Databricks 앱 템플릿을 사용하여 첫 번째 AI 에이전트를 빌드하고 배포합니다. 이 자습서에서 수행하는 작업은 다음과 같습니다.
- Databricks Apps UI에서 에이전트를 빌드하고 배포합니다.
- 미리 빌드된 채팅 인터페이스를 사용하여 에이전트와 채팅합니다.
필수 조건
작업 영역에서 Databricks 앱을 사용하도록 설정합니다. Databricks Apps 작업 영역 및 개발 환경 설정을 참조하세요.
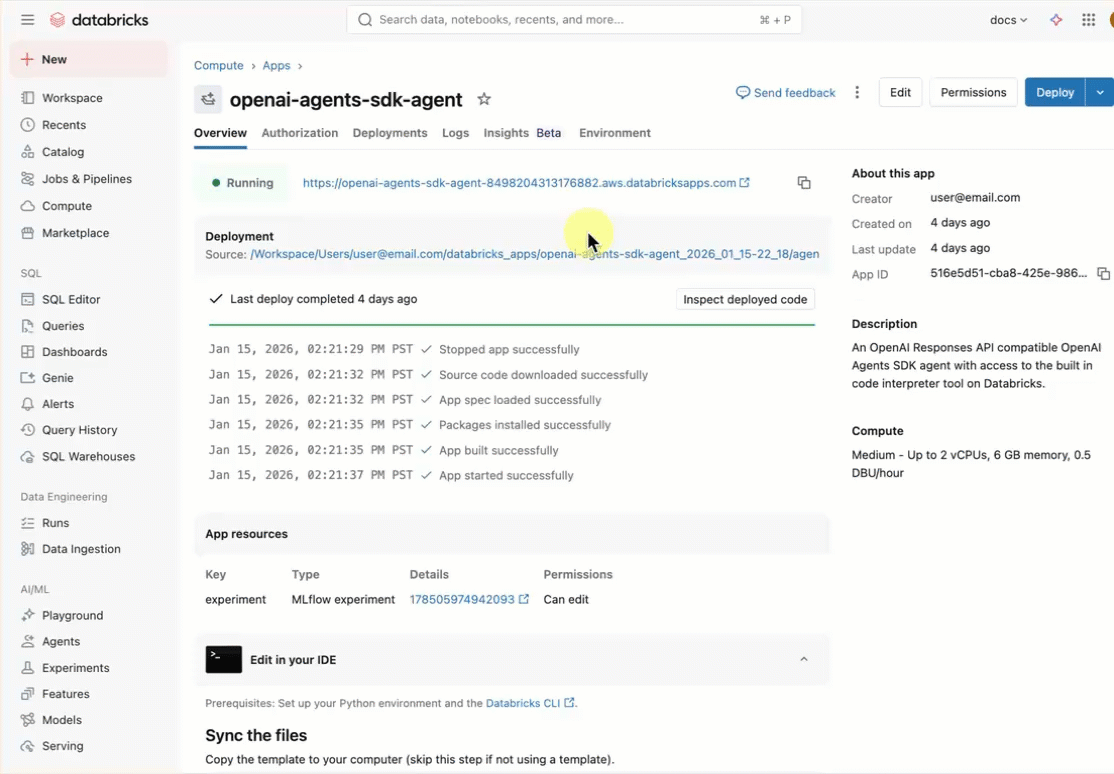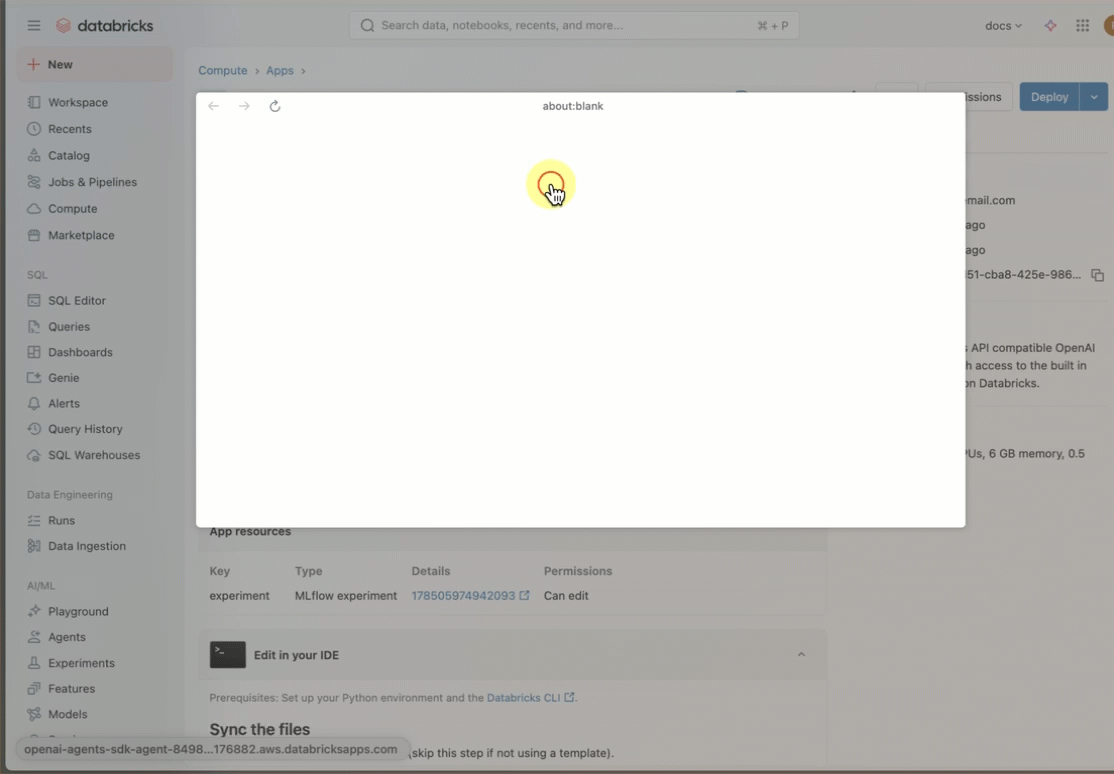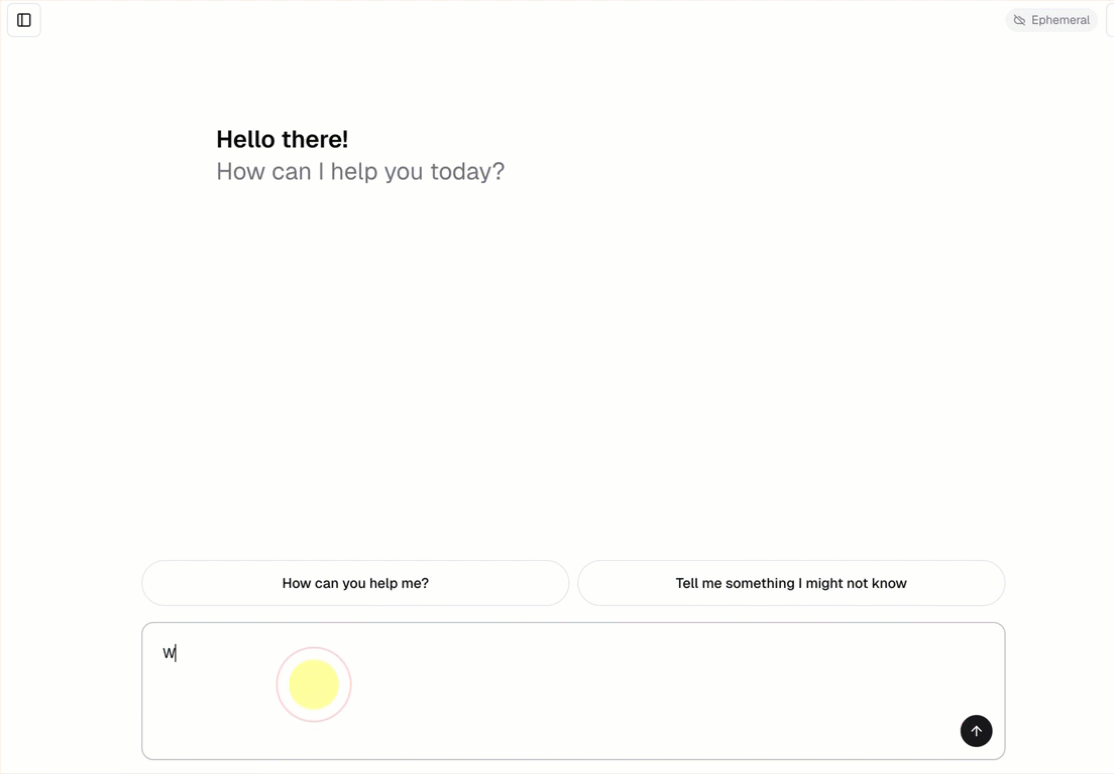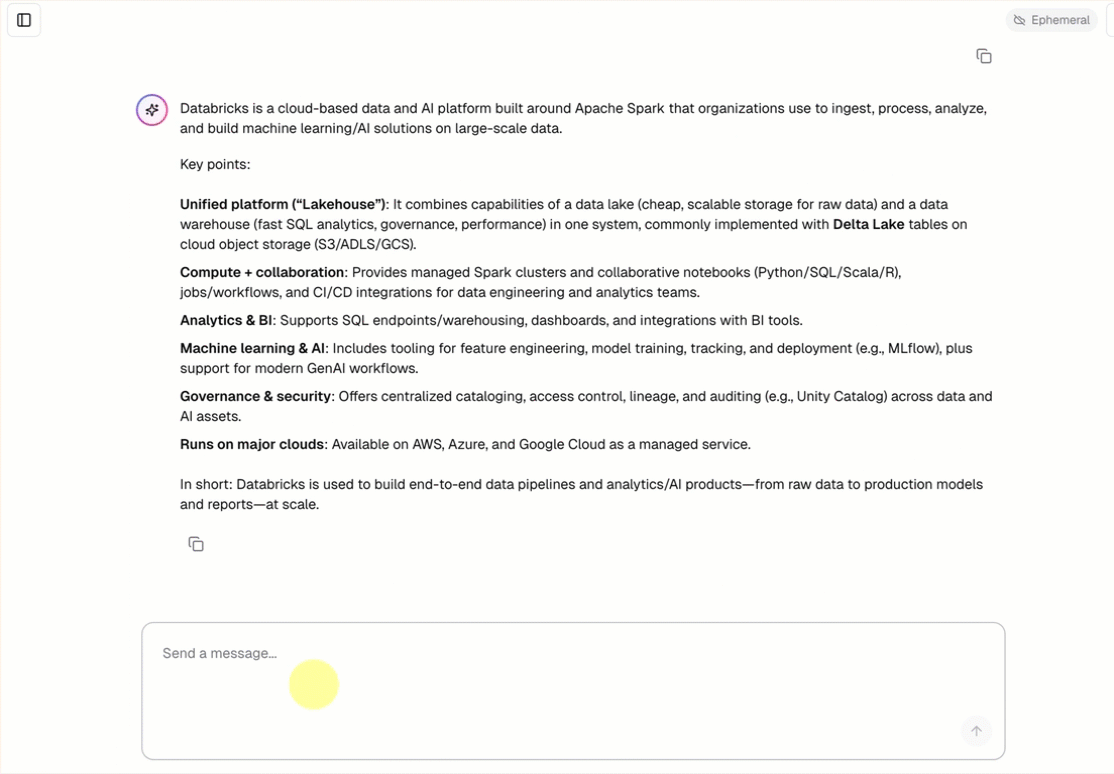
에이전트 템플릿 배포
Databricks 앱 템플릿 리포지토리에서 미리 빌드된 에이전트 템플릿을 사용하여 시작합니다.
이 자습서에서는 다음을 포함하는 템플릿을 agent-openai-agents-sdk 사용합니다.
- OpenAI 에이전트 SDK를 사용하여 만든 에이전트
