중요합니다
이 기능은 베타 버전으로 제공됩니다. 계정 관리자는 미리 보기 페이지에서 이 기능에 대한 액세스를 제어할 수 있습니다.
이 페이지에서는 사용량 추적 시스템 테이블을 사용하여 AI 게이트웨이(베타) 엔드포인트의 사용량을 모니터링하는 방법을 설명합니다.
사용 현황 추적 테이블은 엔드포인트에 대한 요청 및 응답 세부 정보를 자동으로 캡처하여 토큰 사용량 및 대기 시간과 같은 필수 메트릭을 로깅합니다. 이 테이블의 데이터를 사용하여 사용량을 모니터링하고, 비용을 추적하고, 엔드포인트 성능 및 소비에 대한 인사이트를 얻을 수 있습니다.
요구 사항
- 계정에 대해 AI 게이트웨이(베타) 미리 보기가 사용하도록 설정되었습니다.
- AI 게이트웨이(베타) 지원 지역의 Azure Databricks 작업 영역.
- 작업 영역에서 Unity 카탈로그가 사용하도록 설정되었습니다. Unity 카탈로그에 대한 작업 영역 사용을 참조하세요.
사용 현황 테이블 쿼리
AI 게이트웨이는 사용량 현황 system.ai_gateway.usage 데이터를 시스템 테이블에 기록합니다. UI에서 테이블을 보거나 Databricks SQL 또는 Notebook에서 테이블을 쿼리할 수 있습니다.
비고
계정 관리자만 테이블을 보거나 쿼리할 수 있는 권한이 있습니다 system.ai_gateway.usage .
UI에서 테이블을 보려면 엔드포인트 페이지에서 사용량 추적 테이블 링크를 클릭하여 카탈로그 탐색기에서 테이블을 엽니다.
Databricks SQL 또는 Notebook에서 테이블을 쿼리하려면 다음을 수행합니다.
SELECT * FROM system.ai_gateway.usage;
기본 제공 사용 대시보드
기본 제공 사용 대시보드 가져오기
계정 관리자는 AI 게이트웨이 페이지에서 대시보드 만들기 를 클릭하여 기본 제공 AI 게이트웨이 사용량 대시보드를 가져와 사용량을 모니터링하고, 비용을 추적하고, 엔드포인트 성능 및 소비에 대한 인사이트를 얻을 수 있습니다. 대시보드는 계정 관리자의 권한으로 게시되므로 뷰어는 게시자의 사용 권한을 사용하여 쿼리를 실행할 수 있습니다. 자세한 내용은 대시보드 게시 를 참조하세요. 계정 관리자는 모든 후속 쿼리에 적용되는 대시보드 쿼리를 실행하는 데 사용되는 웨어하우스를 업데이트할 수도 있습니다.

비고
대시보드 가져오기는 테이블에 대한 system.ai_gateway.usage 권한이 SELECT 필요로 하기 때문에 계정 관리자에게만 제한됩니다. 대시보드의 데이터는 usage 테이블의 보존 정책을 준수합니다.
어떤 시스템 테이블을 사용할 수 있는지 확인하세요..
최신 템플릿에서 대시보드를 다시 로드하려면 계정 관리자가 AI 게이트웨이 페이지에서 대시보드 다시 가져오기 를 클릭할 수 있습니다. 이렇게 하면 웨어하우스 구성을 유지하면서 템플릿의 새로운 시각화 또는 향상된 기능으로 대시보드를 업데이트합니다.
사용량 대시보드 보기
대시보드를 보려면 AI 게이트웨이 페이지에서 대시보드 보기를 클릭합니다. 기본 제공 대시보드는 AI Gateway 엔드포인트 사용량 및 성능에 대한 포괄적인 가시성을 제공합니다. 여기에는 여러 페이지 추적 요청, 토큰 사용량, 대기 시간 메트릭, 오류 비율 및 코딩 에이전트 작업이 포함됩니다.

