Apache Kafka 및 Azure Cosmos DB에서 Apache Spark 정형 스트림 사용
Apache Spark정형 스트리밍을 사용하여 Azure HDInsight의 Apache Kafka에서 데이터를 읽은 다음, Azure Cosmos DB로 저장하는 방법을 알아봅니다.
Azure Cosmos DB는 전 세계에 배포된 다중 모델 데이터베이스입니다. 이 예에서는 Azure Cosmos DB for NoSQL 데이터베이스 모델을 사용합니다. 자세한 내용은 Azure Cosmos DB 시작 문서를 참조하세요.
Spark 구조적 스트림은 Spark SQL에서 작성된 스트림 처리 엔진입니다. 정적 데이터에 대한 일괄 처리 계산과 동일하게 스트리밍 계산을 표현할 수 있습니다. 구조적 스트림에 대한 자세한 내용은 Apache.org에서 구조적 스트림 프로그래밍 가이드를 참조하세요.
Important
이 예에서는 HDInsight 4.0에서 Spark 2.4를 사용합니다.
이 문서의 단계는 HDInsight의 Spark와 HDInsight의 Kafka 클러스터를 모두 포함하는 Azure 리소스 그룹을 만듭니다. 이러한 클러스터는 모두 Azure Virtual Network에 있으며, 여기서는 Spark 클러스터와 Kafka 클러스터 간에 직접 통신할 수 있습니다.
이 문서의 단계를 완료하는 경우 과도한 요금이 청구되지 않도록 클러스터를 삭제해야 합니다.
클러스터 만들기
HDInsight의 Apache Kafka는 공용 인터넷을 통한 액세스를 Kafka broker에 제공하지 않습니다. Kafka와 통신하는 대상은 Kafka 클러스터의 노드와 동일한 Azure 가상 네트워크에 있어야 합니다. 여기서는 Kafka 클러스터와 Spark 클러스터가 모두 Azure 가상 네트워크에 있습니다. 클러스터 간의 통신 흐름을 보여 주는 다이어그램은 다음과 같습니다.
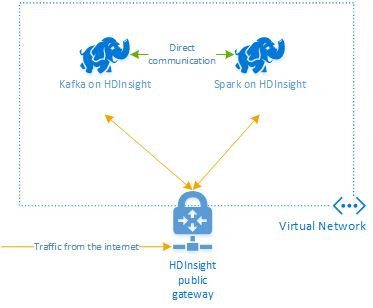
참고 항목
Kafka 서비스는 가상 네트워크 내에서 통신으로 제한됩니다. SSH 및 Ambari와 같은 클러스터의 다른 서비스는 인터넷을 통해 액세스할 수 있습니다. HDInsight에서 사용할 수 있는 공용 포트에 대한 자세한 내용은 HDInsight에서 사용하는 포트 및 URI를 참조하세요.
Azure 가상 네트워크, Kafka 클러스터 및 Spark 클러스터를 수동으로 만들 수 있지만 Azure Resource Manager 템플릿을 사용하는 것이 더 쉽습니다. 다음 단계에 따라 Azure 가상 네트워크, Kafka 클러스터 및 Spark 클러스터를 Azure 구독에 배포합니다.
Azure에 로그인하고 Azure Portal에서 템플릿을 열려면 다음 단추를 사용합니다.

Azure Resource Manager 템플릿은 이 프로젝트에 대한 GitHub 리포지토리에 위치합니다(https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb).
이 템플릿은 다음과 같은 리소스를 만듭니다.
HDInsight 4.0 클러스터의 Kafka
HDInsight 4.0 클러스터의 Spark
HDInsight 클러스터를 포함하는 Azure Virtual Network 템플릿에서 만든 가상 네트워크는 10.0.0.0/16 주소 공간을 사용합니다.
Azure Cosmos DB for NoSQL 데이터베이스.
