HorovodRunner: Horovod를 사용한 분산 딥 러닝
Important
Horovod 및 HorovodRunner는 이제 더 이상 사용되지 않습니다. 15.4 LTS ML 이후 릴리스에는 이 패키지가 미리 설치되어 있지 않습니다. 분산 딥 러닝의 경우 Databricks는 PyTorch와 함께 분산 학습에 TorchDistributor를 사용하거나 TensorFlow를 사용한 분산 학습을 위해 tf.distribute.Strategy API를 사용하는 것이 좋습니다.
HorovodRunner를 사용하여 기계 학습 모델의 분산 학습을 수행하여 Azure Databricks에서 Spark 작업으로 Horovod 학습 작업을 시작하는 방법을 알아봅니다.
HorovodRunner란?
HorovodRunner는 Horovod 프레임워크를 사용하여 Azure Databricks에서 분산 딥 러닝 워크로드를 실행하는 일반적인 API입니다. Horovod를 Spark의 장벽 모드와 통합함으로써 Azure Databricks는 Spark에서 장기 실행 딥 러닝 학습 작업에 더 높은 안정성을 제공할 수 있습니다. HorovodRunner는 Horovod 후크가 있는 딥 러닝 학습 코드를 포함하는 Python 메서드를 사용합니다. HorovodRunner는 드라이버의 메서드를 선택해 Spark 작업자에게 배포합니다. Horovod MPI 작업은 장벽 실행 모드를 사용하여 Spark 작업으로 포함됩니다. 첫 번째 실행기는 BarrierTaskContext를 사용하여 모든 작업 실행기의 IP 주소를 수집하고 mpirun를 사용하여 Horovod 작업을 트리거합니다. 각 Python MPI 프로세스는 절인 사용자 프로그램을 로드하고, 역직렬화하고, 실행합니다.
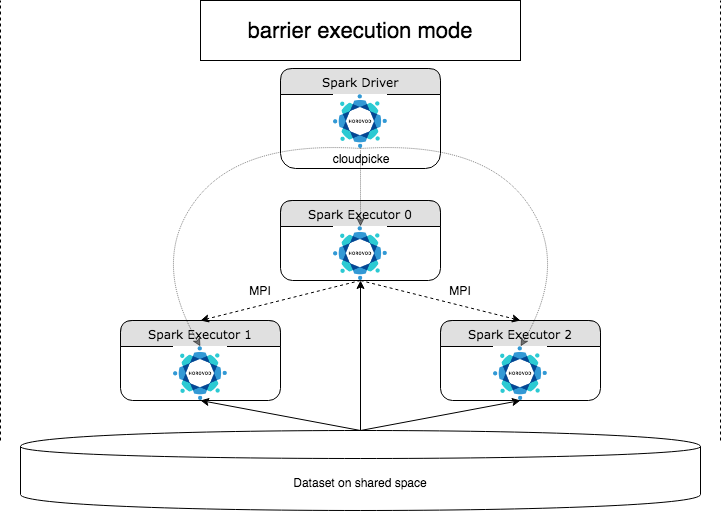
HorovodRunner를 사용하여 배포된 학습
HorovodRunner를 사용하면 Spark 작업으로 Horovod 학습 작업을 시작할 수 있습니다. HorovodRunner API는 테이블에 표시된 메서드를 지원합니다. 자세한 내용은 HorovodRunner API 설명서를 참조하세요.
| 메서드 및 서명 | 설명 |
|---|---|
init(self, np) |
HorovodRunner의 인스턴스를 만듭니다. |
run(self, main, **kwargs) |
main(**kwargs)를 호출하는 Horovod 학습 작업을 실행합니다. main 함수와 키워드 인수는 cloudpickle을 사용하여 직렬화되고 클러스터 작업자에게 배포됩니다. |
HorovodRunner를 사용하여 분산 학습 프로그램을 개발하는 일반적인 방법은 다음과 같습니다.
- 노드 수로 초기화된
HorovodRunner인스턴스를 만듭니다. - Horovod 사용법에 설명된 메서드에 따라 Horovod 학습 메서드를 정의하여 메서드 내에 import 문을 추가해야 합니다.
- 학습 메서드를
HorovodRunner인스턴스에 전달합니다.
예시:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
n 하위 프로세서를 사용하는 드라이버에서만 HorovodRunner를 실행하려면 hr = HorovodRunner(np=-n)를 사용합니다. 예를 들어 드라이버 노드에 4개의 GPU가 있는 경우 n에서 4까지 선택할 수 있습니다. 매개 변수 np에 대한 자세한 내용은 HorovodRunner API 설명서를 참조하세요. 하위 프로세스당 하나의 GPU를 고정하는 방법에 대한 자세한 내용은 Horovod 사용 가이드를 참조하세요.
일반적인 오류는 TensorFlow 개체를 찾거나 pickle일 수 없다는 것입니다. 라이브러리 가져오기 문이 다른 실행기에 배포되지 않는 경우에 발생합니다. 이 문제를 방지하려면 Horovod 학습 메서드의 맨 위와 Horovod 학습 메서드에서 호출된 다른 사용자 정의 함수 내부에 모든 import 문(예: import tensorflow as tf)을 포함합니다.
