Databricks 자동 로깅
Databricks 자동 로깅은 MLflow 자동 로깅을 확장하여 Azure Databricks에서 기계 학습 교육 세션에 대한 자동 실험 추적을 제공하는 코드 없는 솔루션입니다.
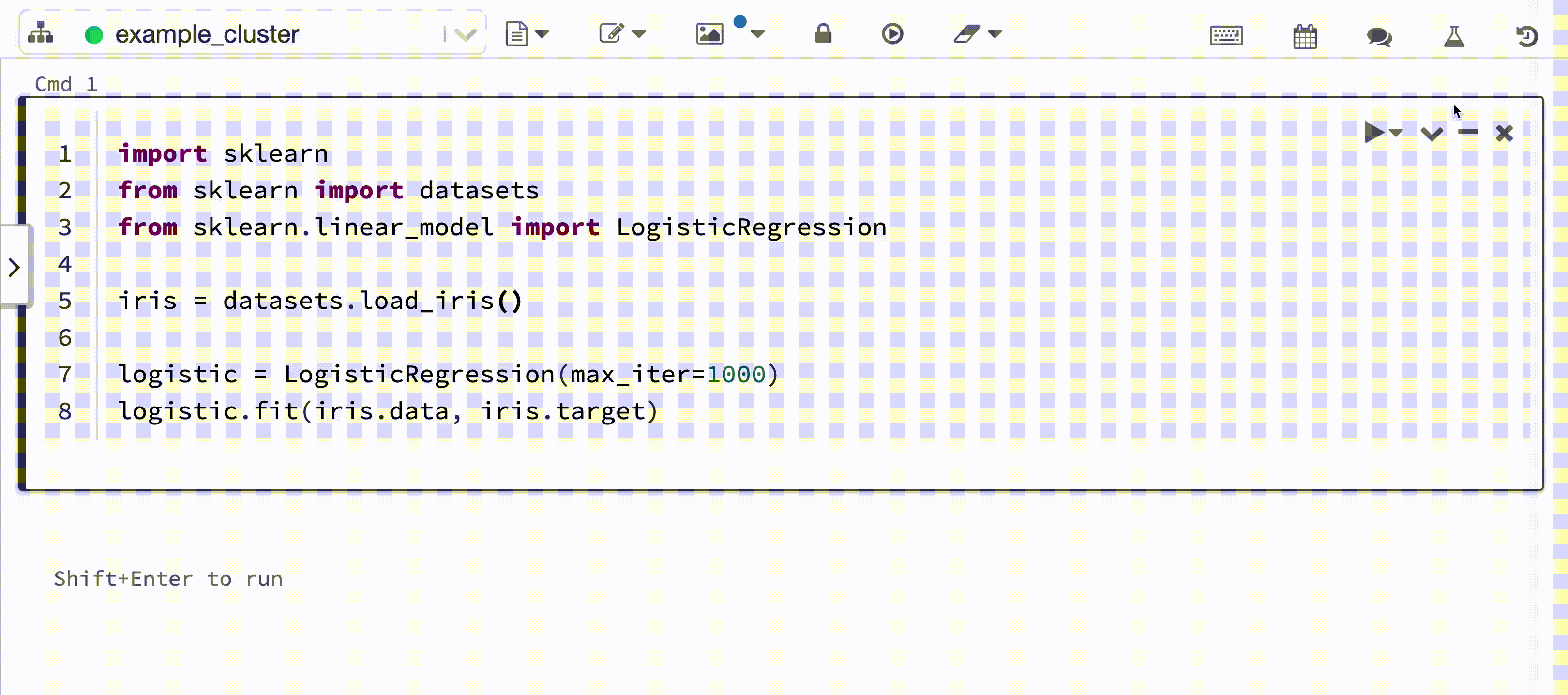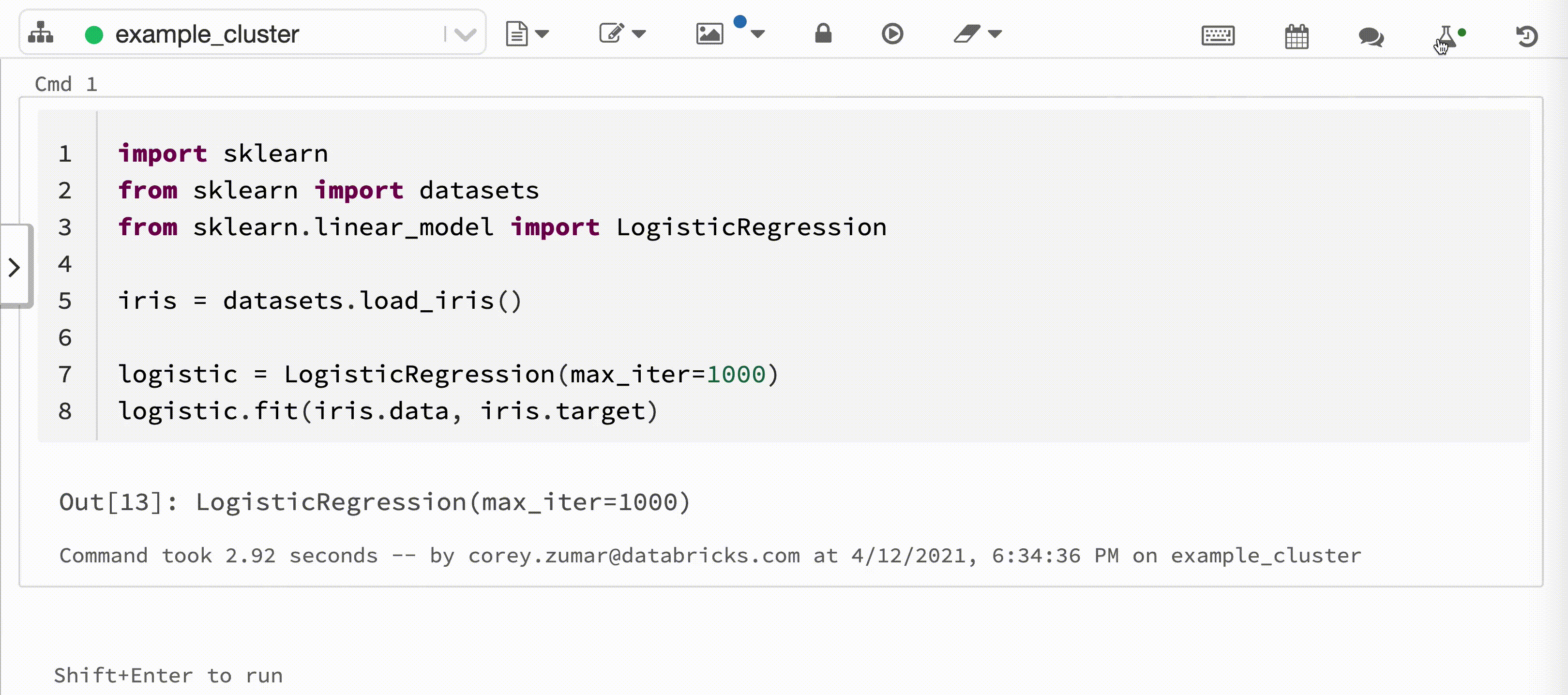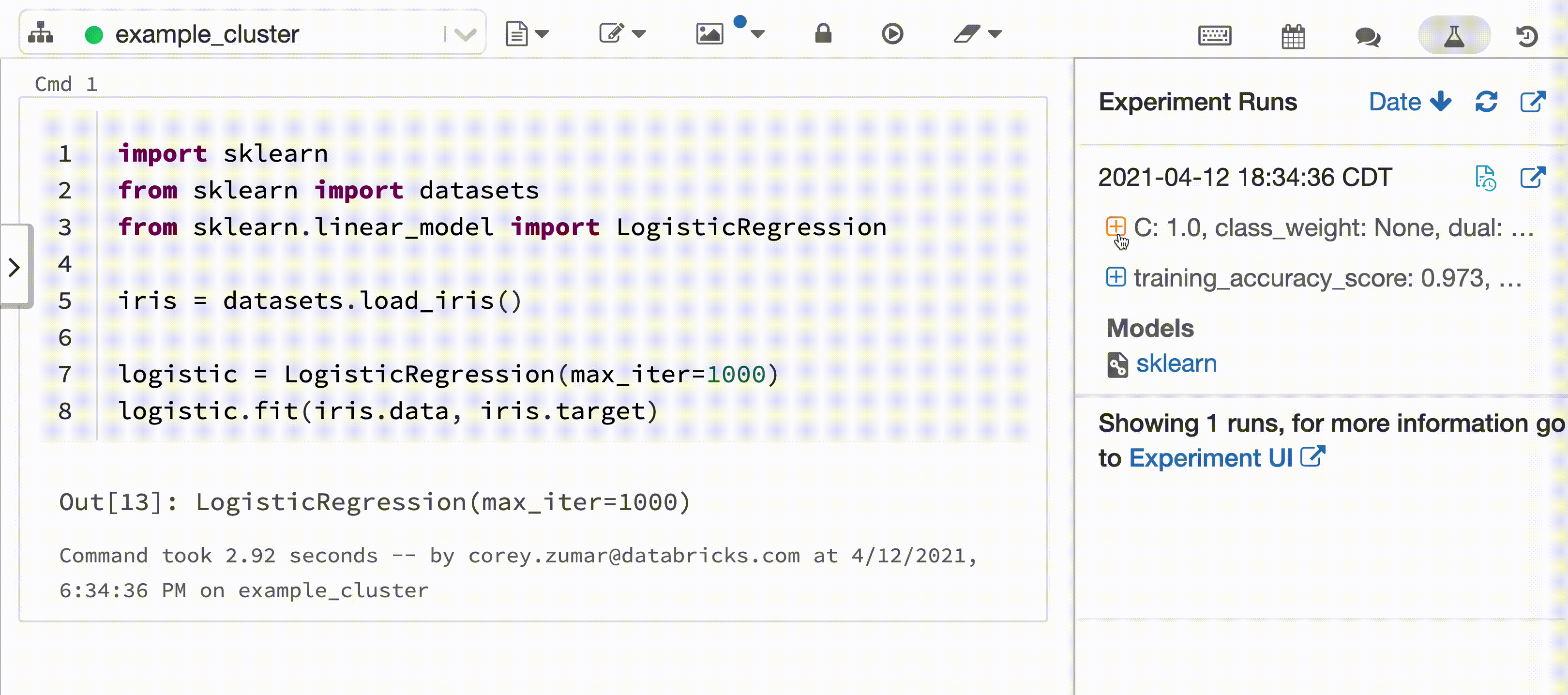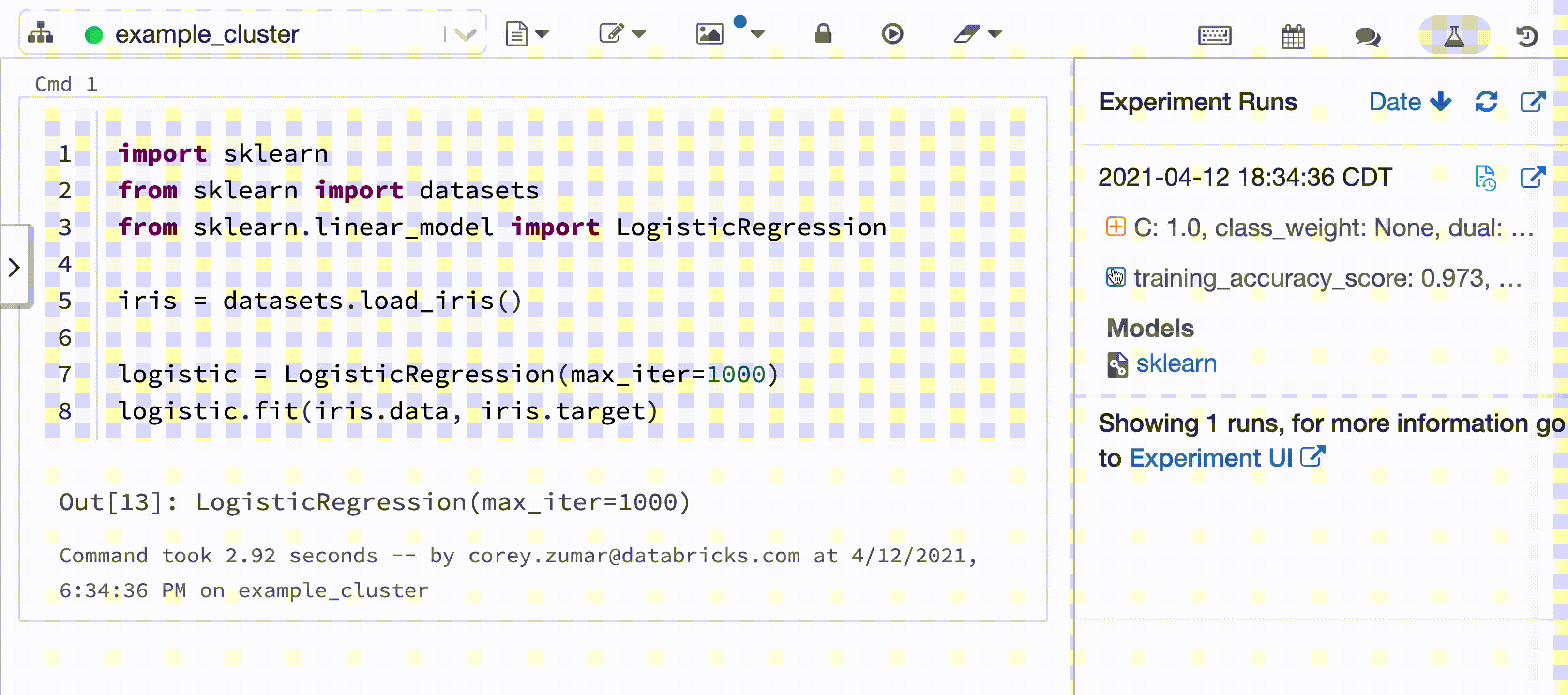
Databricks 자동 로깅을 사용하면 널리 사용되는 다양한 기계 학습 라이브러리에서 모델을 학습할 때 모델 매개 변수, 메트릭, 파일 및 계보 정보가 자동으로 캡처됩니다. 학습 세션은 MLflow 추적 실행으로 기록됩니다. 