Azure DevOps를 사용하여 Azure Databricks에서 연속 통합 및 업데이트
참고 항목
이 문서에서는 Databricks에서 제공하거나 지원하지 않는 Azure DevOps에 대해 설명합니다. 공급자에게 문의하려면 Azure DevOps Services 지원을 참조하세요.
이 문서에서는 Azure Databricks에서 작동하는 코드 및 아티팩트용 Azure DevOps 자동화를 구성하는 방법을 안내합니다. 특히 Git 리포지토리에 연결하고, Azure Pipelines를 사용해 작업을 실행하여 Python 휠(*.whl)을 빌드 및 단위 테스트하고, Databricks Notebook에서 사용할 수 있도록 배포하는 CI/CD(연속 통합 및 제공) 워크플로를 구성합니다.
CI/CD 개발 워크플로
Databricks는 Azure DevOps를 사용한 CI/CD 개발을 위한 다음 워크플로를 제안합니다.
- 타사 Git 공급자와 함께 리포지토리를 만들거나 기존 리포지토리를 사용합니다.
- 로컬 개발 컴퓨터를 동일한 타사 리포지토리에 연결합니다. 지침은 타사 Git 공급자의 설명서를 참조하세요.
- 기존 업데이트된 아티팩트(예: Notebook, 코드 파일 및 빌드 스크립트)를 타사 리포지토리에서 로컬 개발 컴퓨터로 끌어옵니다.
- 필요에 따라 로컬 개발 컴퓨터에서 아티팩트를 만들고 업데이트 및 테스트합니다. 그런 다음, 로컬 개발 컴퓨터에서 타사 리포지토리로 새 아티팩트 및 변경된 아티팩트를 푸시합니다. 지침은 타사 Git 공급자의 설명서를 참조하세요.
- 필요에 따라 3단계와 4단계를 반복합니다.
- 타사 리포지토리에서 아티팩트를 자동으로 끌어오고, Azure Databricks 작업 영역에서 코드를 빌드, 테스트 및 실행하고, 테스트 및 실행 결과를 보고하는 접근 방법으로 Azure DevOps를 정기적으로 사용하세요. Azure DevOps를 수동으로 실행할 수 있지만 실제 구현에서는 리포지토리 끌어오기 요청과 같은 특정 이벤트가 발생할 때마다 타사 Git 공급자가 Azure DevOps를 실행하도록 지시합니다.
파이프라인을 관리하고 실행하는 데 사용할 수 있는 수많은 CI/CD 도구가 있습니다. 이 문서에서는 Azure DevOps를 사용하는 방법을 설명합니다. CI/CD는 디자인 패턴이므로 이 문서 예에 설명된 단계는 각 도구의 파이프라인 정의 언어에 대한 몇 가지 변경 내용과 함께 전송되어야 합니다. 또한 이 예제 파이프라인의 코드 대부분은 다른 도구에서 호출할 수 있는 표준 Python 코드입니다.
팁
Azure DevOps 대신 Azure Databricks와 함께 Jenkins를 사용하는 방법에 대한 자세한 내용은 Azure Databricks에서 Jenkins를 사용하는 CI/CD를 참조하세요.
이 문서의 나머지 부분에서는 Azure Databricks에 대한 고유한 요구 사항에 맞게 조정할 수 있는 Azure DevOps의 두 파이프라인 예에 대해 설명합니다.
예에 대한 정보
이 문서의 예제에서는 두 개의 파이프라인을 사용하여 원격 Git 리포지토리에 저장된 예제 Python 코드 및 Python Notebook을 수집, 배포 및 실행합니다.
첫 번째 파이프라인(빌드 파이프라인이라고 함)은 두 번째 파이프라인(릴리스 파이프라인이라고 함)을 위한 빌드 아티팩트를 준비합니다. 릴리스 파이프라인에서 빌드 파이프라인을 분리하면 빌드 아티팩트를 배포하지 않고 빌드 아티팩트를 만들거나 한 번에 여러 빌드에서 아티팩트를 배포할 수 있습니다. 빌드 및 릴리스 파이프라인을 생성하려면 다음을 수행합니다.
- 빌드 파이프라인에 대한 Azure Virtual Machines를 만듭니다.
- Git 리포지토리에서 가상 머신으로 파일을 복사합니다.
- Python 코드, Python Notebook 및 관련 빌드, 배포 및 실행 설정 파일이 포함된 gzip'ed tar 파일을 만듭니다.
- gzip으로 압축된 tar 파일을 Zip 파일로 릴리스 파이프라인이 액세스할 위치에 복사합니다.
- 릴리스 파이프라인에 대한 다른 Azure Virtual Machines를 만듭니다.
- 빌드 파이프라인의 위치에서 Zip 파일을 가져온 다음 Zip 파일을 압축 해제하여 Python Notebook 및 관련 빌드, 배포 및 실행 설정 파일을 가져옵니다.
