이 문서에서는 Mosaic AI 벡터 검색의 정의와 작동 방식을 포함하여 Mosaic AI 벡터 검색에 대한 개요를 제공합니다.
Mosaic AI Vector Search란?
Mosaic AI Vector Search는 Databricks Data Intelligence 플랫폼에 기본 제공되고 거버넌스 및 생산성 도구와 통합된 벡터 검색 솔루션입니다. 벡터 검색은 포함 검색에 최적화된 검색 유형입니다. 포함은 데이터의 의미 체계 콘텐츠(일반적으로 텍스트 또는 이미지 데이터)의 수학적 표현입니다. 포함은 큰 언어 모델에 의해 생성되며 서로 유사한 문서 또는 이미지를 찾는 데 의존하는 많은 생성 AI 애플리케이션의 핵심 구성 요소입니다. 예를 들어 RAG 시스템, 추천 시스템, 이미지 및 비디오 인식이 있습니다.
Mosaic AI Vector Search를 사용하여 델타 테이블에서 벡터 검색 인덱스 만들기 인덱스에는 메타데이터가 내장된 데이터가 포함되어 있습니다. 그런 다음 REST API를 사용하여 인덱스를 쿼리하여 가장 유사한 벡터를 식별하고 연결된 문서를 반환할 수 있습니다. 기본 델타 테이블이 업데이트되면 자동으로 동기화되도록 인덱스 구조를 지정할 수 있습니다.
Mosaic AI Vector Search는 다음을 지원합니다.
- 하이브리드 키워드 유사성 검색.
- 모든 엔드포인트에서 전체 텍스트 키워드 검색(베타) 또는 스토리지 최적화 엔드포인트의 전용 전체 텍스트 인덱스(베타)입니다.
- 필터링합니다.
- 재정렬.
- ACL(액세스 제어 목록)을 사용하여 벡터 검색 엔드포인트를 관리합니다.
- 선택한 열만동기화합니다.
- 생성된 임베딩을 저장하고 동기화합니다.
모자이크 AI 벡터 검색은 어떻게 작동하나요?
Mosaic AI Vector Search는 근사 최근접 검색(ANN)에 HNSW (Hierarchical Navigable Small World) 알고리즘을 사용하고, L2 거리 메트릭을 사용하여 임베딩 벡터의 유사성을 측정합니다. 코사인 유사성을 사용하려면 데이터 요소 포함을 벡터 검색에 공급하기 전에 정규화해야 합니다. 데이터 요소가 정규화되면 L2 거리로 생성된 순위는 코사인 유사성에 의해 생성되는 순위와 동일합니다.
Mosaic AI Vector Search는 벡터 기반 포함 검색과 기존 키워드 기반 검색 기술을 결합하는 하이브리드 키워드 유사성 검색도 지원합니다. 이 방법은 벡터 기반 유사성 검색을 사용하여 쿼리의 의미 체계 관계 및 컨텍스트를 캡처하는 동시에 쿼리의 정확한 단어와 일치합니다.
이러한 두 가지 기술을 통합하여 하이브리드 키워드 유사성 검색은 정확한 키워드뿐만 아니라 개념적으로 유사한 키워드가 포함된 문서를 검색하여 보다 포괄적이고 관련 있는 검색 결과를 제공합니다. 이 메서드는 원본 데이터에 순수 유사성 검색에 적합하지 않은 SKU 또는 식별자와 같은 고유한 키워드가 있는 RAG 애플리케이션에서 특히 유용합니다.
API에 대한 자세한 내용은 Python SDK 참조 및 벡터 검색 인덱스 쿼리를 참조하세요.
유사성 검색 계산
유사성 검색 계산에서는 다음 수식을 사용합니다.
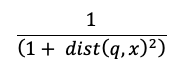
여기서 dist 쿼리 q 인덱스 항목 x사이의 유클리드 거리입니다.
