Vector Search 인덱스 만들기 및 쿼리 방법
이 문서에서는 Databricks Vector Search를 사용하여 벡터 검색 인덱스를 만들고 쿼리하는 방법을 설명합니다.
UI , Python SDK 또는 REST API를 사용하여 벡터 검색 엔드포인트 및 벡터 검색 인덱스와 같은 벡터 검색 구성 요소를 만들고 관리할 수 있습니다.
요구 사항
- Unity 카탈로그 사용 작업 영역.
- 서버리스 컴퓨팅을 사용하도록 설정했습니다.
- 원본 테이블에 변경 데이터 피드를 사용하도록 설정해야 합니다.
- 인덱스를 만들려면 카탈로그 스키마에 대한 CREATE TABLE 권한이 있어야 인덱스를 만들 수 있습니다. 다른 사용자가 소유한 인덱스를 쿼리하려면 추가 권한이 있어야 합니다. 벡터 검색 엔드포인트 쿼리를 참조하세요.
- 개인 액세스 토큰(프로덕션 워크로드에는 권장되지 않음)을 사용하려는 경우 개인 액세스 토큰이 사용하도록 설정된 검사. 대신 서비스 주체 토큰을 사용하려면 SDK 또는 API 호출을 사용하여 명시적으로 전달합니다.
SDK를 사용하려면 Notebook에 설치해야 합니다. 다음 코드를 사용합니다.
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
벡터 검색 엔드포인트 만들기
Databricks UI, Python SDK 또는 API를 사용하여 벡터 검색 엔드포인트를 만들 수 있습니다.
UI를 사용하여 벡터 검색 엔드포인트 만들기
다음 단계에 따라 UI를 사용하여 벡터 검색 엔드포인트를 만듭니다.
왼쪽 사이드바에서 컴퓨팅을 클릭합니다.
벡터 검색 탭을 클릭하고 만들기를 클릭합니다.

엔드포인트 만들기 양식이 열립니다. 이 엔드포인트의 이름을 입력합니다.
확인을 클릭합니다.
Python SDK를 사용하여 벡터 검색 엔드포인트 만들기
다음 예제에서는 create_endpoint() SDK 함수를 사용하여 Vector Search 엔드포인트를 만듭니다.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
REST API를 사용하여 벡터 검색 엔드포인트 만들기
POST /api/2.0/vector-search/endpoints를 참조 하세요.
(선택 사항) 포함 모델을 제공하도록 엔드포인트 만들기 및 구성
Databricks가 포함을 컴퓨팅하도록 선택하는 경우 포함 모델을 제공하도록 엔드포인트를 제공하는 모델을 설정해야 합니다. 지침은 엔드포인트를 제공하는 기본 모델 만들기를 참조하세요. 예를 들어 Notebook은 embeddings 모델을 호출하는 Notebook 예제를 참조하세요.
포함 엔드포인트를 구성할 때 Databricks는 크기 조정의 기본 선택을 0으로 제거하는 것이 좋습니다. 엔드포인트를 제공하는 데 몇 분 정도 걸릴 수 있으며, 규모가 축소된 엔드포인트가 있는 인덱스의 초기 쿼리는 시간 초과될 수 있습니다.
참고 항목
포함 엔드포인트가 데이터 세트에 대해 적절하게 구성되지 않은 경우 벡터 검색 인덱스 초기화 시간이 초과될 수 있습니다. 작은 데이터 세트 및 테스트에만 CPU 엔드포인트를 사용해야 합니다. 더 큰 데이터 세트의 경우 최적의 성능을 위해 GPU 엔드포인트를 사용합니다.
벡터 검색 인덱스 만들기
UI, Python SDK 또는 REST API를 사용하여 벡터 검색 인덱스 만들 수 있습니다. UI는 가장 간단한 방법입니다.
인덱스에는 두 가지 유형이 있습니다.
- 델타 동기화 인덱 스는 원본 델타 테이블과 자동으로 동기화되며 델타 테이블의 기본 데이터가 변경됨에 따라 인덱스를 자동으로 증분 방식으로 업데이트합니다.
- 직접 벡터 액세스 인덱 스는 벡터 및 메타데이터의 직접 읽기 및 쓰기를 지원합니다. 사용자는 REST API 또는 Python SDK를 사용하여 이 테이블을 업데이트해야 합니다. 이 유형의 인덱스도 UI를 사용하여 만들 수 없습니다. REST API 또는 SDK를 사용해야 합니다.
UI를 사용하여 인덱스 만들기
왼쪽 사이드바에서 카탈로그를 클릭하여 카탈로그 탐색기 UI를 엽니다.
사용하려는 델타 테이블로 이동합니다.
