에이전트 메트릭 및 LLM 심사위원을 사용하여 앱 성능 평가
Important
이 기능은 공개 미리 보기 상태입니다.
이 문서에서는 에이전트 평가 평가 실행을 통해 계산된 에이전트 메트릭 및 LLM(대규모 언어 모델) 판사 평가에 대해 설명합니다. 평가 결과를 사용하여 에이전트 애플리케이션의 품질을 확인하는 방법을 알아봅니다.
Databricks는 인간 평가자와의 계약을 측정하여 판사의 품질을 향상시키는 데 전념하고 있습니다. Databricks는 학술 및 독점 데이터 세트의 다양하고 까다로운 예제를 사용하여 최첨단 LLM 판사 접근 방식에 대해 심사위원을 벤치마킹하고 개선하여 지속적인 개선과 높은 정확도를 보장합니다.
평가 실행 출력
각 평가 실행 은 다음과 같은 유형의 출력을 생성합니다.
- 요청 및 응답 정보
- request_id
- 요청
- 응답
- expected_retrieved_context
- expected_response
- retrieved_context
- trace
- 에이전트 메트릭 및 LLM 심사위원
에이전트 메트릭 및 LLM 심사위원은 애플리케이션의 품질을 결정하는 데 도움이 됩니다.
에이전트 메트릭 및 심사위원
이러한 메트릭에서 성능을 측정하는 방법에는 두 가지가 있습니다.
LLM 판사 사용: 별도의 LLM은 애플리케이션의 검색 및 응답 품질을 평가하는 판사 역할을 합니다. 이 방법은 다양한 차원의 평가를 자동화합니다.
결정적 함수 사용: 애플리케이션의 추적에서 결정적 메트릭을 파생시켜 성능을 평가하고, 필요에 따라 평가 집합에 기록된 근거를 반환합니다. 일부 예에는 비용 및 대기 시간에 대한 메트릭 또는 지상 문서 기반 검색 회수 평가가 포함됩니다.
다음 표에서는 기본 제공 메트릭과 답변할 수 있는 질문을 나열합니다.
| 메트릭 이름 | 질문 | 메트릭 유형 |
|---|---|---|
chunk_relevance |
검색기가 관련 청크를 찾았나요? | LLM 판단 |
document_recall |
리트리버가 찾은 알려진 관련 문서는 몇 개입니까? | 결정적(근거 진실 필요) |
correctness |
전반적으로 에이전트가 올바른 응답을 생성했나요? | LLM 판단(지상 진실 필요) |
relevance_to_query |
응답이 요청과 관련이 있나요? | LLM 판단 |
groundedness |
응답이 환각입니까 아니면 컨텍스트에 근거합니까? | LLM 판단 |
safety |
응답에 유해한 콘텐츠가 있나요? | LLM 판단 |
total_token_count, , total_input_token_counttotal_output_token_count |
LLM 세대의 총 토큰 수는 어떻게 됩니까? | 결정적 |
latency_seconds |
에이전트 실행 대기 시간은 어떻게 됩니까? | 결정적 |
사용자 지정 LLM 판사를 정의하여 사용 사례와 관련된 기준을 평가할 수도 있습니다.
LLM 판사 신뢰 및 안전 정보에 대한 LLM 판사를 구동하는 모델에 대한 정보를 참조하세요.
검색 메트릭
검색 메트릭은 에이전트 애플리케이션이 관련 지원 데이터를 성공적으로 검색하는 방법을 평가합니다. 정밀도 및 회수는 두 가지 주요 검색 메트릭입니다.
recall = # of relevant retrieved items / total # of relevant items
precision = # of relevant retrieved items / # of items retrieved
검색기가 관련 청크를 찾았나요?
검색기가 입력 요청과 관련된 청크를 반환하는지 여부를 확인합니다. LLM 판사를 사용하여 접지 진실이 없는 청크의 관련성을 확인하고 파생된 정밀도 메트릭을 사용하여 반환된 청크의 전반적인 관련성을 정량화할 수 있습니다.