- Python 코드, Python Notebook 및 관련 빌드, 배포 및 실행 설정 파일을 원격 Azure Databricks 작업 영역에 배포합니다.
- Python 휠 라이브러리의 구성 요소 코드 파일을 Python 휠 파일로 빌드합니다.
- 구성 요소 코드에서 단위 테스트를 실행하여 Python 휠 파일의 논리를 확인합니다.
- Python Notebook을 실행하고, 그 중 하나는 Python 휠 파일의 기능을 호출합니다.
Databricks CLI에 대해
이 문서의 예제에서는 파이프라인 내 비대화형 모드에서 Databricks CLI를 사용하는 방법을 보여 줍니다. 이 문서의 예제 파이프라인은 코드를 배포하고, 라이브러리를 빌드하고, Azure Databricks 작업 영역에서 Notebook을 실행합니다.
이 문서의 예제 코드, 라이브러리 및 Notebook을 구현하지 않고 파이프라인에서 Databricks CLI를 사용하는 경우 다음 단계를 수행합니다.
서비스 주체를 인증하기 위해 OAuth M2M(machine-to-machine) 인증을 사용하도록 Azure Databricks 작업 영역을 준비합니다. 시작하기 전에 Azure Databricks OAuth 비밀이 있는 Microsoft Entra ID 서비스 주체가 있는지 확인합니다. OAuth(OAuth M2M)를 사용하여 서비스 주체로 Azure Databricks에 액세스 인증을 참조하세요.
파이프라인에 Databricks CLI를 설치합니다. 이렇게 하려면 다음 스크립트를 실행하는 Bash 스크립트 태스크를 파이프라인에 추가합니다.
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh파이프라인에 Bash 스크립트 작업을 추가하려면 3.6단계: Databricks CLI 및 Python 휠 빌드 도구를 설치를 참조하세요.
설치된 Databricks CLI가 작업 영역에서 서비스 주체를 인증할 수 있도록 파이프라인을 구성합니다. 이렇게 하려면 3.1단계: 릴리스 파이프라인에 대한 환경 변수 정의를 참조하세요.
Databricks CLI 명령을 실행하기 위해 필요에 따라 파이프라인에 Bash 스크립트 태스크를 더 추가합니다. Databricks CLI 명령을 참조 하세요.
시작하기 전에
이 문서의 예를 사용하려면 다음이 있어야 합니다.
- 기존 Azure DevOps 프로젝트. 아직 프로젝트가 없으면 Azure DevOps에서 프로젝트를 만듭니다.
- Azure DevOps가 지원하는 Git 공급자가 있는 기존 리포지토리. 이 리포지토리에 Python 코드 예, Python Notebook 예 및 관련 릴리스 설정 파일을 추가합니다. 아직 리포지토리가 없는 경우 Git 공급자의 지침에 따라 리포지토리를 만듭니다. 그런 다음, 아직 수행하지 않은 경우 Azure DevOps 프로젝트를 이 리포지토리에 연결합니다. 지침은 지원되는 원본 리포지토리의 링크를 따릅니다.
- 이 문서의 예제에서는 OAuth M2M(machine-to-machine) 인증을 사용하여 Azure Databricks 작업 영역에 Microsoft Entra ID 서비스 주체를 인증합니다. 해당 서비스 주체에 대한 Azure Databricks OAuth 비밀이 있는 Microsoft Entra ID 서비스 주체가 있어야 합니다. OAuth(OAuth M2M)를 사용하여 서비스 주체로 Azure Databricks에 액세스 인증을 참조하세요.
1단계: 리포지토리에 예제 파일 추가
이 단계에서는 타사 Git 공급자가 있는 리포지토리에서 Azure DevOps 파이프라인이 원격 Azure Databricks 작업 영역에서 빌드, 배포 및 실행하는 이 문서의 예제 파일을 모두 추가합니다.
1.1단계: Python 휠 구성 요소 파일 추가
이 문서의 예제에서 Azure DevOps 파이프라인은 Python 휠 파일을 빌드하고 단위 테스트합니다. 그런 다음 Azure Databricks Notebook에 빌드된 Python 휠 파일의 기능을 호출합니다.
Notebook이 실행되는 Python 휠 파일에 대한 논리 및 단위 테스트를 정의하려면 리포지토리의 루트에서 addcol.py와 test_addcol.py라고 명명된 두 개의 파일을 만들고 python/dabdemo/dabdemo 폴더에 Libraries이라고 명명된 폴더 구조에 하고 다음과 같이 시각화합니다.
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
addcol.py 파일에는 나중에 Python 휠 파일에 빌드된 다음 Azure Databricks 클러스터에 설치되는 라이브러리 함수가 포함되어 있습니다. Apache Spark DataFrame에 리터럴로 채워진 새 열을 추가하는 간단한 함수입니다.
