이 자습서에서는 Azure Databricks Notebook을 사용하여 SQL, Python, Scala 및 R을 사용하여 Unity 카탈로그에 저장된 샘플 데이터를 쿼리한 다음 Notebook에서 쿼리 결과를 시각화하는 방법을 안내합니다.
팁 (조언)
지니 코드(에이전트 모드)에게 다음을 수행하도록 지시합니다.
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
요구 사항
이 문서의 작업을 완료하려면 다음 요구 사항을 충족해야 합니다.
- 작업 영역에 Unity 카탈로그 가 활성화되어 있어야 합니다. Unity 카탈로그를 시작하는 방법에 대한 자세한 내용은 Unity 카탈로그 시작을 참조하세요.
- 기존 컴퓨팅 리소스를 사용하거나 새 컴퓨팅 리소스를 만들 수 있는 권한이 있어야 합니다. 컴퓨팅을 참조하거나 Databricks 관리자를 참조하세요.
1단계: 새 Notebook 만들기
작업 영역에서 전자 필기장을 만들려면 사이드바에서 ![]() 새로 만들기를 클릭한 다음 전자 필기장을 클릭합니다. 작업 영역에서 빈 전자 필기장이 열립니다.
새로 만들기를 클릭한 다음 전자 필기장을 클릭합니다. 작업 영역에서 빈 전자 필기장이 열립니다.
Notebook을 만들고 관리하는 방법에 대한 자세한 내용은 Notebook 관리를 참조하세요.
2단계: 테이블 쿼리
선택한 언어를 사용하여 Unity 카탈로그의 samples.nyctaxi.trips 테이블을 쿼리합니다.
다음 코드를 복사하고 새로운 빈 Notebook 셀에 붙여넣습니다. 이 코드는 Unity 카탈로그에서
samples.nyctaxi.trips테이블을 쿼리한 결과를 표시합니다.SQL
SELECT * FROM samples.nyctaxi.trips파이썬
display(spark.read.table("samples.nyctaxi.trips"))스칼라
display(spark.read.table("samples.nyctaxi.trips"))R 프로그래밍 언어
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Shift+Enter키를 눌러 셀을 실행하고 다음 셀로 이동합니다.쿼리 결과가 Notebook에 표시됩니다.
3단계: 데이터 표시
여정 거리별 평균 요금 금액을 픽업 우편 번호로 그룹화하여 표시합니다.
테이블 탭 옆의 +을 클릭한 다음 시각화를 클릭합니다.
시각화 편집기가 표시됩니다.
시각화 유형 드롭다운에서 막대가 선택되어 있는지 확인합니다.
fare_amount선택합니다.trip_distance선택합니다.집계 유형으로
Average선택합니다.열을 기준으로
그룹에서 을 선택합니다. 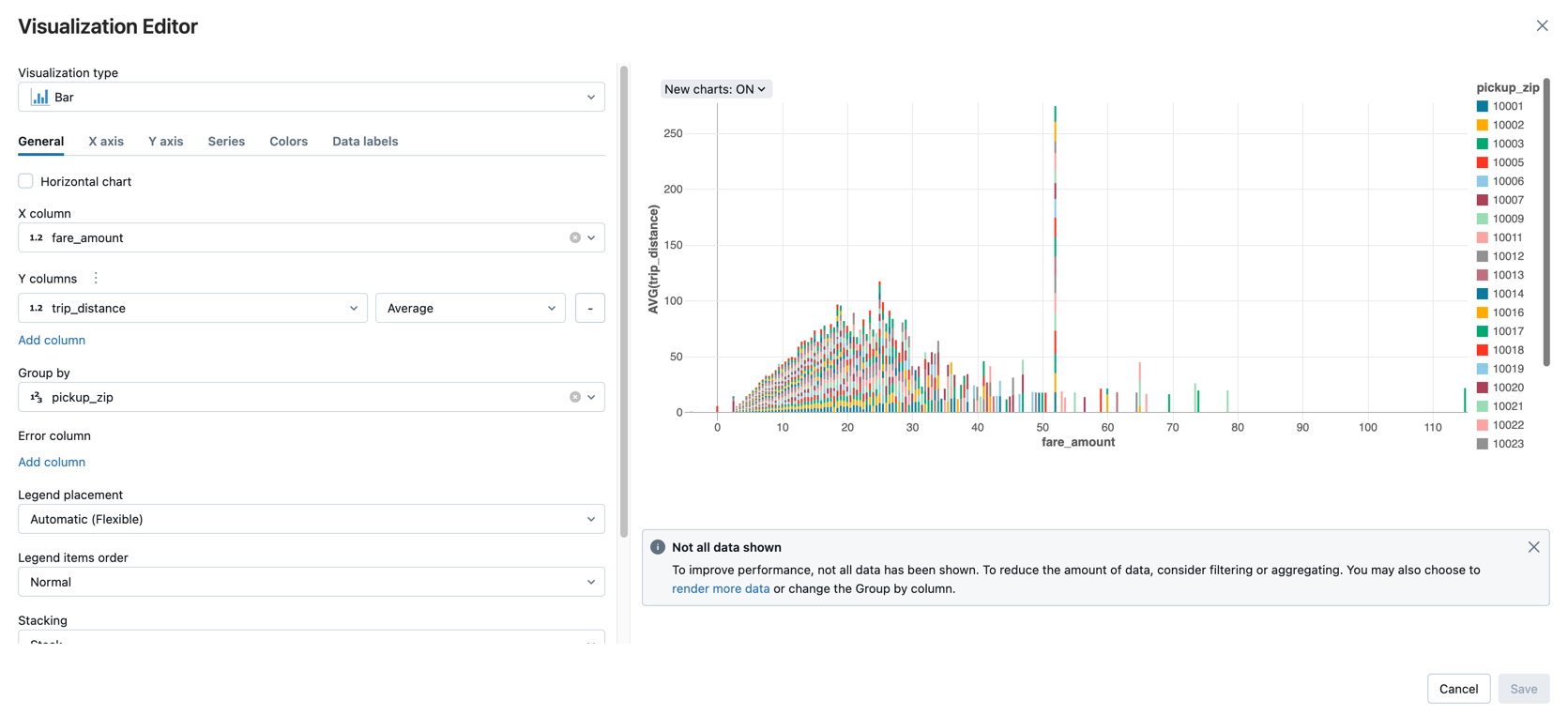
저장을 클릭합니다.
다음 단계
- CSV 파일의 데이터를 Unity 카탈로그에 추가하고 데이터를 시각화하는 방법에 대한 자세한 내용은 자습서: Notebook에서 CSV 데이터 가져오기 및 시각화를 참조하세요.
- Apache Spark를 사용하여 Databricks에 데이터를 로드하는 방법을 알아보려면 자습서: Apache Spark DataFrames를 사용하여 데이터 로드 및 변환을 참조하세요.
- Databricks로 데이터를 수집하는 방법에 대한 자세한 내용은 Lakeflow Connect의 표준 커넥터를 참조하세요.
- Databricks를 사용하여 데이터를 쿼리하는 방법에 대한 자세한 내용은 쿼리 데이터를 참조하세요.
- 시각화에 대한 자세한 내용은 Databricks Notebook 및 SQL 편집기에서 시각화를 참조하세요.
- EDA(예비 데이터 분석) 기술에 대한 자세한 내용은 자습서: Databricks Notebook을 사용하는 EDA 기법을 참조하세요.