데이터 파일 크기를 제어하도록 Delta Lake 구성
참고 항목
이 문서의 권장 사항은 Unity 카탈로그 관리 테이블에 적용되지 않습니다. Databricks는 모든 새 델타 테이블에 대한 기본 설정과 함께 Unity 카탈로그 관리 테이블을 사용하는 것이 좋습니다.
Databricks Runtime 13.3 이상에서 Databricks는 델타 테이블 레이아웃에 클러스터링을 사용하는 것이 좋습니다. Delta 테이블에 Liquid 클러스터링 사용을 참조하세요.
Databricks는 예측 최적화를 사용하여 델타 테이블을 자동으로 실행하는 OPTIMIZE VACUUM 것이 좋습니다. Unity 카탈로그 관리 테이블에 대한 예측 최적화를 참조 하세요.
Databricks Runtime 10.4 LTS 이상에서는 자동 압축 및 최적화된 쓰기가 항상 , UPDATE및 DELETE 작업에 대해 MERGE사용하도록 설정됩니다. 이 기능을 사용하지 않도록 설정할 수 없습니다.
Delta Lake는 쓰기 및 OPTIMIZE 작업을 위한 대상 파일 크기를 수동 또는 자동으로 구성하는 옵션을 제공합니다. Azure Databricks는 이러한 많은 설정을 자동으로 조정하고 적절한 크기의 파일을 검색하여 테이블 성능을 자동으로 향상시키는 기능을 사용하도록 설정합니다.
Unity 카탈로그 관리 테이블의 경우 SQL 웨어하우스 또는 Databricks Runtime 11.3 LTS 이상을 사용하는 경우 Databricks는 이러한 구성의 대부분을 자동으로 조정합니다.
Databricks Runtime 10.4 LTS 이하에서 워크로드를 업그레이드하는 경우 백그라운드 자동 압축으로 업그레이드를 참조하세요.
실행 시기 OPTIMIZE
자동 압축 및 최적화된 쓰기는 각각 작은 파일 문제를 줄이지만 OPTIMIZE. 특히 1TB보다 큰 테이블의 경우 Databricks는 파일을 추가로 통합하기 위해 일정에 따라 실행하는 OPTIMIZE 것이 좋습니다. Azure Databricks는 테이블에서 자동으로 실행 ZORDER 되지 않으므로 향상된 데이터 건너뛰기를 사용하도록 설정하려면 실행 OPTIMIZE ZORDER 해야 합니다. Delta Lake에 대한 데이터 건너뛰기 참조
Azure Databricks에서 자동 최적화란?
자동 최적화라는 용어는 설정 delta.autoOptimize.autoCompact 에 의해 제어되는 기능을 설명하는 데 사용되는 경우가 있습니다delta.autoOptimize.optimizeWrite. 이 용어는 각 설정을 개별적으로 설명하기 위해 사용 중지되었습니다. Azure Databricks의 Delta Lake 자동 압축 및 Azure Databricks의 Delta Lake에 대한 최적화된 쓰기를 참조하세요.
Azure Databricks의 Delta Lake 자동 압축
자동 압축은 델타 테이블 파티션 내의 작은 파일을 결합하여 작은 파일 문제를 자동으로 줄입니다. 자동 압축은 테이블에 대한 쓰기가 성공한 후 발생하고 쓰기를 수행한 클러스터에서 동기적으로 실행됩니다. 자동 압축은 이전에 압축되지 않은 파일만 압축합니다.
Spark 구성spark.databricks.delta.autoCompact.maxFileSize을 설정하여 출력 파일 크기를 제어할 수 있습니다. Databricks는 워크로드 또는 테이블 크기에 따라 자동 조정을 사용하는 것이 좋습니다. 테이블 크기에 따라 워크로드 및 Autotune 파일 크기에 따라 Autotune 파일 크기를 참조하세요.
자동 압축은 적어도 특정 개수의 작은 파일이 있는 파티션 또는 테이블에 대해서만 트리거됩니다. 필요에 따라 설정 spark.databricks.delta.autoCompact.minNumFiles하여 자동 압축을 트리거하는 데 필요한 최소 파일 수를 변경할 수 있습니다.
다음 설정을 사용하여 테이블 또는 세션 수준에서 자동 압축을 사용하도록 설정할 수 있습니다.