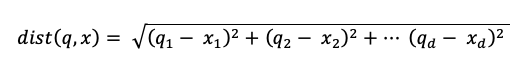
키워드 검색 알고리즘
관련성 점수는 Okapi BM25를 사용하여 계산됩니다. 텍스트 또는 문자열 형식의 원본 텍스트 포함 및 메타데이터 열을 포함하여 모든 텍스트 또는 문자열 열이 검색됩니다. 토큰화 함수는 단어 경계에서 분할되고 문장 부호를 제거하며 모든 텍스트를 소문자로 변환합니다.
유사성 검색 및 키워드 검색을 결합하는 방법
유사성 검색 및 키워드 검색 결과는 상호 순위 퓨전(RRF) 함수를 사용하여 결합됩니다.
RRF는 먼저 점수를 사용하여 각 방법에 대해 각 문서에 다시 점수를 매깁니다.
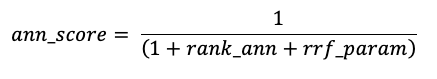
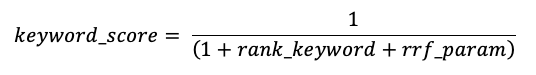
rrf_param는 상위 순위 및 하위 순위 문서의 상대적 중요도를 제어합니다. 문헌에 따라 rrf_param 60으로 설정됩니다.
다음 정규화 요소를 사용하여 가능한 가장 높은 점수가 1이 되도록 점수가 정규화됩니다.
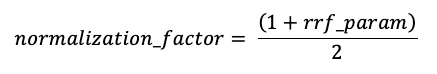
각 문서의 최종 점수는 다음과 같이 계산됩니다.
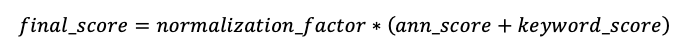
최종 점수가 가장 높은 문서가 반환됩니다.
벡터 임베딩 제공 옵션
Databricks에서 벡터 검색 인덱스를 만들려면 먼저 벡터 포함을 제공하는 방법을 결정해야 합니다. Databricks는 세 가지 옵션을 지원합니다.
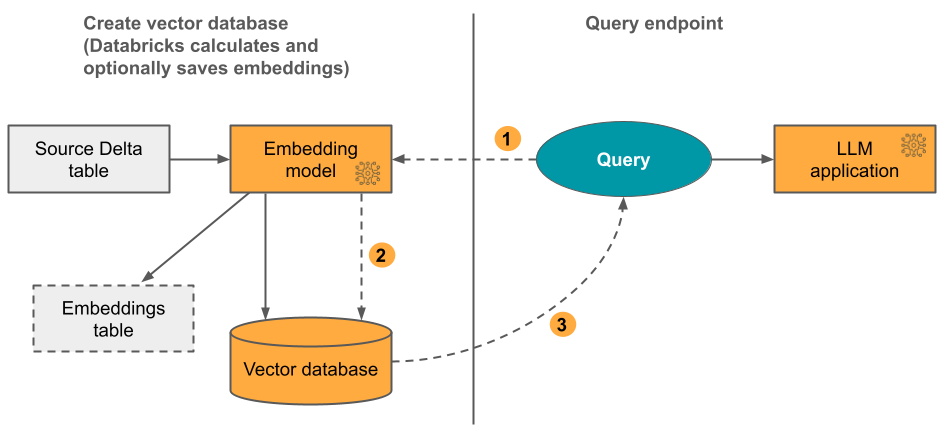
옵션 1: Databricks에서 계산한 포함을 사용하는 델타 동기화 인덱스
이 옵션을 사용하면 텍스트 형식의 데이터가 포함된 원본 델타 테이블을 제공합니다. Databricks는 사용자가 지정한 모델을 사용하여 포함을 계산하고 선택적으로 Unity 카탈로그의 테이블에 포함을 저장합니다. 델타 테이블이 업데이트되면 인덱스는 델타 테이블과 동기화된 상태로 유지됩니다.
아래 다이어그램은 이 프로세스를 보여 줍니다.
- 쿼리 임베딩을 계산합니다. 쿼리에는 메타데이터 필터가 포함될 수 있습니다.
- 유사성 검색을 수행하여 가장 관련성이 큰 문서를 식별합니다.
