평가를 실행하고 결과를 보는 방법
Important
이 기능은 공개 미리 보기 상태입니다.
이 문서에서는 AI 애플리케이션을 개발할 때 평가를 실행하고 결과를 보는 방법을 설명합니다. 프로덕션 트래픽에서 배포된 에이전트의 품질을 모니터링하는 방법에 대한 자세한 내용은 프로덕션 트래픽에서 에이전트의 품질을 모니터링하는 방법을 참조하세요.
앱 개발 중에 에이전트 평가를 사용하려면 평가 집합을 지정해야 합니다. 평가 집합은 사용자가 애플리케이션에 대해 만드는 일반적인 요청 집합입니다. 평가 집합에는 각 입력 요청에 대한 예상 응답(지상 진리)도 포함될 수 있습니다. 예상 응답이 제공되면 에이전트 평가는 정확성 및 컨텍스트 부족과 같은 추가 품질 메트릭을 계산할 수 있습니다. 평가 집합의 목적은 대표적인 질문에 대해 테스트하여 에이전트 애플리케이션의 성능을 측정하고 예측하는 데 도움이 되는 것입니다.
평가 집합에 대한 자세한 내용은 평가 집합을 참조 하세요. 필요한 스키마는 에이전트 평가 입력 스키마를 참조하세요.
평가를 시작하려면 MLflow API의 mlflow.evaluate() 메서드를 사용합니다. mlflow.evaluate() 는 평가 집합의 각 입력에 대한 대기 시간 및 비용 메트릭과 함께 품질 평가를 계산하고 모든 입력에서 이러한 결과를 집계합니다. 이러한 결과를 평가 결과라고도 합니다. 다음 코드에서 mlflow.evaluate()를 호출하는 예제를 볼 수 있습니다.
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
import pandas as pd
eval_df = pd.DataFrame(...)
# Puts the evaluation results in the current Run, alongside the logged model parameters
with mlflow.start_run():
logged_model_info = mlflow.langchain.log_model(...)
mlflow.evaluate(data=eval_df, model=logged_model_info.model_uri,
model_type="databricks-agent")
이 예제 mlflow.evaluate() 에서는 다른 명령(예: 모델 매개 변수)에 의해 기록된 정보와 함께 바깥쪽 MLflow 실행에 평가 결과를 기록합니다. MLflow 실행 외부에서 mlflow.evaluate()를 호출하는 경우 새 실행을 시작하고 해당 실행에서 평가 결과를 기록합니다. 실행에 기록된 평가 결과에 대한 세부 정보를 포함하여 mlflow.evaluate()에 관한 자세한 내용은 MLflow 설명서를 참조하세요.
요구 사항
작업 영역에서 Azure AI 기반 AI 보조 기능을 사용하도록 설정해야 합니다.
평가 실행에 입력을 제공하는 방법
평가 실행에 대한 입력을 제공하는 방법에는 다음과 같이 두 가지가 있습니다.
평가 집합과 비교할 이전에 생성된 출력을 제공합니다. 프로덕션에 이미 배포된 애플리케이션의 출력을 평가하거나 평가 구성 간의 평가 결과를 비교하려는 경우 이 옵션을 사용하는 것이 좋습니다.
이 옵션을 사용하면 다음 코드와 같이 평가 집합을 지정합니다. 평가 집합에는 이전에 생성된 출력이 포함되어야 합니다. 자세한 예제는 예제: 이전에 생성된 출력을 에이전트 평가에 전달하는 방법을 참조하세요.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )애플리케이션을 입력 인수로 전달합니다.
mlflow.evaluate()는 평가 집합의 각 입력에 대한 애플리케이션을 호출하고 생성된 각 출력에 대한 품질 평가 및 기타 메트릭을 보고합니다. MLflow 추적을 사용하도록 설정된 MLflow를 사용하여 애플리케이션을 기록했거나 애플리케이션이 Notebook에서 Python 함수로 구현되는 경우 이 옵션을 사용하는 것이 좋습니다. 애플리케이션이 Databricks 외부에서 개발되었거나 Databricks 외부에 배포된 경우에는 이 옵션을 사용하지 않는 것이 좋습니다.이 옵션을 사용하면 다음 코드와 같이 함수 호출에서 평가 집합 및 애플리케이션을 지정합니다. 자세한 예제는 예제: 에이전트 평가에 애플리케이션을 전달하는 방법을 참조하세요.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
평가 집합 스키마에 대한 자세한 내용은 에이전트 평가 입력 스키마를 참조 하세요.