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
test_addcol.py 파일에는 with_status에 정의된 addcol.py 함수에 모의 DataFrame 개체를 전달하는 테스트가 포함되어 있습니다. 그런 다음 결과는 예상 값을 포함하는 DataFrame 개체와 비교됩니다. 값이 일치하면 테스트는 통과합니다.
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Databricks CLI가 이 라이브러리 코드를 Python 휠 파일에 올바르게 패키지할 수 있개 하려면 이전 두 파일과 일한 폴더에 이름이 __init__.py 및 __main__.py인 두 개의 파일을 만듭니다. 또한 setup.py 폴더에 python/dabdemo라는 이름이 지정된 파일을 만들고 다음과 같이 시각화합니다.
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
__init__.py 파일에는 라이브러리의 버전 번호와 작성자가 포함됩니다. <my-author-name>을 사용자의 이름으로 바꿉니다.
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
__main__.py 파일에는 라이브러리의 진입점이 포함됩니다.
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
setup.py 파일에는 라이브러리를 Python 휠 파일로 빌드하기 위한 추가 설정이 포함되어 있습니다. <my-url>, <my-author-name>@<my-organization> 및 <my-package-description>을 유효한 값으로 대체합니다.
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
1.2단계: Python 휠 파일에 대한 단위 테스트 Notebook 추가
나중에 Databricks CLI가 Notebook 작업을 실행합니다. 이 작업은 run_unit_tests.py 파일 이름으로 Python Notebook을 실행합니다. 이 Notebook은 Python 휠 라이브러리의 논리에 대해 반하는 pytest을 실행합니다.
이 문서의 예제에 대한 단위 테스트를 실행하려면 리포지토리의 루트의 다음 내용에 run_unit_tests.py라는 이름의 Notebook 파일을 추가합니다.
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
1.3단계: Python 휠 파일을 호출하는 Notebook 추가
나중에 Databricks CLI는 다른 Notebook 작업을 실행합니다. 이 Notebook은 DataFrame 개체를 만들고, Python 휠 라이브러리의 with_status 함수에 전달하고, 결과를 출력하고, 작업의 실행 결과를 보고합니다. 리포지토리의 루트를 다음 내용으로 dabdemo_notebook.py라고 명명된 Notebook 파일을 만듭니다.
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
1.4단계: 번들 구성 만들기
이 문서의 예제에서는 Databricks 자산 번들을 사용하여 Python 휠 파일, 두 Notebook 및 Python 코드 파일을 빌드, 배포 및 실행하기 위한 설정과 동작을 정의합니다. 단순히 번들로 알려진 Databricks 자산 번들을 사용하면 전체 데이터, 분석 및 ML 프로젝트를 원본 파일 컬렉션으로 표현할 수 있습니다. Databricks 자산 번들이란?을 참조하세요.
이 문서의 예제에 대한 번들을 구성하려면 리포지토리의 루트에 databricks.yml라는 이름이 지정된 파일을 만듭니다. 이 예제 databricks.yml 파일에서 다음 자리 표시자를 바꿉니다.
- 번들에 대한 고유한 프로그래밍 이름으로
<bundle-name>를 바꿉니다. 예들 들어azure-devops-demo입니다. - 이 예제에서는 Azure Databricks 작업 영역에서 만든 작업을 고유하게 식별하는 데 도움이 되는
<job-prefix-name>을 일부 문자열로 바꿉니다. 예들 들어azure-devops-demo입니다. - 예를 들어 작업 클러스터에 대한 Databricks Runtime 버전 ID(예:
<spark-version-id>)로13.3.x-scala2.12을 바꿉니다. - 예를 들어 작업 클러스터에 대한 클러스터 노드 유형 ID(예:
<cluster-node-type-id>)로Standard_DS3_v2을 바꿉니다. dev매핑에서targets은 호스트 및 관련 배포 동작을 지정합니다. 실제 구현에서는 이 대상에 고유한 번들에서 다른 이름을 지정할 수 있습니다.
databricks.yml 구성 파일의 예는 다음과 같습니다.
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
databricks.yml 파일 구문에 대한 자세한 내용은 Databricks 자산 번들 구성을 참조하세요.
2단계: 빌드 파이프라인 정의
Azure DevOps는 YAML을 사용하여 CI/CD 파이프라인의 단계를 정의하기 위한 클라우드 호스팅 사용자 인터페이스를 제공합니다. Azure DevOps 및 파이프라인에 대한 자세한 내용은 Azure DevOps 설명서를 참조하세요.
이 단계에서는 YAML 마크업을 사용하여 배포 아티팩트를 빌드하는 빌드 파이프라인을 정의합니다. 코드를 Azure Databricks 작업 영역에 배포하려면 이 파이프라인의 빌드 아티팩트를 릴리스 파이프라인에 입력으로 지정합니다. 이 릴리스 파이프라인은 나중에 정의합니다.
빌드 파이프라인을 실행하기 위해 Azure DevOps는 Kubernetes, VM, Azure Functions, Azure Web Apps 및 더 많은 대상에 대한 배포를 지원하는 클라우드 호스팅 주문형 실행 에이전트를 제공합니다. 이 예제에서는 주문형 에이전트를 사용하여 배포 아티팩트 빌드를 자동화합니다.
