LangChain.js 및 Azure 서비스를 사용하여 지능형 HR 도우미를 빌드합니다. 이 에이전트는 가상의 NorthWind 회사의 직원들이 회사 설명서를 검색하여 인적 자원 질문에 대한 답변을 찾을 수 있도록 도와줍니다.
Azure AI Search를 사용하여 관련 문서 및 Azure OpenAI를 찾아 정확한 답변을 생성합니다. LangChain.js 프레임워크는 에이전트 오케스트레이션의 복잡성을 처리하여 특정 비즈니스 요구 사항에 집중할 수 있도록 합니다.
학습할 내용:
- Azure Developer CLI를 사용하여 Azure 리소스 배포
- Azure 서비스와 통합되는 LangChain.js 에이전트 빌드
- 문서 검색을 위한 RAG(검색 보강 생성) 구현
- 로컬 및 Azure에서 에이전트 테스트 및 디버그
이 자습서의 끝부분에는 회사의 설명서를 사용하여 HR 질문에 답변하는 작업 REST API가 있습니다.
아키텍처 개요
NorthWind는 다음 두 가지 데이터 원본을 사용합니다.
- 모든 직원이 액세스할 수 있는 HR 설명서
- 중요한 직원 데이터를 포함하는 기밀 HR 데이터베이스입니다.
이 자습서에서는 공용 HR 문서를 사용하여 직원의 질문에 대답할 수 있는지 여부를 결정하는 LangChain.js 에이전트를 빌드하는 데 중점을 둡니다. 이 경우 LangChain.js 에이전트가 직접 답변을 제공합니다.
필수 조건
LangChain.js 에이전트 빌드 및 실행을 포함하여 Codespace 또는 로컬 개발 컨테이너에서 이 샘플을 사용하려면 다음이 필요합니다.
- 활성 Azure 계정입니다. 계정이 없는 경우 무료로 계정을 만듭니다.
개발 컨테이너 없이 샘플 코드를 로컬로 실행하는 경우에도 다음이 필요합니다.
- 시스템에 설치된Node.js LTS
- TypeScript 코드를 작성하고 컴파일하기 위한 TypeScript입니다.
- Azure 개발자 CLI(azd) 가 설치 및 구성되었습니다.
- 에이전트를 빌드하기 위한 LangChain.js 라이브러리입니다.
- 선택 사항: AI 사용량을 모니터링하기 위한 LangSmith 입니다. 프로젝트 이름, 키 및 엔드포인트가 필요합니다.
- 선택 사항: LangGraph 체인 및 LangChain.js 에이전트를 디버깅하기 위한 LangGraph Studio 입니다.
Azure 리소스
다음 Azure 리소스가 필요합니다. 이 문서에서는 AVM(Azure Verified Modules)을 사용하는 Azure Developer CLI 및 Bicep 템플릿을 사용하여 만들어집니다. 리소스는 학습을 위해 암호 없는 액세스 권한과 키 액세스를 모두 사용하여 만들어집니다. 이 자습서에서는 암호 없는 인증에 로컬 개발자 계정을 사용합니다.
- Azure 서비스에 대한 암호 없는 인증에 대한 관리 ID입니다.
- Azure Container Registry 는 Node.js Fastify API 서버에 대한 Docker 이미지를 저장합니다.
- Node.js Fastify API 서버를 호스트하는 Azure Container App입니다.
- 벡터 검색을 위한 Azure AI Search 리소스입니다.
- 다음 모델이 포함된 Azure OpenAI 리소스:
- embeddings 모델(예:
text-embedding-3-small.) - 와 같은
'gpt-4.1-miniLLM(큰 언어 모델)입니다.
- embeddings 모델(예:

에이전트 아키텍처
LangChain.js 프레임워크는 지능형 에이전트를 LangGraph로 빌드하기 위한 의사 결정 흐름을 제공합니다. 이 자습서에서는 HR 관련 질문에 답변하기 위해 Azure AI Search 및 Azure OpenAI와 통합되는 LangChain.js 에이전트를 만듭니다. 에이전트의 아키텍처는 다음을 수행하도록 설계되었습니다.