평가 결과
에이전트 평가는 해당 출력을 mlflow.evaluate() 데이터 프레임으로 반환하고 이러한 출력을 MLflow 실행에 기록합니다. Notebook 또는 해당 MLflow 실행의 페이지에서 출력을 검사할 수 있습니다.
Notebook에서 출력 검토
다음 코드에서는 Notebook에서 평가 실행 결과를 검토하는 방법에 대한 몇 가지 예제를 보여 줍니다.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
데이터 프레임에는 per_question_results_df 입력 스키마의 모든 열과 각 요청과 관련된 모든 평가 결과가 포함됩니다. 계산 결과에 대한 자세한 내용은 에이전트 평가에서 품질, 비용 및 대기 시간을 평가하는 방법을 참조하세요.
MLflow UI를 사용하여 출력 검토
평가 결과는 MLflow UI에서도 확인할 수 있습니다. MLflow UI에 액세스하려면 Notebook의 오른쪽 사이드바에서 실험 아이콘 ![]() 을 클릭한 다음 해당 실행을 클릭하거나
을 클릭한 다음 해당 실행을 클릭하거나 mlflow.evaluate()를 실행한 Notebook 셀의 셀 결과에 표시되는 링크를 클릭합니다.
단일 실행에 대한 평가 결과 검토
이 섹션에서는 개별 실행에 대한 평가 결과를 검토하는 방법을 설명합니다. 실행 간에 결과를 비교하려면 실행 간에 평가 결과 비교를 참조 하세요.
LLM 심사위원의 품질 평가 개요
요청별 판사 평가는 버전 0.3.0 이상에서 databricks-agents 사용할 수 있습니다.
평가 집합에서 각 요청의 LLM 판단 품질에 대한 개요를 보려면 MLflow 실행 페이지에서 평가 결과 탭을 클릭합니다. 이 페이지에는 각 평가 실행의 요약 테이블이 표시됩니다. 추가 세부 정보는 실행의 평가 ID 를 클릭합니다.

이 개요에서는 각 요청에 대해 서로 다른 심사위원의 평가, 이러한 평가를 기반으로 하는 각 요청의 품질 전달/실패 상태 및 실패한 요청에 대한 근본 원인을 보여 줍니다. 테이블에서 행을 클릭하면 다음이 포함된 해당 요청에 대한 세부 정보 페이지로 이동됩니다.
- 모델 출력: 에이전트 앱에서 생성된 응답 및 포함된 경우 해당 추적입니다.
- 예상 출력: 각 요청에 대한 예상 응답입니다.
- 자세한 평가: 이 데이터에 대한 LLM 평가자의 평가입니다. 세부 정보 보기를 클릭하여 심사위원이 제공한 근거를 표시합니다.