- Table 속성:
delta.autoOptimize.autoCompact - SparkSession 설정:
spark.databricks.delta.autoCompact.enabled
이러한 설정은 다음 옵션을 허용합니다.
| 옵션 | 동작 |
|---|---|
auto (권장) |
다른 자동 조정 기능을 유지하면서 대상 파일 크기를 조정합니다. Databricks Runtime 10.4 LTS 이상이 필요합니다. |
legacy |
에 대한 별칭입니다 true. Databricks Runtime 10.4 LTS 이상이 필요합니다. |
true |
대상 파일 크기로 128MB를 사용합니다. 동적 크기 조정이 없습니다. |
false |
자동 압축을 해제합니다. 워크로드에서 수정된 모든 델타 테이블에 대한 자동 압축을 재정의하도록 세션 수준에서 설정할 수 있습니다. |
Important
Databricks Runtime 9.1 LTS에서 다른 작성자가 같은 DELETEMERGEUPDATE작업을 수행하거나 OPTIMIZE 동시에 수행할 때 자동 압축으로 인해 트랜잭션 충돌과 함께 다른 작업이 실패할 수 있습니다. Databricks Runtime 10.4 LTS 이상에서는 문제가 되지 않습니다.
Azure Databricks의 Delta Lake에 최적화된 쓰기
최적화된 쓰기는 데이터가 작성될 때 파일 크기를 개선하고 테이블의 후속 읽기에 도움이 됩니다.
최적화된 쓰기는 각 파티션에 기록되는 작은 파일의 수를 줄이기 때문에 분할된 테이블에 가장 효과적입니다. 적은 수의 큰 파일을 작성하는 것이 많은 작은 파일을 작성하는 것보다 더 효율적이지만, 데이터를 쓰기 전에 순서가 섞이기 때문에 쓰기 대기 시간이 증가할 수 있습니다.
다음 이미지는 최적화된 쓰기의 작동 방식을 보여 줍니다.
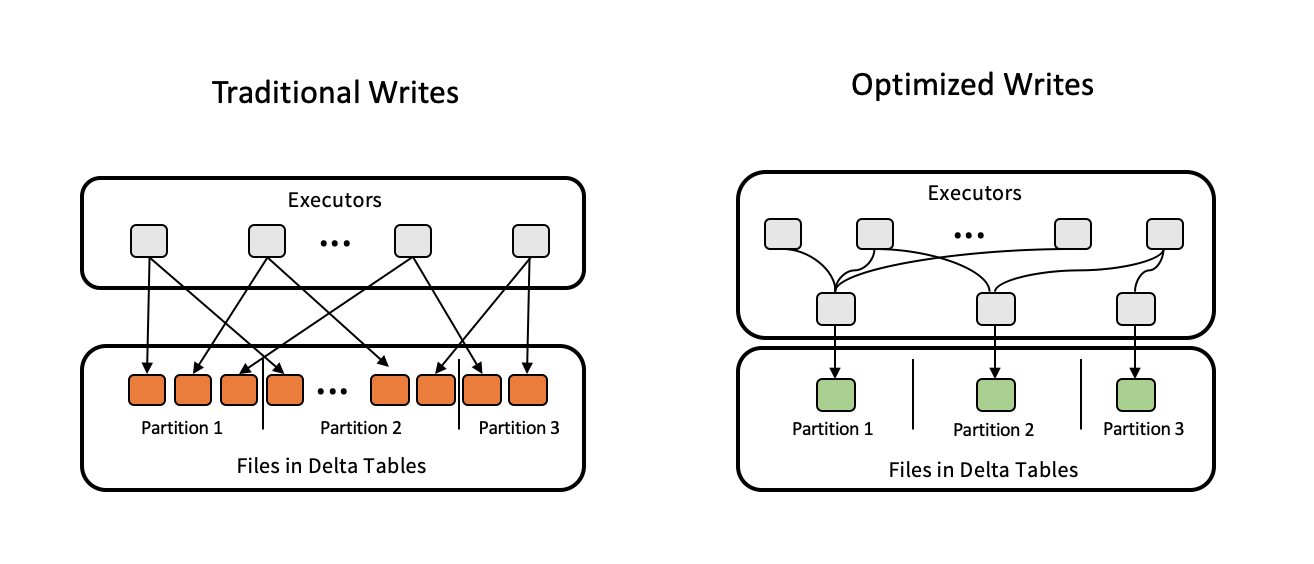
참고 항목
작성된 파일 수를 제어하기 위해 데이터를 쓰기 직전에 실행되는 coalesce(n) repartition(n) 코드가 있을 수 있습니다. 최적화된 쓰기는 이 패턴을 사용할 필요가 없습니다.
