Azure HDInsight 클러스터 자동 크기 조정
Azure HDInsight의 무료 자동 크기 조정 기능은 고객이 채택한 클러스터 메트릭과 크기 조정 정책에 따라 클러스터의 작업자 노드 수를 자동으로 늘리거나 줄일 수 있습니다. 자동 크기 조정 기능은 스케일 업 및 스케일 다운 작업의 성능 메트릭이나 정의된 일정에 따라 미리 설정된 제한 내에서 노드 수를 조정하여 작동합니다.
작동 방식
자동 크기 조정 기능은 다음 두 가지 조건 유형을 사용하여 크기 조정 이벤트를 트리거합니다. 하나는 다양한 클러스터 성능 메트릭에 대한 임계값(부하 기반 크기 조정이라고 함)이고, 다른 하나는 시간 기반 트리거(일정 기반 크기 조정이라고 함)입니다. 최적의 CPU 사용량을 보장하고 실행 비용을 최소화하기 위해, 부하 기반 크기 조정에서는 설정하는 범위 내에서 클러스터의 노드 수를 변경합니다. 일정 기반 크기 조정은 확대 및 축소 작업의 일정에 따라 클러스터의 노드 수를 변경합니다.
다음 비디오는 자동 크기 조정에서 해결하는 문제와 HDInsight를 사용하여 비용을 관리하는 데 도움이 되는 방법에 대한 개요를 제공합니다.
부하 기반 또는 일정 기반 크기 조정 선택
일정 기반 크기 조정을 사용할 수 있습니다.
- 작업이 고정 일정과 예측 가능한 기간 동안 실행될 것으로 예상되는 경우 또는 하루 중 특정 시간 동안 사용량이 낮을 것으로 예상되는 경우(예: 근무 후 시간, 하루 작업 종료 후의 테스트 및 개발 환경)
부하 기반 크기 조정을 사용할 수 있습니다.
- 부하 패턴이 하루 동안 예측 불가능하게 심하게 변동하는 경우. 예: 다양한 요인에 따라 부하 패턴 임의 변동을 사용하여 데이터 처리 순서 지정
클러스터 메트릭
자동 크기 조정은 지속적으로 클러스터를 모니터링하면서 다음 메트릭을 수집합니다.
| 메트릭 | Description |
|---|---|
| 보류 중인 총 CPU | 보류 중인 모든 컨테이너의 실행을 시작하는 데 필요한 총 코어 수입니다. |
| 보류 중인 총 메모리 | 보류 중인 모든 컨테이너의 실행을 시작하는 데 필요한 총 메모리(MB)입니다. |
| 사용 가능한 총 CPU | 활성 작업자 노드에서 사용되지 않는 모든 코어의 합계입니다. |
| 사용 가능한 총 메모리 | 활성 작업자 노드에서 사용되지 않는 메모리(MB)의 합계입니다. |
| 노드당 사용되는 메모리 | 작업자 노드의 부하입니다. 메모리 사용량이 10GB인 작업자 노드는 메모리 사용량이 2GB인 작업자보다 부하가 많은 것으로 간주됩니다. |
| 노드당 애플리케이션 마스터 수: | 작업자 노드에서 실행되는 AM(애플리케이션 마스터) 수입니다. 2개의 AM 컨테이너를 호스트하는 작업자 노드는 제로 AM 컨테이너를 호스트하는 작업자 노드 보다 더 중요 한 것으로 간주됩니다. |
위의 메트릭은 60초마다 확인됩니다. 자동 크기 조정은 이러한 메트릭을 기반으로 스케일 업 및 스케일 다운 의사 결정을 내립니다.
부하 기반 크기 조정 조건
다음 조건이 감지되면 자동 크기 조정에서 크기 조정 요청을 실행합니다.
| 강화 | 스케일 다운 |
|---|---|
| 보류 중인 총 CPU가 3~5분 이상 사용 가능한 총 CPU보다 큽니다. | 보류 중인 총 CPU가 3~5분 이상 사용 가능한 총 CPU보다 작습니다. |
| 보류 중인 총 메모리가 3~5분 이상 사용 가능한 총 메모리보다 큽니다. | 보류 중인 총 메모리가 3~5분 이상 사용 가능한 총 메모리보다 작습니다. |
확대의 경우, 자동 크기 조정에서 필요한 노드 수를 추가하기 위한 확대 요청을 발행합니다. 확대는 현재 CPU 및 메모리 요구 사항을 충족하는 데 필요한 새 작업자 노드 수를 기반으로 합니다.
