Databricks의 AI 및 Machine Learning
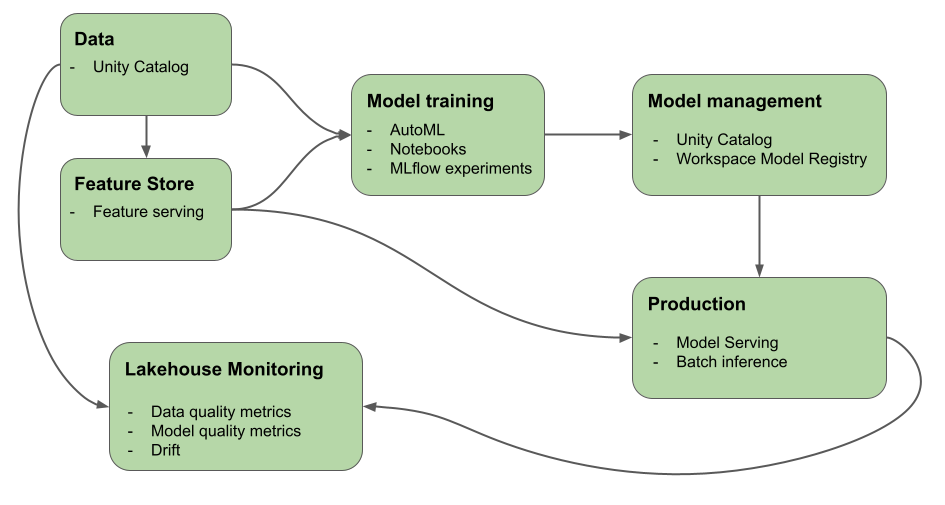
이 문서에서는 AI 및 ML 워크플로를 빌드하고 모니터링하는 데 도움이 되는 Azure Databricks가 제공하는 도구에 대해 설명합니다. 다이어그램은 이러한 구성 요소가 함께 작동하여 모델 개발 및 배포 프로세스를 구현하는 데 도움이 되는 방법을 보여 줍니다.
기계 학습 및 딥 러닝에 Databricks를 사용하는 이유는 무엇인가요?
Databricks를 사용하면 단일 플랫폼은 원시 데이터부터 제공된 모델에 대한 모든 요청 및 응답을 저장하는 유추 테이블에 이르기까지 모델 개발 및 배포 프로세스의 모든 단계를 제공합니다. 데이터 과학자, 데이터 엔지니어, ML 엔지니어 및 DevOps는 동일한 도구 집합과 데이터에 대한 단일 진실 소스를 사용하여 작업을 수행할 수 있습니다.
데이터 인텔리전스 플랫폼을 사용하면 ML 플랫폼과 데이터 스택이 동일한 시스템입니다. ML 플랫폼은 데이터 계층 위에 빌드됩니다. 모델 및 함수와 같은 모든 데이터 자산 및 아티팩트를 검색할 수 있으며 단일 카탈로그에서 관리됩니다. 데이터 및 모델에 단일 플랫폼을 사용하면 원시 데이터에서 프로덕션 모델로 계보를 추적할 수 있습니다. 기본 제공 데이터 및 모델 모니터링은 플랫폼에도 저장된 테이블에 품질 메트릭을 저장하여 모델 성능 문제의 근본 원인을 보다 쉽게 식별할 수 있도록 합니다. Databricks가 전체 ML 수명 주기 및 MLOps를 지원하는 방법에 대한 자세한 내용은 Azure Databricks 및 MLOps 스택의 MLOps 워크플로: 모델 개발 프로세스를 코드로 참조하세요.
데이터 인텔리전스 플랫폼의 주요 구성 요소 중 일부는 다음과 같습니다.
| 작업 | 구성 요소 |
|---|---|
| 데이터, 기능, 모델 및 함수를 제어하고 관리합니다. 또한 검색, 버전 관리 및 계보. | Unity 카탈로그 |
| 데이터, 데이터 품질 및 모델 예측 품질에 대한 변경 내용 추적 | Lakehouse 모니터링, 유추 테이블 |
| 기능 개발 및 관리 | 기능 엔지니어링 |
| 모델 학습 | Databricks AutoML, Databricks Notebook |
| 모델 개발 추적 | MLflow 추적 |
| 사용자 지정 모델 제공 | 모자이크 AI 모델 서비스. |
| LLM 배포 | 파운데이션 모델 API, 외부 모델 |
| 자동화된 워크플로 및 프로덕션 준비 ETL 파이프라인 빌드 | Databricks 작업 |
| Git 통합 | Databricks Git 폴더 |
Databricks에 대한 딥 러닝
딥 러닝 애플리케이션에 대한 인프라 구성은 어려울 수 있습니다.