- 질문이 모든 직원이 사용할 수 있는 일반 HR 설명서와 관련이 있는지 확인합니다.
- 사용자 쿼리를 기반으로 Azure AI Search에서 관련 문서를 검색합니다.
- Azure OpenAI를 사용하여 검색된 문서 및 LLM 모델을 기반으로 답변을 생성합니다.
주요 구성 요소:
그래프 구조: LangChain.js 에이전트는 그래프로 표시됩니다. 여기서는 다음을 수행합니다.
- 노드는 의사 결정 또는 데이터 검색과 같은 특정 작업을 수행합니다.
- 엣지는 노드 간의 흐름을 정의하고 작업 순서를 결정합니다.
Azure AI Search 통합:
- embeddings 모델을 사용하여 벡터를 만듭니다.
- HR 문서(*.md, *.pdf)를 벡터 저장소에 삽입합니다.
문서는 다음과 같습니다.
- 회사 정보
- 직원 핸드북
- 혜택 핸드북
- 직원 역할 라이브러리
- 사용자 프롬프트에 따라 관련 문서를 검색합니다.
-
Azure OpenAI 통합:
- 큰 언어 모델을 사용하여 다음을 수행합니다.
- 비인격 HR 문서에서 질문에 대답할 수 있는지 여부를 결정합니다.
- 문서 및 사용자 질문의 컨텍스트를 사용하여 프롬프트를 사용하여 답변을 생성합니다.
- 큰 언어 모델을 사용하여 다음을 수행합니다.
다음 표에는 일반 인사 문서에서 관련이 있고 답변할 수 없는 사용자 질문의 예가 있습니다.
| 질문 | 관련 | Explanation |
|---|---|---|
Does the NorthWind Health Plus plan cover eye exams? |
Yes | 직원 핸드북과 같은 HR 문서는 답변을 제공해야 합니다. |
How much of my perks + benefits have I spent? |
아니오 | 이 질문에는 이 에이전트의 범위를 벗어나는 기밀 직원 데이터에 액세스해야 합니다. |
LangChain.js 프레임워크를 사용하면 에이전트 및 Azure 서비스 통합에 일반적으로 필요한 에이전트 상용구 코드의 대부분을 방지하여 비즈니스 요구 사항에 집중할 수 있습니다.
샘플 코드 리포지토리 복제
새 디렉터리에서 샘플 코드 리포지토리를 복제하고 새 디렉터리로 변경합니다.
git clone https://github.com/Azure-Samples/azure-typescript-langchainjs.git
cd azure-typescript-langchainjs
이 샘플에서는 보안 Azure 리소스를 만들고, Azure AI Search 및 Azure OpenAI를 사용하여 LangChain.js 에이전트를 빌드하고, Node.js Fastify API 서버에서 에이전트를 사용하는 데 필요한 코드를 제공합니다.
Azure CLI 및 Azure 개발자 CLI에 인증
Azure 개발자 CLI를 사용하여 Azure에 로그인하고, Azure 리소스를 만들고, 소스 코드를 배포합니다. 배포 프로세스는 Azure CLI와 Azure Developer CLI를 모두 사용하므로 Azure CLI에 로그인한 다음 Azure CLI에서 인증을 사용하도록 Azure 개발자 CLI를 구성합니다.
az login
azd config set auth.useAzCliAuth true
Azure Developer CLI를 사용하여 리소스 만들기 및 코드 배포
다음 명령을 실행하여 배포 프로세스를 시작합니다.azd up
azd up
명령을 수행하는 동안 azd up 질문에 대답하십시오.
-
새 환경 이름: 다음과 같은
langchain-agent고유한 환경 이름을 입력합니다. 이 환경 이름은 Azure 리소스 그룹의 일부로 사용됩니다. - Azure 구독 선택: 리소스가 만들어지는 구독을 선택합니다.