Horovod 타임라인을 사용한 Horovod 학습 기록
Horovod에는 Horovod 타임라인이라고 하는 활동의 타임라인을 기록할 수 있습니다.
Important
Horovod 타임라인은 성능에 큰 영향을 줍니다. Horovod 타임라인을 사용하도록 설정하면 Inception3 처리량이 ~40%까지 감소할 수 있습니다. HorovodRunner 작업 속도를 높이기 위해 Horovod 타임라인을 사용하지 마세요.
학습이 진행되는 동안에는 Horovod 타임라인을 볼 수 없습니다.
Horovod 타임라인을 기록하려면 HOROVOD_TIMELINE 환경 변수를 타임라인 파일을 저장할 위치로 설정합니다. Databricks는 타임라인 파일을 쉽게 검색할 수 있도록 공유 스토리지의 위치를 사용하는 것이 좋습니다. 예를 들어 다음과 같이 DBFS 로컬 파일 API를 사용할 수 있습니다.
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
그런 다음, 학습 함수의 시작 및 끝에 타임라인 특정 코드를 추가합니다. 다음 예제 Notebook에는 학습 진행률을 보기 위한 해결 방법으로 사용할 수 있는 예제 코드가 포함되어 있습니다.
Horovod 타임라인 예제 Notebook
타임라인 파일을 다운로드하려면 Databricks CLI를 사용한 다음 Chrome 브라우저의 chrome://tracing 기능을 사용하여 볼 수 있습니다. 예시:
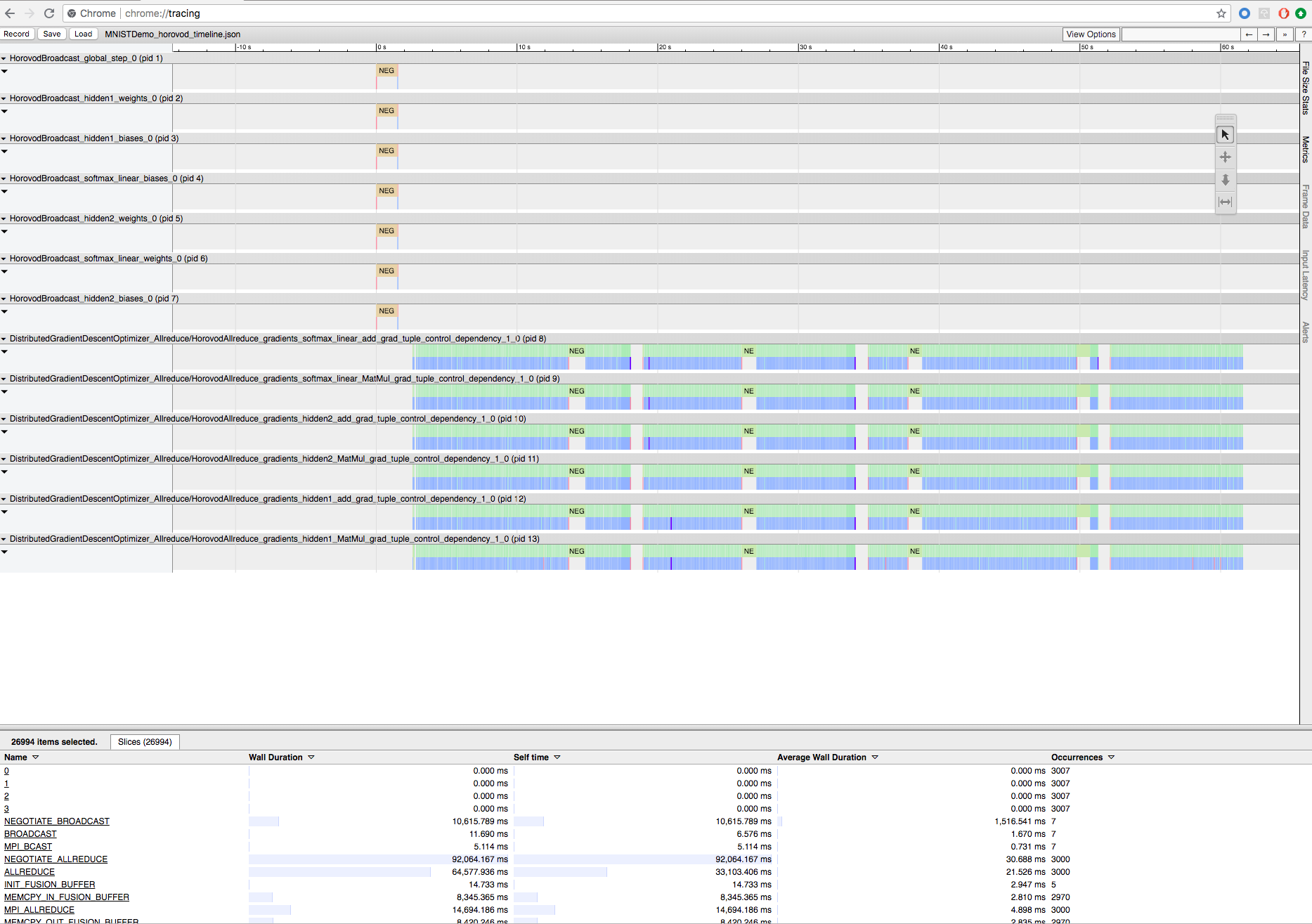
개발 워크플로
다음은 단일 노드 딥 러닝 코드를 분산 학습으로 마이그레이션하는 일반적인 단계입니다. 예제: 이 섹션의 HorovodRunner를 사용하여 분산된 딥 러닝으로 마이그레이션은 이러한 단계를 보여 줍니다.