Machine Learning 용 Databricks Runtime은 TensorFlow, PyTorch 및 Keras와 같은 가장 일반적인 딥 러닝 라이브러리의 호환되는 기본 제공 버전이 있는 클러스터와 Petastorm, Hyperopt 및 Horovod와 같은 지원 라이브러리를 사용하여 이를 처리합니다. Databricks 런타임 ML 클러스터에는 드라이버 및 지원 라이브러리를 사용하여 미리 구성된 GPU 지원도 포함됩니다. 또한 Ray와 같은 라이브러리를 지원하여 ML 워크플로 및 AI 애플리케이션의 크기를 조정하기 위한 컴퓨팅 처리를 병렬화합니다.
Databricks 런타임 ML 클러스터에는 드라이버 및 지원 라이브러리를 사용하여 미리 구성된 GPU 지원도 포함됩니다. Mosaic AI 모델 서비스를 사용하면 추가 구성 없이 딥 러닝 모델에 대해 확장 가능한 GPU 엔드포인트를 만들 수 있습니다.
기계 학습 애플리케이션의 경우 Databricks에서 Machine Learning을 위한 Databricks Runtime을 실행하는 클러스터를 사용하는 것을 권장합니다. Databricks 런타임 ML을 사용하여 클러스터 만들기를 참조하세요.
Databricks에서 딥 러닝을 시작하려면 다음을 참조하세요.
Databricks의 LLM(대규모 언어 모델) 및 생성 AI
Machine Learning용 Databricks 런타임에는 미리 학습된 기존 모델 또는 기타 오픈 소스 라이브러리를 워크플로에 통합할 수 있는 Hugging Face Transformers 및 LangChain과 같은 라이브러리가 포함되어 있습니다. Databricks MLflow 통합을 사용하면 변환기 파이프라인, 모델 및 처리 구성 요소와 함께 MLflow 추적 서비스를 쉽게 사용할 수 있습니다. 또한 Azure Databricks 워크플로에서 John Snow Labs와 같은 파트너의 OpenAI 모델 또는 솔루션을 통합할 수 있습니다.
Azure Databricks를 사용하면 특정 작업에 대한 데이터에 대한 LLM을 사용자 지정할 수 있습니다. Hugging Face 및 DeepSpeed와 같은 오픈 소스 도구를 지원하면 기본 LLM을 효율적으로 사용하고 고유한 데이터로 학습하여 특정 도메인 및 워크로드에 대한 정확도를 향상시킬 수 있습니다. 그런 다음, 생성 AI 애플리케이션에서 사용자 지정 LLM을 활용할 수 있습니다.
또한 Databricks는 서비스 엔드포인트에서 최신 오픈 모델에 액세스하고 쿼리할 수 있는 파운데이션 모델 API 및 외부 모델을 제공합니다. 개발자는 파운데이션 모델 API를 사용하여 자체 모델 배포를 유지 관리하지 않고도 고품질의 생성 AI 모델을 활용하는 애플리케이션을 빠르고 쉽게 빌드할 수 있습니다.
SQL 사용자의 경우 Databricks는 SQL 데이터 분석가가 데이터 파이프라인 및 워크플로 내에서 직접 OpenAI를 비롯한 LLM 모델에 액세스하는 데 사용할 수 있는 AI 함수를 제공합니다. Azure Databricks의 AI 함수를 참조 하세요.
Machine Learning용 Databricks Runtime
Machine Learning용 Databricks Runtime(Databricks Runtime ML)은 가장 일반적인 ML 및 DL 라이브러리를 포함하여 미리 빌드된 기계 학습 및 딥 러닝 인프라를 사용하여 클러스터를 만드는 것을 자동화합니다. Databricks Runtime ML의 각 버전에 있는 라이브러리의 전체 목록은 릴리스 정보를 참조하세요.
기계 학습 워크플로를 위해 Unity 카탈로그의 데이터에 액세스하려면 클러스터에 대한 액세스 모드가 단일 사용자(할당됨)여야 합니다. 공유 클러스터는 Machine Learning용 Databricks Runtime과 호환되지 않습니다. 또한 Databricks Runtime ML은 TableACLs 클러스터 또는 로 설정된 true클러스터 spark.databricks.pyspark.enableProcessIsolation config 에서 지원되지 않습니다.
Databricks Runtime ML을 사용하여 클러스터 만들기
클러스터를 만들 때 Databricks 런타임 버전 드롭다운 메뉴에서 Databricks 런타임 ML 버전을 선택합니다. CPU 및 GPU 지원 ML 런타임을 모두 사용할 수 있습니다.
