작업 영역 기능 저장소의 기능 작업
참고 항목
이 설명서에서는 작업 영역 기능 저장소에 대해 설명합니다. Databricks는 Unity 카탈로그에서 기능 엔지니어링을 사용하는 것이 좋습니다. 작업 영역 기능 저장소는 나중에 더 이상 사용되지 않습니다.
이 페이지에서는 작업 영역 기능 저장소에서 기능 테이블을 만들고 사용하는 방법을 설명합니다.
참고 항목
작업 영역이 Unity 카탈로그에 사용하도록 설정된 경우 기본 키가 있는 Unity 카탈로그에서 관리하는 모든 테이블은 자동으로 모델 학습 및 유추에 사용할 수 있는 기능 테이블입니다. 보안, 계보, 태그 지정 및 작업 영역 간 액세스와 같은 모든 Unity 카탈로그 기능은 기능 테이블에서 자동으로 사용할 수 있습니다. Unity 카탈로그 사용 작업 영역에서 기능 테이블을 사용하는 방법에 대한 자세한 내용은 Unity 카탈로그의 기능 엔지니어링을 참조하세요.
기능 계보 및 새로 고침 추적에 대한 자세한 내용은 기능 검색 및 기능 계보 추적을 참조하세요.
참고 항목
데이터베이스 및 기능 테이블 이름은 영숫자 문자와 밑줄(_)만 포함할 수 있습니다.
기능 테이블용 데이터베이스 만들기
기능 테이블을 만들기 전에 이를 저장할 데이터베이스를 만들어야 합니다.
%sql CREATE DATABASE IF NOT EXISTS <database-name>
기능 테이블은 델타 테이블로 저장됩니다. create_table(Feature Store 클라이언트 v0.3.6 이상) 또는 create_feature_table(v0.3.5 이하)을 사용하여 기능 테이블을 만들 때 데이터베이스 이름을 지정해야 합니다. 예를 들어 이 인수는 recommender_system 데이터베이스에 customer_features라는 델타 테이블을 만듭니다.
name='recommender_system.customer_features'
기능 테이블을 온라인 저장소에 게시하는 경우 기본 테이블과 데이터베이스 이름은 테이블을 만들 때 지정한 이름입니다. publish_table 메서드를 사용하여 다른 이름을 지정할 수 있습니다.
Databricks 기능 저장소 UI에는 다른 메타데이터와 함께 온라인 저장소에 있는 테이블 및 데이터베이스의 이름이 표시됩니다.
Databricks 기능 저장소에서 기능 테이블 만들기
참고 항목
또한 기존 델타 테이블을 기능 테이블로 등록할 수 있습니다. 기존 델타 테이블을 기능 테이블로 등록을 참조하세요.
기능 테이블을 만드는 기본 단계는 다음과 같습니다.
- Python 함수를 작성하여 기능을 계산합니다. 각 함수의 출력은 고유한 기본 키가 있는 Apache Spark DataFrame이어야 합니다. 기본 키는 하나 이상의 열로 구성할 수 있습니다.
FeatureStoreClient를 인스턴스화하고create_table(v0.3.6 이상) 또는create_feature_table(v0.3.5 이하)을 사용하여 기능 테이블을 만듭니다.write_table을 사용하여 기능 테이블을 채웁니다.
다음 예제에서 사용되는 명령 및 매개 변수에 대한 자세한 내용은 기능 저장소 Python API 참조를 참조하세요.
V0.3.6 이상
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
name='recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_table call
# customer_feature_table = fs.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
V0.3.5 이하
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
기존 델타 테이블을 기능 테이블로 등록
v0.3.8 이상에서는 기존 Delta 테이블을 기능 테이블로 등록할 수 있습니다. 델타 테이블은 메타스토어에 있어야 합니다.
참고 항목
등록된 기능 테이블을 업데이트하려면 기능 저장소 Python API를 사용해야 합니다.
fs.register_table(
delta_table='recommender.customer_features',
primary_keys='customer_id',
description='Customer features'
)
기능 테이블에 대한 액세스 제어
기능 테이블에 대한 액세스 제어를 참조하세요.
기능 테이블 업데이트
새 기능을 추가하거나 기본 키를 기준으로 특정 행을 수정하여 기능 테이블을 업데이트할 수 있습니다.
다음 기능 테이블 메타데이터는 업데이트할 수 없습니다.
- 기본 키
- 파티션 키
- 기존 기능의 이름 또는 형식
기존 기능 테이블에 새 기능 추가
다음의 두 가지 방법 중 하나로 기존 기능 테이블에 새 기능을 추가할 수 있습니다.
- 기존 기능 계산 함수를 업데이트하고 반환된 DataFrame을 사용하여
write_table을 실행합니다. 그러면 기능 테이블 스키마가 업데이트되고 기본 키를 기준으로 새 기능 값이 병합됩니다. - 새 기능 계산 함수를 만들어 새 기능 값을 계산합니다. 이 새 계산 함수에서 반환된 DataFrame에는 기능 테이블의 기본 키와 파티션 키(정의된 경우)가 포함되어야 합니다. 기본 키를 사용하여 기존 기능 테이블에 새 기능을 쓸 수 있도록 DataFrame을 사용해
write_table을 실행합니다.