최적화된 쓰기는 Databricks Runtime 9.1 LTS 이상에서 다음 작업에 대해 기본적으로 사용하도록 설정됩니다.
MERGE- 하위 쿼리를 사용한
UPDATE - 하위 쿼리를 사용한
DELETE
SQL 웨어하우스를 사용할 때 문 및 INSERT 작업에 최적화된 CTAS 쓰기도 사용할 수 있습니다. Databricks Runtime 13.3 LTS 이상에서 Unity 카탈로그에 등록된 모든 델타 테이블은 분할된 테이블에 대한 CTAS 문 및 INSERT 작업에 대해 최적화된 쓰기를 사용하도록 설정했습니다.
다음 설정을 사용하여 테이블 또는 세션 수준에서 최적화된 쓰기를 사용하도록 설정할 수 있습니다.
- 테이블 설정:
delta.autoOptimize.optimizeWrite - SparkSession 설정:
spark.databricks.delta.optimizeWrite.enabled
이러한 설정은 다음 옵션을 허용합니다.
| 옵션 | 동작 |
|---|---|
true |
대상 파일 크기로 128MB를 사용합니다. |
false |
최적화된 쓰기를 해제합니다. 워크로드에서 수정된 모든 델타 테이블에 대한 자동 압축을 재정의하도록 세션 수준에서 설정할 수 있습니다. |
대상 파일 크기 설정
Delta 테이블의 파일 크기를 조정하려면 테이블 속성을 delta.targetFileSize 원하는 크기로 설정합니다. 이 속성이 설정되면 모든 데이터 레이아웃 최적화 작업은 지정된 크기의 파일을 가장 효율적인 방법으로 생성하려고 시도합니다. 여기에 최적화 또는 Z 순서, 자동 압축 및 최적화된 쓰기가 있습니다.
참고 항목
Unity 카탈로그 관리 테이블과 SQL 웨어하우스 또는 Databricks Runtime 11.3 LTS 이상을 사용하는 경우 명령만 OPTIMIZE 이 설정을 준수 targetFileSize 합니다.
| 테이블 속성 |
|---|
| delta.targetFileSize 형식: 바이트 또는 그 이상 단위의 크기입니다. 대상 파일 크기입니다. 예를 들어 104857600(바이트) 또는 100mb입니다.기본값: 없음 |
기존 테이블의 경우 ALTER TABLE SET TBL PROPERTIES SQL 명령을 사용하여 속성을 설정 및 설정 해제할 수 있습니다. Spark 세션 구성을 사용하여 새 테이블을 만들 때 이러한 속성을 자동으로 설정할 수도 있습니다. 자세한 내용은 Delta 테이블 속성 참조를 참조하세요.
워크로드를 기반으로 하는 Autotune 파일 크기
Databricks는 Databricks 런타임, Unity 카탈로그 또는 기타 최적화에 관계없이 여러 MERGE 또는 DML 작업의 대상이 되는 모든 테이블에 대해 테이블 속성을 delta.tuneFileSizesForRewrites true 설정하는 것이 좋습니다. 테이블 true의 대상 파일 크기가 훨씬 낮은 임계값으로 설정되어 쓰기 집약적 작업을 가속화합니다.
명시적으로 설정하지 않으면 Azure Databricks는 Delta 테이블에 대한 이전 10개 작업 중 9개가 작업인지 MERGE 자동으로 감지하고 이 테이블 속성을 . true로 설정합니다. 이 동작을 방지하려면 이 속성을 false 명시적으로 설정해야 합니다.
| 테이블 속성 |
|---|
| delta.tuneFileSizesForRewrites 유형: Boolean데이터 레이아웃 최적화에 맞게 파일 크기를 튜닝할지 여부입니다. 기본값: 없음 |
기존 테이블의 경우 ALTER TABLE SET TBL PROPERTIES SQL 명령을 사용하여 속성을 설정 및 설정 해제할 수 있습니다. Spark 세션 구성을 사용하여 새 테이블을 만들 때 이러한 속성을 자동으로 설정할 수도 있습니다. 자세한 내용은 Delta 테이블 속성 참조를 참조하세요.