이 문서의 빌드 파이프라인 예제를 다음과 같이 정의합니다.
Azure DevOps에 로그인하고 Azure DevOps 프로젝트를 열기 위해 로그인 링크를 클릭합니다.
참고 항목
Azure Portal이 Azure DevOps 프로젝트 대신 표시되는 경우 >Azure DevOps 조직 > 내 Azure DevOps 조직에서 더 많은 서비스를 클릭한 다음 Azure DevOps 프로젝트를 엽니다.
사이드바에서 파이프라인을 클릭한 다음 파이프라인 메뉴에서 파이프라인을 클릭합니다.
새 파이프라인 단추를 클릭하고 화면의 지침을 따릅니다. (파이프라인이 이미 있는 경우 대신 파이프라인 생성을 클릭합니다.) 이러한 지침이 끝나면 파이프라인 편집기가 열립니다. 여기서 표시되는
azure-pipelines.yml파일에서 빌드 파이프라인 스크립트를 정의합니다. 지침의 끝에 파이프라인 편집기가 표시되지 않으면 빌드 파이프라인의 이름을 선택한 다음 편집을 클릭합니다.Git 분기 선택기
 를 사용하여 Git 리포지토리의 각 분기에 대한 빌드 프로세스를 사용자 지정할 수 있습니다. 리포지토리의
를 사용하여 Git 리포지토리의 각 분기에 대한 빌드 프로세스를 사용자 지정할 수 있습니다. 리포지토리의 main분기에서 직접 프로덕션 작업을 수행하지 않는 것이 CI/CD 모범 사례입니다 . 이 예제에서는main대신release라는 이름의 분기가 리포지토리에 있고 사용할 것으로 가정합니다.
azure-pipelines.yml빌드 파이프라인 스크립트는 기본적으로 파이프라인과 연결된 원격 Git 리포지토리의 루트에 저장됩니다.파이프라인의
azure-pipelines.yml파일의 시작 콘텐츠를 다음 정의로 덮어쓰고 저장을 클릭합니다.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
3단계: 릴리스 파이프라인 정의
릴리스 파이프라인은 빌드 파이프라인에서 빌드 아티팩트를 Azure Databricks 환경에 배포합니다. 이전 단계의 빌드 파이프라인에서 이 단계의 릴리스 파이프라인을 분리하면 배포하지 않고 빌드를 만들거나 동시에 여러 빌드의 아티팩트를 배포할 수 있습니다.
Azure DevOps 프로젝트의 사이드바에 있는 파이프라인 메뉴에서 릴리스를 클릭합니다.

새 > 새 릴리스 파이프라인을 클릭합니다. (파이프라인이 이미 있는 경우대신 새 파이프라인 을 클릭합니다.)
화면 측면에는 일반적인 배포 패턴에 대한 주요 템플릿 목록이 있습니다. 이 릴리스 파이프라인의 경우
