dbt(데이터 빌드 도구)는 데이터 분석가와 데이터 엔지니어가 select 문을 작성하여 데이터를 변환할 수 있도록 해 주는 개발 환경입니다. dbt는 select 문을 테이블과 뷰로 변환해 줍니다. dbt는 코드를 원시 SQL로 컴파일한 다음 Azure Databricks의 지정된 데이터베이스에서 실행합니다. dbt는 버전 제어, 설명서화, 모듈화와 같은 협업 코딩 패턴과 모범 사례를 지원합니다.
dbt는 데이터를 추출하거나 로드하지 않습니다. dbt는 “로드 후 변환” 아키텍처를 사용하여 변환 단계에만 집중합니다. dbt는 데이터베이스에 데이터 복사본이 이미 있다고 가정합니다.
이 문서에서는 dbt Cloud를 중점적으로 다룹니다. dbt Cloud는 작업 예약, CI/CD, 설명서 제공, 모니터링 및 경고, IDE(통합 개발 환경)에 대한 턴키 지원을 갖추고 있습니다.
dbt Core라는 로컬 버전의 dbt도 사용할 수 있습니다. dbt Core를 사용하면 로컬 개발 컴퓨터에서 원하는 텍스트 편집기 또는 IDE로 dbt 코드를 작성한 다음 명령줄에서 dbt를 실행할 수 있습니다. dbt Core에는 dbt CLI(명령줄 인터페이스)가 포함되어 있습니다. dbt CLI는 무료이며 오픈 소스입니다. 자세한 내용은 dbt Core에 연결을 참조하세요.
dbt Cloud 및 dbt Core는 호스팅된 git 리포지토리(예: GitHub, GitLab 또는 BitBucket에서)를 사용할 수 있으므로 dbt Cloud를 사용하여 dbt 프로젝트를 만든 다음 dbt Cloud 및 dbt Core 사용자가 사용할 수 있도록 할 수 있습니다. 자세한 내용은 dbt 웹 사이트의 Creating a dbt project(dbt 프로젝트 만들기) 및 Using an existing project(기존 프로젝트 사용)를 참조하세요.
dbt에 대한 일반적인 개요는 다음 YouTube 비디오(26분)를 시청하세요.
Partner Connect를 사용하여 dbt Cloud에 연결
이 섹션에서는 Partner Connect를 사용하여 Databricks SQL 웨어하우스를 dbt Cloud에 연결한 다음, dbt Cloud에 데이터에 대한 읽기 액세스 권한을 부여하는 방법을 설명합니다.
표준 연결과 dbt Cloud 간의 차이점
Partner Connect를 사용하여 dbt Cloud에 연결하려면 Partner Connect를 사용하여 데이터 준비 파트너에 연결의 단계를 수행합니다. dbt Cloud 연결은 다음과 같은 방법으로 표준 데이터 준비 및 변환 연결과 다릅니다.
- Partner Connect는 서비스 주체 및 개인용 액세스 토큰 외에도 기본적으로 DBT_CLOUD_ENDPOINT로 명명된 SQL 웨어하우스(이전 명칭 SQL 엔드포인트)를 만듭니다.
연결 단계
Partner Connect를 사용하여 dbt Cloud에 연결하려면 다음을 수행합니다.
dbt Cloud에 연결하면 dbt Cloud 대시보드가 나타납니다. dbt Cloud 프로젝트를 탐색하려면 메뉴 모음의 dbt 로고 옆에 있는 dbt 계정 이름이 표시되지 않으면 첫 번째 드롭다운에서 dbt 계정 이름을 선택한 다음, 두 번째 드롭다운 메뉴에서 Databricks Partner Connect 평가판 프로젝트를 선택합니다(표시되지 않는 경우).
팁
프로젝트의 설정을 보려면 "세 줄무늬" 또는 "햄버거" 메뉴를 클릭하고 계정 설정 > 프로젝트를 클릭한 다음 프로젝트 이름을 클릭합니다. 연결 설정을 보려면 연결 옆의 링크를 클릭합니다. 설정을 변경하려면 편집을 클릭합니다.