- 가장 관련성이 높은 문서를 반환하고 쿼리에 추가합니다.
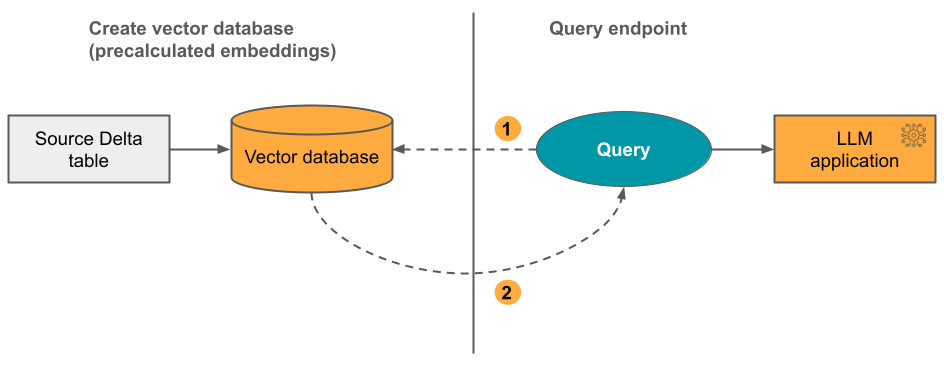
옵션 2: 자체 관리형 포함을 사용하는 델타 동기화 인덱스
이 옵션을 사용하면 미리 계산된 임베딩이 포함된 원본 소스 델타 테이블을 제공합니다. 델타 테이블이 업데이트되면 인덱스는 델타 테이블과 동기화된 상태로 유지됩니다.
비고
자체 관리형 포함 인덱스를 Databricks 관리형 인덱스로 변환할 수 없습니다. 나중에 관리되는 포함을 사용하기로 결정한 경우 새 인덱스를 만들고 포함을 다시 계산해야 합니다.
아래 다이어그램은 이 프로세스를 보여 줍니다.
- 쿼리는 임베딩으로 구성되며, 메타데이터 필터를 사용할 수 있습니다.
- 유사성 검색을 수행하여 가장 관련성이 큰 문서를 식별합니다. 가장 관련성이 높은 문서를 반환하고 쿼리에 추가합니다.
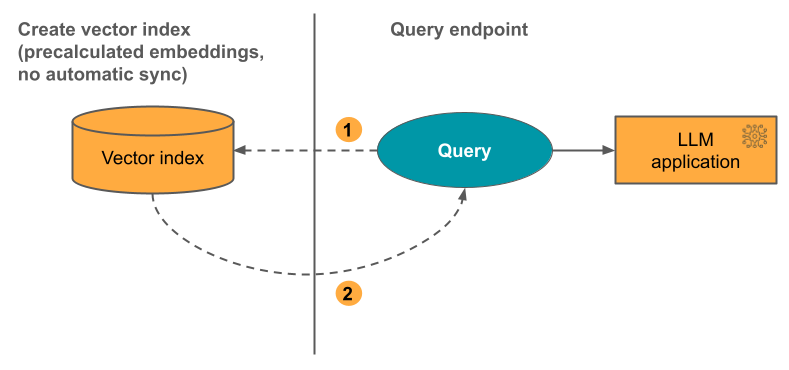
옵션 3: 직접 벡터 액세스 인덱스
이 옵션을 사용하면 포함 테이블이 변경될 때 REST API를 사용하여 인덱스를 수동으로 업데이트해야 합니다.
아래 다이어그램은 이 프로세스를 보여 줍니다.
옵션 4: 스토리지 최적화 엔드포인트의 전체 텍스트 검색 인덱스(베타)
이 옵션을 사용하면 열을 포함하지 않고 스토리지 최적화 엔드포인트에 델타 동기화 인덱스를 만듭니다. 인덱스는 벡터 포함 없이 BM25 점수 매기기를 사용하여 키워드 기반 전체 텍스트 검색을 지원합니다. 텍스트 데이터에서 정확한 용어, 식별자 또는 키워드를 검색하는 데 유용합니다.