 을 클릭합니다.
을 클릭합니다.
화면 측면의 Artifacts 상자에서
 를 클릭합니다. 아티팩트 추가 창의 원본(빌드 파이프라인)에서 이전에 만든 빌드 파이프라인을 선택합니다. 그런 다음, 추가를 클릭합니다.
를 클릭합니다. 아티팩트 추가 창의 원본(빌드 파이프라인)에서 이전에 만든 빌드 파이프라인을 선택합니다. 그런 다음, 추가를 클릭합니다.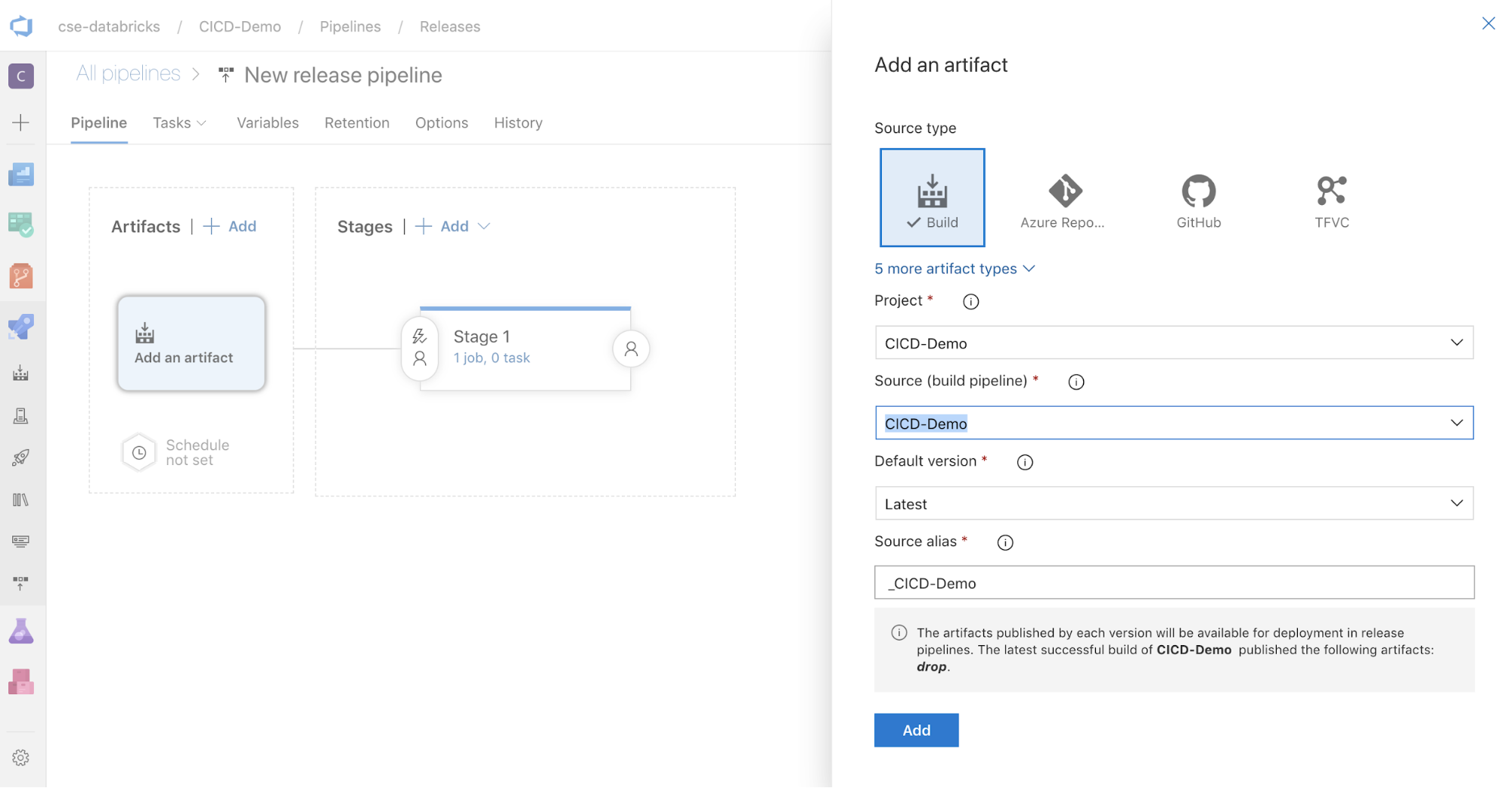
 를 클릭하여 파이프라인이 트리거되는 방식을 구성하여 화면 측면에 트리거 옵션을 표시할 수 있습니다. 빌드 아티팩트 가용성에 따라 또는 풀 요청 워크플로 후에 릴리스가 자동으로 시작되도록 하려면 적절한 트리거를 사용하도록 설정합니다. 현재 이 예의 경우 이 문서의 마지막 단계에서 수동으로 빌드 파이프라인을 트리거한 다음 릴리스 파이프라인을 트리거합니다.
를 클릭하여 파이프라인이 트리거되는 방식을 구성하여 화면 측면에 트리거 옵션을 표시할 수 있습니다. 빌드 아티팩트 가용성에 따라 또는 풀 요청 워크플로 후에 릴리스가 자동으로 시작되도록 하려면 적절한 트리거를 사용하도록 설정합니다. 현재 이 예의 경우 이 문서의 마지막 단계에서 수동으로 빌드 파이프라인을 트리거한 다음 릴리스 파이프라인을 트리거합니다.
저장 > 확인을 클릭합니다.
3.1단계: 릴리스 파이프라인에 대한 환경 변수 정의
이 예의 릴리스 파이프라인은 1단계의 범위로 변수 탭의 파이프라인 변수 섹션에서 추가를 클릭하여 추가할 수 있는 다음 환경 변수에 의존합니다.
BUNDLE_TARGET,databricks.yml파일의target이름과 일치해야 합니다 . 이 문서의 예제에서는dev입니다.DATABRICKS_HOST,https://로 시작하는 Azure Databricks 작업 영역의 작업 영역별 URL을 나타냅니다(예:https://adb-<workspace-id>.<random-number>.azuredatabricks.net)..net뒤에 후행/을 포함하지 마세요.DATABRICKS_CLIENT_ID, Microsoft Entra ID 서비스 주체의 애플리케이션 ID를 나타냅니다.DATABRICKS_CLIENT_SECRET, Microsoft Entra ID 서비스 주체에 대한 Azure Databricks OAuth 비밀을 나타냅니다.
3.2단계: 릴리스 파이프라인에 대한 릴리스 에이전트 구성
1단계 개체 내에서 1개의 작업, 0개의 작업 링크를 클릭합니다.
작업 탭에서 에이전트 작업을 클릭합니다.