규모 축소의 경우 자동 크기 조정에서 일부 노드를 제거하라는 요청을 발행합니다. 스케일 다운은 노드당 AM(애플리케이션 마스터) 컨테이너 수를 기반으로 합니다. 그리고 현재 CPU 및 메모리 요구 사항. 또한 서비스는 현재 작업 실행을 기반으로 제거할 후보를 검색합니다. 스케일 다운 작업은 먼저 노드를 해제한 다음, 클러스터에서 제거합니다.
자동 크기 조정에 대한 Ambari DB 크기 조정 고려 사항
자동 크기 조정의 이점을 얻으려면 Ambari DB의 크기를 올바르게 조정하는 것이 좋습니다. 고객은 올바른 DB 계층을 사용하고 대규모 클러스터에 사용자 지정 Ambari DB를 사용해야 합니다. 데이터베이스 및 헤드 노드 크기 조정 권장 사항을 읽어보세요.
클러스터 호환성
Important
Azure HDInsight 자동 크기 조정 기능은 Spark 및 Hadoop 클러스터를 위해 2019년 11월 7일에 일반 공급되고, 해당 기능의 미리 보기 버전에서는 사용할 수 없는 향상된 기능이 포함되어 있습니다. 2019년 11월 7일 이전에 Spark 클러스터를 만들었고 클러스터에서 자동 크기 조정 기능을 사용하려는 경우 새 클러스터를 만들고 새 클러스터에서 자동 크기 조정 기능을 사용하도록 설정하는 것이 좋습니다.
LLAP(대화형 쿼리)에 대한 자동 크기 조정은 2020년 8월 27일에 HDI 4.0에 대한 일반 공급으로 릴리스되었습니다. Spark, Hadoop, Interactive Query 및 클러스터에서만 자동 크기 조정을 사용할 수 있습니다.
다음 표에서는 자동 크기 조정 기능과 호환되는 클러스터 유형 및 버전을 설명합니다.
| 버전 | Spark | Hive | 대화형 쿼리 | HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0(ESP 제외) | 예 | 예 | 예* | 아니요 | 아니요 |
| HDInsight 4.0(ESP 포함) | 예 | 예 | 예* | 아니요 | 아니요 |
| HDInsight 5.0(ESP 제외) | 예 | 예 | 예* | 아니요 | 아니요 |