기능 테이블의 특정 행만 업데이트
write_table에서 mode = "merge"를 사용합니다. write_table 호출에서 전송된 DataFrame에 기본 키가 없는 행은 변경되지 않은 상태로 유지됩니다.
fs.write_table(
name='recommender.customer_features',
df = customer_features_df,
mode = 'merge'
)
기능 테이블을 업데이트하는 작업 예약
기능 테이블의 기능에 항상 최신 값이 있는지 확인하기 위해 Databricks에서 정기적으로(예: 매일) 기능 테이블을 업데이트하기 위해 Notebook을 실행하는 작업을 만들 것을 권장합니다. 예약되지 않은 작업을 이미 만든 경우 예약된 작업으로 변환하여 기능 값이 항상 최신 상태인지 확인할 수 있습니다.
기능 테이블을 업데이트하는 코드에서는 다음 예제와 같이 mode='merge'를 사용합니다.
fs = FeatureStoreClient()
customer_features_df = compute_customer_features(data)
fs.write_table(
df=customer_features_df,
name='recommender_system.customer_features',
mode='merge'
)
과거 일일 기능 값 저장
복합 기본 키를 사용하여 기능 테이블을 정의합니다. 기본 키에 날짜를 포함합니다. 예를 들어 store_purchases 기능 테이블의 경우 복합 기본 키(date, user_id)와 파티션 키(date)를 사용해 효과적으로 읽을 수 있습니다.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
그러면 date 기능 테이블 필터링에서 관심 기간까지 읽을 코드를 만들 수 있습니다.
인수를 사용하여 timestamp_keys 열을 타임스탬프 키로 지정하여 date 시계열 기능 테이블을 만들 수도 있습니다.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
timestamp_keys=['date'],
schema=customer_features_df.schema,
description='Customer timeseries features'
)
이렇게 하면 사용 create_training_set 하거나 score_batch사용할 때 지정 시간 조회를 사용할 수 있습니다. 시스템은 지정한 대로 타임스탬프 조인을 timestamp_lookup_key 수행합니다.
기능 테이블을 최신 상태로 유지하려면 기능을 쓰거나 새로운 기능 값을 기능 테이블에 스트리밍하도록 정기적으로 예약된 작업을 설정합니다.
기능을 업데이트하는 스트리밍 기능 계산 파이프라인 만들기
스트리밍 기능 계산 파이프라인을 만들려면 DataFrame 스트리밍을 write_table에 인수로 전달합니다. 이 메서드는 개체를 StreamingQuery 반환합니다.
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass # not shown
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fs.write_table(
df=stream_df,
name='recommender_system.customer_features',
mode='merge'
)
기능 테이블에서 읽기
read_table을 사용하여 기능 값을 읽습니다.
fs = feature_store.FeatureStoreClient()
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
기능 테이블 검색 및 찾아보기
기능 저장소 UI를 사용하여 기능 테이블을 검색하거나 찾아봅니다.
사이드바에서 Machine Learning > 기능 저장소를 선택하여 기능 저장소 UI를 표시합니다.
검색 상자에 기능 테이블, 기능 또는 기능 계산에 사용되는 데이터 원본의 이름 중 일부 또는 전부를 입력합니다. 태그의 키 또는 값 중 일부 또는 전부를 입력할 수도 있습니다. 검색 텍스트는 대/소문자를 구분하지 않습니다.

기능 테이블 메타데이터 가져오기
기능 테이블 메타데이터를 가져올 수 있는 API는 사용 중인 Databricks 런타임 버전에 따라 다릅니다. v0.3.6 이상에서는 get_table을 사용합니다. v0.3.5 이하에서는 get_feature_table을 사용합니다.
# this example works with v0.3.6 and above
# for v0.3.5, use `get_feature_table`
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.get_table("feature_store_example.user_feature_table")
기능 테이블 태그 사용
태그는 기능 테이블을 검색하는 데 사용하고 만들 수 있는 키-값 쌍입니다. 기능 저장소 UI 또는 기능 저장소 Python API를 사용하여 태그를 만들고, 편집하고, 삭제할 수 있습니다.
UI에서 기능 테이블 태그 사용
기능 저장소 UI를 사용하여 기능 테이블을 검색하거나 찾아봅니다. UI에 액세스하려면 사이드바에서 Machine Learning > 기능 저장소를 선택합니다.
기능 저장소 UI를 사용하여 태그 추가
아직 열려 있지 않은 경우 클릭합니다
 . 태그 테이블이 나타납니다.
. 태그 테이블이 나타납니다.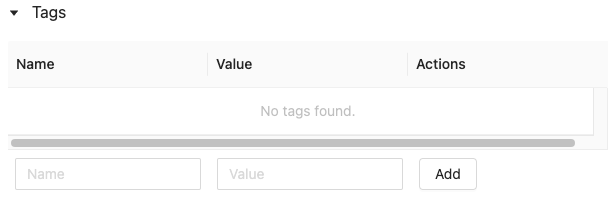
이름 및 값 필드를 클릭하고 태그의 키와 값을 입력합니다.