에이전트 선택 섹션의 에이전트 풀에서 Azure Pipelines를 선택합니다.
에이전트 사양의 경우 이전에 빌드 에이전트에 대해 지정한 것과 동일한 에이전트를 선택합니다(이 예에서는 ubuntu-22.04.

저장 > 확인을 클릭합니다.
3.3단계: 릴리스 에이전트의 Python 버전 설정
다음 그림에서 빨간색 화살표로 표시된 에이전트 작업 섹션에서 더하기 기호를 클릭합니다. 사용 가능한 작업의 검색 가능한 목록이 나타납니다. 표준 Azure DevOps 작업을 보완하는 데 사용할 수 있는 타사 플러그 인용 Marketplace 탭도 있습니다. 다음 몇 단계 동안 릴리스 에이전트에 여러 작업을 추가합니다.
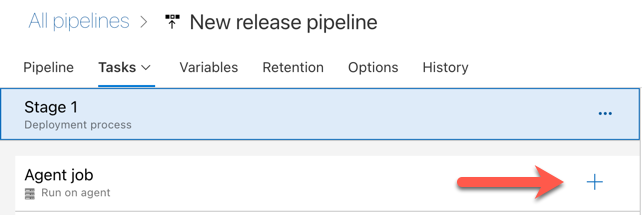
추가하는 첫 번째 작업은 도구 탭에 있는 Python 버전 사용입니다. 이 작업을 찾을 수 없으면 검색 상자를 사용하여 찾습니다. 해당 작업을 찾으면 선택한 다음 Python 버전 사용 작업 옆에 있는 추가 단추를 클릭합니다.
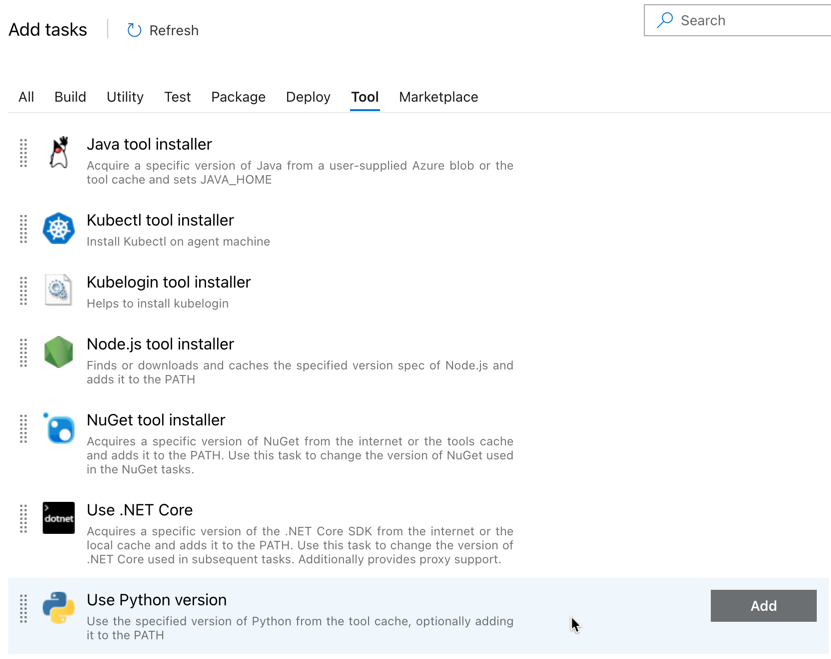
빌드 파이프라인과 마찬가지로 Python 버전이 후속 작업에서 호출되는 스크립트와 호환되는지 확인하려고 합니다. 이 경우 에이전트 작업 옆에 있는 Python 3.x 사용 작업을 클릭한 다음 버전 사양을
3.10로 설정합니다. 또한 표시 이름을Use Python 3.10로 설정합니다. 이 파이프라인은 Python 3.10.12가 설치된 클러스터에서 Databricks Runtime 13.3 LTS를 사용한다고 가정합니다.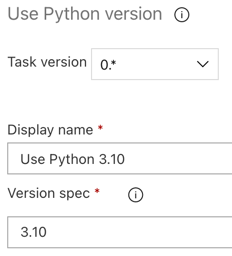
저장 > 확인을 클릭합니다.
3.4단계: 빌드 파이프라인에서 빌드 아티팩트 패키지 해제
그런 다음 릴리스 에이전트가 파일 추출 작업을 사용하여 Zip 파일에서 Python 휠 파일, 관련 릴리스 설정 파일, Notebook 및 Python 코드 파일 을 추출하도록 합니다. 에이전트 작업 섹션에서 더하기 기호를 클릭하고 유틸리티 탭에서 파일 추출 작업을 선택한 다음 추가를 클릭합니다.