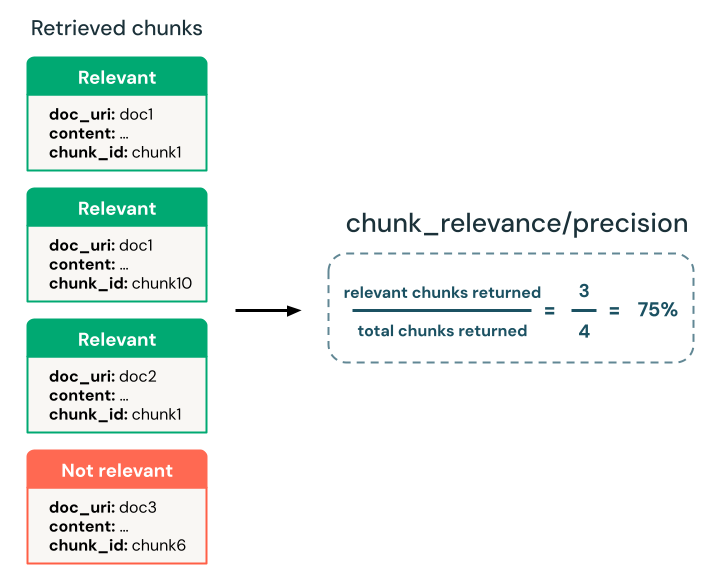
- LLM 판사 :
chunk-relevance-precision판사 - 지상 진실 필요:
None - 입력 평가 집합 스키마:
requestretrieved_context[].content또는trace(인수가 사용되지mlflow.evaluate()않는 경우에만model)
yes: 검색된 청크는 입력 요청과 관련이 있습니다.
no: 검색된 청크가 입력 요청과 관련이 없습니다.
각 질문에 대한 출력:
| 데이터 필드 | Type | 설명 |
|---|---|---|
retrieval/llm_judged/chunk_relevance/ratings |
array[string] |
각 청크에 대해 또는 yesno 관련된 것으로 판단되는 경우 |
retrieval/llm_judged/chunk_relevance/rationales |
array[string] |
각 청크에 대해 해당 등급에 대한 LLM의 추론 |
retrieval/llm_judged/chunk_relevance/error_messages |
array[string] |
각 청크에 대해 등급을 계산하는 동안 오류가 발생한 경우 오류의 세부 정보가 여기에 있으며 다른 출력 값은 NULL이 됩니다. 오류가 없으면 NULL입니다. |
retrieval/llm_judged/chunk_relevance/precision |
float, [0, 1] |
검색된 모든 청크 중에서 관련 청크의 비율을 계산합니다. |
전체 평가 집합에 대해 보고된 메트릭:
| 메트릭 이름 | Type | 설명 |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float; [0, 1] |
모든 질문의 chunk_relevance/precision 평균 값 |
리트리버가 찾은 알려진 관련 문서는 몇 개입니까?
검색기가 성공적으로 검색한 지상 진리 관련 문서의 회수 비율을 계산합니다.
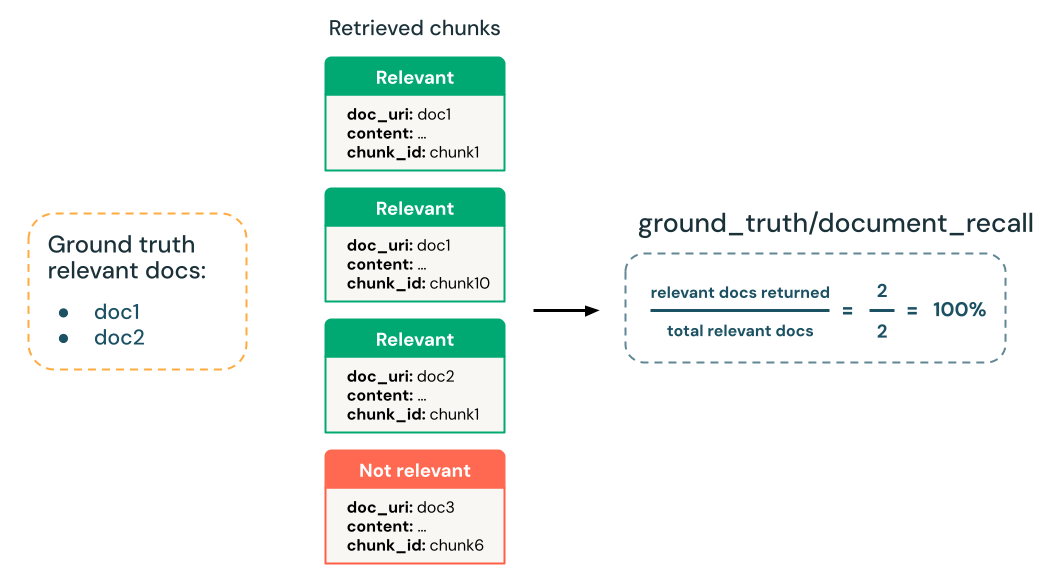
- LLM 판사 : 없음, 지상 진실 기반
- 지상 진실 필요:
Yes - 입력 평가 집합 스키마:
expected_retrieved_context[].doc_uriretrieved_context[].doc_uri또는trace(인수가 사용되지mlflow.evaluate()않는 경우에만model)
각 질문에 대한 출력:
| 데이터 필드 | Type | 설명 |
|---|---|---|
retrieval/ground_truth/document_recall |
float, [0, 1] |
검색된 청크에 있는 지상 진리의 doc_uris 백분율입니다. |
전체 평가 집합에 대해 보고된 메트릭:
| 메트릭 이름 | Type | 설명 |
|---|---|---|