-
지역을 선택합니다. 예:
eastus2
배포에는 약 10-15분이 걸립니다. Azure 개발자 CLI는 파일에 정의된 azure.yaml 단계 및 후크를 사용하여 프로세스를 오케스트레이션합니다.
프로비전 단계 (azd provision와 동일한):
- 에 정의된 Azure 리소스를 만듭니다.
infra/main.bicep- Azure Container App
- OpenAI
- AI 검색
- Container Registry
- 관리되는 아이덴티티
-
프로비전 후 후크: Azure AI Search 인덱스가 이미 있는지 확인
- 인덱스가 존재하지 않는 경우: LangChain.js PDF 로더 및 포함 클라이언트를 사용하여
npm install및npm run load_data을 실행하여 HR 문서를 업로드합니다. - 인덱스가 있는 경우: 중복을 방지하기 위해 데이터 로드를 건너뜁니다(인덱스를 삭제하거나 실행
npm run load_data하여 수동으로 다시 로드할 수 있음) 배포 단계 (해당azd deploy):
- 인덱스가 존재하지 않는 경우: LangChain.js PDF 로더 및 포함 클라이언트를 사용하여
- 사전 배포 후크: Fastify API 서버에 대한 Docker 이미지를 빌드하고 Azure Container Registry에 푸시합니다.
- Azure Container Apps에 컨테이너화된 API 서버 배포
배포가 완료되면 환경 변수 및 리소스 정보가 리포지토리 루트의 .env 파일에 저장됩니다.
Azure Portal에서 리소스를 볼 수 있습니다.
리소스는 학습을 위해 암호 없는 액세스 권한과 키 액세스를 모두 사용하여 만들어집니다. 이 소개 자습서에서는 암호 없는 인증에 로컬 개발자 계정을 사용합니다. 프로덕션 애플리케이션의 경우 관리 ID에 암호 없는 인증만 사용합니다. 암호 없는 인증에 대해 자세히 알아봅니다.
샘플 코드를 로컬로 사용
이제 Azure 리소스를 만들었으므로 LangChain.js 에이전트를 로컬로 실행할 수 있습니다.
종속성 설치
이 프로젝트에 대한 Node.js 패키지를 설치합니다.
npm install이 명령은 다음을 포함하여 디렉터리의 두
package.json파일에packages-v1정의된 종속성을 설치합니다.-
./packages-v1/server-api:- 웹 서버용 Fastify
-
./packages-v1/langgraph-agent:- 에이전트를 빌드하기 위한 LangChain.js
- Azure AI Search 리소스와 통합하기 위한 Azure SDK 클라이언트 라이브러리
@azure/search-documents입니다. 참조 설명서는 다음과 같습니다.
-
API 서버와 AI 에이전트라는 두 가지 패키지를 빌드합니다.
npm run build이 명령은 API 서버가 AI 에이전트를 호출할 수 있도록 두 패키지 간에 링크를 만듭니다.
로컬로 API 서버 실행
Azure Developer CLI는 필요한 Azure 리소스를 만들고 루트 .env 파일에 환경 변수를 구성했습니다. 이 구성에는 데이터를 벡터 저장소에 업로드하기 위한 프로비저닝 후 후크가 포함되었습니다. 이제 LangChain.js 에이전트를 호스트하는 Fastify API 서버를 실행할 수 있습니다. Fastify API 서버를 시작합니다.
npm run dev
서버가 포트 3000에서 시작되고 수신 대기합니다. 웹 브라우저에서 [http://localhost:3000]로 이동하여 서버를 테스트할 수 있습니다. 서버가 실행 중임을 나타내는 환영 메시지가 표시됩니다.
API를 사용하여 질문하기
REST 클라이언트와 같은 도구를 사용하거나 curl 질문을 포함하는 JSON 본문을 사용하여 엔드포인트에 POST 요청을 /ask 보낼 수 있습니다.
Rest 클라이언트 쿼리는 packages-v1/server-api/http 디렉터리에서 사용할 수 있습니다.
curl사용하는 예제:
curl -X POST http://localhost:3000/answer -H "Content-Type: application/json" -d "{\"question\": \"Does the NorthWind Health Plus plan cover eye exams?\"}"
LangChain.js 에이전트의 답변과 함께 JSON 응답을 받아야 합니다.