오른쪽 위에 있는 만들기 단추를 클릭하고 드롭다운 메뉴에서 벡터 검색 인덱스 선택
대화 상자의 선택기를 사용하여 인덱스 구성
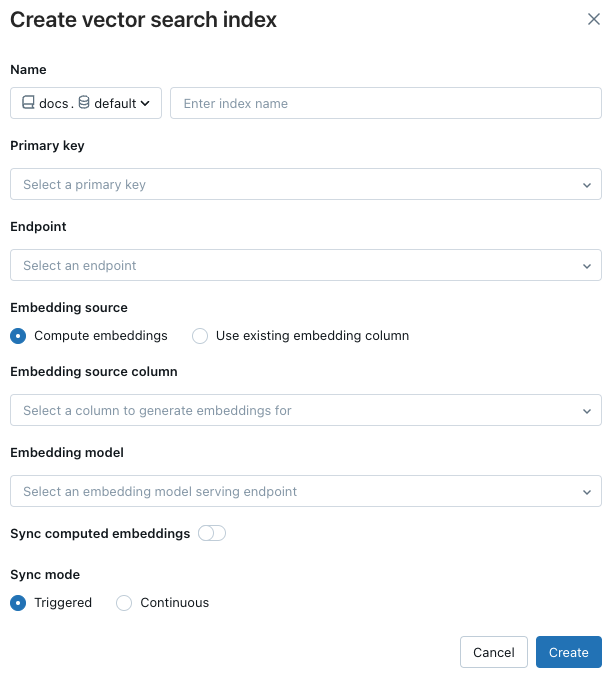
이름: Unity 카탈로그의 온라인 테이블에 사용할 이름입니다. 이름에는 세 개의 수준 네임스페이스가
<catalog>.<schema>.<name>필요합니다. 영숫자 문자와 밑줄만 허용됩니다.기본 키: 기본 키로 사용할 열입니다.
엔드포인트: 사용하려는 엔드포인트를 제공하는 모델을 선택합니다.
원본 포함: Databricks가 델타 테이블(Compute embeddings)의 텍스트 열에 대한 포함을 계산할지 또는 델타 테이블에 미리 계산된 포함 항목이 포함되어 있는지 여부를 나타냅니다(기존 포함 열 사용).
- 컴퓨팅 포함을 선택한 경우 계산할 포함 열과 포함 모델을 제공하는 엔드포인트를 선택합니다. 텍스트 열만 지원됩니다.
- 기존 포함 열 사용을 선택한 경우 미리 계산된 포함 및 포함 차원이 포함된 열을 선택합니다. 미리 계산된 포함 열의 형식은 이어야
array[float]합니다.
계산된 포함 동기화: 생성된 포함을 Unity 카탈로그 테이블에 저장하려면 이 설정을 설정/해제합니다. 자세한 내용은 생성된 포함 테이블 저장을 참조 하세요.
동기화 모드: 연속적으로 인덱스가 대기 시간(초)과 동기화된 상태로 유지됩니다. 그러나 연속 동기화 스트리밍 파이프라인을 실행하기 위해 컴퓨팅 클러스터가 프로비전되므로 연결된 비용이 더 높습니다. 트리거는 비용 효율적이지만 API를 사용하여 수동으로 시작해야 합니다. 연속 및 트리거의 경우 업데이트는 증분이며 마지막 동기화가 처리된 이후 변경된 데이터만 있습니다.
인덱스 구성을 마쳤으면 만들기를 클릭합니다.
Python SDK를 사용하여 인덱스 만들기
다음 예제에서는 Databricks에서 계산하는 포함을 사용하여 델타 동기화 인덱스를 만듭니다.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type='TRIGGERED',
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
다음 예제에서는 직접 벡터 액세스 인덱스 만들기
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "str",
"field3": "float",
"text_vector": "array<float>"}
)
REST API를 사용하여 인덱스 만들기
POST /api/2.0/vector-search/indexes를 참조 하세요.
생성된 포함 테이블 저장
Databricks가 포함을 생성하는 경우 생성된 포함을 Unity 카탈로그의 테이블에 저장할 수 있습니다. 이 테이블은 벡터 인덱스와 동일한 스키마에 만들어지고 벡터 인덱스 페이지에서 연결됩니다.
테이블의 이름은 벡터 검색 인덱스의 이름으로, .에 의해 추가됩니다 _writeback_table. 이름을 편집할 수 없습니다.
Unity 카탈로그의 다른 테이블과 마찬가지로 테이블에 액세스하고 쿼리할 수 있습니다. 그러나 수동으로 업데이트할 수 없으므로 테이블을 삭제하거나 수정해서는 안 됩니다. 인덱스가 삭제되면 테이블이 자동으로 삭제됩니다.