Important
이 예에서 사용된 구조적 스트림 Notebook은 HDInsight 4.0의 Spark가 필요합니다. HDInsight에서 이전 버전의 Spark를 사용하면 Notebook을 사용하는 경우 발생하는 오류가 발생합니다.
다음 정보를 사용하여 사용자 지정 배포 섹션의 항목을 채웁니다.
속성 값 Subscription Azure 구독을 선택합니다. Resource group 그룹을 만들거나 기존 그룹을 선택합니다. 이 그룹에는 HDInsight 클러스터가 포함됩니다. Azure Cosmos DB 계정 이름 이 값은 Azure Cosmos DB 계정의 이름으로 사용됩니다. 이름은 소문자, 숫자 및 하이픈(-) 문자만 포함할 수 있으며, 3~31자여야 합니다. 기본 클러스터 이름 이 값은 Spark 및 Kafka 클러스터의 기본 이름으로 사용됩니다. 예를 들어, myhdi를 입력하면 spark-myhdi라는 Spark 클러스터와 kafka-myhdi라는 Kafka 클러스터가 만들어집니다. 클러스터 버전 HDInsight 클러스터 버전입니다. 이 예는 HDInsight 4.0을 사용하여 테스트되고 다른 클러스터 형식에서 작동하지 않을 수 있습니다. 클러스터 로그인 사용자 이름 Spark 및 Kafka 클러스터의 관리 사용자 이름입니다. 클러스터 로그인 암호 Spark 및 Kafka 클러스터의 관리자 사용자 암호입니다. SSH 사용자 이름 Spark 및 Kafka 클러스터에 만들 SSH 사용자입니다. SSH 암호 Spark 및 Kafka 클러스터에 대한 SSH 사용자의 암호입니다. 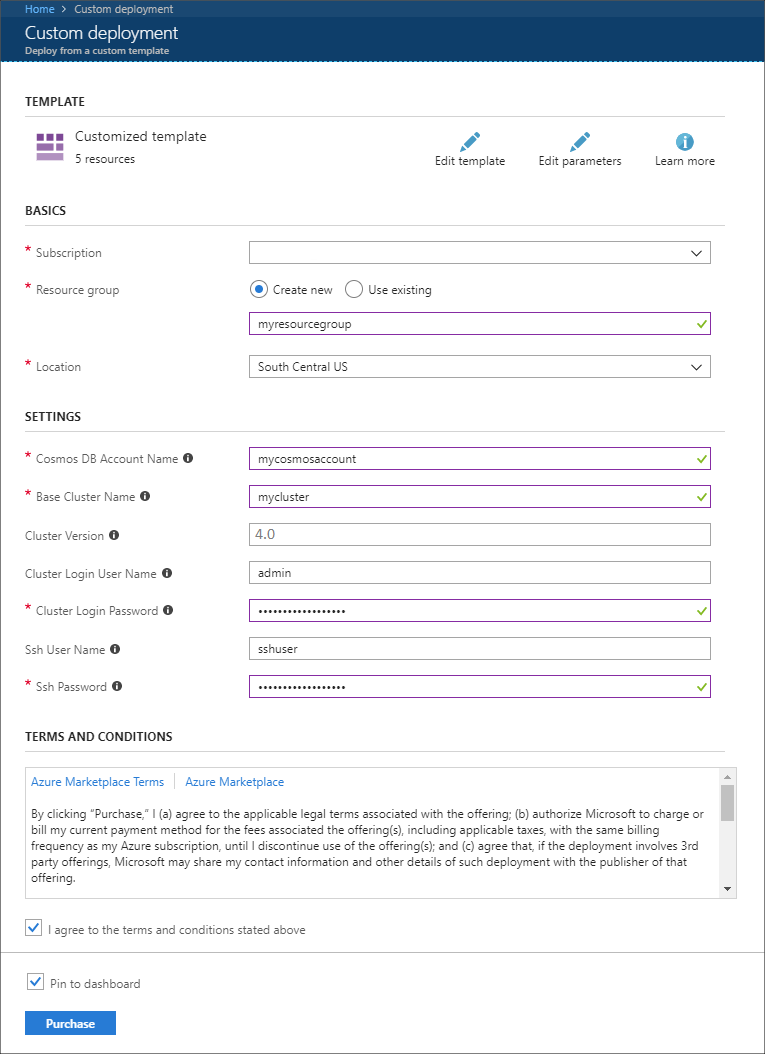
사용 약관을 읽은 다음 위에 명시된 사용 약관에 동의함을 선택합니다.