{
"answer": "Yes, the NorthWind Health Plus plan covers eye exams. According to the Employee Handbook, employees enrolled in the Health Plus plan are eligible for annual eye exams as part of their vision benefits."
}
디렉터리에서 packages-v1/server-api/http 몇 가지 예제 질문을 사용할 수 있습니다.
REST 클라이언트를 사용하여 Visual Studio Code에서 파일을 열어 빠르게 테스트합니다.
애플리케이션 코드 이해
이 섹션에서는 LangChain.js 에이전트가 Azure 서비스와 통합되는 방법을 설명합니다. 리포지토리의 애플리케이션은 다음 두 개의 기본 패키지가 있는 npm 작업 영역으로 구성됩니다.
Project Root
│
├── packages-v1/
│ │
│ ├── langgraph-agent/ # Core LangGraph agent implementation
│ │ ├── src/
│ │ │ ├── azure/ # Azure service integrations
│ │ │ │ ├── azure-credential.ts # Centralized auth with DefaultAzureCredential
│ │ │ │ ├── embeddings.ts # Azure OpenAI embeddings + PDF loading + rate limiting
│ │ │ │ ├── llm.ts # Azure OpenAI chat completion (key-based & passwordless)
│ │ │ │ └── vector_store.ts # Azure AI Search vector store + indexing + similarity search
│ │ │ │
│ │ │ ├── langchain/ # LangChain agent logic
│ │ │ │ ├── node_get_answer.ts # RAG: retrieves docs + generates answers
│ │ │ │ ├── node_requires_hr_documents.ts # Determines if HR docs needed
│ │ │ │ ├── nodes.ts # LangGraph node definitions + state management
│ │ │ │ └── prompt.ts # System prompts + conversation templates
│ │ │ │
│ │ │ └── scripts/ # Utility scripts
│ │ │ └── load_vector_store.ts # Uploads PDFs to Azure AI Search
│ │ │
│ │ └── data/ # Source documents (PDFs) for vector store
│ │
│ └── server-api/ # Fastify REST API server
│ └── src/
│ └── server.ts # HTTP server with /answer endpoint
│
├── infra/ # Infrastructure as Code
│ └── main.bicep # Azure resources: Container Apps, OpenAI, AI Search, ACR, managed identity
│
├── azure.yaml # Azure Developer CLI config + deployment hooks
├── Dockerfile # Multi-stage Docker build for containerized deployment
└── package.json # Workspace configuration + build scripts
주요 아키텍처 결정 사항:
- Monorepo 구조: npm 작업 영역에서 공유 종속성 및 연결된 패키지를 허용합니다.
-
우려 사항 분리: 에이전트 논리(
langgraph-agent)가 API 서버와 독립적(server-api) -
중앙 집중식 인증: 키 기반 인증과 암호 없는 인증 및 Azure 서비스 통합을 모두 처리하는 파일
./langgraph-agent/src/azure
Azure 서비스에 대한 인증
애플리케이션은 환경 변수에 의해 SET_PASSWORDLESS 제어되는 키 기반 인증 방법과 암호 없는 인증 방법을 모두 지원합니다.
Azure ID 라이브러리의 DefaultAzureCredential API는 암호 없는 인증에 사용되므로 로컬 개발 및 Azure 환경에서 애플리케이션을 원활하게 실행할 수 있습니다. 다음 코드 조각에서 이 인증을 볼 수 있습니다.