모델 파일도 추적되므로 MLflow 모델 레지스트리에 쉽게 로그하고 Model Serving를 사용하여 실시간 채점을 위해 배포할 수 있습니다.
다음 비디오에서는 대화형 Python Notebook에서 scikit-learn 모델 학습 세션을 사용하는 Databricks 자동 로깅을 보여 줍니다. 추적 정보는 실험 실행 사이드바 및 MLflow UI에 자동으로 캡처되고 표시됩니다.
요구 사항
- Databricks 자동 로깅은 Databricks Runtime 10.4 LTS ML 이상이 있는 모든 지역에서 일반적으로 사용할 수 있습니다.
- Databricks 자동 로깅은 Databricks Runtime 9.1 LTS ML 이상이 있는 일부 미리 보기 지역에서 사용할 수 있습니다.
작동 방식
대화형 Python Notebook을 Azure Databricks 클러스터에 연결하는 경우 Databricks 자동 로깅은 mlflow.autolog()를 호출하여 모델 학습 세션에 대한 추적을 설정합니다. Notebook에서 모델을 학습하면 MLflow 추적을 사용하여 모델 학습 정보가 자동으로 추적됩니다. 이 모델 학습 정보를 보호 및 관리하는 방법에 대한 자세한 내용은 보안 및 데이터 관리를 참조하세요.
mlflow.autolog() 호출에 대한 기본 구성은 다음과 같습니다.
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
자동 로깅 구성을 사용자 지정할 수 있습니다.
사용
Databricks 자동 로깅을 사용하려면 대화형 Azure Databricks Python Notebook을 사용하여 지원되는 프레임워크에서 기계 학습 모델을 학습합니다. Databricks 자동 로깅은 모델 계보 정보, 매개 변수 및 메트릭을 MLflow 추적에 자동으로 기록합니다. Databricks 자동 로깅의 동작을 사용자 지정할 수도 있습니다.
참고 항목
Databricks 자동 로깅은 mlflow.start_run()과 함께 MLflow 흐름 API를 사용하여 만든 실행에 적용되지 않습니다. 이러한 경우 mlflow.autolog()를 호출하여 자동 로그된 콘텐츠를 MLflow 실행에 저장합니다. 추가 콘텐츠 추적을 참조하세요.
로깅 동작 사용자 지정
로깅을 사용자 지정하려면 mlflow.autolog()를 사용합니다.
