Python의 채팅 앱에서 답변 평가 시작
이 문서에서는 올바른 답변 또는 이상적인 답변 집합(지상 진리라고 함)에 대해 채팅 앱의 답변을 평가하는 방법을 보여 줍니다. 답변에 영향을 주는 방식으로 채팅 애플리케이션을 변경할 때마다 평가를 실행하여 변경 내용을 비교합니다. 이 데모 애플리케이션은 평가를 더 쉽게 실행할 수 있도록 오늘 사용할 수 있는 도구를 제공합니다.
이 문서의 지침을 따르면 다음을 수행할 수 있습니다.
- 주체 도메인에 맞게 조정된 제공된 샘플 프롬프트를 사용합니다. 이러한 프롬프트는 이미 리포지토리에 있습니다.
- 사용자 고유의 문서에서 샘플 사용자 질문 및 근거 정답을 생성합니다.
- 생성된 사용자 질문과 함께 샘플 프롬프트를 사용하여 평가를 실행합니다.
- 답변 분석을 검토합니다.
참고 항목
이 문서에서는 문서의 예제 및 지침에 대한 기준으로 하나 이상의 AI 앱 템플릿을 사용합니다. AI 앱 템플릿은 AI 앱의 고품질 시작 지점을 보장하는 데 도움이 되는 잘 유지 관리되고 배포하기 쉬운 참조 구현을 제공합니다.
아키텍처 개요
아키텍처의 주요 구성 요소는 다음과 같습니다.
- Azure 호스팅 채팅 앱: 채팅 앱은 Azure 앱 Service에서 실행됩니다.
- Microsoft AI 채팅 프로토콜 은 AI 솔루션 및 언어에서 표준화된 API 계약을 제공합니다. 채팅 앱은 Microsoft AI 채팅 프로토콜을 준수하며, 이 프로토콜을 준수하는 모든 채팅 앱에 대해 평가 앱을 실행할 수 있습니다.
- Azure AI Search: 채팅 앱은 Azure AI Search를 사용하여 사용자 고유의 문서에서 데이터를 저장합니다.
- 샘플 질문 생성기: 기본 진리 답변과 함께 각 문서에 대해 많은 질문을 생성할 수 있습니다. 질문이 많을수록 평가가 길어질 수 있습니다.
- 평가자는 채팅 앱에 대해 샘플 질문 및 프롬프트를 실행하고 결과를 반환합니다.
- 검토 도구를 사용하면 평가 결과를 검토할 수 있습니다.
- Diff 도구를 사용하면 평가 간의 답변을 비교할 수 있습니다.
이 평가를 Azure에 배포하면 자체 용량이 있는 모델에 대한 GPT-4 Azure OpenAI 엔드포인트가 만들어집니다. 채팅 애플리케이션을 평가할 때는 평가자가 자체 용량을 사용하여 자체 OpenAI 리소스를 보유 GPT-4 하는 것이 중요합니다.
필수 조건
Azure 구독. 무료로 계정 만들기
원하는 Azure 구독의 Azure OpenAI에 대한 액세스 권한. https://aka.ms/oai/access에서 자세히 알아보세요.
이전 채팅 앱 절차를 완료하여 Azure에 채팅 앱을 배포합니다. 평가 앱이 작동하려면 이 리소스가 필요합니다. 이전 절차의 리소스 정리 섹션을 완료하지 마세요.
이 문서의 채팅 앱이라고 하는 해당 배포의 다음 Azure 리소스 정보가 필요합니다.
- 채팅 API URI: 프로세스의
azd up끝에 표시되는 서비스 백 엔드 엔드포인트입니다. - Azure AI 검색. 다음 값이 필요합니다.
- 리소스 이름: 프로세스 중에
azd up보고된Search serviceAzure AI Search 리소스 이름의 이름입니다. - 인덱스 이름: 문서가 저장되는 Azure AI Search 인덱스의 이름입니다. Search 서비스에 대한 Azure Portal에서 찾을 수 있습니다.
- 리소스 이름: 프로세스 중에
채팅 API URL을 사용하면 평가에서 백 엔드 애플리케이션을 통해 요청을 할 수 있습니다. Azure AI Search 정보를 사용하면 평가 스크립트가 문서와 함께 로드된 백 엔드와 동일한 배포를 사용할 수 있습니다.