이 프로젝트에 대한 Azure Databricks 개인용 액세스 토큰 정보를 보려면 메뉴 모음에서 “사람” 아이콘을 클릭하고 프로필 > 자격 증명 > Databricks Partner Connect 평가판을 클릭한 다음, 프로젝트 이름을 클릭합니다. 변경하려면 편집을 클릭합니다.
dbt Cloud에 데이터에 대한 읽기 권한을 부여하는 단계
Partner Connect 기본 카탈로그에서만 DBT_CLOUD_USER 서비스 주체에 대한 만들기 전용 권한을 부여합니다. Azure Databricks 작업 영역에서 다음 단계를 수행하여 DBT_CLOUD_USER 서비스 주체에게 선택한 데이터에 대한 읽기 권한을 부여합니다.
경고
이러한 단계를 조정하여 작업 영역 내의 카탈로그, 데이터베이스 및 테이블에서 dbt Cloud에 추가 액세스 권한을 부여할 수 있습니다. 그러나 보안 모범 사례로 Databricks는 DBT_CLOUD_USER 서비스 주체가 필요한 개별 테이블에만 액세스 권한을 부여하고 해당 테이블에 대한 읽기 권한만 제공하는 것이 좋습니다.
 을 클릭합니다.사이드바의 카탈로그입니다.
을 클릭합니다.사이드바의 카탈로그입니다.오른쪽 위에 있는 드롭다운 목록에서 SQL 웨어하우스(DBT_CLOUD_ENDPOINT)를 선택합니다.
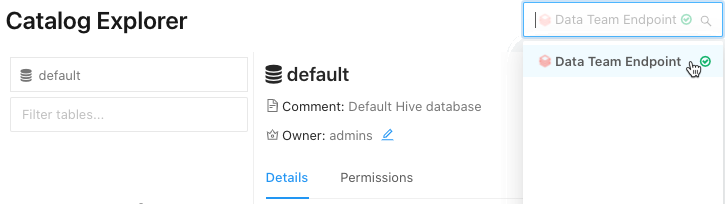
- Catalog Explorer 아래에서 테이블의 데이터베이스가 포함된 카탈로그를 선택합니다.
- 테이블이 포함된 데이터베이스를 선택합니다.
- 테이블 선택
팁
카탈로그, 데이터베이스 또는 테이블이 나열되지 않으면 카탈로그 선택, 데이터베이스 선택 또는 테이블 필터링 상자에 이름의 일부를 입력하여 목록의 범위를 좁힐 수 있습니다.

사용 권한을 클릭합니다.
권한 부여를 클릭합니다.
여러 사용자 또는 그룹을 추가할 형식의 경우 DBT_CLOUD_USER를 선택합니다. 이전 섹션에서 Partner Connect가 만든 Azure Databricks 서비스 주체입니다.
팁
DBT_CLOUD_USER가 표시되지 않으면 목록에 나타날 때까지
DBT_CLOUD_USER상자에 을(를) 입력한 다음, 선택합니다.SELECT및READ METADATA을(를) 선택하여 읽기 액세스 권한만 부여합니다.확인을 클릭합니다.
dbt Cloud에 읽기 권한을 부여하려는 각 추가 테이블에 대해 4~9단계를 반복합니다.
dbt Cloud 연결 문제 해결
누군가가 이 계정에 대해 dbt Cloud에서 프로젝트를 삭제하고 dbt 타일을 클릭하면 프로젝트를 찾을 수 없다는 오류 메시지가 나타납니다. 이 문제를 해결하려면 연결 삭제를 클릭한 다음, 이 절차의 시작 부분에서 시작하여 연결을 다시 만듭니다.
dbt Cloud에 수동으로 연결
이 섹션에서는 Azure Databricks 작업 영역의 Azure Databricks 클러스터 또는 Databricks SQL 웨어하우스를 dbt Cloud에 연결하는 방법을 설명합니다.
중요합니다
Databricks는 SQL 웨어하우스에 연결하는 것을 권장합니다. Databricks SQL 액세스 권한이 없거나 Python 모델을 실행하려는 경우 대신 클러스터에 연결할 수 있습니다.
요구 사항
Azure Databricks 작업 영역의 클러스터 또는 SQL 웨어하우스
클러스터 또는 SQL 웨어하우스, 특히 서버 호스트 이름, 포트 및 HTTP 경로 값에 대한 연결 세부 정보.
Azure Databricks 개인용 액세스 토큰 또는 Microsoft Entra ID(이전 Azure Active Directory) 토큰. 개인 액세스 토큰을 만들려면 작업 영역 사용자에 대한 개인 액세스 토큰 만들기의 단계를 수행합니다.