이 함수는 모델 로깅(log_models)을 활성화하고, 입력 예제(log_input_examples)를 수집하고, 경고 구성(silent) 등을 위한 구성 매개 변수를 제공합니다.
추가 콘텐츠 추적
Databricks 자동 로깅에서 만든 MLflow 실행을 사용하여 추가 메트릭, 매개 변수, 파일 및 메타데이터를 추적하려면 Azure Databricks 대화형 Python Notebook에서 다음 단계를 수행합니다.
exclusive=False를 사용하여 mlflow.autolog()를 호출합니다.- mlflow.start_run()를 사용하여 MLflow 실행을 시작합니다.
이 호출을
with mlflow.start_run()로 래핑할 수 있습니다. 이렇게 하면 실행이 완료된 후 자동으로 종료됩니다. - mlflow.log_param()과 같은 MLflow 추적 메서드를 사용하여 학습 전 콘텐츠를 추적합니다.
- Databricks 자동 로깅에서 지원하는 프레임워크에서 하나 이상의 기계 학습 모델을 학습시킵니다.
- mlflow.log_metric()과 같은 MLflow 추적 메서드를 사용하여 학습 후 콘텐츠를 추적합니다.
- 2단계에서
with mlflow.start_run()을 사용하지 않은 경우 mlflow.end_run()을 사용하여 MLflow 실행을 종료합니다.
예시:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
Databricks 자동 로깅 사용 안 함
Azure Databricks 대화형 Python Notebook에서 Databricks 자동 로깅을 사용하지 않도록 설정하려면 다음을 사용하여 mlflow.autolog()disable=True를 호출합니다.
import mlflow
mlflow.autolog(disable=True)
관리자는 관리자 설정 페이지의 고급 탭에서 작업 영역의 모든 클러스터에 대해 Databricks 자동 로깅을 사용하지 않도록 설정할 수도 있습니다. 이 변경 내용을 적용하려면 인스턴스를 다시 시작해야 합니다.
지원되는 환경 및 프레임워크
Databricks 자동 로깅은 대화형 Python Notebook에서 지원되며 다음 ML 프레임워크에서 사용할 수 있습니다.
- scikit-learn
- Apache Spark MLlib
- Tensorflow
- Keras
- PyTorch Lightning
- XGBoost
- LightGBM
- Gluon
- Fast.ai(버전 1.x)
- statsmodels.
지원되는 각 프레임워크에 대한 자세한 내용은 MLflow 자동 로깅을 참조하세요.
보안 및 데이터 관리
Databricks 자동 로깅으로 추적되는 모든 모델 학습 정보는 MLflow 추적에 저장되며 MLflow 실험 권한으로 보호됩니다. MLflow 추적 API 또는 UI를 사용하여 모델 학습 정보를 공유, 수정 또는 삭제할 수 있습니다.
관리
관리자는 관리자 설정 페이지의 고급 탭에서 작업 영역 전체의 모든 대화형 전자 필기장 세션에 대해 Databricks 자동 로깅을 사용하거나 사용하지 않도록 설정할 수 있습니다. 클러스터가 다시 시작할 때까지 변경 내용이 적용되지 않습니다.
제한 사항
- Databricks 자동 로깅은 Azure Databricks 작업에서 지원되지 않습니다. 작업에서 자동 로깅을 사용하려면 mlflow.autolog()를 명시적으로 호출할 수 있습니다.
- Databricks 자동 로깅은 Azure Databricks 클러스터의 드라이버 노드에서만 사용하도록 설정됩니다. 작업자 노드에서 자동 로깅을 사용하려면 각 작업자에서 실행되는 코드 내에서 mlflow.autolog()를 명시적으로 호출해야 합니다.
- XGBoost scikit-learn 통합은 지원되지 않습니다.
Apache Spark MLlib, Hyperopt 및 자동화된 MLflow 추적
Databricks 자동 로깅은 Apache Spark MLlib 및 Hyperopt에 대한 기존 자동화된 MLflow 추적 통합의 동작을 변경하지 않습니다.
참고 항목
Databricks Runtime 10.1 ML Apache Spark MLlib CrossValidator 및 TrainValidationSplit 모델에 대한 자동화된 MLflow 추적 통합을 사용하지 않도록 설정하면 모든 Apache Spark MLlib 모델에 대한 Databricks 자동 로깅 기능도 비활성화됩니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기