import { DefaultAzureCredential } from "@azure/identity";
export const CREDENTIAL = new DefaultAzureCredential();
export const SCOPE_OPENAI = "https://cognitiveservices.azure.com/.default";
export async function azureADTokenProvider_OpenAI() {
const tokenResponse = await CREDENTIAL.getToken(SCOPE_OPENAI);
return tokenResponse.token;
}
LangChain.js 또는 OpenAI 라이브러리와 같은 타사 라이브러리를 사용하여 Azure OpenAI에 액세스하는 경우 자격 증명 개체를 직접 전달하는 대신 토큰 공급자 함수 가 필요합니다. Azure ID 라이브러리의 함수는 getBearerTokenProvider 특정 Azure 리소스 범위(예 "https://cognitiveservices.azure.com/.default": )에 대한 OAuth 2.0 전달자 토큰을 자동으로 가져오고 새로 고치는 토큰 공급자를 만들어 이 문제를 해결합니다. 설정 중에 범위를 한 번 구성하면 토큰 공급자가 모든 토큰 관리를 자동으로 처리합니다. 이 방법은 관리 ID 및 Azure CLI 자격 증명을 비롯한 모든 Azure ID 라이브러리 자격 증명에서 작동합니다. Azure SDK 라이브러리는 직접 수락 DefaultAzureCredential 하지만 LangChain.js 같은 타사 라이브러리에는 인증 격차를 해소하기 위해 이 토큰 공급자 패턴이 필요합니다.
Azure AI Search 통합
Azure AI Search 리소스는 문서 포함을 저장하고 관련 콘텐츠에 대한 의미 체계 검색을 사용하도록 설정합니다. 애플리케이션은 인덱스 스키마를 정의하지 않고도 LangChain을 AzureAISearchVectorStore 사용하여 벡터 저장소를 관리합니다.
벡터 저장소는 문서 로드 및 쿼리에서 서로 다른 구성을 사용할 수 있도록 관리자(쓰기) 및 쿼리(읽기) 작업 모두에 대한 구성으로 만들어집니다. 이는 관리 ID와 함께 키 또는 암호 없는 인증을 사용하는지 여부에 관계없이 중요합니다.
Azure Developer CLI 배포에는 LangChain.js PDF 로더 및 포함 클라이언트를 사용하여 문서를 벡터 저장소에 업로드하는 배포 후 후크가 포함되어 있습니다. 이 배포 후 후크는 Azure AI Search 리소스를 azd up 만든 후 명령의 마지막 단계입니다. 문서 로드 스크립트는 일괄 처리 및 재시도 논리를 사용하여 서비스 속도 제한을 처리합니다.
postdeploy:
posix:
sh: bash
run: |
echo "Checking if vector store data needs to be loaded..."
# Check if already loaded
INDEX_CREATED=$(azd env get-values | grep INDEX_CREATED | cut -d'=' -f2 || echo "false")
if [ "$INDEX_CREATED" = "true" ]; then
echo "Index already created. Skipping data load."
echo "Current document count: $(azd env get-values | grep INDEX_DOCUMENT_COUNT | cut -d'=' -f2)"
else
echo "Loading vector store data..."
npm install
npm run build
npm run load_data
# Get document count from the index
SEARCH_SERVICE=$(azd env get-values | grep AZURE_AISEARCH_ENDPOINT | cut -d'/' -f3 | cut -d'.' -f1)
DOC_COUNT=$(az search index show --service-name $SEARCH_SERVICE --name northwind --query "documentCount" -o tsv 2>/dev/null || echo "0")
# Mark as loaded
azd env set INDEX_CREATED true
azd env set INDEX_DOCUMENT_COUNT $DOC_COUNT
echo "Data loading complete! Indexed $DOC_COUNT documents."
fi
Azure 개발자 CLI에서 만든 루트 .env 파일을 사용하여 Azure AI Search 리소스에 인증하고 AzureAISearchVectorStore 클라이언트를 만들 수 있습니다.