테이블 크기에 따라 자동 조정 파일 크기
수동 튜닝에 대한 필요성을 Azure Databricks는 테이블 크기에 따라 델타 테이블의 파일 크기를 자동으로 튜닝합니다. Azure Databricks는 테이블의 파일 수가 너무 커지지 않도록 더 작은 테이블에는 더 작은 파일 크기를 사용하고 더 큰 테이블에는 더 큰 파일 크기를 사용합니다. Azure Databricks는 특정 대상 크기로 튜닝하거나 빈번하게 다시 쓰는 워크로드에 따라 튜닝한 테이블을 자동 튜닝하지 않습니다.
대상 파일 크기는 델타 테이블의 현재 크기를 기반으로 합니다. 2.56TB보다 작은 테이블의 경우 자동 튜닝된 대상 파일 크기는 256MB입니다. 크기가 2.56TB~10TB인 테이블의 경우 대상 크기는 256MB에서 1GB로 선형적으로 증가합니다. 10TB보다 큰 테이블의 경우 대상 파일 크기는 1GB입니다.
참고 항목
테이블의 대상 파일 크기가 커지면 기존 파일이 OPTIMIZE 명령을 통해 더 큰 파일로 다시 최적화되지 않습니다. 따라서 큰 테이블에는 항상 대상 크기보다 작은 일부 파일이 있을 수 있습니다. 이러한 작은 파일을 더 큰 파일로 최적화해야 하는 경우 delta.targetFileSize 테이블 속성을 사용하여 테이블에 대한 고정 대상 파일 크기를 구성할 수 있습니다.
테이블이 증분 방식으로 작성되는 경우 대상 파일 크기와 파일 수는 테이블 크기를 기준으로 다음 숫자에 가깝습니다. 이 표의 파일 수는 예일 뿐이며, 실제 결과는 여러 요인에 따라 달라집니다.
| 테이블 크기 | 대상 파일 크기 | 테이블의 대략적인 파일 수 |
|---|---|---|
| 10 GB | 256MB | 40 |
| 1TB | 256MB | 4096 |
| 2.56TB | 256MB | 10240 |
| 3 TB | 307MB | 12108 |
| 5TB | 512MB | 17339 |
| 7TB | 716MB | 20,784 |
| 10TB | 1GB | 24437 |
| 20TB | 1GB | 34437 |
| 50TB | 1GB | 64437 |
| 100TB | 1GB | 114437 |
데이터 파일에 기록된 행 제한
경우에 따라 데이터가 좁은 테이블에는 지정된 데이터 파일의 행 수가 Parquet 형식의 지원 제한을 초과하는 오류가 발생할 수 있습니다. 이 오류를 방지하려면 SQL 세션 구성 spark.sql.files.maxRecordsPerFile 을 사용하여 Delta Lake 테이블에 대한 단일 파일에 쓸 최대 레코드 수를 지정할 수 있습니다. 값 0 또는 음수 값을 지정하면 제한이 없습니다.
Databricks Runtime 11.3 LTS 이상에서는 DataFrame API를 사용하여 Delta Lake 테이블에 쓸 때 DataFrameWriter 옵션을 maxRecordsPerFile 사용할 수도 있습니다. maxRecordsPerFile이 지정된 경우 SQL 세션 구성 spark.sql.files.maxRecordsPerFile의 값은 무시됩니다.
참고 항목
앞서 언급한 오류를 방지할 필요가 없는 경우 Databricks는 이 옵션을 사용하지 않는 것이 좋습니다. 이 설정은 매우 좁은 데이터가 있는 일부 Unity 카탈로그 관리 테이블에 여전히 필요할 수 있습니다.
백그라운드 자동 압축으로 업그레이드
백그라운드 자동 압축은 Databricks Runtime 11.3 LTS 이상의 Unity 카탈로그 관리 테이블에 사용할 수 있습니다. 레거시 워크로드 또는 테이블을 마이그레이션할 때 다음을 수행합니다.
- 클러스터 또는 Notebook 구성 설정에서 Spark 구성
spark.databricks.delta.autoCompact.enabled을 제거합니다. - 각 테이블에 대해 실행
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)하여 레거시 자동 압축 설정을 제거합니다.
이러한 레거시 구성을 제거한 후에는 모든 Unity 카탈로그 관리 테이블에 대해 자동으로 트리거되는 백그라운드 자동 압축이 표시됩니다.