이 정보를 수집한 후에는 채팅 앱 개발 환경을 다시 사용할 필요가 없습니다. 이 문서의 뒷부분에서 여러 번 참조되어 평가 앱에서 채팅 앱을 사용하는 방법을 나타냅니다. 이 문서의 전체 절차를 완료할 때까지 채팅 앱 리소스를 삭제하지 마세요.
- 채팅 API URI: 프로세스의
이 문서를 완료하는 데 필요한 모든 종속성을 갖춘 개발 컨테이너 환경을 사용할 수 있습니다. GitHub Codespaces(브라우저)에서 개발 컨테이너를 실행하거나 Visual Studio Code를 사용하여 로컬로 실행할 수 있습니다.
- GitHub 계정
개방형 개발 환경
이 문서를 완료하려면 모든 종속성이 설치된 개발 환경으로 지금 시작합니다. 이 설명서와 개발 환경을 동시에 볼 수 있도록 모니터 작업 영역을 정렬해야 합니다.
이 문서는 평가 배포를 switzerlandnorth 위해 지역과 함께 테스트되었습니다.
GitHub Codespaces는 사용자 인터페이스로 웹용 Visual Studio Code를 사용하여 GitHub에서 관리하는 개발 컨테이너를 실행합니다. 가장 간단한 개발 환경을 위해서는 GitHub Codespaces를 사용하여 이 문서를 완료하는 데 필요한 올바른 개발자 도구와 종속성을 미리 설치합니다.
Important
모든 GitHub 계정은 2개의 코어 인스턴스를 사용하여 매월 최대 60시간 동안 Codespaces를 무료로 사용할 수 있습니다. 자세한 내용은 GitHub Codespaces 월별 포함 스토리지 및 코어 시간을 참조하세요.
Azure-Samples/ai-rag-chat-evaluatorGitHub 리포지토리의main분기에 새 GitHub Codespace를 만드는 프로세스를 시작합니다.개발 환경과 설명서를 동시에 표시하려면 다음 단추를 마우스 오른쪽 단추로 클릭하고 새 창에서 링크 열기를 선택합니다.

코드스페이 스 만들기 페이지에서 코드스페 이스 구성 설정을 검토한 다음, 새 코드스페이스 만들기를 선택합니다 .
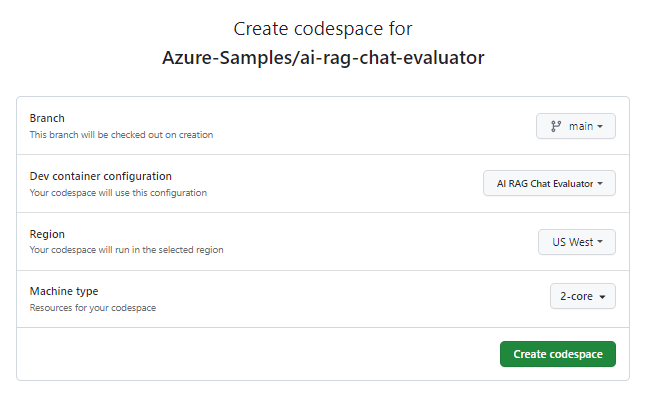
codespace가 생성될 때까지 기다립니다. 이 프로세스에는 몇 분 정도 걸릴 수 있습니다.
화면 아래쪽의 터미널에서 Azure 개발자 CLI를 사용하여 Azure에 로그인합니다.
azd auth login --use-device-code터미널에서 코드를 복사한 다음 브라우저에 붙여넣습니다. 지침에 따라 Azure 계정으로 인증합니다.
평가 앱에 필요한 Azure 리소스인 Azure OpenAI를 프로비전합니다.
azd up평가
AZD command앱을 배포하지는 않지만 로컬 개발 환경에서 평가를 실행하는 데 필요한GPT-4배포를 사용하여 Azure OpenAI 리소스를 만듭니다.이 문서의 나머지 작업은 이 개발 컨테이너의 컨텍스트에서 수행됩니다.