추가를 클릭합니다.
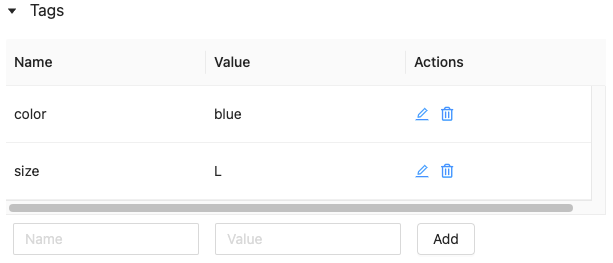
기능 저장소 UI를 사용하여 태그 편집 또는 삭제
기존 태그를 편집하거나 삭제하려면 작업 열에 있는 아이콘을 사용합니다.
기능 저장소 Python API를 사용하여 기능 테이블 태그 작업
v0.4.1 이상을 실행하는 클러스터에서 Feature Store Python API를 사용하여 태그를 만들고, 편집하고, 삭제할 수 있습니다.
요구 사항
Feature Store 클라이언트 v0.4.1 이상
기능 저장소 Python API를 사용하여 태그가 있는 기능 테이블 만들기
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
...
)
기능 저장소 Python API를 사용하여 태그 추가, 업데이트 및 삭제
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Upsert a tag
fs.set_feature_table_tag(table_name="my_table", key="quality", value="gold")
# Delete a tag
fs.delete_feature_table_tag(table_name="my_table", key="quality")
기능 테이블에 대한 데이터 원본 업데이트
기능 저장소는 기능을 컴퓨팅하는 데 사용되는 데이터 원본을 자동으로 추적합니다. 기능 저장소 Python API를 사용하여 데이터 원본을 수동으로 업데이트할 수도 있습니다.
요구 사항
Feature Store 클라이언트 v0.5.0 이상
기능 저장소 Python API를 사용하여 데이터 원본 추가
다음은 몇 가지 예제 명령입니다. 자세한 내용은 API 설명서를 참조하세요.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Use `source_type="table"` to add a table in the metastore as data source.
fs.add_data_sources(feature_table_name="clicks", data_sources="user_info.clicks", source_type="table")
# Use `source_type="path"` to add a data source in path format.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="dbfs:/FileStore/user_metrics.json", source_type="path")
# Use `source_type="custom"` if the source is not a table or a path.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="user_metrics.txt", source_type="custom")
기능 저장소 Python API를 사용하여 기능 테이블 삭제
자세한 내용은 API 설명서를 참조하세요.
참고 항목
다음 명령은 원본 이름과 일치하는 모든 형식("테이블", "경로" 및 "사용자 지정")의 데이터 원본을 삭제합니다.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.delete_data_sources(feature_table_name="clicks", sources_names="user_info.clicks")
기능 테이블 삭제
기능 저장소 UI 또는 기능 저장소 Python API를 사용하여 기능 테이블을 삭제할 수 있습니다.
참고 항목
- 기능 테이블을 삭제하면 업스트림 프로듀서 및 다운스트림 소비자(모델, 엔드포인트, 예약된 작업)에서 예기치 않은 오류가 발생할 수 있습니다. 클라우드 공급자를 사용하여 게시된 온라인 스토어를 삭제해야 합니다.
- API를 사용하여 기능 테이블을 삭제하면 기본 Delta 테이블도 삭제됩니다. UI에서 기능 테이블을 삭제하는 경우 기본 Delta 테이블을 별도로 삭제해야 합니다.
UI를 사용하여 기능 테이블 삭제
기능 테이블 페이지에서 기능 테이블 이름 오른쪽을 클릭하고
 삭제를 선택합니다. 기능 테이블에 대한 CAN MANAGE 권한이 없는 경우 이 옵션이 표시되지 않습니다.
삭제를 선택합니다. 기능 테이블에 대한 CAN MANAGE 권한이 없는 경우 이 옵션이 표시되지 않습니다.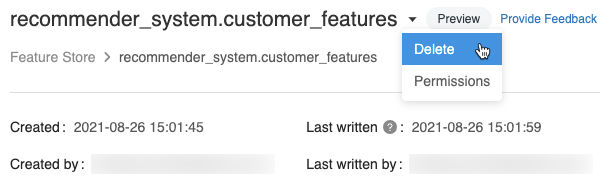
기능 테이블 삭제 대화 상자에서 삭제를 클릭하여 확인합니다.
기본 델타 테이블도 삭제하려면 Notebook에서 다음 명령을 실행합니다.
%sql DROP TABLE IF EXISTS <feature-table-name>;
기능 저장소 Python API를 사용하여 기능 테이블 삭제
기능 저장소 클라이언트 v0.4.1 이상에서 drop_table을 사용하여 기능 테이블을 삭제할 수 있습니다. drop_table을(를) 사용하여 테이블을 삭제하면 기본 Delta 테이블도 삭제됩니다.
fs.drop_table(
name='recommender_system.customer_features'
)