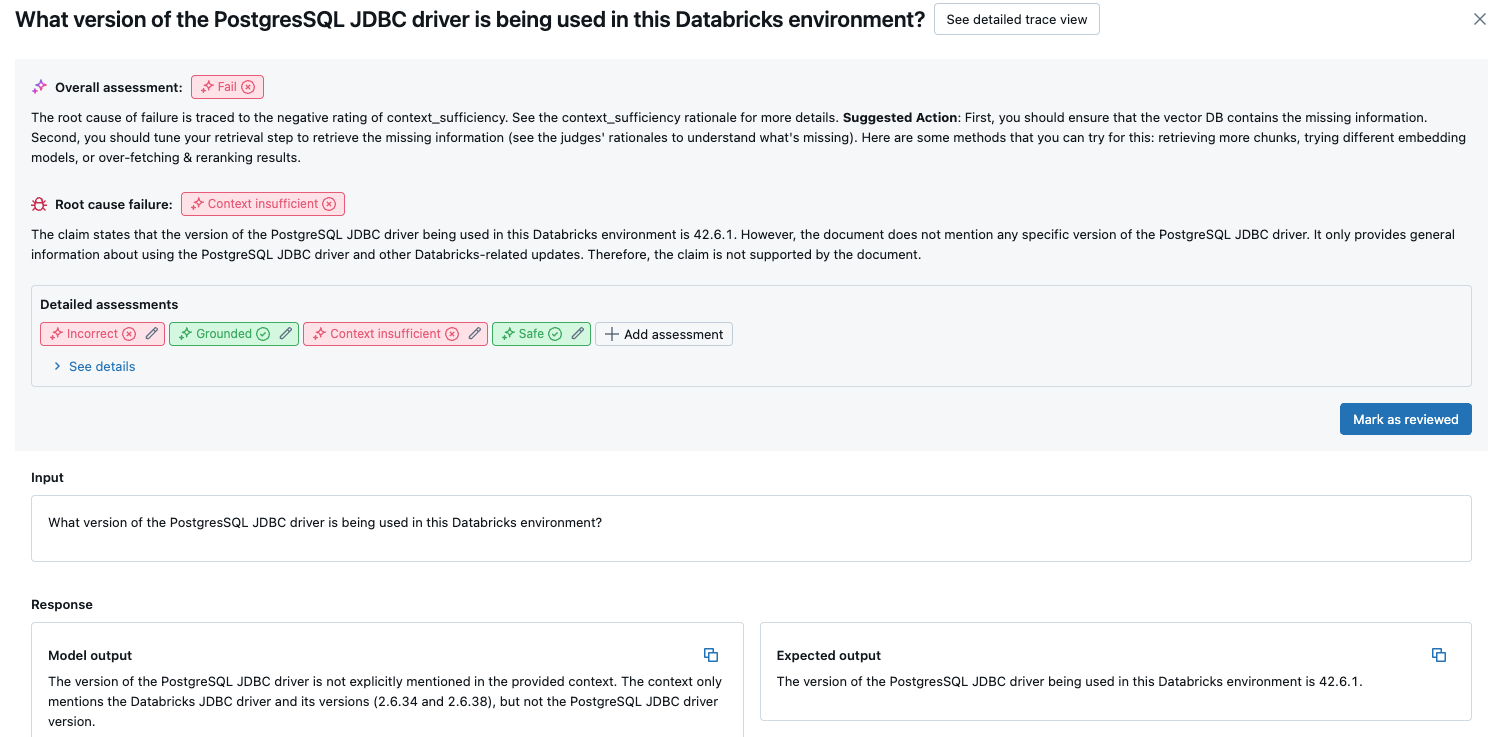
전체 평가 집합에서 집계된 결과
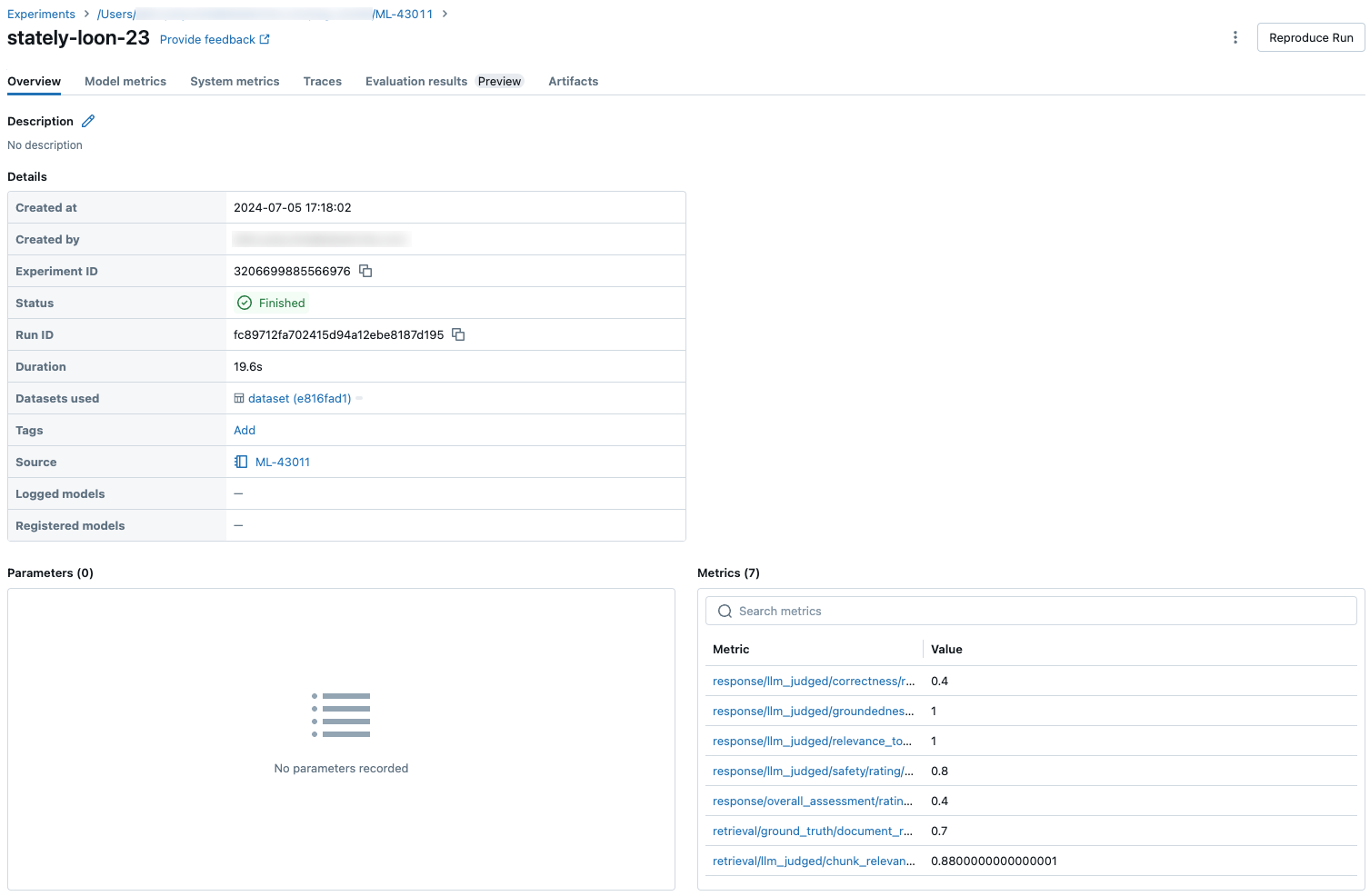
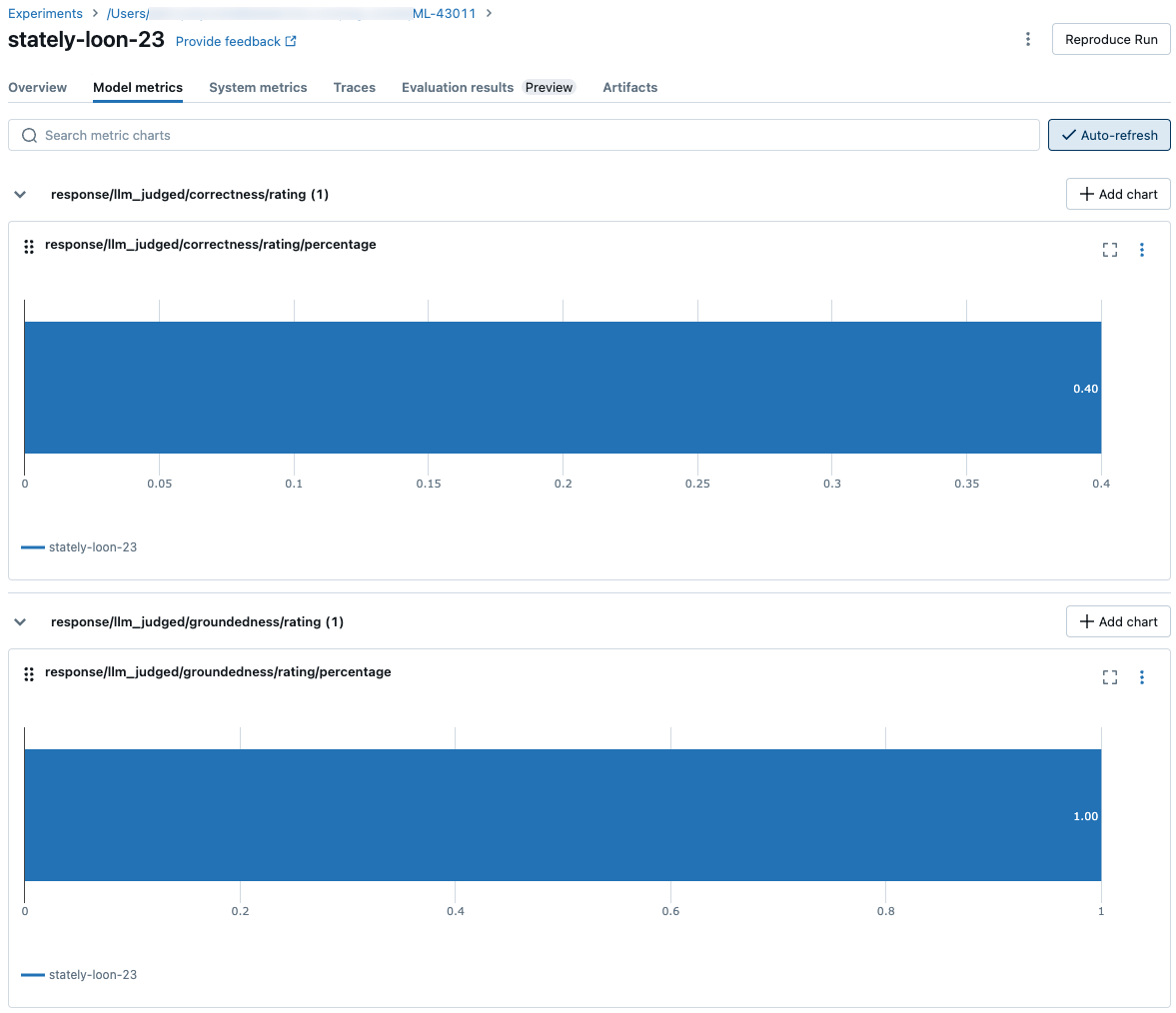
전체 평가 집합에서 집계된 결과를 보려면 개요 탭(숫자 