Data Lake tools for Visual Studio를 사용하여 Apache Hive 쿼리 실행
Data Lake Tools for Visual Studio를 사용하여 Apache Hive를 쿼리하는 방법을 알아봅니다. Data Lake 도구를 사용하면 Azure HDInsight에서 Apache Hadoop에 대해 Hive 쿼리를 쉽게 만들고, 제출하고, 모니터링할 수 있습니다.
필수 조건
HDInsight의 Apache Hadoop 클러스터. 이 항목을 만드는 방법에 대한 자세한 내용은 Resource Manager 템플릿을 사용하여 Azure HDInsight에서 Apache Hadoop 클러스터 만들기를 참조하세요.
Visual Studio. 이 문서의 단계에서는 Visual Studio 2019를 사용합니다.
Visual Studio용 HDInsight 도구 또는 Visual Studio용 Azure Data Lake 도구 도구를 설치하고 구성하는 방법에 대한 자세한 내용은 Data Lake Tools For Visual Studio 설치를 참조하세요.
Visual Studio를 사용하여 Apache Hive 쿼리 실행
Hive 쿼리를 만들고 실행하기 위한 두 가지 옵션이 있습니다.
- 임시 쿼리를 만듭니다.
- Hive 애플리케이션을 만듭니다.
임시 Hive 쿼리 만들기
임시 쿼리는 일괄 처리 또는 대화형 모드로 실행할 수 있습니다.
Visual Studio를 시작하고 코드를 사용하지 않고 계속을 선택합니다.
서버 탐색기에서 Azure를 마우스 오른쪽 단추로 클릭하고 Microsoft Azure 구독에 연결...을 선택하여 로그인 프로세스를 완료합니다.
HDInsight를 확장하고 쿼리를 실행하려는 클러스터를 마우스 오른쪽 단추로 클릭한 다음, Hive 쿼리 작성을 선택합니다.
다음 Hive 쿼리를 입력합니다.
SELECT * FROM hivesampletable;실행을 선택합니다. 실행 모드는 기본적으로 대화형으로 설정됩니다.
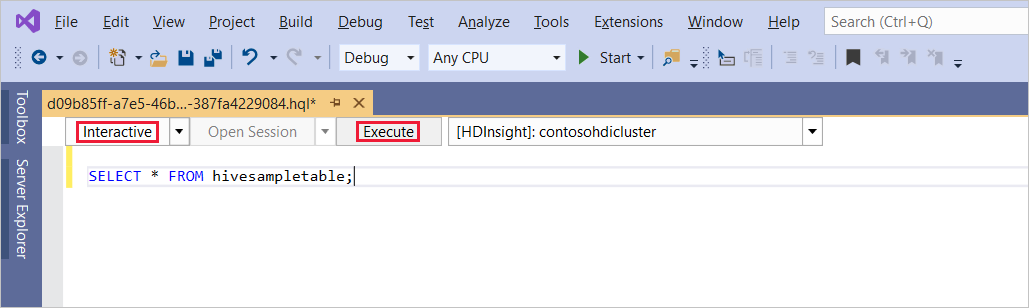
일괄 처리 모드에서 동일한 쿼리를 실행하려면 드롭다운 목록을 대화형에서 일괄 처리로 전환합니다. 실행 단추가 실행에서 제출로 변경됩니다.

Hive 편집기는 IntelliSense를 지원합니다. Data Lake Tools for Visual Studio는 Hive 스크립트를 편집할 때 원격 메타데이터 로드를 지원합니다. 예를 들어
SELECT * FROM을 입력하면 IntelliSense에서 제시된 테이블 이름을 모두 나열합니다. 테이블 이름이 지정되면 IntelliSense에서 열 이름을 나열합니다. 이 도구는 대부분의 Hive DML 문, 하위 쿼리 및 기본 제공 UDF를 지원합니다. IntelliSense는 HDInsight 도구 모음에서 선택한 클러스터의 메타데이터만 제안합니다.쿼리 도구 모음(쿼리 탭 아래, 쿼리 텍스트 위 영역)에서 제출을 선택하거나 제출 옆의 풀다운 화살표를 선택하고 풀다운 목록에서 고급을 선택합니다. 후자 옵션을 선택하는 경우
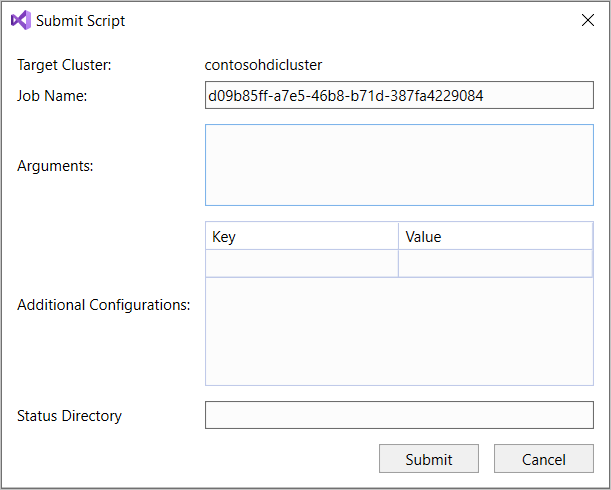
고급 제출 옵션을 선택하는 경우 스크립트 제출 대화 상자에서 작업 이름, 인수, 추가 구성 및 상태 디렉터리를 구성합니다. 그런 다음, 제출을 선택합니다.
Hive 애플리케이션 만들기
Hive 애플리케이션을 만들어 Hive 쿼리를 실행하려면 다음 단계를 수행합니다.
Visual Studio를 엽니다.
시작 창에서 새 프로젝트 만들기를 선택합니다.