const endpoint = process.env.AZURE_AISEARCH_ENDPOINT;
const indexName = process.env.AZURE_AISEARCH_INDEX_NAME;
const adminKey = process.env.AZURE_AISEARCH_ADMIN_KEY;
const queryKey = process.env.AZURE_AISEARCH_QUERY_KEY;
export const QUERY_DOC_COUNT = 3;
const MAX_INSERT_RETRIES = 3;
const shared_admin = {
endpoint,
indexName,
};
export const VECTOR_STORE_ADMIN_KEY: AzureAISearchConfig = {
...shared_admin,
key: adminKey,
};
export const VECTOR_STORE_ADMIN_PASSWORDLESS: AzureAISearchConfig = {
...shared_admin,
credentials: CREDENTIAL,
};
export const VECTOR_STORE_ADMIN_CONFIG: AzureAISearchConfig =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_ADMIN_PASSWORDLESS
: VECTOR_STORE_ADMIN_KEY;
const shared_query = {
endpoint,
indexName,
search: {
type: AzureAISearchQueryType.Similarity,
},
};
// Key-based config
export const VECTOR_STORE_QUERY_KEY: AzureAISearchConfig = {
key: queryKey,
...shared_query,
};
export const VECTOR_STORE_QUERY_PASSWORDLESS: AzureAISearchConfig = {
credentials: CREDENTIAL,
...shared_query,
};
export const VECTOR_STORE_QUERY_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_QUERY_PASSWORDLESS
: VECTOR_STORE_QUERY_KEY;
쿼리할 때 벡터 저장소는 사용자의 쿼리를 포함으로 변환하고, 유사한 벡터 표현이 있는 문서를 검색하고, 가장 관련성이 큰 청크를 반환합니다.
export function getReadOnlyVectorStore(): AzureAISearchVectorStore {
const embeddings = getEmbeddingClient();
return new AzureAISearchVectorStore(embeddings, VECTOR_STORE_QUERY_CONFIG);
}
export async function getDocsFromVectorStore(
query: string,
): Promise<Document[]> {
const store = getReadOnlyVectorStore();
// @ts-ignore
//return store.similaritySearchWithScore(query, QUERY_DOC_COUNT);
return store.similaritySearch(query, QUERY_DOC_COUNT);
}
벡터 저장소는 LangChain.js위에 구축되므로 벡터 저장소와 직접 상호 작용하는 복잡성을 추상화합니다. LangChain.js 벡터 저장소 인터페이스를 알게 되면 나중에 다른 벡터 저장소 구현으로 쉽게 전환할 수 있습니다.
Azure OpenAI 통합
애플리케이션은 포함 및 LLM(대규모 언어 모델) 기능 모두에 Azure OpenAI를 사용합니다.
AzureOpenAIEmbeddingsLangChain.js 클래스는 문서 및 쿼리에 대한 포함을 생성하는 데 사용됩니다. embeddings 클라이언트를 만들면 LangChain.js는 이를 사용하여 임베딩을 생성합니다.
임베딩 위한 Azure OpenAI 통합
Azure Developer CLI에서 만든 루트 .env 파일을 사용하여 Azure OpenAI 리소스에 인증하고 AzureOpenAIEmbeddings 클라이언트를 만듭니다.
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiEmbeddingsDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
dimensions: 1536, // for text-embedding-3-small
batchSize: EMBEDDING_BATCH_SIZE,
maxRetries: 7,
timeout: 60000,
};
export const EMBEDDINGS_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const EMBEDDINGS_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const EMBEDDINGS_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? EMBEDDINGS_CONFIG_PASSWORDLESS
: EMBEDDINGS_KEY_CONFIG;
export function getEmbeddingClient(): AzureOpenAIEmbeddings {
return new AzureOpenAIEmbeddings({ ...EMBEDDINGS_CONFIG });
}
LLM에 대한 Azure OpenAI 통합
Azure 개발자 CLI에서 만든 루트 .env 파일을 사용하여 Azure OpenAI 리소스에 인증하고 AzureChatOpenAI 클라이언트를 만듭니다.