참고 항목
보안 모범 사례로, 자동화된 도구, 시스템, 스크립트, 앱을 사용하여 인증할 때 Databricks는 작업 영역 사용자 대신 서비스 주체에 속한 개인용 액세스 토큰을 사용하는 것을 권장합니다. 서비스 주체에 대한 토큰을 만들려면 서비스 주체에 대한 토큰 관리를 참조하세요.
dbt Cloud를 Unity Catalog에서 관리하는 데이터에 연결하려면 dbt 버전 1.1 이상이 필요합니다.
이 문서의 단계에서는 최신 dbt 버전을 사용하는 새로운 환경을 만듭니다. 기존 환경의 dbt 버전을 업그레이드하는 방법에 대한 자세한 내용은 dbt 설명서의 Cloud에서 dbt 최신 버전으로 업그레이드를 참조하세요.
1단계: dbt Cloud에 등록
dbt Cloud - 등록으로 이동하여 이메일, 이름 및 회사 정보를 입력합니다. 암호를 만들고 내 계정 만들기를 클릭합니다.
2단계: dbt 프로젝트 만들기
이 단계에서는 소스 코드 및 하나 이상의 환경(예: 테스트 및 프로덕션 환경)이 포함된 리포지토리인 Azure Databricks 클러스터 또는 SQL 웨어하우스에 대한 연결이 포함된 dbt 프로젝트를 만듭니다.
설정 아이콘을 클릭한 다음 계정 설정을 클릭합니다.
새 프로젝트를 클릭합니다.
이름에 프로젝트의 고유한 이름을 입력한 후 계속을 클릭합니다.
연결 선택 드롭다운 메뉴에서 Azure Databricks 컴퓨팅 연결을 선택 하거나 새 연결을 만듭니다.
새 연결추가를 클릭합니다.
새 연결 추가 마법사가 새 탭에서 열립니다.
Databricks클릭한 후 다음클릭합니다.
참고 항목
Databricks에서는
dbt-databricks대신 Unity Catalog를 지원하는dbt-spark을(를) 사용하는 것이 좋습니다. 기본적으로 새 프로젝트는dbt-databricks을(를) 사용합니다. 기존 프로젝트를dbt-databricks(으)로 마이그레이션하려면 dbt 설명서의 dbt-spark에서 dbt-databricks로 마이그레이션을 참조하세요.설정에서 서버 호스트 이름에 요구 사항의 서버 호스트 이름 값을 입력합니다.
HTTP 경로의 경우 요구 사항의 HTTP 경로 값을 입력합니다.
작업 영역이 Unity 카탈로그를 사용하는 경우 옵션 설정에서 dbt가 사용할 카탈로그의 이름을 입력합니다.
저장을 클릭합니다.
새 프로젝트 마법사로 돌아가서 연결 드롭다운 메뉴에서 방금 만든 연결을 선택합니다.
개발 자격 증명의 토큰에 대해 요구 사항의 개인용 액세스 토큰이나 Microsoft Entra ID 토큰을 입력합니다.
스키마에서 dbt가 테이블과 뷰를 생성할 스키마의 이름을 입력하세요.
연결 테스트를 클릭합니다.
테스트가 성공적으로 완료되면 저장을 클릭합니다.
자세한 내용은 dbt 웹 사이트에서 Databricks ODBC에 연결을 참조하세요.
팁
이 프로젝트의 설정을 보거나 변경하거나 프로젝트를 완전히 삭제하려면 설정 아이콘을 클릭하고 계정 설정 > 프로젝트를 클릭한 다음 프로젝트 이름을 클릭합니다. 설정을 변경하려면 편집을 클릭합니다. 프로젝트를 삭제하려면 편집 > 프로젝트 삭제를 클릭합니다.
이 프로젝트에 대한 Azure Databricks 개인용 액세스 토큰 값을 보거나 변경하려면 "사람" 아이콘을 클릭하고 프로필 > 자격 증명을 클릭한 다음 프로젝트 이름을 클릭합니다. 변경하려면 편집을 클릭합니다.
Azure Databricks 클러스터 또는 Databricks SQL 웨어하우스에 연결한 후 화면의 지시에 따라 리포지토리 설정을 수행한 다음, 계속을 클릭합니다.
리포지토리를 설정한 후 화면상의 지침에 따라 사용자를 초대한 다음 완료를 클릭합니다. 또는 건너뛰기 및 완료를 클릭합니다.