값) 또는 모델 메트릭 탭(차트의 경우)을 클릭합니다.
실행 간에 평가 결과 비교
에이전트 애플리케이션이 변경에 응답하는 방식을 확인하려면 실행 간에 평가 결과를 비교하는 것이 중요합니다. 결과를 비교하면 변경 내용이 품질에 긍정적인 영향을 미치는지 또는 변경 동작 문제 해결에 도움이 되는지 이해하는 데 도움이 될 수 있습니다.
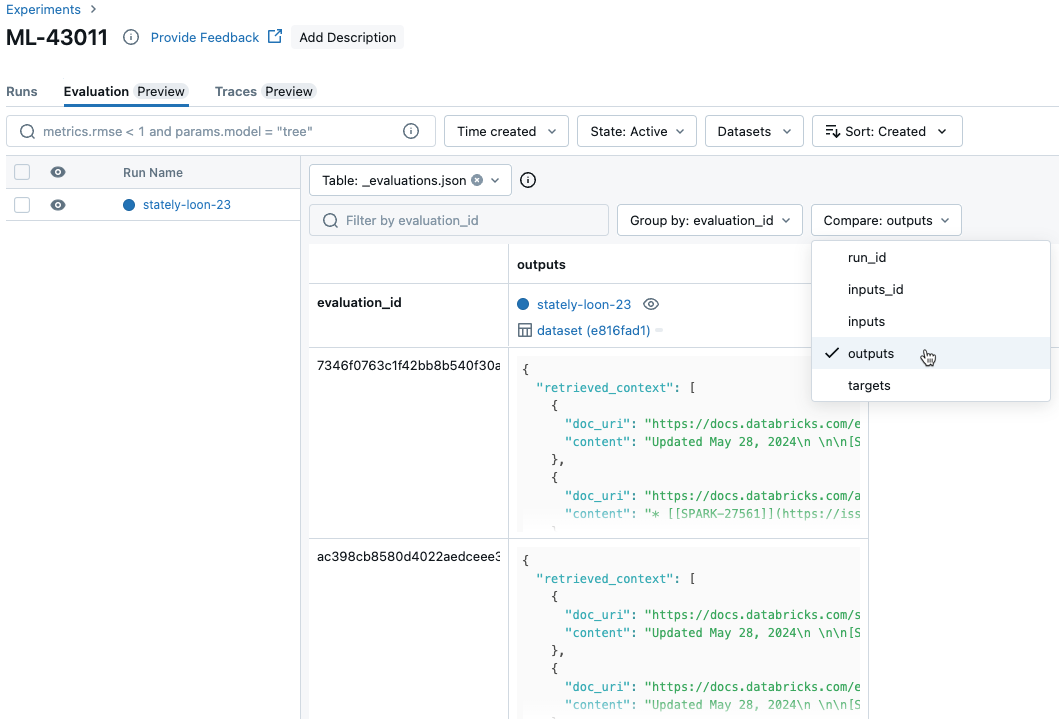
실행에서 요청당 결과 비교
실행에서 각 개별 요청에 대한 데이터를 비교하려면 실험 페이지에서 평가 탭을 클릭합니다. 테이블은 평가 집합의 각 질문을 보여줍니다. 드롭다운 메뉴를 사용하여 보려는 열을 선택합니다.