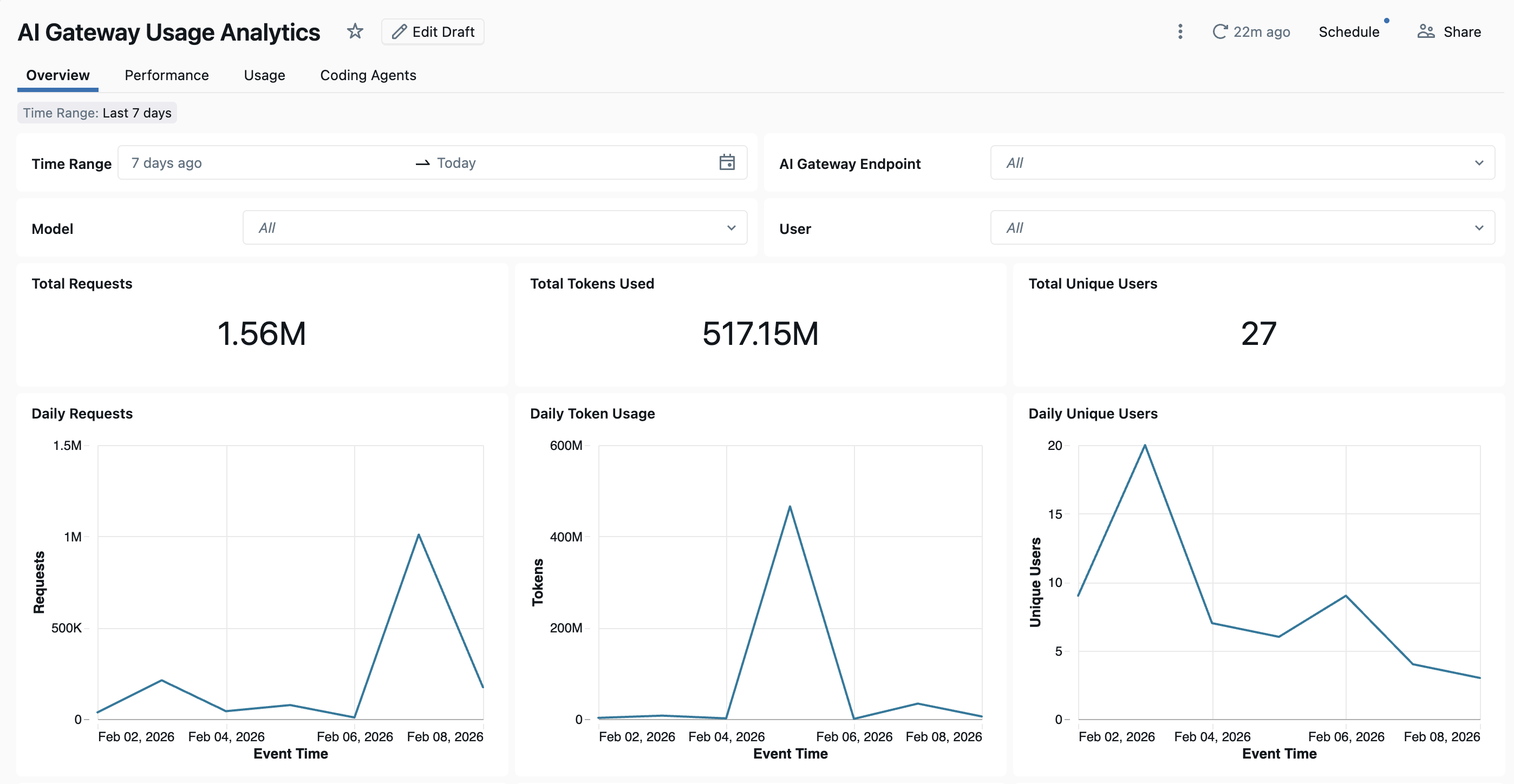
대시보드는 기본적으로 작업 영역 간 분석을 제공합니다. 모든 대시보드 페이지는 날짜 범위 및 작업 영역 ID를 기준으로 필터링할 수 있습니다.
- 개요 탭: 일일 요청 볼륨, 시간에 따른 토큰 사용량 추세, 토큰 사용량별 상위 사용자 수 및 총 고유 사용자 수를 포함한 상위 수준 사용 메트릭을 표시합니다. 이 탭을 사용하여 전체 AI 게이트웨이 활동의 빠른 스냅샷을 가져오고 가장 활동적인 사용자 및 모델을 식별할 수 있습니다.
- 성능 탭: 대기 시간 백분위수(P50, P90, P95, P99), 시간-첫 번째 바이트, 오류 비율 및 HTTP 상태 코드 배포를 포함한 주요 성능 메트릭을 추적합니다. 이 탭을 사용하여 엔드포인트 상태를 모니터링하고 성능 병목 상태 또는 안정성 문제를 식별합니다.
- 사용 탭: 엔드포인트, 작업 영역 및 요청자별 자세한 사용량 분석을 표시합니다. 이 탭에서는 비용을 분석하고 최적화하는 데 도움이 되는 토큰 사용 패턴, 요청 배포 및 캐시 적중 비율을 보여 줍니다.