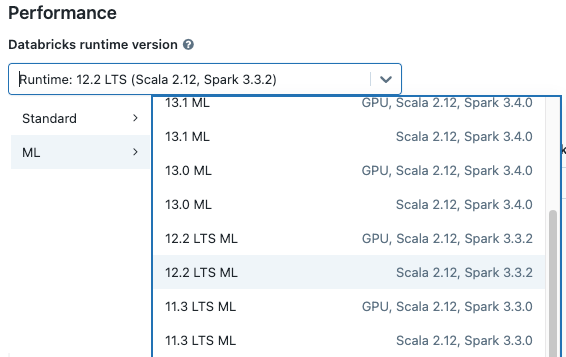
Notebook의 드롭다운 메뉴에서 클러스터를 선택하면 클러스터 이름 오른쪽에 Databricks 런타임 버전이 표시됩니다.
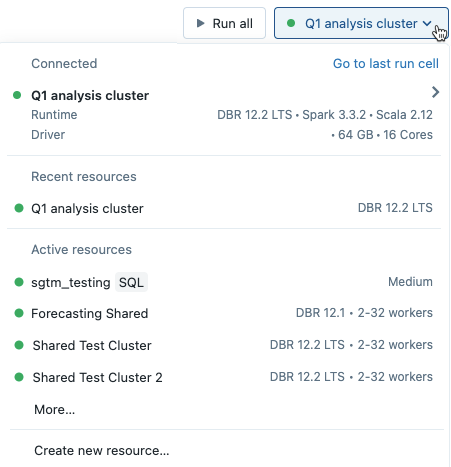
GPU 사용 ML 런타임을 선택하는 경우 호환되는 드라이버 유형 및 작업자 유형을 선택하라는 메시지가 표시됩니다. 호환되지 않는 인스턴스 유형은 드롭다운 메뉴에서 회색으로 표시됩니다. GPU 사용 인스턴스 유형은 GPU 가속 레이블 아래에 나열됩니다 .
참고 항목
기계 학습 워크플로를 위해 Unity 카탈로그의 데이터에 액세스하려면 클러스터에 대한 액세스 모드 가 단일 사용자(할당됨)여야 합니다. 공유 클러스터는 Machine Learning용 Databricks Runtime과 호환되지 않습니다. 클러스터를 만드는 방법에 대한 자세한 내용은 Compute 구성 참조를 참조하세요.
Photon 및 Databricks Runtime ML
Databricks Runtime 15.2 ML 이상을 실행하는 CPU 클러스터를 만들 때 Photon을 사용하도록 선택할 수 있습니다. Photon은 Spark SQL, Spark DataFrames, 기능 엔지니어링, GraphFrames 및 xgboost4j를 사용하여 애플리케이션의 성능을 향상시킵니다. Spark RDD, Pandas UDF 및 Python과 같은 비 JVM 언어를 사용하는 애플리케이션의 성능은 향상되지 않을 것으로 예상됩니다. 따라서 XGBoost, PyTorch 및 TensorFlow와 같은 Python 패키지는 Photon에서 향상된 기능을 볼 수 없습니다.
Spark RDD API 및 Spark MLlib 는 Photon과의 호환성이 제한됩니다. Spark RDD 또는 Spark MLlib를 사용하여 큰 데이터 세트를 처리할 때 Spark 메모리 문제가 발생할 수 있습니다. Spark 메모리 문제를 참조하세요.
Databricks Runtime ML에 포함된 라이브러리
Databricks 런타임 ML에는 널리 사용되는 다양한 ML 라이브러리가 포함되어 있습니다. 라이브러리는 새로운 기능과 수정 사항을 포함하도록 각 릴리스와 함께 업데이트됩니다.
Databricks는 지원되는 라이브러리의 하위 집합을 최상위 계층 라이브러리로 지정했습니다. 이러한 라이브러리의 경우 Databricks는 각 런타임 릴리스를 사용하여 최신 패키지 릴리스로 업데이트하는 빠른 업데이트 주기를 제공합니다(종속성 충돌 금지). 또한 Databricks는 최상위 계층 라이브러리에 대한 고급 지원, 테스트 및 포함된 최적화를 제공합니다.
최상위 계층 및 기타 제공된 라이브러리의 전체 목록은 Databricks Runtime ML에 대한 릴리스 정보를 참조하세요.
다음 단계
시작하려면 다음을 참조하십시오.
Databricks Machine Learning에 대한 권장 MLOps 워크플로는 다음을 참조하세요.
주요 Databricks Machine Learning 기능에 대해 알아보려면 다음을 참조하세요.