GitHub 리포지토리의 이름이 검색 창에 표시됩니다. 이 시각적 표시기를 사용하면 평가 앱을 채팅 앱과 구분할 수 있습니다. 이 리포지토리를 이
ai-rag-chat-evaluator문서의 평가 앱이라고 합니다.

환경 값 및 구성 정보 준비
평가 앱에 대한 필수 구성 요소 중에 수집한 정보로 환경 값 및 구성 정보를 업데이트합니다.
다음을
.env기반으로 파일을 만듭니다..env.samplecp .env.sample .env이 명령을 실행하여 배포된 리소스 그룹에 필요한
AZURE_OPENAI_EVAL_DEPLOYMENTAZURE_OPENAI_SERVICE값을 가져와서 해당 값을 파일에 붙여넣.env습니다.azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICEAzure AI Search 인스턴스에 대한 채팅 앱의 다음 값을 필수 구성 요소 섹션에서 수집한 값에 추가합니다.
.envAZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
구성 정보에 Microsoft AI 채팅 프로토콜 사용
채팅 앱과 평가 앱은 모두 사용 및 평가에 사용되는 오픈 소스, 클라우드 및 언어에 구애받지 않은 AI 엔드포인트 API 계약을 구현Microsoft AI Chat Protocol specification합니다. 클라이언트 및 중간 계층 엔드포인트가 이 API 사양을 준수하는 경우 AI 백 엔드에서 지속적으로 평가를 사용하고 실행할 수 있습니다.
명명
my_config.json된 새 파일을 만들고 다음 콘텐츠를 복사합니다.{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }평가 스크립트는 폴더를
my_results만듭니다.개체에는
overrides애플리케이션에 필요한 구성 설정이 포함됩니다. 각 애플리케이션은 자체 설정 속성 집합을 정의합니다.다음 표를 사용하여 채팅 앱으로 전송되는 설정 속성의 의미를 이해합니다.
설정 속성 설명 semantic_ranker 사용자 쿼리와 의미 체계 유사성에 따라 검색 결과를 다시 표시하는 모델인 의미 체계 순위 매기기를 사용할지 여부입니다. 이 자습서에서는 비용을 줄이기 위해 사용하지 않도록 설정합니다. retrieval_mode 사용할 검색 모드입니다. 기본값은 hybrid입니다.온도 모델의 온도 설정입니다. 기본값은 0.3입니다.top 반환할 검색 결과 수입니다. 기본값은 3입니다.prompt_template 질문 및 검색 결과에 따라 답변을 생성하는 데 사용되는 프롬프트의 재정의입니다. seed GPT 모델에 대한 모든 호출의 초기값입니다. 시드를 설정하면 평가에서 더 일관된 결과가 생성됩니다. target_url필수 구성 요소 섹션에서 수집한 채팅 앱의 URI 값으로 변경합니다. 채팅 앱은 채팅 프로토콜을 준수해야 합니다. URI 형식은 다음과 같습니다https://CHAT-APP-URL/chat. 프로토콜과 경로가chatURI의 일부인지 확인합니다.
샘플 데이터 생성
새로운 답변을 평가하려면 특정 질문에 대한 이상적인 대답인 "지상 진리" 답변과 비교해야 합니다. 채팅 앱에 대한 Azure AI Search에 저장된 문서에서 질문과 답변을 생성합니다.
폴더를
example_input새my_input폴더에 복사합니다.터미널에서 다음 명령을 실행하여 샘플 데이터를 생성합니다.
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
질문/답변 쌍은 다음 단계에서 사용되는 평가자에 대한 입력으로 생성되고 JSONL 형식으로 저장 my_input/qa.jsonl 됩니다. 프로덕션 평가의 경우 이 데이터 세트에 대해 200개 이상의 QA 쌍을 생성합니다.
참고 항목
원본당 몇 가지 질문과 답변은 이 절차를 신속하게 완료할 수 있도록 하기 위한 것입니다. 원본당 더 많은 질문과 답변이 있어야 하는 프로덕션 평가가 아닙니다.