- 코딩 에이전트 탭: 커서, 클로드 코드, Gemini CLI 및 Codex CLI를 비롯한 통합 코딩 에이전트의 활동을 추적합니다. 이 탭은 개발자 도구 사용을 모니터링하기 위해 추가되거나 제거된 코드 줄, 코딩 세션, 커밋 및 활성 날짜와 같은 메트릭을 보여 줍니다. 자세한 내용은 코딩 에이전트 대시보드 를 참조하세요.
사용량 테이블 스키마
테이블에 system.ai_gateway.usage 는 다음 스키마가 있습니다.
| 열 이름 | 유형 | Description | 예시 |
|---|---|---|---|
account_id |
STRING | 계정 ID입니다. | 11d77e21-5e05-4196-af72-423257f74974 |
workspace_id |
STRING | 작업 영역 ID입니다. | 1653573648247579 |
request_id |
STRING | 요청의 고유 식별자 | b4a47a30-0e18-4ae3-9a7f-29bcb07e0f00 |
schema_version |
정수 | 사용 레코드의 스키마 버전입니다. | 1 |
endpoint_id |
STRING | AI 게이트웨이 엔드포인트의 고유 ID입니다. | 43addf89-d802-3ca2-bd54-fe4d2a60d58a |
endpoint_name |
STRING | AI 게이트웨이 엔드포인트의 이름입니다. | databricks-gpt-5-2 |
endpoint_tags |
MAP | 엔드포인트와 연결된 태그입니다. | {"team": "engineering"} |
endpoint_metadata |
구조 | 엔드포인트 메타데이터에는 creator, creation_time, last_updated_time, destinations, inference_table, 및 fallbacks 등이 포함됩니다. |
{"creator": "user.name@email.com", "creation_time": "2026-01-06T12:00:00.000Z", ...} |
event_time |
TIMESTAMP | 요청을 받은 타임스탬프입니다. | 2026-01-20T19:48:08.000+00:00 |
latency_ms |
LONG | 총 대기 시간(밀리초)입니다. | 300 |
time_to_first_byte_ms |
LONG | 첫 번째 바이트 시간(밀리초)입니다. | 300 |
destination_type |
STRING | 대상 유형(예: 외부 모델 또는 기본 모델)입니다. | PAY_PER_TOKEN_FOUNDATION_MODEL |
destination_name |
STRING | 대상 모델 또는 공급자의 이름입니다. | databricks-gpt-5-2 |
destination_id |
STRING | 대상의 고유 ID입니다. | 507e7456151b3cc89e05ff48161efb87 |
destination_model |
STRING | 요청에 사용되는 특정 모델입니다. | GPT-5.2 |
requester |
STRING | 요청을 수행한 사용자 또는 서비스 주체의 ID입니다. | user.name@email.com |
requester_type |
STRING | 요청자 유형(사용자, 서비스 주체 또는 사용자 그룹)입니다. | USER |
ip_address |
STRING | 요청자의 IP 주소입니다. | 1.2.3.4 |
url |
STRING | 요청의 URL입니다. | https://<ai-gateway-url>/mlflow/v1/chat/completions |
user_agent |
STRING | 요청자의 사용자 에이전트입니다. | OpenAI/Python 2.13.0 |
api_type |
STRING | API 호출 유형(예: 채팅, 완료 또는 포함)입니다. | mlflow/v1/chat/completions |
request_tags |
MAP | 요청과 연결된 태그입니다. | {"team": "engineering"} |
input_tokens |
LONG | 입력 토큰의 수입니다. | 100 |
output_tokens |
LONG | 출력 토큰의 수입니다. | 100 |
total_tokens |
LONG | 총 토큰 수(입력 + 출력)입니다. | 200 |
token_details |
구조 | 자세한 토큰 분석에는 cache_read_input_tokens, cache_creation_input_tokens, 및 output_reasoning_tokens가 포함됩니다. |
{"cache_read_input_tokens": 100, ...} |
response_content_type |
STRING | 응답의 콘텐츠 형식입니다. | application/json |
status_code |
INT | 응답의 HTTP 상태 코드입니다. | 200 |
routing_information |
구조 |
폴백 시도에 대한 라우팅 세부 정보입니다.
attempts 배열에는 요청 중 시도된 각 모델에 대해 priority, action, destination, destination_id, status_code, error_code, latency_ms, start_time, 및 end_time가 포함됩니다. |
{"attempts": [{"priority": "1", ...}]} |