자습서
이 섹션에서는 dbt Cloud 프로젝트를 사용하여 일부 샘플 데이터를 사용합니다. 이 섹션에서는 이미 프로젝트를 만들었으며 dbt Cloud IDE가 해당 프로젝트에 열려 있다고 가정합니다.
1단계: 모델 만들기 및 실행
이 단계에서는 dbt Cloud IDE를 사용하여 같은 데이터베이스의 기존 데이터를 기반으로 데이터베이스에 새 보기(기본값) 또는 새 테이블을 만드는 문인 select을 만들고 실행합니다. 이 절차에서는 diamonds의 샘플 테이블을 기반으로 모델을 만듭니다.
다음 코드를 사용하여 이 테이블을 만듭니다.
DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds USING CSV OPTIONS (path "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header "true")
이 절차에서는 이 테이블이 작업 영역의 default 데이터베이스에 이미 만들어졌다고 가정합니다.
프로젝트가 열리면 UI 상단의 개발을 클릭합니다.
dbt 프로젝트 초기화를 클릭합니다.
커밋 및 동기화를 클릭하고 커밋 메시지를 입력한 다음 커밋을 클릭합니다.
분기 만들기를 클릭하고 분기 이름을 입력한 다음 제출을 클릭합니다.
첫 번째 모델 만들기: 새 파일 만들기를 클릭합니다.
텍스트 편집기에 다음 SQL 문을 복사합니다. 이 문은
diamonds테이블에서 각 다이아몬드의 캐럿, 컷, 색상 및 투명도 세부 정보만 선택합니다.config블록은 이 문을 기반으로 데이터베이스에 테이블을 만들도록 dbt에 지시합니다.{{ config( materialized='table', file_format='delta' ) }}select carat, cut, color, clarity from diamonds팁
config증분 전략과 같은 추가merge옵션에 대한 자세한 내용은 dbt 설명서의 Databricks 구성을 참조하세요.다른 이름으로 저장을 클릭합니다.
파일 이름에
models/diamonds_four_cs.sql을 입력한 후 만들기를 클릭합니다.두 번째 모델 만들기: 오른쪽 상단 모서리에 있는
 (새 파일 만들기)를 클릭하세요.
(새 파일 만들기)를 클릭하세요.텍스트 편집기에 다음 SQL 문을 복사합니다. 이 명령문은
colors테이블의diamonds_four_cs열에서 고유한 값을 선택하여 결과를 알파벳 순서로 처음부터 마지막까지 정렬합니다.config블록이 없기 때문에 이 모델은 dbt에게 이 명령문을 기반으로 데이터베이스에 보기를 만들도록 지시합니다.select distinct color from diamonds_four_cs sort by color asc다른 이름으로 저장을 클릭합니다.
파일 이름에
models/diamonds_list_colors.sql을 입력한 후 만들기를 클릭합니다.세 번째 모델 만들기: 오른쪽 상단 모서리에 있는
(새 파일 만들기)를 클릭하세요.텍스트 편집기에 다음 SQL 문을 복사합니다. 이 명령문은 다이아몬드 가격을 색상별로 평균화하여 평균 가격을 기준으로 가장 높은 값에서 가장 낮은 값까지 결과를 정렬합니다. 이 모델은 dbt에 이 문을 기반으로 데이터베이스에 뷰를 만들도록 지시합니다.
select color, avg(price) as price from diamonds group by color order by price desc다른 이름으로 저장을 클릭합니다.
파일 이름에
models/diamonds_prices.sql을 입력하고 만들기를 클릭합니다.모델 실행: 명령줄에서 앞의 세 파일에 대한 경로를 포함하여
dbt run명령을 실행합니다.default데이터베이스에서 dbt는diamonds_four_cs라는 테이블 하나와diamonds_list_colors및diamonds_prices라는 두 개의 보기를 만듭니다. dbt는 관련.sql파일 이름으로부터 뷰 및 테이블 이름을 가져옵니다.dbt run --model models/diamonds_four_cs.sql models/diamonds_list_colors.sql models/diamonds_prices.sql... ... | 1 of 3 START table model default.diamonds_four_cs.................... [RUN] ... | 1 of 3 OK created table model default.diamonds_four_cs............... [OK ...] ... | 2 of 3 START view model default.diamonds_list_colors................. [RUN] ... | 2 of 3 OK created view model default.diamonds_list_colors............ [OK ...] ... | 3 of 3 START view model default.diamonds_prices...................... [RUN] ... | 3 of 3 OK created view model default.diamonds_prices................. [OK ...] ... | ... | Finished running 1 table model, 2 view models ... Completed successfully Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3다음 SQL 코드를 실행하여 새 보기에 대한 정보를 나열하고 테이블 및 보기에서 모든 행을 선택합니다.