에이전트 작업 옆에 있는 파일 추출 작업을 클릭하고 보관 파일 패턴을
**/*.zip으로 설정하고 대상 폴더를 시스템 변수$(Release.PrimaryArtifactSourceAlias)/Databricks로 설정합니다. 또한 표시 이름을Extract build pipeline artifact로 설정합니다.참고 항목
$(Release.PrimaryArtifactSourceAlias)는 릴리스 에이전트에서 기본 아티팩트 원본 위치를 식별하기 위해 Azure DevOps에서 생성한 별칭을 나타냅니다(예:_<your-github-alias>.<your-github-repo-name>). 릴리스 파이프라인은 릴리스 에이전트의 작업 초기화 단계에서 이 값을 환경 변수RELEASE_PRIMARYARTIFACTSOURCEALIAS로 설정합니다. 클래식 릴리스 및 아티팩트 변수를 참조하세요.표시 이름을
Extract build pipeline artifact로 설정합니다.
저장 > 확인을 클릭합니다.
3.5단계: BUNDLE_ROOT 환경 변수 설정
이 문서의 예제가 예상대로 작동하려면 릴리스 파이프라인에 BUNDLE_ROOT라고 명명된 환경 변수를 설정해야 합니다. Databricks 자산 번들은 이 환경 변수를 사용하여 databricks.yml 파일이 있는 위치를 결정합니다. 이 환경 변수를 설정하려면:
환경 변수를 사용합니다. 에이전트 작업 섹션에서 더하기 기호를 다시 클릭하고 유틸리티 탭에서 환경 변수 작업을 선택한 다음 추가를 클릭합니다.
참고 항목
유틸리티 탭에 환경 변수 작업이 표시되지 않으면 검색 상자에
Environment Variables을 입력하고 화면상의 지침에 따라 유틸리티 탭에 작업을 추가합니다. 이렇게 하려면 Azure DevOps를 종료한 다음 중단한 위치로 돌아가야 할 수 있습니다.환경 변수(쉼표로 구분됨)의 경우 다음 정의를 입력합니다.
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks참고 항목
$(Agent.ReleaseDirectory)는 릴리스 에이전트에서 릴리스 디렉터리 위치를 식별하기 위해 Azure DevOps에서 생성한 별칭을 나타냅니다(예:/home/vsts/work/r1/a). 릴리스 파이프라인은 릴리스 에이전트의 작업 초기화 단계에서 이 값을 환경 변수AGENT_RELEASEDIRECTORY로 설정합니다. 클래식 릴리스 및 아티팩트 변수를 참조하세요.$(Release.PrimaryArtifactSourceAlias)에 대한 자세한 내용은 이전 단계의 참고 항목을 참조하세요.표시 이름을
Set BUNDLE_ROOT environment variable로 설정합니다.
저장 > 확인을 클릭합니다.
3.6단계. Databricks CLI 및 Python 휠 빌드 도구 설치
다음으로, 릴리스 에이전트에 Databricks CLI 및 Python 휠 빌드 도구를 설치합니다. 릴리스 에이전트는 다음 몇 가지 작업에서 Databricks CLI 및 Python 휠 빌드 도구를 호출합니다. 이렇게 하려면 Bash 작업을 사용합니다. 에이전트 작업 섹션에서 더하기 기호를 다시 클릭하고 유틸리티 탭에서 Bash 작업을 선택한 다음 추가를 클릭합니다.
에이전트 작업 옆에 있는 Bash 스크립트 작업을 클릭합니다.
형식에서 인라인을 선택합니다.
스크립트의 콘텐츠를 Databricks CLI 및 Phython 휠 빌드 도구를 설치하는 다음 명령으로 바꿉니다.
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheel표시 이름을
Install Databricks CLI and Python wheel build tools로 설정합니다.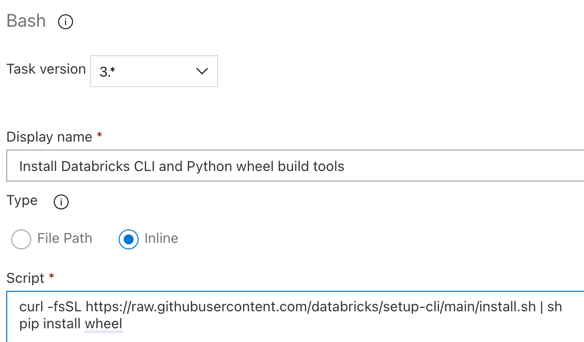
저장 > 확인을 클릭합니다.
3.7단계: Databricks 자산 번들 유효성 검사
이 단계에서는 databricks.yml 파일이 구문적으로 올바른지 확인 합니다.
Bash 작업을 사용합니다. 에이전트 작업 섹션에서 더하기 기호를 다시 클릭하고 유틸리티 탭에서 Bash 작업을 선택한 다음 추가를 클릭합니다.
에이전트 작업 옆에 있는 Bash 스크립트 작업을 클릭합니다.
형식에서 인라인을 선택합니다.