새 프로젝트 만들기 대화 상자의 템플릿 검색 상자에 Hive를 입력합니다. 그런 다음, Hive 애플리케이션을 선택하고 다음을 선택합니다.
새 프로젝트 구성 창에서 프로젝트 이름을 입력하고 새 프로젝트의 위치를 선택하거나 만든 다음, 만들기를 선택합니다.
이 프로젝트에서 만든 Script.hql 파일을 열고 아래 HiveQL 문을 붙여 넣습니다.
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;이러한 문은 다음 작업을 수행합니다.
DROP TABLE: 테이블이 있으면 테이블을 삭제합니다.CREATE EXTERNAL TABLE: Hive에서 새 '외부' 테이블을 만듭니다. 외부 테이블만 테이블 정의를 Hive에 저장합니다. (데이터는 원래 위치에 그대로 유지됩니다.)참고 항목
MapReduce 작업 또는 Azure 서비스와 같은 외부 원본에서 기본 데이터를 업데이트해야 하는 경우 외부 테이블을 사용해야 합니다.
외부 테이블을 삭제하면 데이터는 삭제되지 않고 테이블 정의만 삭제됩니다.
ROW FORMAT: 데이터의 형식 지정 방식을 Hive에 알립니다. 이 경우, 각 로그의 필드는 공백으로 구분됩니다.STORED AS TEXTFILE LOCATION: 데이터가 example/data 디렉터리에 텍스트로 저장되었음을 Hive에 알립니다.SELECT:t4열에[ERROR]값이 포함된 모든 행의 수를 선택합니다. 이 문에서는 이 값을 포함하는 행이 3개 있으므로3값이 반환되어야 합니다.INPUT__FILE__NAME LIKE '%.log': .log로 끝나는 파일의 데이터만 반환하도록 Hive에 지시합니다. 이 절은 데이터가 포함된 sample.log 파일로 검색을 제한합니다.
임시 쿼리 도구 모음과 비슷한 모양의 쿼리 파일 도구 모음에서 이 쿼리에 사용할 HDInsight 클러스터를 선택합니다. 그런 다음, 대화형을 일괄 처리로 변경하고(필요한 경우) 제출을 선택하여 문을 Hive 작업으로 실행합니다.
Hive 작업 요약 이 표시되고 실행 중인 작업 정보가 표시됩니다. 작업 상태가 완료로 변경될 때까지 새로 고침 링크를 사용하여 작업 정보를 새로 고칩니다.
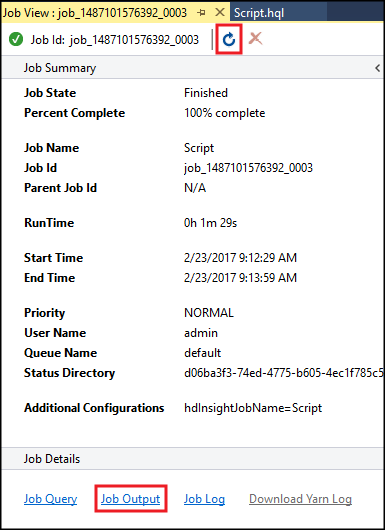
작업 출력을 선택하여 이 작업의 출력을 볼 수 있습니다. 이 쿼리로 반환된 값으로
[ERROR] 3이 표시되어야 합니다.
추가 예제
다음 예에서는 이전 절차, Hive 애플리케이션 만들기에서 만든 log4jLogs 테이블을 합니다.
서버 탐색기에서 클러스터를 마우스 오른쪽 단추로 클릭하고 Hive 쿼리 작성을 선택합니다.
다음 Hive 쿼리를 입력합니다.
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';이러한 문은 다음 작업을 수행합니다.
CREATE TABLE IF NOT EXISTS: 테이블이 아직 없는 경우 테이블을 만듭니다.EXTERNAL키워드가 사용되지 않으므로 이 문으로 내부 테이블이 생성됩니다. 내부 테이블은 Hive 데이터 웨어하우스에 저장되며 Hive에 의해 관리됩니다.참고 항목
EXTERNAL테이블과 달리 내부 테이블을 삭제하면 기본 데이터도 삭제됩니다.STORED AS ORC: 데이터를 ORC(Optimized Row Columnar) 형식으로 저장합니다. ORC는 Hive 데이터를 저장하기 위한 고도로 최적화되고 효율적인 형식입니다.INSERT OVERWRITE ... SELECT:[ERROR]가 포함된log4jLogs테이블에서 행을 선택하고 데이터를errorLogs테이블에 삽입합니다.
필요한 경우 대화형을 일괄 처리로 변경하고 제출을 선택합니다.
작업이 테이블을 만들었는지 확인하려면 서버 탐색기로 이동하여 Azure>HDInsight를 확장합니다. HDInsight 클러스터를 확장한 다음, Hive 데이터베이스>기본값을 확장합니다. errorLogs 테이블과 Log4jLogs 테이블이 나열됩니다.
다음 단계
여기에서 볼 수 있듯이 Visual Studio용 HDInsight 도구는 HDInsight에서 Hive 쿼리를 수행하는 쉬운 방법을 제공합니다.
HDInsight의 Hive에 대한 일반적인 내용은 Azure HDInsight의 Apache Hive 및 HiveQL이란?을 참조하세요.
HDInsight에서 Hadoop으로 작업하는 다른 방법에 대한 자세한 내용은 hdinsight의 Apache Hadoop에서 MapReduce 사용을 참조하세요.
HDInsight Tools for Visual Studio에 대한 자세한 내용은Data Lake Tools for Visual Studio를 사용하여 Azure HDInsight에 연결 및 Apache Hive 쿼리 실행을 참조하세요.