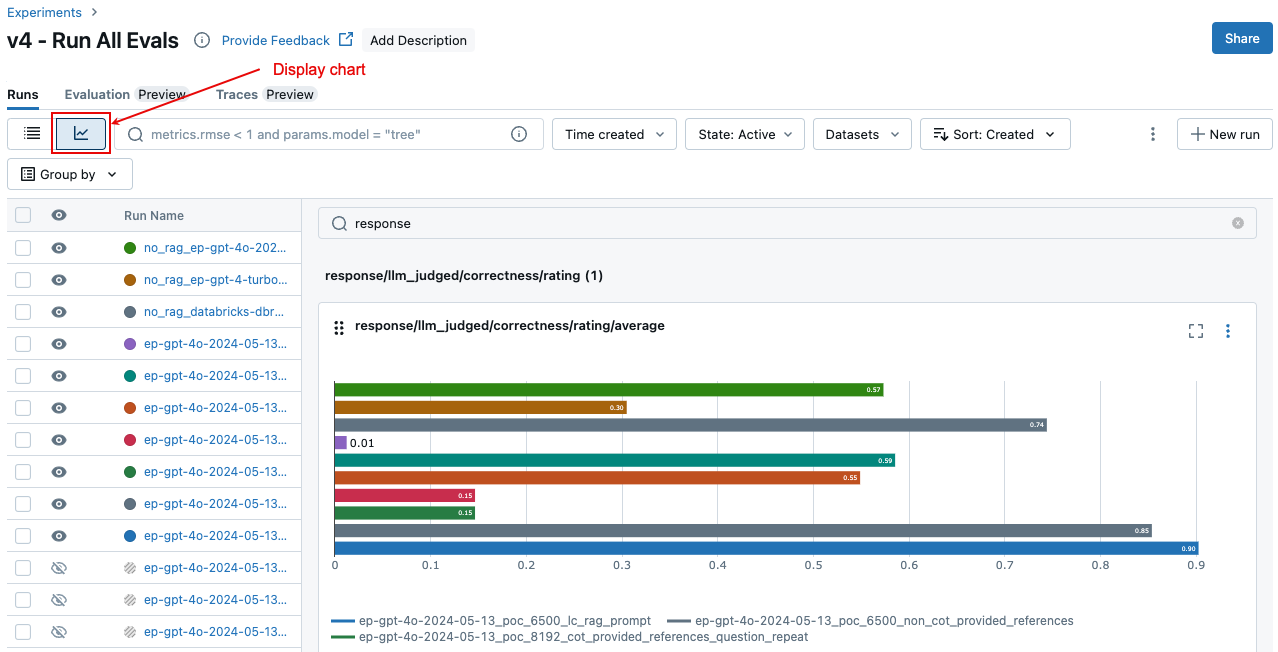
실행 간에 집계된 결과 비교
실험 페이지에서 동일한 집계된 결과에 액세스할 수 있으며, 이를 통해 여러 실행에서 결과를 비교할 수도 있습니다. 실험 페이지에 액세스하려면 Notebook의 오른쪽 사이드바에서 실험 아이콘 ![]() 을 클릭하거나
을 클릭하거나 mlflow.evaluate()를 실행한 Notebook 셀의 셀 결과에 표시되는 링크를 클릭합니다.