벡터 검색 인덱스 업데이트
델타 동기화 인덱스 업데이트
연속 동기화 모드로 만든 인덱스는 원본 델타 테이블이 변경되면 자동으로 업데이트됩니다. 트리거된 동기화 모드를 사용하는 경우 Python SDK 또는 REST API를 사용하여 동기화를 시작할 수 있습니다.
Python sdk
index.sync()
Rest API
REST API(POST /api/2.0/vector-search/indexes/{index_name}/sync)를 참조하세요.
직접 벡터 액세스 인덱스 업데이트
Python SDK 또는 REST API를 사용하여 직접 벡터 액세스 인덱스에서 데이터를 삽입, 업데이트 또는 삭제할 수 있습니다.
Python sdk
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
Rest API
REST API(POST /api/2.0/vector-search/indexes)를 참조하세요.
벡터 검색 엔드포인트 쿼리
Python SDK 또는 REST API를 사용하여 벡터 검색 엔드포인트만 쿼리할 수 있습니다.
참고 항목
엔드포인트를 쿼리하는 사용자가 벡터 검색 인덱스의 소유자가 아닌 경우 사용자에게 다음 UC 권한이 있어야 합니다.
- 벡터 검색 인덱스가 포함된 카탈로그에서 CATALOG를 사용합니다.
- 벡터 검색 인덱스가 포함된 스키마에서 SCHEMA를 사용합니다.
- 벡터 검색 인덱스 선택
Python sdk
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
results
Rest API
POST /api/2.0/vector-search/indexes/{index_name}/query를 참조하세요.
쿼리에 필터 사용
쿼리는 델타 테이블의 모든 열을 기반으로 필터를 정의할 수 있습니다. similarity_search 는 지정된 필터와 일치하는 행만 반환합니다. 다음 필터가 지원됩니다.
| 필터 연산자 | 동작 | 예제 |
|---|---|---|
NOT |
필터를 부정합니다. 키는 "NOT"으로 끝나야 합니다. 예를 들어 값이 "빨강"인 "color NOT"은 색이 빨간색이 아닌 문서와 일치합니다. | {"id NOT": 2} {“color NOT”: “red”} |
< |
필드 값이 필터 값보다 작은지 확인합니다. 키는 "로 <끝나야 합니다. 예를 들어 값이 100인 "price <"는 가격이 100보다 작은 문서와 일치합니다. | {"id <": 200} |
<= |
필드 값이 필터 값보다 작거나 같은지 확인합니다. 키는 " <="로 끝나야 합니다. 예를 들어 값이 100인 "price <="는 가격이 100보다 작거나 같은 문서와 일치합니다. | {"id <=": 200} |
> |
필드 값이 필터 값보다 큰지 확인합니다. 키는 "로 >끝나야 합니다. 예를 들어 값이 100인 "price >"는 가격이 100보다 큰 문서와 일치합니다. | {"id >": 200} |
>= |
필드 값이 필터 값보다 크거나 같은지 확인합니다. 키는 " >="로 끝나야 합니다. 예를 들어 값이 100인 "price >="는 가격이 100보다 크거나 같은 문서와 일치합니다. | {"id >=": 200} |
OR |
필드 값이 필터 값과 일치하는지 확인합니다. 키는 여러 하위 키를 구분하는 데 포함되어 OR 야 합니다. 예를 들어 color1 OR color2 값이 있는 경우는 문서 color1bluecolor2red 와 일치합니다.["red", "blue"] |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
부분 문자열과 일치합니다. | {"column LIKE": "hello"} |
| 필터 연산자가 지정되지 않음 | 정확한 일치 항목에 대한 검사 필터링합니다. 여러 값을 지정하면 값 중 하나와 일치합니다. | {"id": 200} {"id": [200, 300]} |
다음 코드 예제를 참조하세요.
Python sdk
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]}
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]}
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"}
num_results=2
)
Rest API
POST /api/2.0/vector-search/indexes/{index_name}/query를 참조하세요.
예제 Notebook
이 섹션의 예제에서는 Vector Search Python SDK를 사용하는 방법을 보여 줍니다.
LangChain 예제
LangChain 패키지와의 통합에서처럼 Databricks Vector Search를 사용하기 위해 Databricks Vector Search에서 LangChain을 사용하는 방법을 참조하세요.
다음 전자 필기장에서는 유사성 검색 결과를 LangChain 문서로 변환하는 방법을 보여 줍니다.
Python SDK Notebook을 사용하여 벡터 검색
embeddings 모델을 호출하기 위한 Notebook 예제
다음 Notebook에서는 포함 생성을 위해 Databricks 모델 서비스 엔드포인트를 구성하는 방법을 보여 줍니다.
Databricks Model Serving Notebook을 사용하여 OpenAI embeddings 모델 호출
Databricks 모델 서비스 Notebook을 사용하여 BGE 포함 모델 호출
OSS 포함 모델 Notebook 등록 및 제공
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기