| HDInsight 5.0(ESP 포함) | 예 | 예 | 예* | 아니요 | 아니요 |
* Interactive Query 클러스터는 부하를 기반으로 하지 않는 일정 기반 크기 조정에만 구성될 수 있습니다.
시작하기
부하 기반 자동 크기 조정을 사용하여 클러스터 만들기
부하 기반 크기 조정에 자동 크기 조정 기능을 사용하려면, 일반 클러스터 만들기 프로세스의 일부로 다음을 수행합니다.
구성 + 가격 책정 탭에서 자동 크기 조정 사용 확인란을 선택합니다.
자동 크기 조정 유형아래에서 부하 기반을 선택합니다.
다음 속성에 대해 원하는 값을 입력합니다.
- 작업자 노드에대 한 초기 노드 수.
- 최소 작업자 노드의 수.
- 최대 작업자 노드의 수.
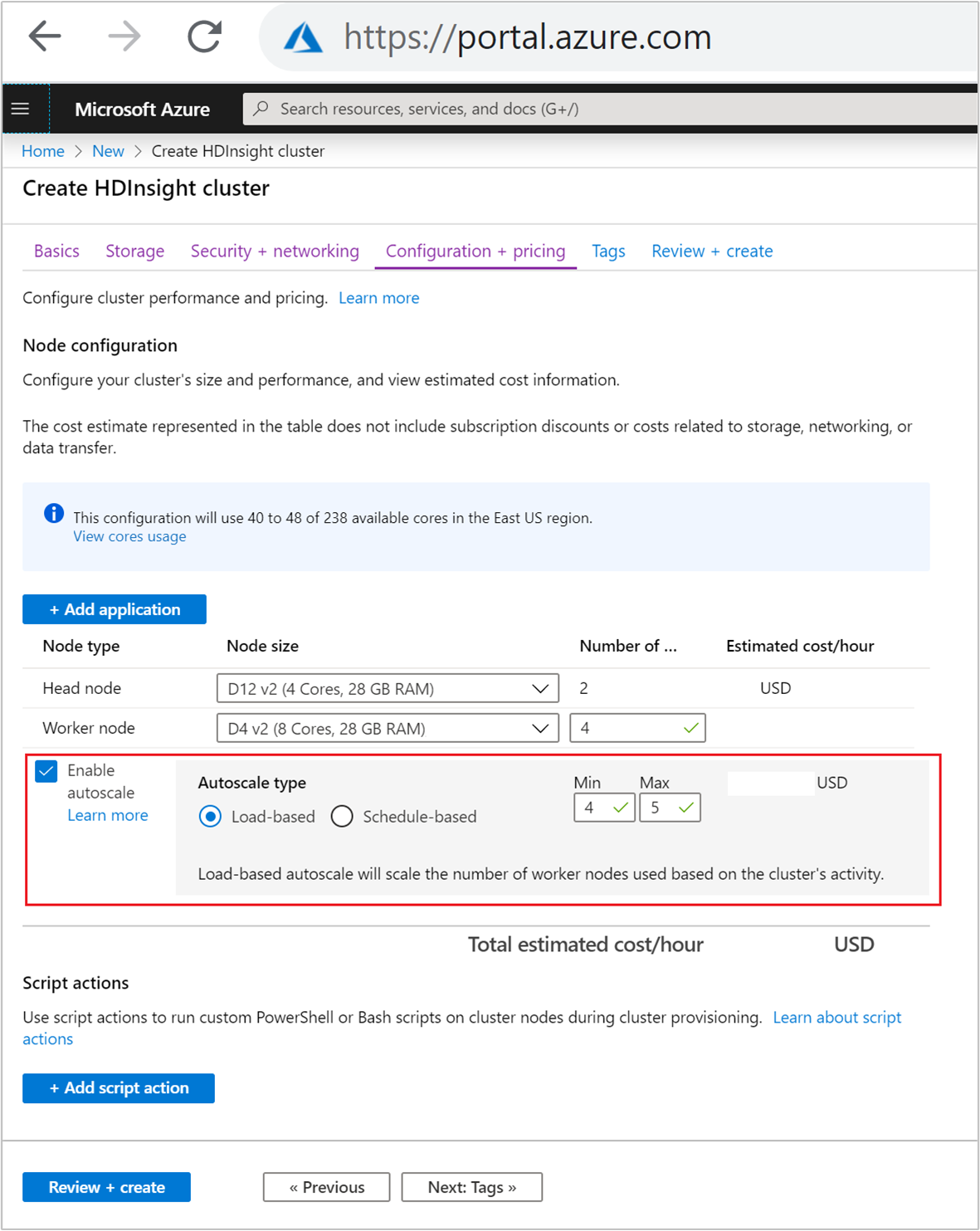
초기 작업자 노드 수는 최소 작업자 노드 수~최대 작업자 노드 수 사이여야 합니다(최댓값 및 최솟값 포함). 이 값은 클러스터를 만들 때 초기 크기를 정의합니다. 최소 작업자 노드 수는 3개 이상으로 설정해야 합니다. 클러스터를 3개 미만의 노드로 크기 조정하면 파일 복제가 충분하지 않기 때문에 안전 모드에서 중단될 수 있습니다. 자세한 내용은 안전 모드에서 중단을 참조하세요.
일정 기반 자동 크기 조정을 사용하여 클러스터 만들기
일정 기반 크기 조정에 자동 크기 조정 기능을 사용하려면, 일반 클러스터 만들기 프로세스의 일부로 다음을 수행합니다.
구성 + 가격 책정 탭에서 자동 크기 조정 사용 확인란을 선택합니다.
작업자 노드에 노드 수를 입력합니다. 이 작업자 노드는 클러스터의 크기 조정에 대한 제한을 제어합니다.
자동 크기 조정 유형아래에서 일정 기반 옵션을 선택합니다.
구성을 선택하여 자동 크기 조정 구성 창을 엽니다.
시간대를 선택하고 + 조건 추가를 클릭합니다.
새 조건이 적용되는 주의 날짜를 선택합니다.
조건이 적용되는 시간 및 클러스터의 크기를 조정해야 하는 노드 수를 편집합니다.
필요한 경우 조건을 더 추가합니다.