실험 페이지에서 ![]() 을 클릭합니다. 이렇게 하면 선택한 실행에 대해 집계된 결과를 시각화하고 과거 실행과 비교할 수 있습니다.
을 클릭합니다. 이렇게 하면 선택한 실행에 대해 집계된 결과를 시각화하고 과거 실행과 비교할 수 있습니다.
어떤 심사위원이 운영되는지
기본적으로 각 평가 레코드에 대해 Mosaic AI 에이전트 평가는 레코드에 있는 정보와 가장 일치하는 심사위원의 하위 집합을 적용합니다. 특별한 사항
- 레코드에 근거 응답이 포함된 경우 에이전트 평가는 ,
groundednesscorrectness및safety판사를context_sufficiency적용합니다. - 레코드에 근거 응답이 포함되지 않은 경우 에이전트 평가는 ,
groundedness및relevance_to_querysafety판사를chunk_relevance적용합니다.
다음과 같은 인수 mlflow.evaluate() 를 사용하여 각 요청에 적용할 심사위원을 evaluator_config 명시적으로 지정할 수도 있습니다.
# Complete list of built-in LLM judges
# "chunk_relevance", "context_sufficiency", "correctness", "groundedness", "relevance_to_query", "safety"
evaluation_results = mlflow.evaluate(
data=eval_df,
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
# Run only LLM judges that don't require ground-truth. Use an empty list to not run any built-in judge.
"metrics": ["groundedness", "relevance_to_query", "chunk_relevance", "safety"]
}
}
)
참고 항목
청크 검색, 체인 토큰 수 또는 대기 시간에 대해 LLM이 아닌 판정자 메트릭을 사용하지 않도록 설정할 수 없습니다.
기본 제공 심사위원 외에도 사용자 지정 LLM 판사를 정의하여 사용 사례와 관련된 기준을 평가할 수 있습니다. LLM 심사위원 사용자 지정을 참조하세요.
LLM 판정자 신뢰 및 안전 정보는 LLM 판정자를 구동하는 모델에 대한 정보를 참조하세요.
평가 결과 및 메트릭에 대한 자세한 내용은 에이전트 평가에서 품질, 비용 및 대기 시간을 평가하는 방법을 참조하세요.
예: 에이전트 평가에 애플리케이션을 전달하는 방법
애플리케이션을 mlflow_evaluate()전달하려면 인수를 model 사용합니다. 인수에 애플리케이션을 전달하기 위한 5가지 옵션이 있습니다 model .
- Unity 카탈로그에 등록된 모델입니다.
- 현재 MLflow 실험에서 기록된 MLflow 모델입니다.
- Notebook에 로드되는 PyFunc 모델입니다.
- Notebook의 로컬 함수입니다.
- 배포된 에이전트 엔드포인트입니다.
각 옵션을 보여 주는 코드 예제는 다음 섹션을 참조하세요.
옵션 1. Unity 카탈로그에 등록된 모델
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
옵션 2. 현재 MLflow 실험에서 기록된 MLflow 모델
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
옵션 3. Notebook에 로드되는 PyFunc 모델
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
옵션 4. Notebook의 로컬 함수
함수는 다음과 같이 형식이 지정된 입력을 받습니다.
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
함수는 다음 세 가지 지원되는 형식 중 하나로 값을 반환해야 합니다.
모델의 응답을 포함하는 일반 문자열입니다.
형식의
ChatCompletionResponse사전입니다. 예시:{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }와 같은
{ "content": "MLflow is a machine learning toolkit.", ... }형식의StringResponse사전입니다.