- 단일 노드 코드 준비: TensorFlow, Keras 또는 PyTorch를 사용하여 단일 노드 코드를 준비하고 테스트합니다.
- Horovod로 마이그레이션: Horovod 사용법의 지침에 따라 Horovod를 사용하여 코드를 마이그레이션하고 드라이버에서 테스트합니다.
hvd.init()를 추가하여 Horovod를 초기화합니다.config.gpu_options.visible_device_list를 사용하여 이 프로세스에서 사용할 서버 GPU를 고정합니다. 프로세스당 하나의 GPU로 구성된 일반적인 설정에서는 로컬 순위로 설정할 수 있습니다. 이 경우 서버의 첫 번째 프로세스에는 첫 번째 GPU가 할당되고, 두 번째 프로세스에는 두 번째 GPU가 할당되는 식입니다.- 데이터 세트의 분할된 데이터베이스를 포함합니다. 이 데이터 세트 연산자는 각 작업자가 고유한 하위 집합을 읽을 수 있으므로 분산 학습을 실행할 때 매우 유용합니다.
- 작업자 수에 따라 학습률을 조정합니다. 동기 분산 학습의 유효 일괄 처리 크기는 작업자 수에 따라 조정됩니다. 학습 속도를 높이면 배치 크기가 증가합니다.
- 최적화 프로그램을
hvd.DistributedOptimizer에 래핑합니다. 분산 최적화 프로그램은 원래 최적화 프로그램에서 그라데이션 계산을 위임하고, allreduce 또는 allgather를 사용하여 그라데이션을 평균화한 다음, 평균 그라데이션을 적용합니다. hvd.BroadcastGlobalVariablesHook(0)를 추가하여 초기 변수 상태를 순위 0에서 다른 모든 프로세스로 브로드캐스트합니다. 학습이 임의의 가중치를 사용하여 시작되거나 검사점에서 복원되는 경우 모든 작업자의 일관된 초기화를 보장하는 데 필요합니다. 또는MonitoredTrainingSession을 사용하지 않는 경우 전역 변수가 초기화된 후hvd.broadcast_global_variables작업을 실행할 수 있습니다.- 다른 작업자가 검사점을 손상시키지 않도록 작업자 0에만 검사점이 저장되도록 코드를 수정합니다.
- HorovodRunner로 마이그레이션: HorovodRunner는 Python 함수를 호출하여 Horovod 학습 작업을 실행합니다. 주 학습 프로시저를 단일 Python 함수로 래핑해야 합니다. 그런 다음, 로컬 모드 및 분산 모드에서 HorovodRunner를 테스트할 수 있습니다.
딥 러닝 라이브러리 업데이트
TensorFlow, Keras 또는 PyTorch를 업그레이드하거나 다운그레이드하는 경우 새로 설치된 라이브러리에 대해 컴파일되도록 Horovod를 다시 설치해야 합니다. 예를 들어 TensorFlow를 업그레이드하려는 경우 Databricks는 TensorFlow 설치 지침의 init 스크립트를 사용하고 다음 TensorFlow 특정 Horovod 설치 코드를 끝에 추가하는 것이 좋습니다. PyTorch 및 기타 라이브러리 업그레이드 또는 다운그레이드와 같은 다양한 조합으로 작업하려면 Horovod 설치 지침을 참조하세요.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
예제: HorovodRunner를 사용하여 분산형 딥 러닝으로 마이그레이션
MNIST 데이터 세트를 기반으로 하는 다음 예제에서는 HorovodRunner를 사용하여 단일 노드 딥 러닝 프로그램을 분산 딥 러닝으로 마이그레이션하는 방법을 보여 줍니다.
제한 사항
- 작업 영역 파일로 작업할 때 HorovodRunner는
np이 1보다 크고 Notebook이 다른 상대 파일에서 가져오는 경우 작동하지 않습니다.HorovodRunner대신 horovod.spark를 사용하는 것이 좋습니다. WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer와 같은 오류가 발생하면 클러스터의 노드 간 네트워크 통신에 문제가 있음을 나타냅니다. 이 오류를 해결하려면 학습 코드에 다음 코드 조각을 추가하여 기본 네트워크 인터페이스를 사용합니다.
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"