구체화된 프롬프트를 사용하여 첫 번째 평가 실행
my_config.json구성 파일 속성을 편집합니다.속성 새 값 results_dir my_results/experiment_refinedprompt_template <READFILE>my_input/prompt_refined.txt구체화된 프롬프트는 주체 도메인에 대해 구체적으로 설명합니다.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].터미널에서 다음 명령을 실행하여 평가를 실행합니다.
python -m evaltools evaluate --config=my_config.json --numquestions=14이 스크립트는 평가와 함께 새 실험 폴더
my_results/를 만들었습니다. 폴더에는 다음을 포함한 평가 결과가 포함됩니다.파일 이름 설명 config.json평가에 사용되는 구성 파일의 복사본입니다. evaluate_parameters.json평가에 사용되는 매개 변수입니다. 타임스탬프와 config.json매우 유사하지만 추가 메타데이터를 포함합니다.eval_results.jsonl각 질문 및 답변과 각 QA 쌍에 대한 GPT 메트릭. summary.json평균 GPT 메트릭과 같은 전체 결과입니다.
약한 프롬프트를 사용하여 두 번째 평가 실행
my_config.json구성 파일 속성을 편집합니다.속성 새 값 results_dir my_results/experiment_weakprompt_template <READFILE>my_input/prompt_weak.txt해당 약한 프롬프트에는 주체 도메인에 대한 컨텍스트가 없습니다.
You are a helpful assistant.터미널에서 다음 명령을 실행하여 평가를 실행합니다.
python -m evaltools evaluate --config=my_config.json --numquestions=14
특정 온도로 세 번째 평가 실행
더 많은 창의력을 발휘할 수 있는 프롬프트를 사용합니다.
my_config.json구성 파일 속성을 편집합니다.Existing 속성 새 값 Existing results_dir my_results/experiment_ignoresources_temp09Existing prompt_template <READFILE>my_input/prompt_ignoresources.txt새로 만들기 온도 0.9기본값
temperature은 0.7입니다. 온도가 높을수록 답변이 창의적입니다.프롬프트가
ignore짧습니다.Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!구성 개체는 경로로 바꾸기
results_dir를 제외하고 다음과 같이 표시됩니다.{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }터미널에서 다음 명령을 실행하여 평가를 실행합니다.
python -m evaltools evaluate --config=my_config.json --numquestions=14
평가 결과 검토
다양한 프롬프트 및 앱 설정에 따라 세 가지 평가를 수행했습니다. 결과는 폴더에 my_results 저장됩니다. 설정에 따라 결과가 어떻게 다른지 검토합니다.
검토 도구를 사용하여 평가 결과를 확인합니다.
python -m evaltools summary my_results결과는 다음과 같습니다.

각 값은 숫자와 백분율로 반환됩니다.
다음 표를 사용하여 값의 의미를 이해합니다.
값 설명 접지 이는 모델의 응답이 사실적이고 검증 가능한 정보를 기반으로 얼마나 잘 수행되는지를 나타냅니다. 응답은 실제로 정확하고 현실을 반영하는 경우 접지된 것으로 간주됩니다. 정확도 이렇게 하면 모델의 응답이 컨텍스트 또는 프롬프트와 얼마나 밀접하게 일치하는지 측정합니다. 관련 응답은 사용자의 쿼리 또는 문을 직접 다룹니다. 일관성 이는 모델의 응답이 논리적으로 얼마나 일치하는지를 나타냅니다. 일관된 응답은 논리적 흐름을 유지 관리하며 자체와 모순되지 않습니다. 인용 이는 프롬프트에서 요청된 형식으로 응답이 반환되었는지를 나타냅니다. Length 응답의 길이를 측정합니다. 결과는 세 가지 평가 모두 관련성이 높고 관련성이
experiment_ignoresources_temp09가장 낮음을 나타내야 합니다.평가에 대한 구성을 보려면 폴더를 선택합니다.
Ctrl + C를 입력하여 앱을 종료하고 터미널로 돌아갑니다.
답변 비교
평가에서 반환된 답변을 비교합니다.
비교할 평가 중 두 가지를 선택한 다음, 동일한 검토 도구를 사용하여 답변을 비교합니다.
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09결과를 검토합니다. 결과는 다를 수 있습니다.

Ctrl + C를 입력하여 앱을 종료하고 터미널로 돌아갑니다.