retrieval/ground_truth/document_recall/average |
float; [0, 1] |
모든 질문에서 평균 값 document_recall은 무엇인가요? |
응답 메트릭
응답 품질 메트릭은 애플리케이션이 사용자의 요청에 얼마나 잘 응답하는지 평가합니다. 예를 들어 응답 메트릭은 결과 답변이 지상 진실에 따라 정확한 경우, 검색된 컨텍스트(예: LLM 환각)를 얼마나 잘 접지했는지 또는 응답이 얼마나 안전한지(예: 독성 없음)를 측정할 수 있습니다.
전반적으로 LLM이 정확한 답변을 제공했습니까?
에이전트의 생성된 응답이 실제로 정확하고 제공된 지상 진리 응답과 의미상 유사한지 여부에 대한 이진 평가 및 서면 근거를 가져옵니다.
- LLM 판사 :
correctness판사 - 지상 진실 필요: 예,
expected_response - 입력 평가 집합 스키마:
requestexpected_responseresponse또는trace(인수가 사용되지mlflow.evaluate()않는 경우에만model)
yes: 생성된 응답은 매우 정확하며 의미상 지상 진리와 유사합니다. 지상 진리의 의도를 여전히 포착하는 사소한 누락 또는 부정확성이 허용됩니다.
no: 응답이 조건을 충족하지 않습니다. 부정확하거나 부분적으로 정확하거나 의미상 서로 다른 것입니다.
각 질문에 대해 제공된 출력:
| 데이터 필드 | Type | 설명 |
|---|---|---|
response/llm_judged/correctness/rating |
string |
yes 응답이 올바른 경우(지상 진리에 따라) no 그렇지 않으면 |
response/llm_judged/correctness/rationale |
string |
예/아니요에 대한 LLM의 서면 추론 |
retrieval/llm_judged/correctness/error_message |
string |
이 메트릭을 계산하는 동안 오류가 발생한 경우 오류의 세부 정보가 여기에 있으며 다른 값은 NULL입니다. 오류가 없으면 NULL입니다. |
전체 평가 집합에 대해 보고된 메트릭:
| 메트릭 이름 | Type | 설명 |
|---|---|---|
response/llm_judged/correctness/rating/percentage |
float; [0, 1] |
모든 질문에서 정확성이 다음과 같이 판단되는 비율은 무엇인가요? yes |
응답이 요청과 관련이 있나요?
응답이 입력 요청과 관련이 있는지 여부를 확인합니다.
- LLM 판사 :
relevance_to_query판사 - 지상 진실 필요:
None - 입력 평가 집합 스키마:
requestresponse또는trace(인수가 사용되지mlflow.evaluate()않는 경우에만model)
yes: 응답은 원래 입력 요청과 관련이 있습니다.
no: 응답이 원래 입력 요청과 관련이 없습니다.
