_cost DESC
빈번하고 비용이 많이 드는 오류가 있는 작업
이 쿼리는 지난 30일 동안 실패한 실행 수가 많은 작업에 대한 정보를 반환합니다. 실행 수, 실패 횟수, 성공 비율 및 작업 실패 실행의 목록 비용을 볼 수 있습니다.
with job_run_timeline_with_cost as (
SELECT
t1.*,
t1.identity_metadata.run_as as run_as,
t2.job_id,
t2.run_id,
t2.result_state,
t1.usage_quantity * list_prices.pricing.default as list_cost
FROM system.billing.usage t1
INNER JOIN system.lakeflow.job_run_timeline t2
ON
t1.workspace_id=t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
INNER JOIN system.billing.list_prices list_prices on
t1.cloud = list_prices.cloud and
t1.sku_name = list_prices.sku_name and
t1.usage_start_time >= list_prices.price_start_time and
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is null)
WHERE
t1.sku_name LIKE '%JOBS%' AND
t1.usage_date >= CURRENT_DATE() - INTERVAL 30 DAYS
),
cumulative_run_status_cost as (
SELECT
workspace_id,
job_id,
run_id,
run_as,
result_state,
usage_end_time,
SUM(list_cost) OVER (ORDER BY workspace_id, job_id, run_id, usage_end_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_cost
FROM job_run_timeline_with_cost
ORDER BY workspace_id, job_id, run_id, usage_end_time
),
cost_per_status as (
SELECT
workspace_id,
job_id,
run_id,
run_as,
result_state,
usage_end_time,
cumulative_cost - COALESCE(LAG(cumulative_cost) OVER (ORDER BY workspace_id, job_id, run_id, usage_end_time), 0) AS result_state_cost
FROM cumulative_run_status_cost
WHERE result_state IS NOT NULL
ORDER BY workspace_id, job_id, run_id, usage_end_time),
cost_per_status_agg as (
SELECT
workspace_id,
job_id,
FIRST(run_as, TRUE) as run_as,
SUM(result_state_cost) as list_cost
FROM cost_per_status
WHERE
result_state IN ('ERROR', 'FAILED', 'TIMED_OUT')
GROUP BY ALL
),
terminal_statues as (
SELECT
workspace_id,
job_id,
CASE WHEN result_state IN ('ERROR', 'FAILED', 'TIMED_OUT') THEN 1 ELSE 0 END as is_failure,
period_end_time as last_seen_date
FROM system.lakeflow.job_run_timeline
WHERE
result_state IS NOT NULL AND
period_end_time >= CURRENT_DATE() - INTERVAL 30 DAYS
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
first(t2.name) as name,
t1.workspace_id,
t1.job_id,
COUNT(*) as runs,
t3.run_as,
SUM(is_failure) as failures,
(1 - COALESCE(try_divide(SUM(is_failure), COUNT(*)), 0)) * 100 as success_ratio,
first(t3.list_cost) as failure_list_cost,
MAX(t1.last_seen_date) as last_seen_date
FROM terminal_statues t1
LEFT JOIN most_recent_jobs t2 USING (workspace_id, job_id)
LEFT JOIN cost_per_status_agg t3 USING (workspace_id, job_id)
GROUP BY ALL
ORDER BY failures DESC
재시도 횟수가 가장 많은 작업
이 쿼리는 수리 횟수, 복구 실행 비용 및 복구 실행의 누적 기간을 포함하여 지난 30일 동안 자주 복구된 작업에 대한 정보를 반환합니다.
with job_run_timeline_with_cost as (
SELECT
t1.*,
t2.job_id,
t2.run_id,
t1.identity_metadata.run_as as run_as,
t2.result_state,
t1.usage_quantity * list_prices.pricing.default as list_cost
FROM system.billing.usage t1
INNER JOIN system.lakeflow.job_run_timeline t2
ON
t1.workspace_id=t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
INNER JOIN system.billing.list_prices list_prices on
t1.cloud = list_prices.cloud and
t1.sku_name = list_prices.sku_name and
t1.usage_start_time >= list_prices.price_start_time and
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is null)
WHERE
t1.sku_name LIKE '%JOBS%' AND
t1.usage_date >= CURRENT_DATE() - INTERVAL 30 DAYS
),
cumulative_run_status_cost as (
SELECT
workspace_id,
job_id,
run_id,
run_as,
result_state,
usage_end_time,
SUM(list_cost) OVER (ORDER BY workspace_id, job_id, run_id, usage_end_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_cost
FROM job_run_timeline_with_cost
ORDER BY workspace_id, job_id, run_id, usage_end_time
),
cost_per_status as (
SELECT
workspace_id,
job_id,
run_id,
run_as,
result_state,
usage_end_time,
cumulative_cost - COALESCE(LAG(cumulative_cost) OVER (ORDER BY workspace_id, job_id, run_id, usage_end_time), 0) AS result_state_cost
FROM cumulative_run_status_cost
WHERE result_state IS NOT NULL
ORDER BY workspace_id, job_id, run_id, usage_end_time),
cost_per_unsuccesful_status_agg as (
SELECT
workspace_id,
job_id,
run_id,
first(run_as, TRUE) as run_as,
SUM(result_state_cost) as list_cost
FROM cost_per_status
WHERE
result_state != "SUCCEEDED"
GROUP BY ALL
),
repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) as cnt
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING cnt > 1
),
successful_repairs as (
SELECT t1.workspace_id, t1.job_id, t1.run_id, MAX(t1.period_end_time) as period_end_time
FROM system.lakeflow.job_run_timeline t1
JOIN repaired_runs t2
ON t1.workspace_id=t2.workspace_id AND t1.job_id=t2.job_id AND t1.run_id=t2.run_id
WHERE t1.result_state="SUCCEEDED"
GROUP BY ALL
),
combined_repairs as (
SELECT
t1.*,
t2.period_end_time,
t1.cnt as repairs
FROM repaired_runs t1
LEFT JOIN successful_repairs t2 USING (workspace_id, job_id, run_id)
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
last(t3.name) as name,
t1.workspace_id,
t1.job_id,
t1.run_id,
first(t4.run_as, TRUE) as run_as,
first(t1.repairs) - 1 as repairs,
first(t4.list_cost) as repair_list_cost,
CASE WHEN t1.period_end_time IS NOT NULL THEN CAST(t1.period_end_time - MIN(t2.period_end_time) as LONG) ELSE NULL END AS repair_time_seconds
FROM combined_repairs t1
JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
LEFT JOIN most_recent_jobs t3 USING (workspace_id, job_id)
LEFT JOIN cost_per_unsuccesful_status_agg t4 USING (workspace_id, job_id, run_id)
WHERE
t2.result_state IS NOT NULL
GROUP BY t1.workspace_id, t1.job_id, t1.run_id, t1.period_end_time
ORDER BY repairs DESC