비고
표준 및 스토리지 최적화 엔드포인트 모두에서 기존 벡터 검색 인덱스에 대한 키워드 검색을 수행하는 데 사용할 query_type="FULL_TEXT" 수도 있습니다. 이 옵션은 임베딩이 전혀 포함되지 않은 전용 인덱스를 만들기 위한 것입니다.
전용 전체 텍스트 검색 인덱스는 스토리지 최적화 엔드포인트에서만 사용할 수 있으며 트리거된 동기화 모드가 필요합니다. 지침 은 전체 텍스트 검색 인덱스 만들기(베타) 를 참조하세요.
엔드포인트 옵션
Mosaic AI Vector Search는 애플리케이션의 요구 사항을 충족하는 엔드포인트 구성을 선택할 수 있도록 다음 옵션을 제공합니다.
비고
스토리지 최적화 엔드포인트는 공개 미리 보기로 제공됩니다. 높은 QPS는 베타 버전이며 표준 엔드포인트에만 사용할 수 있습니다.
-
표준 엔드포인트의 용량은 768차원에서 3억 2천만 벡터입니다.
- 표준 엔드포인트를 사용하면 높은 QPS를 사용하여 높은 지속적인 처리량을 지원할 수 있습니다. QPS(베타)를 활용하여 엔드포인트 처리량을 확장하세요.
- 스토리지 최적화 엔드포인트는 더 큰 용량(768차원에서 10억 개 이상의 벡터)을 가지며 10~20배 더 빠른 인덱싱을 제공합니다. 스토리지 최적화 엔드포인트에 대한 쿼리의 대기 시간은 약 250msec로 약간 증가합니다. 이 옵션의 가격은 더 많은 수의 벡터에 최적화되어 있습니다. 가격 책정 세부 정보는 벡터 검색 가격 책정 페이지를 참조하세요. 벡터 검색 비용 관리에 대한 자세한 내용은 벡터 검색 비용 관리 가이드를 참조하세요.
엔드포인트를 만들 때 엔드포인트 유형을 지정합니다.
스토리지 최적화 엔드포인트 제한 사항도 참조하세요.
Mosaic AI 벡터 검색을 설정하는 방법
Mosaic AI Vector Search를 사용하려면 다음을 만들어야 합니다.
벡터 검색 엔드포인트입니다. 이 엔드포인트는 벡터 검색 인덱스 역할을 합니다. REST API 또는 SDK를 사용하여 엔드포인트를 쿼리하고 업데이트할 수 있습니다. 지침은 벡터 검색 엔드포인트 만들기를 참조하세요.
엔드포인트는 인덱스의 크기 또는 동시 요청 수를 지원하도록 자동으로 확장됩니다. 인덱스가 삭제되면 엔드포인트가 자동으로 축소됩니다.
벡터 검색 인덱스입니다. 벡터 검색 인덱스는 Delta 테이블에서 생성되며, 실시간 근사 최근접 이웃(ANN) 검색을 제공하도록 최적화되어 있습니다. 검색의 목표는 쿼리와 유사한 문서를 식별하는 것입니다. 벡터 검색 인덱스는 Unity 카탈로그 내에 존재하며, Unity 카탈로그에 의해 관리됩니다. 지침은 벡터 검색 인덱스 만들기를 참조하세요.
또한 Databricks가 임베딩을 컴퓨팅하도록 선택한 경우 미리 구성된 Foundation Model API 엔드포인트를 사용하거나 엔드포인트를 제공하는 모델을 만들어 원하는 임베딩 모델을 제공할 수 있습니다. 지침은 토큰당 종량제 모델 API 또는 엔드포인트 제공하는 기본 모델 만들기를 참조하세요.
엔드포인트를 제공하는 모델을 쿼리하려면 REST API 또는 Python SDK를 사용합니다. 쿼리는 델타 테이블의 모든 열을 기반으로 필터를 정의할 수 있습니다. 자세한 내용은 쿼리, API 참조 또는 Python SDK 참조 필터를 참조하세요.
요구 사항
- Unity 카탈로그가 활성화된 작업 영역.