추가 평가를 위한 제안
- 프롬프트를
my_input편집하여 주체 도메인, 길이 및 기타 요인과 같은 답변을 조정합니다. my_config.json파일을 편집하여 같은temperature매개 변수를 변경하고semantic_ranker실험을 다시 실행합니다.- 다른 답변을 비교하여 프롬프트와 질문이 답변 품질에 미치는 영향을 이해합니다.
- Azure AI Search 인덱스의 각 문서에 대한 별도의 질문 및 근거 정답 집합을 생성합니다. 그런 다음 평가를 다시 실행하여 답변이 어떻게 다른지 확인합니다.
- 프롬프트 끝에 요구 사항을 추가하여 더 짧거나 긴 답변을 나타내도록 프롬프트를 변경합니다. 예들 들어
Please answer in about 3 sentences.입니다.
리소스 및 종속성 정리
Azure 리소스 정리
이 문서에서 만들어진 Azure 리소스는 Azure 구독에 요금이 청구됩니다. 앞으로 이러한 리소스가 필요하지 않을 것으로 예상되는 경우 추가 요금이 발생하지 않도록 삭제합니다.
Azure 리소스를 삭제하고 소스 코드를 제거하려면 다음 Azure Developer CLI 명령을 실행합니다.
azd down --purge
GitHub Codespaces 정리
GitHub Codespaces 환경을 삭제하면 계정에 대해 얻을 수 있는 코어당 무료 사용 권한을 최대화할 수 있습니다.
중요
GitHub 계정의 자격에 대한 자세한 내용은 GitHub Codespaces 월별 포함된 스토리지 및 코어 시간을 참조하세요.
GitHub Codespaces 대시보드(https://github.com/codespaces)에 로그인합니다.
Azure-Samples/ai-rag-chat-evaluatorGitHub 리포지토리에서 제공된 현재 실행 중인 Codespaces를 찾습니다.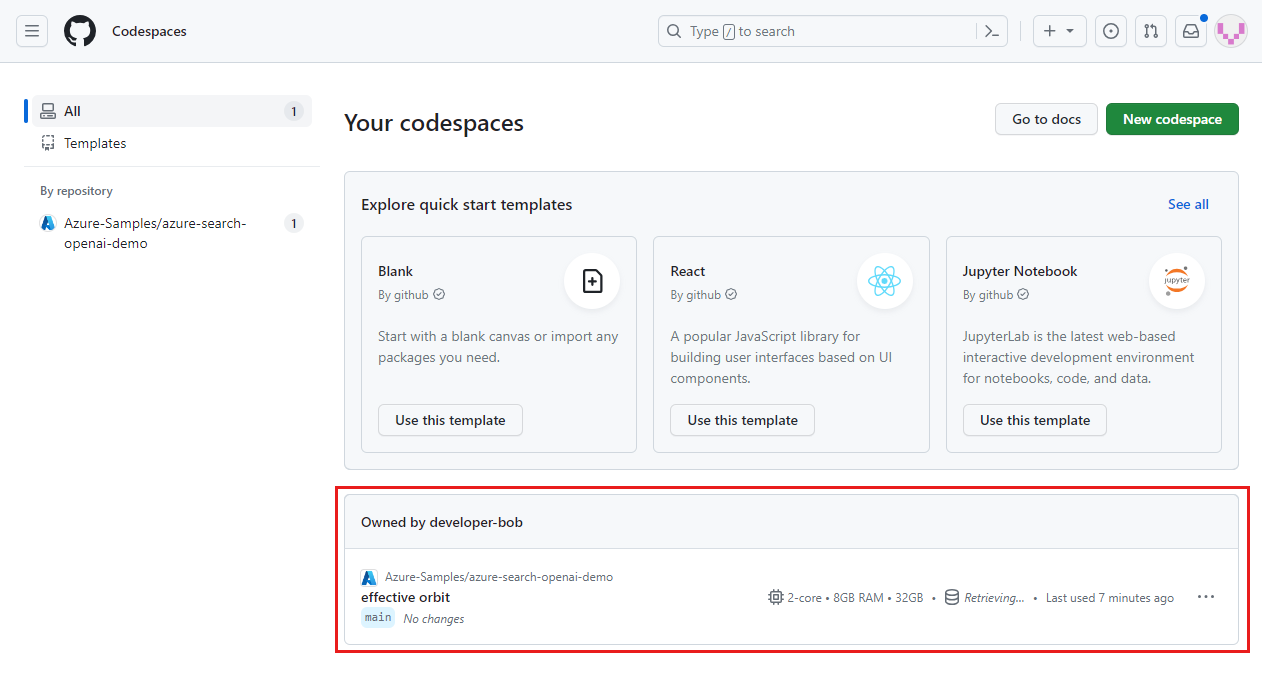
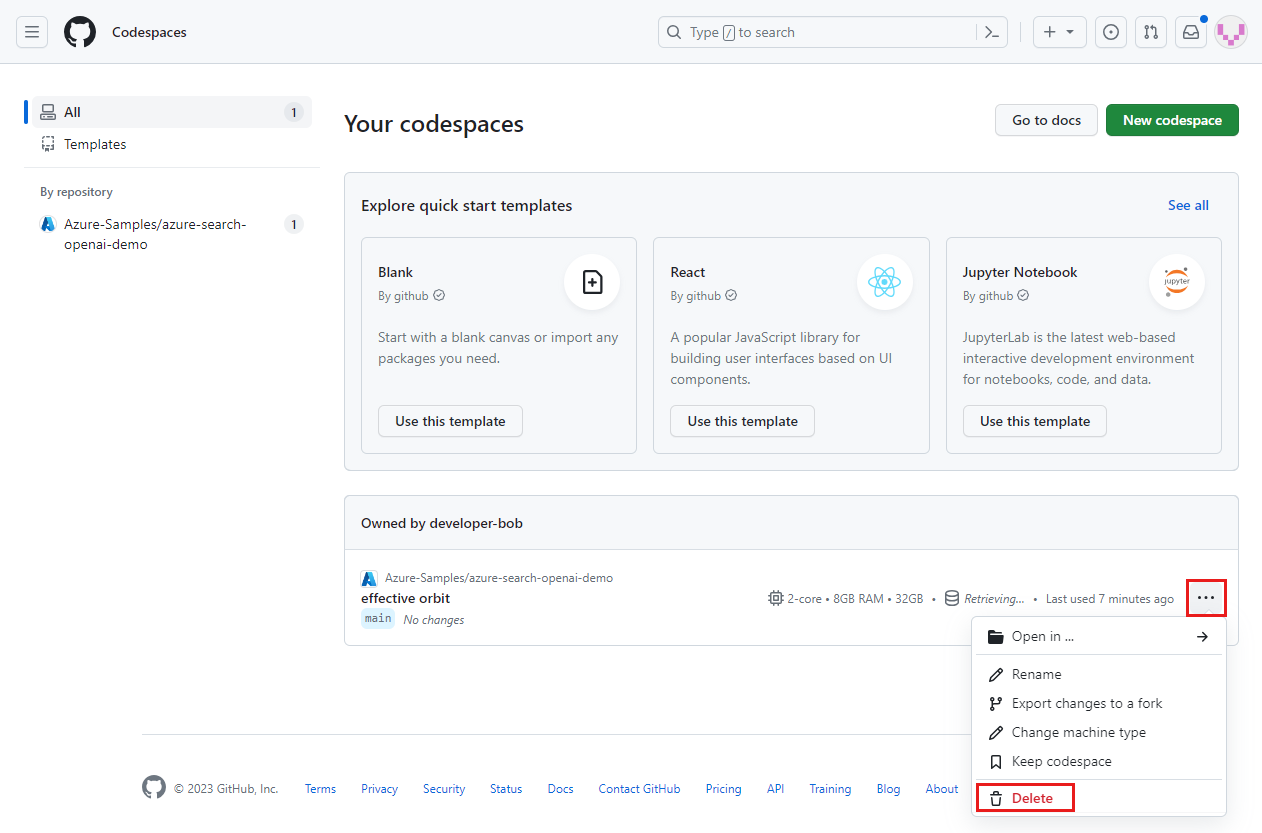
codespace에 대한 상황에 맞는 메뉴를 열고 삭제를 선택합니다.
채팅 앱 문서로 돌아가서 해당 리소스를 정리합니다.