Databricks CLI를 사용하여
databricks.yml파일이 구문적으로 올바른지 확인하는 다음 명령으로 스크립트의 내용을 바꿉니다.databricks bundle validate -t $(BUNDLE_TARGET)표시 이름을
Validate bundle로 설정합니다.저장 > 확인을 클릭합니다.
3.8단계: 번들 배포
이 단계에서는 Python 휠 파일을 빌드하고 빌드된 Python 휠 파일, 두 개의 Python Notebook 및 Python 파일을 릴리스 파이프라인에서 Azure Databricks 작업 영역으로 배포합니다.
Bash 작업을 사용합니다. 에이전트 작업 섹션에서 더하기 기호를 다시 클릭하고 유틸리티 탭에서 Bash 작업을 선택한 다음 추가를 클릭합니다.
에이전트 작업 옆에 있는 Bash 스크립트 작업을 클릭합니다.
형식에서 인라인을 선택합니다.
Databricks CLI를 사용하여 Python 휠 파일을 빌드하고 릴리스 파이프라인에서 Azure Databricks 작업 영역으로 이 문서의 예제 파일을 배포하는 다음 명령으로 스크립트 의 내용을 바꿉니다.
databricks bundle deploy -t $(BUNDLE_TARGET)표시 이름을
Deploy bundle로 설정합니다.저장 > 확인을 클릭합니다.
3.9단계: Python 휠에 대한 단위 테스트 Notebook 실행
이 단계에서는 단위 테스트 Notebook을 실행하는 Azure Databricks 작업 영역에서 작업을 실행합니다. 이 Notebook은 Python 휠 라이브러리의 논리에 대해 단위 테스트를 실행합니다.
Bash 작업을 사용합니다. 에이전트 작업 섹션에서 더하기 기호를 다시 클릭하고 유틸리티 탭에서 Bash 작업을 선택한 다음 추가를 클릭합니다.
에이전트 작업 옆에 있는 Bash 스크립트 작업을 클릭합니다.
형식에서 인라인을 선택합니다.
Databricks CLI를 사용하여 Azure Databricks 작업 영역에서 작업을 실행하는 다음 명령으로 스크립트 의 내용을 바꿉니다.
databricks bundle run -t $(BUNDLE_TARGET) run-unit-tests표시 이름을
Run unit tests로 설정합니다.저장 > 확인을 클릭합니다.
3.10단계: Python 휠을 호출하는 Notebook 실행
이 단계에서는 다른 Notebook을 실행하는 Azure Databricks 작업 영역에서 작업을 실행합니다. 이 Notebook은 Python 휠 라이브러리를 호출합니다.
Bash 작업을 사용합니다. 에이전트 작업 섹션에서 더하기 기호를 다시 클릭하고 유틸리티 탭에서 Bash 작업을 선택한 다음 추가를 클릭합니다.
에이전트 작업 옆에 있는 Bash 스크립트 작업을 클릭합니다.
형식에서 인라인을 선택합니다.
Databricks CLI를 사용하여 Azure Databricks 작업 영역에서 작업을 실행하는 다음 명령으로 스크립트 의 내용을 바꿉니다.
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebook표시 이름을
Run notebook로 설정합니다.저장 > 확인을 클릭합니다.
이제 릴리스 파이프라인 구성을 완료했습니다. 아래와 같이 표시됩니다.

4단계: 빌드 및 릴리스 파이프라인 실행
이 단계에서는 파이프라인을 수동으로 실행합니다. 파이프라인을 자동으로 실행하는 방법을 알아보려면 파이프라인을 트리거하는 이벤트 지정 및 릴리스 트리거을 참조하세요.
빌드 파이프라인을 수동으로 실행하려면 다음을 수행합니다.
- 사이드바의 파이프라인 메뉴에서 파이프라인을 클릭합니다.
- 파이프라인 이름을 클릭한 다음 파이프라인 실행을 클릭합니다.
- 분기/태그에서 추가한 모든 소스 코드가 포함된 Git 리포지토리의 분기 이름을 선택합니다. 이 예에서는 이것이
release분기에 있다고 가정합니다. - 실행을 클릭합니다. 빌드 파이프라인의 실행 페이지가 나타납니다.
- 빌드 파이프라인의 진행 상황과 관련 로그를 보려면 작업 옆에 있는 회전 아이콘을 클릭합니다.
- 작업 아이콘이 녹색 확인 표시로 바뀌면 릴리스 파이프라인을 계속 실행합니다.
릴리스 파이프라인을 수동으로 실행하려면 다음을 수행합니다.
- 빌드 파이프라인이 성공적으로 실행되면 사이드바의 파이프라인 메뉴에서 릴리스를 클릭합니다.
- 릴리스 파이프라인의 이름을 클릭한 다음 릴리스 만들기를 클릭합니다.
- 만들기를 클릭합니다.
- 릴리스 파이프라인의 진행 상황을 보려면 릴리스 탭에서 최신 릴리스의 이름을 클릭합니다.
- 스테이지 상자에서 스테이지 1을 클릭하고 로그를 클릭합니다.