- 서버리스 컴퓨팅을 사용하도록 설정했습니다. 지침은 서버리스 컴퓨팅 연결하기를 참조하세요.
- 표준 엔드포인트의 경우 원본 테이블에 변경 데이터 피드를 사용하도록 설정해야 합니다. Azure Databricks에서 Delta Lake 변경 데이터 피드 사용을 참조하세요.
- 벡터 검색 인덱스를 만들려면 인덱스를 만들 카탈로그 스키마에 대한 CREATE TABLE 권한이 있어야 합니다.
벡터 검색 엔드포인트를 만들고 관리하는 권한은 액세스 제어 목록을 사용하여 구성됩니다. 벡터 검색 엔드포인트 ACL을 참조 하세요.
데이터 보호 및 인증
Databricks는 데이터를 보호하기 위해 다음 보안 제어를 구현합니다.
- Mosaic AI Vector Search에 대한 모든 고객 요청은 논리적으로 격리되고 인증되며 권한이 부여됩니다.
- Mosaic AI Vector Search는 미사용 데이터(AES-256) 및 전송 중인 모든 데이터(TLS 1.2 이상)를 암호화합니다.
Mosaic AI Vector Search는 두 가지 인증 모드, 서비스 주체 및 PAT(개인 액세스 토큰)를 지원합니다. 프로덕션 애플리케이션의 경우 Databricks는 개인 액세스 토큰에 비해 쿼리당 성능이 최대 100msec 더 빨라질 수 있는 서비스 주체를 사용하는 것이 좋습니다.
서비스 주체 토큰입니다. 관리자는 서비스 주체 토큰을 생성하여 SDK 또는 API에 전달할 수 있습니다. 서비스 주체 사용하기를 참조하세요. 프로덕션 사용 사례의 경우 Databricks는 서비스 주체 토큰을 사용하는 것이 좋습니다.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )개인용 액세스 토큰입니다. 개인용 액세스 토큰을 사용하여 Mosaic AI Vector Search로 인증할 수 있습니다. 개인용 액세스 토큰 인증을 참고하세요. Notebook 환경에서 SDK를 사용하는 경우 SDK는 인증을 위해 PAT 토큰을 자동으로 생성합니다.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
CMK(고객 관리형 키)는 2024년 5월 8일 이후에 만든 엔드포인트에서 지원됩니다.
사용량 및 비용 모니터링
벡터 검색 인덱스 및 엔드포인트와 관련된 사용량 및 비용 모니터링에 대한 자세한 내용은 벡터 검색 비용 관리 가이드를 참조하세요.
예산 정책별로 사용량을 쿼리할 수도 있습니다. 벡터 검색 예산 정책을 참조하세요.
리소스 및 데이터 크기 제한
다음 표에는 벡터 검색 엔드포인트 및 인덱스에 대한 리소스 및 데이터 크기 제한이 요약되어 있습니다.
| Resource | 세분성 | 한계 |
|---|---|---|
| 벡터 검색 엔드포인트 | 작업 영역당 | 100 |
| 임베딩(델타 동기화 인덱스) | 표준 엔드포인트당 | ~ 768 포함 차원에서 320,000,000 1536 임베딩 차원에서 ~ 160,000,000 ~ 80,000,000 at 3072 임베딩 차원 (대략 선형적으로 확장) |
| 임베딩(직접 벡터 접근 인덱스) | 표준 엔드포인트당 | 768 포함 차원에서 ~ 2,000,000 |
| 임베딩(스토리지 최적화 엔드포인트) | 스토리지 최적화 엔드포인트당 | 임베딩 차원이 768일 때 ~10억 |
| 임베딩 차원 | 인덱스당 | 4096 |
| Indexes | 엔드포인트당 | 50 |
| 칼럼 | 인덱스당 | 50 |
| 칼럼 | 지원되는 형식: 바이트, 짧음, 정수, long, float, double, boolean, string, timestamp, date, array | |
| 메타데이터 필드 | 인덱스당 | 50 |
| 인덱스 이름 | 인덱스당 | 128자 |
다음 제한은 벡터 검색 인덱스의 생성 및 업데이트에 적용됩니다.