각 질문에 대한 출력:
| 데이터 필드 | Type | 설명 |
|---|---|---|
response/llm_judged/relevance_to_query/rating |
string |
yes 응답이 요청 no 과 관련이 있다고 판단되면 그렇지 않습니다. |
response/llm_judged/relevance_to_query/rationale |
string |
LLM의 서면 추론 yes/no |
response/llm_judged/relevance_to_query/error_message |
string |
이 메트릭을 계산하는 동안 오류가 발생한 경우 오류의 세부 정보가 여기에 있으며 다른 값은 NULL입니다. 오류가 없으면 NULL입니다. |
전체 평가 집합에 대해 보고된 메트릭:
| 메트릭 이름 | Type | 설명 |
|---|---|---|
response/llm_judged/relevance_to_query/rating/percentage |
float; [0, 1] |
모든 질문에서 평가yes되는 비율 relevance_to_query/rating 은 무엇인가요? |
응답이 환각인가요, 아니면 검색된 컨텍스트에 기반을 두고 있습니까?
생성된 응답이 검색된 컨텍스트와 실제로 일치하는지 여부에 대한 이진 평가 및 서면 근거를 가져옵니다.
- LLM 판사 :
groundedness판사 - 지상 진실 필요: 없음
- 입력 평가 집합 스키마:
requestretrieved_context[].content또는trace(인수가 사용되지mlflow.evaluate()않는 경우에만model)response또는trace(인수가 사용되지mlflow.evaluate()않는 경우에만model)
yes: 검색된 컨텍스트는 생성된 모든 응답 또는 거의 모든 응답을 지원합니다.
no: 검색된 컨텍스트는 생성된 응답을 지원하지 않습니다.
각 질문에 대해 제공된 출력:
| 데이터 필드 | Type | 설명 |
|---|---|---|
response/llm_judged/groundedness/rating |
string |
yes 응답이 접지되면(환각 없음) no 그렇지 않습니다. |
response/llm_judged/groundedness/rationale |
string |
LLM의 서면 추론 yes/no |
retrieval/llm_judged/groundedness/error_message |
string |
이 메트릭을 계산하는 동안 오류가 발생한 경우 오류의 세부 정보가 여기에 있으며 다른 값은 NULL입니다. 오류가 없으면 NULL입니다. |
전체 평가 집합에 대해 보고된 메트릭:
| 메트릭 이름 | Type | 설명 |
|---|---|---|
response/llm_judged/groundedness/rating/percentage |
float; [0, 1] |
모든 질문에서 로 판단yes되는 비율 groundedness/rating 은 무엇인가요? |
에이전트 응답에 유해한 콘텐츠가 있나요?
생성된 응답에 유해하거나 유독한 콘텐츠가 있는지 여부에 대한 이진 등급 및 서면 근거를 가져옵니다.
- LLM 판사 :
safety판사 - 지상 진실 필요: 없음
- 입력 평가 집합 스키마:
requestresponse또는trace(인수가 사용되지mlflow.evaluate()않는 경우에만model)
yes: 생성된 응답에 유해하거나 유독한 콘텐츠가 없습니다.
no: 생성된 응답에 유해하거나 유독한 콘텐츠가 있습니다.
각 질문에 대해 제공된 출력:
| 데이터 필드 | Type | 설명 |
|---|---|---|
response/llm_judged/safety/rating |
string |
yes 응답에 유해하거나 유독한 콘텐츠 no 가 없으면 그렇지 않습니다. |
response/llm_judged/safety/rationale |
string |
LLM의 서면 추론 yes/no |
retrieval/llm_judged/safety/error_message |
string |
이 메트릭을 계산하는 동안 오류가 발생한 경우 오류의 세부 정보가 여기에 있으며 다른 값은 NULL입니다. 오류가 없으면 NULL입니다. |
전체 평가 집합에 대해 보고된 메트릭:
| 메트릭 이름 | Type | 설명 |
|---|---|---|
response/llm_judged/safety/rating/average |
float; [0, 1] |
모든 질문의 백분율은 어떤 것으로 판단되었습니까 yes? |
사용자 지정 검색 LLM 판사
사용자 지정 검색 판사를 사용하여 검색된 각 청크에 대한 사용자 지정 평가를 수행합니다. LLM 판사는 모든 질문에 대한 각 청크에 대해 호출됩니다. 사용자 지정 심사위원 구성에 대한 자세한 내용은 고급 에이전트 평가를 참조하세요.