클러스터에 연결하는 경우 SQL을 Notebook의 기본 언어로 지정하여 클러스터에 연결된 Notebook에서 이 SQL 코드를 실행할 수 있습니다. SQL 웨어하우스에 연결하는 경우 쿼리에서 이 SQL 코드를 실행할 수 있습니다.
SHOW views IN default+-----------+----------------------+-------------+ | namespace | viewName | isTemporary | +===========+======================+=============+ | default | diamonds_list_colors | false | +-----------+----------------------+-------------+ | default | diamonds_prices | false | +-----------+----------------------+-------------+SELECT * FROM diamonds_four_cs+-------+---------+-------+---------+ | carat | cut | color | clarity | +=======+=========+=======+=========+ | 0.23 | Ideal | E | SI2 | +-------+---------+-------+---------+ | 0.21 | Premium | E | SI1 | +-------+---------+-------+---------+ ...SELECT * FROM diamonds_list_colors+-------+ | color | +=======+ | D | +-------+ | E | +-------+ ...SELECT * FROM diamonds_prices+-------+---------+ | color | price | +=======+=========+ | J | 5323.82 | +-------+---------+ | I | 5091.87 | +-------+---------+ ...
2단계: 더 복잡한 모델 만들기 및 실행
이 단계에서는 관련 데이터 테이블 집합에 대해 더 복잡한 모델을 만듭니다. 이 데이터 테이블에는 한 시즌 동안 6차례의 경기를 플레이하는 세 팀의 가상 스포츠 리그에 대한 정보가 포함되어 있습니다. 이 절차에서는 데이터 테이블을 만들고, 모델을 만들고, 모델을 실행합니다.
다음 SQL 코드를 실행하여 필요한 데이터 테이블을 만듭니다.
클러스터에 연결하는 경우 SQL을 Notebook의 기본 언어로 지정하여 클러스터에 연결된 Notebook에서 이 SQL 코드를 실행할 수 있습니다. SQL 웨어하우스에 연결하는 경우 쿼리에서 이 SQL 코드를 실행할 수 있습니다.
이 단계의 테이블과 뷰는 이 예에서 식별하는 데 도움이 되도록
zzz_로 시작합니다. 자체 테이블 및 뷰에서는 이 패턴을 따를 필요는 없습니다.DROP TABLE IF EXISTS zzz_game_opponents; DROP TABLE IF EXISTS zzz_game_scores; DROP TABLE IF EXISTS zzz_games; DROP TABLE IF EXISTS zzz_teams; CREATE TABLE zzz_game_opponents ( game_id INT, home_team_id INT, visitor_team_id INT ) USING DELTA; INSERT INTO zzz_game_opponents VALUES (1, 1, 2); INSERT INTO zzz_game_opponents VALUES (2, 1, 3); INSERT INTO zzz_game_opponents VALUES (3, 2, 1); INSERT INTO zzz_game_opponents VALUES (4, 2, 3); INSERT INTO zzz_game_opponents VALUES (5, 3, 1); INSERT INTO zzz_game_opponents VALUES (6, 3, 2); -- Result: -- +---------+--------------+-----------------+ -- | game_id | home_team_id | visitor_team_id | -- +=========+==============+=================+ -- | 1 | 1 | 2 | -- +---------+--------------+-----------------+ -- | 2 | 1 | 3 | -- +---------+--------------+-----------------+ -- | 3 | 2 | 1 | -- +---------+--------------+-----------------+ -- | 4 | 2 | 3 | -- +---------+--------------+-----------------+ -- | 5 | 3 | 1 | -- +---------+--------------+-----------------+ -- | 6 | 3 | 2 | -- +---------+--------------+-----------------+ CREATE TABLE zzz_game_scores ( game_id INT, home_team_score INT, visitor_team_score INT ) USING DELTA; INSERT INTO zzz_game_scores VALUES (1, 4, 2); INSERT INTO zzz_game_scores VALUES (2, 0, 1); INSERT INTO zzz_game_scores VALUES (3, 1, 2); INSERT INTO zzz_game_scores VALUES (4, 3, 2); INSERT INTO zzz_game_scores VALUES (5, 3, 0); INSERT INTO zzz_game_scores VALUES (6, 3, 1); -- Result: -- +---------+-----------------+--------------------+ -- | game_id | home_team_score | visitor_team_score | -- +=========+=================+====================+ -- | 1 | 4 | 2 | -- +---------+-----------------+--------------------+ -- | 2 | 0 | 1 | -- +---------+-----------------+--------------------+ -- | 3 | 1 | 2 | -- +---------+-----------------+--------------------+ -- | 4 | 3 | 2 | -- +---------+-----------------+--------------------+ -- | 5 | 3 | 0 | -- +---------+-----------------+--------------------+ -- | 6 | 3 | 1 | -- +---------+-----------------+--------------------+ CREATE TABLE zzz_games ( game_id INT, game_date DATE ) USING DELTA; INSERT INTO zzz_games VALUES (1, '2020-12-12'); INSERT INTO zzz_games VALUES (2, '2021-01-09'); INSERT INTO zzz_games VALUES (3, '2020-12-19'); INSERT INTO zzz_games VALUES (4, '2021-01-16'); INSERT INTO zzz_games VALUES (5, '2021-01-23'); INSERT INTO zzz_games VALUES (6, '2021-02-06'); -- Result: -- +---------+------------+ -- | game_id | game_date | -- +=========+============+ -- | 1 | 2020-12-12 | -- +---------+------------+ -- | 2 | 2021-01-09 | -- +---------+------------+ -- | 3 | 2020-12-19 | -- +---------+------------+ -- | 4 | 2021-01-16 | -- +---------+------------+ -- | 5 | 2021-01-23 | -- +---------+------------+ -- | 6 | 2021-02-06 | -- +---------+------------+ CREATE TABLE zzz_teams ( team_id INT, team_city VARCHAR(15) ) USING DELTA; INSERT INTO zzz_teams VALUES (1, "San Francisco"); INSERT INTO zzz_teams VALUES (2, "Seattle"); INSERT INTO zzz_teams VALUES (3, "Amsterdam"); -- Result: -- +---------+---------------+ -- | team_id | team_city | -- +=========+===============+ -- | 1 | San Francisco | -- +---------+---------------+ -- | 2 | Seattle | -- +---------+---------------+ -- | 3 | Amsterdam | -- +---------+---------------+첫 번째 모델 만들기: 오른쪽 상단 모서리에 있는
(새 파일 만들기)를 클릭하세요.텍스트 편집기에 다음 SQL 문을 복사합니다. 이 문은 팀 이름 및 점수와 같은 각 게임의 세부 정보를 제공하는 테이블을 만듭니다.
config블록은 이 문을 기반으로 데이터베이스에 테이블을 만들도록 dbt에 지시합니다.-- Create a table that provides full details for each game, including -- the game ID, the home and visiting teams' city names and scores, -- the game winner's city name, and the game date.{{ config( materialized='table', file_format='delta' ) }}-- Step 4 of 4: Replace the visitor team IDs with their city names. select game_id, home, t.team_city as visitor, home_score, visitor_score, -- Step 3 of 4: Display the city name for each game's winner. case when home_score > visitor_score then home when visitor_score > home_score then t.team_city end as winner, game_date as date from ( -- Step 2 of 4: Replace the home team IDs with their actual city names. select game_id, t.team_city as home, home_score, visitor_team_id, visitor_score, game_date from ( -- Step 1 of 4: Combine data from various tables (for example, game and team IDs, scores, dates). select g.game_id, go.home_team_id, gs.home_team_score as home_score, go.visitor_team_id, gs.visitor_team_score as visitor_score, g.game_date from zzz_games as g, zzz_game_opponents as go, zzz_game_scores as gs where g.game_id = go.game_id and g.game_id = gs.game_id ) as all_ids, zzz_teams as t where all_ids.home_team_id = t.team_id ) as visitor_ids, zzz_teams as t where visitor_ids.visitor_team_id = t.team_id order by game_date desc다른 이름으로 저장을 클릭합니다.
파일 이름에
models/zzz_game_details.sql을 입력한 후 만들기를 클릭합니다.두 번째 모델 만들기: 오른쪽 상단 모서리에 있는
(새 파일 만들기)를 클릭하세요.텍스트 편집기에 다음 SQL 문을 복사합니다. 이 문은 시즌의 팀 승패 기록을 나열하는 보기를 만듭니다.