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
maxTokens: maxTokens ? parseInt(maxTokens, 10) : 1000,
maxRetries: 7,
timeout: 60000,
temperature: 0,
};
export const LLM_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const LLM_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const LLM_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? LLM_CONFIG_PASSWORDLESS
: LLM_KEY_CONFIG;
애플리케이션은 LangChain.js AzureChatOpenAI 클래스를 사용하여 @langchain/openai Azure OpenAI 모델과 상호 작용합니다.
export const callChatCompletionModel = async (
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> => {
const llm = new AzureChatOpenAI({
...LLM_CONFIG,
});
const completion = await llm.invoke(state.messages);
completion;
return {
messages: [
...state.messages,
{
role: "assistant",
content: completion.content,
},
],
};
};
LangGraph 에이전트 워크플로
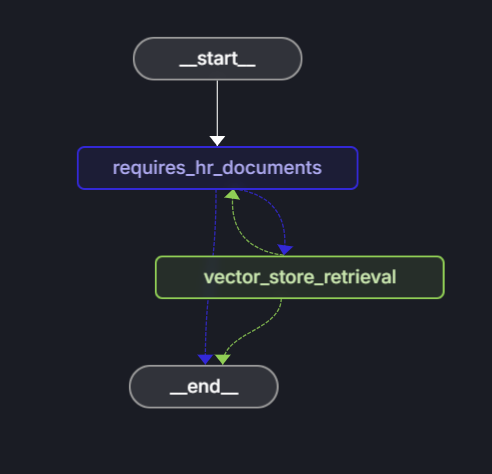
에이전트는 LangGraph를 사용하여 HR 문서를 사용하여 질문에 답변할 수 있는지 여부를 결정하는 의사 결정 워크플로를 정의합니다.
그래프 구조:
import { StateGraph } from "@langchain/langgraph";
import {
START,
ANSWER_NODE,
DECISION_NODE,
route as endRoute,
StateAnnotation,
} from "./langchain/nodes.js";
import { getAnswer } from "./langchain/node_get_answer.js";
import {
requiresHrResources,
routeRequiresHrResources,
} from "./langchain/node_requires_hr_documents.js";
const builder = new StateGraph(StateAnnotation)
.addNode(DECISION_NODE, requiresHrResources)
.addNode(ANSWER_NODE, getAnswer)
.addEdge(START, DECISION_NODE)
.addConditionalEdges(DECISION_NODE, routeRequiresHrResources)
.addConditionalEdges(ANSWER_NODE, endRoute);
export const hr_documents_answer_graph = builder.compile();
hr_documents_answer_graph.name = "Azure AI Search + Azure OpenAI";
워크플로는 다음 단계로 구성됩니다.
- 시작: 사용자가 질문을 제출합니다.
- requires_hr_documents 노드: LLM은 일반 HR 문서에서 질문에 대답할 수 있는지 여부를 결정합니다.
-
조건부 라우팅:
- 그렇다면
get_answer노드로 진행합니다. - 그렇지 않은 경우 해당 질문에 개인 HR 데이터가 필요한 메시지를 반환합니다.
- 그렇다면
- get_answer 노드: 문서를 검색하고 답변을 생성합니다.
- 끝: 사용자에게 답변을 반환합니다.
이 관련성 검사는 일반 문서에서 모든 HR 질문에 답변할 수 없기 때문에 중요합니다. "얼마나 많은 PTO가 있나요?"와 같은 개인 질문에는 개별 직원 데이터가 포함된 직원 데이터베이스에 대한 액세스 권한이 필요합니다. 먼저 관련성을 확인함으로써 에이전트는 액세스 권한이 없는 개인 정보가 필요한 질문에 대한 환각 답변을 방지합니다.
질문에 HR 문서가 필요한지 결정
노드는 requires_hr_documents LLM을 사용하여 일반 HR 문서를 사용하여 사용자의 질문에 대답할 수 있는지 확인합니다. 질문의 관련성에 따라 모델이 YES 또는 NO로 응답하도록 지시하는 프롬프트 템플릿을 사용합니다. 워크플로를 따라 전달될 수 있는 구조화된 메시지에서 답변을 반환합니다. 다음 노드는 이 응답을 사용하여 워크플로를 둘 중 하나 END 또는 로 라우팅합니다 ANSWER_NODE.