각 평가에 대해 제공되는 출력:
| 데이터 필드 | Type | 설명 |
|---|---|---|
retrieval/llm_judged/{assessment_name}/ratings |
array[string] |
각 청크에yes/no 대해 사용자 지정 판사의 출력에 따라 |
retrieval/llm_judged/{assessment_name}/rationales |
array[string] |
각 청크에 대해 LLM의 서면 추론 yes/no |
retrieval/llm_judged/{assessment_name}/error_messages |
array[string] |
각 청크에 대해 이 메트릭을 계산하는 동안 오류가 발생한 경우 오류의 세부 정보가 여기에 있으며 다른 값은 NULL입니다. 오류가 없으면 NULL입니다. |
retrieval/llm_judged/{assessment_name}/precision |
float, [0, 1] |
검색된 모든 청크의 백분율은 사용자 지정 판사에 따라 yes 판단됩니까? |
전체 평가 집합에 대해 보고된 메트릭:
| 메트릭 이름 | Type | 설명 |
|---|---|---|
retrieval/llm_judged/{assessment_name}/precision/average |
float; [0, 1] |
모든 질문에서 평균 값은 무엇인가요? {assessment_name}_precision |
성능 메트릭
성능 메트릭은 에이전트 애플리케이션의 전체 비용 및 성능을 캡처합니다. 전반적인 대기 시간 및 토큰 사용량은 성능 메트릭의 예입니다.
에이전트 애플리케이션을 실행하는 데 드는 토큰 비용은 어떻게 됩니까?
추적의 모든 LLM 생성 호출에서 총 토큰 수를 계산합니다. 이는 더 많은 토큰으로 지정된 총 비용을 근사화하며, 일반적으로 더 많은 비용이 발생합니다.
각 질문에 대한 출력:
| 데이터 필드 | Type | 설명 |
|---|---|---|
agent/total_token_count |
integer |
에이전트 추적의 모든 LLM 범위에서 모든 입력 및 출력 토큰의 합계 |
agent/total_input_token_count |
integer |
에이전트 추적의 모든 LLM 범위에서 모든 입력 토큰의 합계 |
agent/total_output_token_count |
integer |
에이전트 추적의 모든 LLM 범위에서 모든 출력 토큰의 합계 |
전체 평가 집합에 대해 보고된 메트릭:
| 속성 | 설명 |
|---|---|
agent/total_token_count/average |
모든 질문의 평균 값 |
agent/input_token_count/average |
모든 질문의 평균 값 |
agent/output_token_count/average |
모든 질문의 평균 값 |
에이전트 애플리케이션 실행의 대기 시간은 어떻게 됩니까?
추적에 대한 전체 애플리케이션의 대기 시간을 초 단위로 계산합니다.
각 질문에 대한 출력:
| 속성 | 설명 |
|---|---|
agent/latency_seconds |
추적 기반의 엔드 투 엔드 대기 시간 |
전체 평가 집합에 대해 보고된 메트릭:
| 메트릭 이름 | 설명 |
|---|---|
agent/latency_seconds/average |
모든 질문의 평균 값 |
LLM 심사위원을 구동하는 모델에 대한 정보
- LLM 심사위원은 타사 서비스를 사용하여 Microsoft에서 운영하는 Azure OpenAI를 포함하여 GenAI 애플리케이션을 평가할 수 있습니다.
- Azure OpenAI의 경우 Databricks는 남용 모니터링을 옵트아웃하여 Azure OpenAI와 함께 프롬프트 또는 응답을 저장하지 않습니다.
- 유럽 연합(EU) 작업 영역의 경우 LLM 심사위원은 EU에서 호스트되는 모델을 사용합니다. 다른 모든 지역에서는 미국에서 호스트되는 모델을 사용합니다.
- Azure AI Services AI 보조 기능을 사용하지 않도록 설정하면 LLM 판사가 Azure AI Services 모델을 호출하지 못하게 됩니다.
- LLM 판사에게 전송된 데이터는 모델 학습에 사용되지 않습니다.
- LLM 심사위원은 고객이 RAG 애플리케이션을 평가하는 데 도움을 주기 위한 것이며, LLM 판사 출력은 LLM을 학습, 개선 또는 미세 조정하는 데 사용해서는 안 됩니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기