다음 예제에서는 로컬 함수를 사용하여 기본 모델 엔드포인트를 래핑하고 평가합니다.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
옵션 5. 배포된 에이전트 엔드포인트
이 옵션은 SDK 버전 0.8.0 이상을 사용하여 배포된 에이전트 엔드포인트를 사용하는 databricks.agents.deploy databricks-agents 경우에만 작동합니다. 기본 모델 또는 이전 SDK 버전의 경우 옵션 4를 사용하여 로컬 함수에서 모델을 래핑합니다.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
애플리케이션이 호출에 포함될 때 평가 집합을 mlflow_evaluate() 전달하는 방법
다음 코드 data 에서는 평가 집합이 있는 pandas DataFrame입니다. 다음은 간단한 예제입니다. 자세한 내용은 입력 스키마를 참조하세요.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
예: 이전에 생성된 출력을 에이전트 평가에 전달하는 방법
이 섹션에서는 호출에서 mlflow_evaluate() 이전에 생성된 출력을 전달하는 방법을 설명합니다. 필요한 평가 집합 스키마는 에이전트 평가 입력 스키마를 참조하세요.
다음 코드 data 에서는 평가 집합과 애플리케이션에서 생성한 출력이 있는 pandas DataFrame입니다. 다음은 간단한 예제입니다. 자세한 내용은 입력 스키마를 참조하세요.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
예: 사용자 지정 함수를 사용하여 LangGraph에서 응답 처리
LangGraph 에이전트, 특히 채팅 기능이 있는 에이전트는 단일 유추 호출에 대해 여러 메시지를 반환할 수 있습니다. 에이전트의 응답을 에이전트 평가에서 지원하는 형식으로 변환하는 것은 사용자의 책임입니다.
한 가지 방법은 사용자 지정 함수를 사용하여 응답을 처리하는 것입니다. 다음 예제에서는 LangGraph 모델에서 마지막 채팅 메시지를 추출하는 사용자 지정 함수를 보여 줍니다. 이 함수는 열과 mlflow.evaluate() 비교할 수 있는 단일 문자열 응답을 반환하는 ground_truth 데 사용됩니다.
예제 코드는 다음과 같은 가정을 합니다.
- 모델은 {"messages": [{"role": "user", "content": "hello"}]}형식의 입력을 허용합니다.
- 모델은 ["response 1", "response 2"] 형식의 문자열 목록을 반환합니다.
다음 코드는 "response 1nresponse2" 형식으로 연결된 응답을 판사에게 보냅니다.
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
메트릭을 사용하여 대시보드 만들기
에이전트의 품질을 반복하는 경우 시간이 지남에 따라 품질이 어떻게 향상되었는지를 보여 주는 대시보드를 이해 관계자와 공유할 수 있습니다. MLflow 평가 실행에서 메트릭을 추출하고, 값을 델타 테이블에 저장하고, 대시보드를 만들 수 있습니다.
다음 예제에서는 Notebook의 가장 최근 평가 실행에서 메트릭 값을 추출하고 저장하는 방법을 보여 줍니다.
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
다음 예제에서는 MLflow 실험에 저장한 과거 실행에 대한 메트릭 값을 추출하고 저장하는 방법을 보여 줍니다.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
이제 이 데이터를 사용하여 대시보드를 만들 수 있습니다.
다음 코드는 이전 예제에서 사용되는 함수 append_metrics_to_table 를 정의합니다.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
제한 사항
멀티 턴 대화의 경우 평가 출력은 대화의 마지막 항목만 기록합니다.
LLM 판정자를 구동하는 모델 관련 정보
- LLM 판정자는 타사 서비스를 사용하여 Microsoft에서 운영하는 Azure OpenAI를 포함한 GenAI 애플리케이션을 평가할 수 있습니다.
- Azure OpenAI의 경우 Databricks는 남용 모니터링을 옵트아웃하여 Azure OpenAI와 함께 프롬프트 또는 응답을 저장하지 않습니다.
- EU(유럽 연합) 작업 영역의 경우 LLM 판정자는 EU에서 호스트되는 모델을 사용합니다. 다른 모든 지역에서는 미국에서 호스트되는 모델을 사용합니다.
- Azure AI 기반 AI 보조 기능을 사용하지 않도록 설정하면 LLM 판정자가 Azure AI 기반 모델을 호출할 수 없습니다.
- LLM 판정자에게 전송된 데이터는 모델 학습에 사용되지 않습니다.
- LLM 판정자는 고객이 RAG 애플리케이션을 평가하는 데 도움을 주기 위한 것이며, LLM 판정자 출력은 LLM을 학습, 개선 또는 미세 조정하는 데 사용해서는 안 됩니다.