- 대화형 REST API 및 대화형 채팅 UI를 사용하는 에이전트 애플리케이션의 시작 코드
- MLflow를 사용하여 에이전트를 평가하는 코드
작업 영역 UI를 사용하여 앱 템플릿을 설치합니다. 이렇게 하면 앱이 설치되고 작업 영역의 컴퓨팅 리소스에 배포됩니다.
Databricks 작업 영역에서 + 새>앱을 클릭합니다.
에이전트>에이전트 - OpenAI 에이전트 SDK를 클릭합니다.
이름으로
openai-agents-template새 MLflow 실험을 만들고 나머지 설정을 완료하여 템플릿을 설치합니다.앱을 만든 후 앱 URL을 클릭하여 채팅 UI를 엽니다.
에이전트 애플리케이션 이해
에이전트 템플릿은 다음 주요 구성 요소를 사용하여 프로덕션 준비 아키텍처를 보여 줍니다.
MLflow AgentServer: 기본 제공 추적 및 관찰성을 사용하여 에이전트 요청을 처리하는 비동기 FastAPI 서버입니다. AgentServer는 에이전트를 쿼리하기 위한 엔드포인트를 제공하고 /invocations 요청 라우팅, 로깅 및 오류 처리를 자동으로 관리합니다.
OpenAI 에이전트 SDK: 템플릿은 대화 관리 및 도구 오케스트레이션을 위한 에이전트 프레임워크로 OpenAI 에이전트 SDK를 사용합니다. 모든 프레임워크를 사용하여 에이전트를 작성할 수 있습니다. 핵심은 MLflow ResponsesAgent 인터페이스를 사용하여 에이전트를 감싸는 것입니다.
ResponsesAgent 인터페이스: 이 인터페이스는 에이전트가 다양한 프레임워크에서 작동하고 Databricks 도구와 통합되도록 합니다. OpenAI SDK, LangGraph, LangChain 또는 순수 Python을 사용하여 에이전트를 빌드한 다음, ResponsesAgent로 감싸 AI Playground, 에이전트 평가 및 Databricks Apps 배포에 자동으로 호환되게 하십시오.
MCP(모델 컨텍스트 프로토콜) 서버: 템플릿은 Databricks MCP 서버에 연결하여 도구 및 데이터 원본에 대한 에이전트에 액세스합니다. Databricks에서 MCP(모델 컨텍스트 프로토콜)를 참조하세요.

다음 단계
사용자 지정 에이전트 작성 방법 알아보기:AI 에이전트 작성 및 Databricks 앱에 배포