// @ts-nocheck
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "../langchain/state.js";
import { RunnableConfig } from "@langchain/core/runnables";
import { BaseMessage } from "@langchain/core/messages";
import { ANSWER_NODE, END } from "./nodes.js";
const PDF_DOCS_REQUIRED = "Answer requires HR PDF docs.";
export async function requiresHrResources(
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> {
const lastUserMessage: BaseMessage = [...state.messages].reverse()[0];
let pdfDocsRequired = false;
if (lastUserMessage && typeof lastUserMessage.content === "string") {
const question = `Does the following question require general company policy information that could be found in HR documents like employee handbooks, benefits overviews, or company-wide policies, then answer yes. Answer no if this requires personal employee-specific information that would require access to an individual's private data, employment records, or personalized benefits details: '${lastUserMessage.content}'. Answer with only "yes" or "no".`;
const llm = getLlmChatClient();
const response = await llm.invoke(question);
const answer = response.content.toLocaleLowerCase().trim();
console.log(`LLM question (is HR PDF documents required): ${question}`);
console.log(`LLM answer (is HR PDF documents required): ${answer}`);
pdfDocsRequired = answer === "yes";
}
// If HR documents (aka vector store) are required, append an assistant message to signal this.
if (!pdfDocsRequired) {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content:
"Not a question for our HR PDF resources. This requires data specific to the asker.",
},
],
};
return updatedState;
} else {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content: `${PDF_DOCS_REQUIRED} You asked: ${lastUserMessage.content}. Let me check.`,
},
],
};
return updatedState;
}
}
export const routeRequiresHrResources = (
state: typeof StateAnnotation.State,
): typeof END | typeof ANSWER_NODE => {
const lastMessage: BaseMessage = [...state.messages].reverse()[0];
if (lastMessage && !lastMessage.content.includes(PDF_DOCS_REQUIRED)) {
console.log("go to end");
return END;
}
console.log("go to llm");
return ANSWER_NODE;
};
필요한 HR 문서 가져오기
질문에 HR 문서가 필요하다고 판단되면 워크플로는 벡터 저장소에서 관련 문서를 검색하고 프롬프트의 getAnswer에 추가하고 전체 프롬프트를 LLM에 전달하는 데 사용합니다.
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "./nodes.js";
import { AIMessage } from "@langchain/core/messages";
import { getReadOnlyVectorStore } from "../azure/vector_store.js";
const EMPTY_STATE = { messages: [] };
export async function getAnswer(
state: typeof StateAnnotation.State = EMPTY_STATE,
): Promise<typeof StateAnnotation.Update> {
const vectorStore = getReadOnlyVectorStore();
const llm = getLlmChatClient();
// Extract the last user message's content from the state as input
const lastMessage = state.messages[state.messages.length - 1];
const userInput =
lastMessage && typeof lastMessage.content === "string"
? lastMessage.content
: "";
const docs = await vectorStore.similaritySearch(userInput, 3);
if (docs.length === 0) {
const noDocMessage = new AIMessage(
"I'm sorry, I couldn't find any relevant information to answer your question.",
);
return {
messages: [...state.messages, noDocMessage],
};
}
const formattedDocs = docs.map((doc) => doc.pageContent).join("\n\n");
const prompt = ChatPromptTemplate.fromTemplate(`
Use the following context to answer the question:
{context}
Question: {question}
`);
const ragChain = prompt.pipe(llm);
const result = await ragChain.invoke({
context: formattedDocs,
question: userInput,
});
const assistantMessage = new AIMessage(result.text);
return {
messages: [...state.messages, assistantMessage],
};
}
관련 문서를 찾을 수 없는 경우 에이전트는 HR 문서에서 답변을 찾을 수 없음을 나타내는 메시지를 반환합니다.
문제 해결
프로시저에 문제가 있는 경우 샘플 코드 리포지토리에서 문제를 만듭니다.
자원을 정리하세요
Azure AI Search 리소스 및 Azure OpenAI 리소스를 보유하는 리소스 그룹을 삭제하거나 Azure 개발자 CLI를 사용하여 이 자습서에서 만든 모든 리소스를 즉시 삭제할 수 있습니다.
azd down --purge