-- Create a view that summarizes the season's win and loss records by team. -- Step 2 of 2: Calculate the number of wins and losses for each team. select winner as team, count(winner) as wins, -- Each team played in 4 games. (4 - count(winner)) as losses from ( -- Step 1 of 2: Determine the winner and loser for each game. select game_id, winner, case when home = winner then visitor else home end as loser from zzz_game_details ) group by winner order by wins desc다른 이름으로 저장을 클릭합니다.
파일 이름에
models/zzz_win_loss_records.sql을 입력한 후 만들기를 클릭합니다.모델 실행: 명령줄에서 앞의 두 파일에 대한 경로를 포함하여
dbt run명령을 실행합니다. 프로젝트 설정에 지정된 대로default데이터베이스에서 dbt는zzz_game_details이라는 테이블 하나와zzz_win_loss_records라는 뷰 하나를 만듭니다. dbt는 관련.sql파일 이름으로부터 뷰 및 테이블 이름을 가져옵니다.dbt run --model models/zzz_game_details.sql models/zzz_win_loss_records.sql... ... | 1 of 2 START table model default.zzz_game_details.................... [RUN] ... | 1 of 2 OK created table model default.zzz_game_details............... [OK ...] ... | 2 of 2 START view model default.zzz_win_loss_records................. [RUN] ... | 2 of 2 OK created view model default.zzz_win_loss_records............ [OK ...] ... | ... | Finished running 1 table model, 1 view model ... Completed successfully Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2다음 SQL 코드를 실행하여 새 뷰에 대한 정보를 나열하고 테이블 및 뷰의 모든 행을 선택합니다.
클러스터에 연결하는 경우 SQL을 Notebook의 기본 언어로 지정하여 클러스터에 연결된 Notebook에서 이 SQL 코드를 실행할 수 있습니다. SQL 웨어하우스에 연결하는 경우 쿼리에서 이 SQL 코드를 실행할 수 있습니다.
SHOW VIEWS FROM default LIKE 'zzz_win_loss_records';+-----------+----------------------+-------------+ | namespace | viewName | isTemporary | +===========+======================+=============+ | default | zzz_win_loss_records | false | +-----------+----------------------+-------------+SELECT * FROM zzz_game_details;+---------+---------------+---------------+------------+---------------+---------------+------------+ | game_id | home | visitor | home_score | visitor_score | winner | date | +=========+===============+===============+============+===============+===============+============+ | 1 | San Francisco | Seattle | 4 | 2 | San Francisco | 2020-12-12 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 2 | San Francisco | Amsterdam | 0 | 1 | Amsterdam | 2021-01-09 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 3 | Seattle | San Francisco | 1 | 2 | San Francisco | 2020-12-19 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 4 | Seattle | Amsterdam | 3 | 2 | Seattle | 2021-01-16 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 5 | Amsterdam | San Francisco | 3 | 0 | Amsterdam | 2021-01-23 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 6 | Amsterdam | Seattle | 3 | 1 | Amsterdam | 2021-02-06 | +---------+---------------+---------------+------------+---------------+---------------+------------+SELECT * FROM zzz_win_loss_records;+---------------+------+--------+ | team | wins | losses | +===============+======+========+ | Amsterdam | 3 | 1 | +---------------+------+--------+ | San Francisco | 2 | 2 | +---------------+------+--------+ | Seattle | 1 | 3 | +---------------+------+--------+
3단계: 테스트 만들기 및 실행
이 단계에서는 모델에 대한 어설션인 테스트를 만듭니다. 이러한 테스트를 실행할 때 dbt는 프로젝트의 각 테스트의 통과/실패 여부를 알려줍니다.
두 가지 유형의 테스트가 있습니다. YAML로 작성된 스키마 테스트는 어설션을 통과하지 못한 레코드 수를 반환합니다. 이 숫자가 0이면 모든 레코드가 통과하므로 테스트가 통과합니다. 데이터 테스트는 통과하려면 0개의 레코드를 반환해야 하는 쿼리입니다.