마지막으로, 구매를 선택합니다. 클러스터, 가상 네트워크 및 Azure Cosmos DB 계정을 만드는 데 최대 45분이 걸릴 수 있습니다.
Azure Cosmos DB 데이터베이스 및 컬렉션 만들기
이 문서에 사용된 프로젝트는 Azure Cosmos DB에 데이터를 저장합니다. 코드를 실행하기 전에 먼저 Azure Cosmos DB 인스턴스에서 데이터베이스 및 컬렉션을 만들어야 합니다. Azure Cosmos DB에 대한 요청을 인증하는 데 사용된 문서 엔드포인트 및 키도 검색해야 합니다.
이 작업을 수행하는 한 가지 방법은 Azure CLI를 사용하는 것입니다. 다음 스크립트는 kafkadata라는 데이터베이스 및 kafkacollection이라는 컬렉션을 만듭니다. 그런 다음, 기본 키를 반환합니다.
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
문서 엔드포인트 및 기본 키 정보는 다음 텍스트와 유사합니다.
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
Important
Jupyter Notebooks에 필요한 엔드포인트 및 키 값을 저장합니다.
Notebooks 가져오기
이 문서에 설명된 예제에 대한 코드는 https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb에서 지원됩니다.
Notebooks 업로드
프로젝트에서 HDInsight 클러스터의 Spark로 Notebooks을 업로드하려면 다음 단계를 사용합니다.
웹 브라우저의 Spark 클러스터에 있는 Jupyter Notebook에 연결합니다. 다음 URL에서
CLUSTERNAME을 Spark 클러스터의 이름으로 바꿉니다.https://CLUSTERNAME.azurehdinsight.net/jupyter메시지가 표시되면 클러스터를 만들 때 사용한 클러스터 로그인(관리자) 이름과 암호를 입력합니다.
페이지의 오른쪽 위에서 업로드 단추를 사용하여 Stream-taxi-data-to-kafka.ipynb 파일을 클러스터에 업로드합니다. 열기를 선택하여 업로드를 시작합니다.
Notebook 목록에서 Stream-taxi-data-to-kafka.ipynb 항목을 찾아 그 옆에 있는 업로드 단추를 선택합니다.
1~3단계를 반복하여 Stream-data-from-Kafka-to-Cosmos-DB.ipynb Notebook을 로드합니다.
Kafka에 택시 데이터 로드
파일이 업로드되면 Stream-taxi-data-to-kafka.ipynb 항목을 선택하여 Notebook을 엽니다. Notebook의 단계를 따라 Kafka로 데이터를 로드합니다.
Spark 구조적 스트림을 사용하여 택시 데이터 처리
Jupyter Notebook 홈페이지에서 Stream-data-from-Kafka-to-Cosmos-DB.ipynb 항목을 선택합니다. Notebook의 단계를 따라 Spark 구조적 스트림을 사용하여 Kafka에서 Azure Cosmos DB로 데이터를 스트리밍합니다.
다음 단계
이제 Apache Spark 정형 스트리밍을 사용하는 방법을 알아보았으므로 Apache Spark, Apache Kafka 및 Azure Cosmos DB에서 작업하는 방법에 대한 자세한 내용을 보려면 다음 문서를 참조하세요.