| Resource | 세분성 | 한계 |
|---|---|---|
| 델타 동기화 인덱스 행 크기 | 인덱스당 | 100KB |
| 델타 동기화 인덱스에 소스 열의 크기 포함 | 인덱스당 | 32764바이트 |
| Direct Vector 인덱스에 대한 대량 업서트 요청 크기 제한 | 인덱스당 | 10MB |
| 직접 벡터 색인에서 대량 삭제 요청 크기의 제한 | 인덱스당 | 10MB |
쿼리 API에 다음과 같은 제한이 적용됩니다.
| Resource | 세분성 | 한계 |
|---|---|---|
| 쿼리 텍스트 길이 | 쿼리당 | 32764자 |
| 하이브리드 검색을 사용하는 경우 토큰 | 쿼리당 | 1024단어 또는 2 바이트 문자 |
| 필터 조건 | 필터 조건별로 | 1024개 요소 |
| 반환되는 최대 결과 수(근사 최근접 검색) | 쿼리당 | 1만 |
| 반환된 최대 결과 수(하이브리드 키워드 유사성 검색) | 쿼리당 | 200 |
| 반환된 최대 결과 수(전체 텍스트 검색) | 쿼리당 | 200 |
| 응답 크기 | 쿼리당 | 10MB |
제한점
- 열 이름
_id은(는) 예약되어 있습니다. 소스 테이블에_id라는 열이 있을 경우, 벡터 검색 인덱스를 생성하기 전에 그 열의 이름을 변경하십시오. - 행 및 열 수준 권한은 지원되지 않습니다. 그러나 필터 API를 사용하여 고유한 애플리케이션 수준 ACL을 구현할 수 있습니다.
- 인덱스를 다른 작업 영역에 복제할 수 없습니다. Databricks SDK 또는 REST API를 사용하여 작업 영역 간 요청을 수행할 수 있습니다.
- 인덱스 용량은 인덱스 생성 시 원본 테이블 크기에 따라 프로비전됩니다. 작은 원본 테이블부터는 인덱스가 증가할 수 있는 양을 제한하고 용량이 소진될 수 있으므로 인덱스를 만들기 전에 원본 테이블의 크기를 예상 데이터 볼륨과 일치하도록 조정합니다.
스토리지 최적화 엔드포인트 제한 사항
이 섹션의 제한 사항은 스토리지 최적화 엔드포인트에만 적용됩니다. 스토리지 최적화 엔드포인트는 공개 미리 보기로 제공됩니다.
- 연속 동기화 모드는 지원되지 않습니다.
- 동기화할 열은 지원되지 않습니다.
- 포함 차원은 16으로 나눌 수 있어야 합니다.
- 증분 업데이트는 부분적으로 지원됩니다. 모든 동기화는 벡터 검색 인덱스의 일부를 다시 작성해야 합니다.
- 관리되는 인덱스의 경우 원본 행이 변경되지 않은 경우 이전에 계산된 임베딩이 다시 사용됩니다.
- 표준 엔드포인트에 비해 동기화에 필요한 시간이 상당히 단축될 것으로 예상해야 합니다. 임베딩 10억 개가 포함된 데이터셋은 8시간 안에 동기화를 완료해야 합니다. 데이터 세트가 작을수록 동기화하는 데 더 적은 시간이 소요됩니다.
- FedRAMP 규격 작업 영역은 지원되지 않습니다.
- CMK(고객 관리형 키)는 지원되지 않습니다.
- 관리되는 델타 동기화 인덱스용 사용자 지정 포함 모델을 사용하려면 사용자 지정 모델 및 외부 모델에 대한 AI 쿼리 미리 보기를 사용하도록 설정해야 합니다. 미리 보기를 사용하도록 설정하는 방법에 대한 자세한 내용은 Azure Databricks 미리 보기 관리를 참조하세요.
- 스토리지 최적화 엔드포인트는 768차원의 벡터 포함을 최대 10억 개까지 지원합니다. 대규모 사용 사례가 있는 경우 계정 팀에 문의하세요.