스키마 테스트 만들기: 오른쪽 상단 모서리에 있는
(새 파일 만들기)를 클릭하세요.텍스트 편집기에 다음 내용을 입력하세요. 이 파일에는 지정된 열에 고유한 값이 있는지, null이 아닌지, 지정된 값만 있는지 또는 조합이 있는지 여부를 결정하는 스키마 테스트가 포함되어 있습니다.
version: 2 models: - name: zzz_game_details columns: - name: game_id tests: - unique - not_null - name: home tests: - not_null - accepted_values: values: ['Amsterdam', 'San Francisco', 'Seattle'] - name: visitor tests: - not_null - accepted_values: values: ['Amsterdam', 'San Francisco', 'Seattle'] - name: home_score tests: - not_null - name: visitor_score tests: - not_null - name: winner tests: - not_null - accepted_values: values: ['Amsterdam', 'San Francisco', 'Seattle'] - name: date tests: - not_null - name: zzz_win_loss_records columns: - name: team tests: - unique - not_null - relationships: to: ref('zzz_game_details') field: home - name: wins tests: - not_null - name: losses tests: - not_null다른 이름으로 저장을 클릭합니다.
파일 이름에
models/schema.yml을 입력한 후 만들기를 클릭합니다.첫 번째 데이터 테스트 만들기: 오른쪽 상단 모서리에 있는
(새 파일 만들기)를 클릭하세요.텍스트 편집기에 다음 SQL 문을 복사합니다. 이 파일에는 정규 시즌을 벗어나서 진행된 경기가 있는지 확인하는 데이터 테스트가 포함되어 있습니다.
-- This season's games happened between 2020-12-12 and 2021-02-06. -- For this test to pass, this query must return no results. select date from zzz_game_details where date < '2020-12-12' or date > '2021-02-06'다른 이름으로 저장을 클릭합니다.
파일 이름에
tests/zzz_game_details_check_dates.sql을 입력한 후 만들기를 클릭합니다.두 번째 데이터 테스트 만들기: 오른쪽 상단 모서리에 있는
(새 파일 만들기)를 클릭하세요.텍스트 편집기에 다음 SQL 문을 복사합니다. 이 파일에는 점수가 부정적인지 또는 동점인 게임이 있는지 확인하기 위한 데이터 테스트가 포함되어 있습니다.
-- This sport allows no negative scores or tie games. -- For this test to pass, this query must return no results. select home_score, visitor_score from zzz_game_details where home_score < 0 or visitor_score < 0 or home_score = visitor_score다른 이름으로 저장을 클릭합니다.
파일 이름에
tests/zzz_game_details_check_scores.sql을 입력한 후 만들기를 클릭합니다.세 번째 데이터 테스트 만들기: 오른쪽 상단 모서리에 있는
(새 파일 만들기)를 클릭하세요.텍스트 편집기에 다음 SQL 문을 복사합니다. 이 파일에는 음수인 승패 기록이 있는 팀, 플레이한 경기보다 많은 승패 기록이 있는 팀, 허용된 것보다 많은 경기를 플레이한 팀이 있는지 확인하는 데이터 테스트가 포함되어 있습니다.
-- Each team participated in 4 games this season. -- For this test to pass, this query must return no results. select wins, losses from zzz_win_loss_records where wins < 0 or wins > 4 or losses < 0 or losses > 4 or (wins + losses) > 4다른 이름으로 저장을 클릭합니다.
파일 이름에
tests/zzz_win_loss_records_check_records.sql을 입력한 후 만들기를 클릭합니다.테스트 실행하기: 명령줄에서
dbt test명령을 실행합니다.
4단계: 정리
다음 SQL 코드를 실행하여 이 예제에 대해 만든 테이블과 뷰를 삭제할 수 있습니다.
클러스터에 연결하는 경우 SQL을 Notebook의 기본 언어로 지정하여 클러스터에 연결된 Notebook에서 이 SQL 코드를 실행할 수 있습니다. SQL 웨어하우스에 연결하는 경우 쿼리에서 이 SQL 코드를 실행할 수 있습니다.
DROP TABLE zzz_game_opponents;
DROP TABLE zzz_game_scores;
DROP TABLE zzz_games;
DROP TABLE zzz_teams;
DROP TABLE zzz_game_details;
DROP VIEW zzz_win_loss_records;
DROP TABLE diamonds;
DROP TABLE diamonds_four_cs;
DROP VIEW diamonds_list_colors;
DROP VIEW diamonds_prices;
다음 단계
- dbt 모델에 대해 자세히 알아봅니다.
- dbt 프로젝트를 테스트하는 방법을 알아봅니다.
- 템플릿 작성 언어 Jinja를 사용하여 dbt 프로젝트에서 SQL을 프로그래밍하는 방법을 알아봅니다.
- dbt 모범 사례를 알아봅니다.