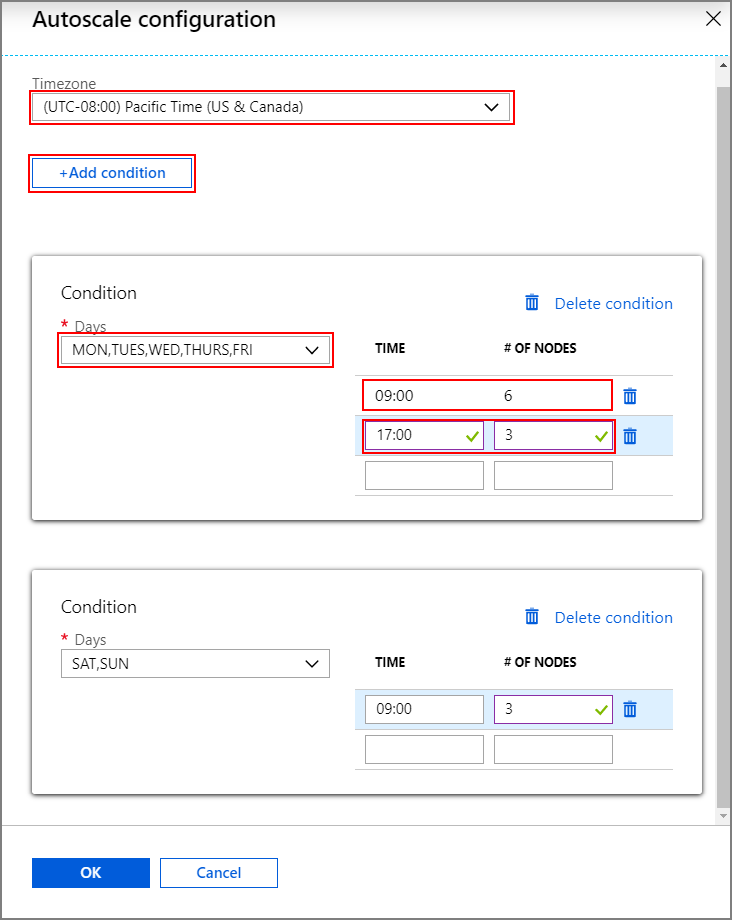
노드 수는 3개와 조건을 추가하기 전에 입력한 최대 작업자 노드 수 사이에 있어야 합니다.
최종 만들기 단계
노드 크기아래의 드롭다운 목록에서 VM을 선택하여 작업자 노드의 VM 유형을 선택합니다. 각 노드 형식의 VM 유형을 선택하면 전체 클러스터의 예상 비용 범위를 볼 수 있습니다. VM 유형을 예산에 맞게 조정합니다.
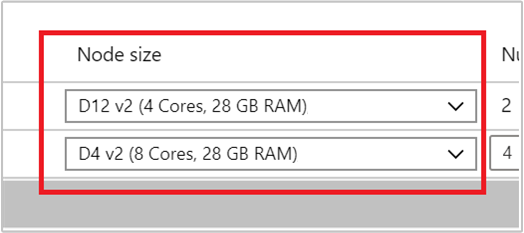
구독에는 각 Azure 지역에 대한 용량 할당량이 있습니다. 헤드 노드의 코어와 최대 작업자 노드의 총 수는 용량 할당량을 초과하면 안됩니다. 그러나 이 할당량은 소프트 제한이며, 언제든지 지원 티켓을 만들어서 간편하게 할당량을 늘릴 수 있습니다.
참고 항목
총 코어 할당량 제한을 초과하면, '최대 노드 수가 이 지역에서 사용 가능한 코어 수를 초과했습니다. 다른 지역을 선택하거나 고객 지원팀에 문의하여 할당량을 늘리세요'라는 내용의 오류 메시지를 받게 됩니다.
Azure Portal을 사용하여 HDInsight 클러스터를 만드는 방법에 대한 자세한 내용은 Azure Portal을 사용하여 HDInsight에서 Linux 기반 클러스터 만들기를 참조하세요.
Resource Manager 템플릿을 사용하여 클러스터 만들기
부하 기반 자동 크기 조정
json 코드 조각에 표시된 대로 minInstanceCount 및 maxInstanceCount 속성을 사용하여 computeProfile>workernode 섹션에 autoscale 노드를 추가하는 방법으로, Azure Resource Manager 템플릿의 부하 기반 자동 크기 조정을 사용하여 HDInsight 클러스터를 만들 수 있습니다. 전체 Resource Manager 템플릿에 대한 정보는 빠른 시작 템플릿: 부하 기반 자동 크기 조정을 사용하는 Spark Cluster 배포를 참조하세요.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
일정 기반 자동 크기 조정
computeProfile>workernode섹션에 autoscale 노드를 추가하여, Azure Resource Manager 템플릿의 일정 기반 자동 크기 조정을 사용하여 HDInsight 클러스터를 만들 수 있습니다. autoscale 노드에는 변경이 발생하는 시기를 설명하는 timezone및 schedule가 있는 recurrence가 포함됩니다. 전체 리소스 관리자 템플릿은 일정 기반 자동 크기 조정을 사용하는 Spark Cluster 배포를 참조하세요.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
실행 중인 클러스터에 자동 크기 조정 사용 및 사용 안 함
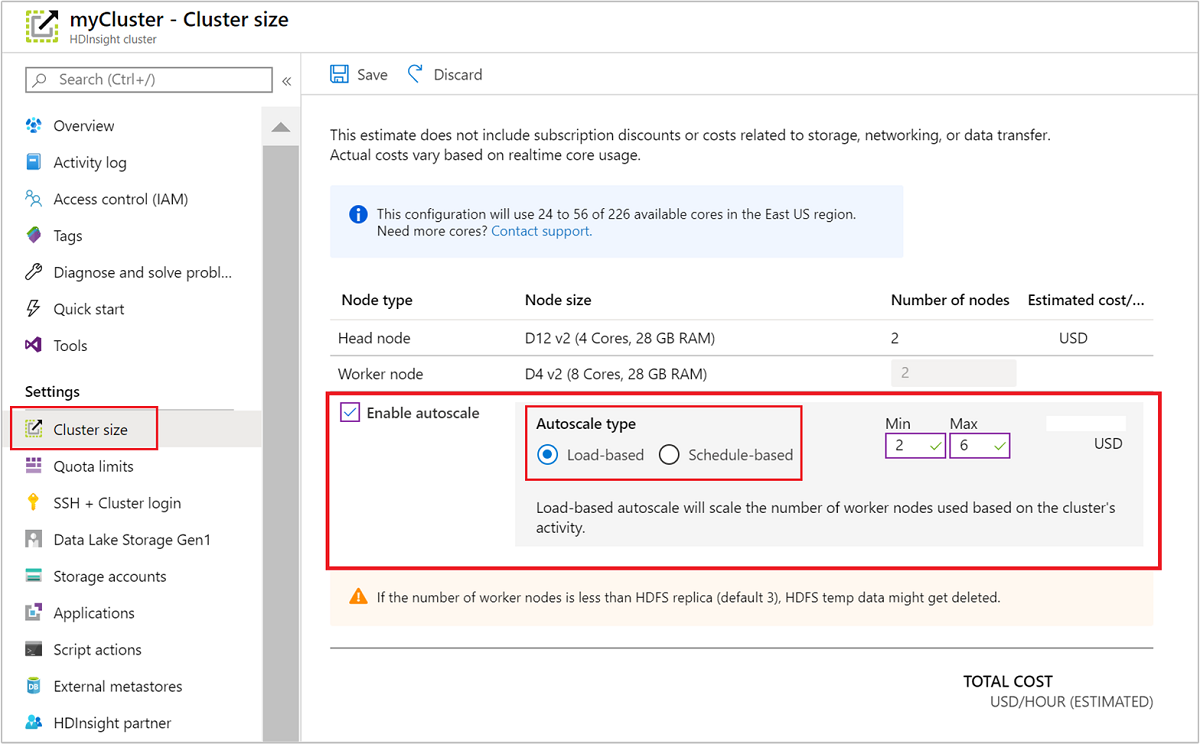
Azure 포털 사용하기
실행 중인 클러스터에 자동 크기 조정을 사용하도록 설정하려면, 설정 아래에서 클러스터 크기를 선택합니다. 그런 다음 자동 크기 조정 사용을 선택합니다. 원하는 자동 크기 조정 유형을 선택하고, 부하 기반 또는 일정 기반 크기 조정 옵션을 입력합니다. 마지막으로 저장을 선택합니다.
REST API 사용
REST API를 사용하여 실행 중인 클러스터에서 자동 크기 조정을 사용하거나 사용하지 않도록 설정하려면, 자동 크기 조정 엔드포인트에 대한 POST 요청을 수행합니다.
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
요청 페이로드에서 적절한 매개 변수를 사용합니다. 다음 json 페이로드를 사용하여 자동 크기 조정을 사용하도록 설정할 수 있습니다. 페이로드 {autoscale: null}를 사용하 여 자동 크기 조정을 사용하지 않도록 설정합니다.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
모든 페이로드 매개 변수에 대한 전체 설명은 부하 기반 자동 크기 조정 사용에 대한 이전 섹션을 참조하세요. 실행 중인 클러스터에서 자동 크기 조정 서비스를 강제로 사용하지 않는 것은 권장되지 않습니다.
자동 크기 조정 작업 모니터링
클러스터 상태
Azure Portal에 나열된 클러스터 상태를 통해 자동 크기 조정 작업을 모니터링할 수 있습니다.
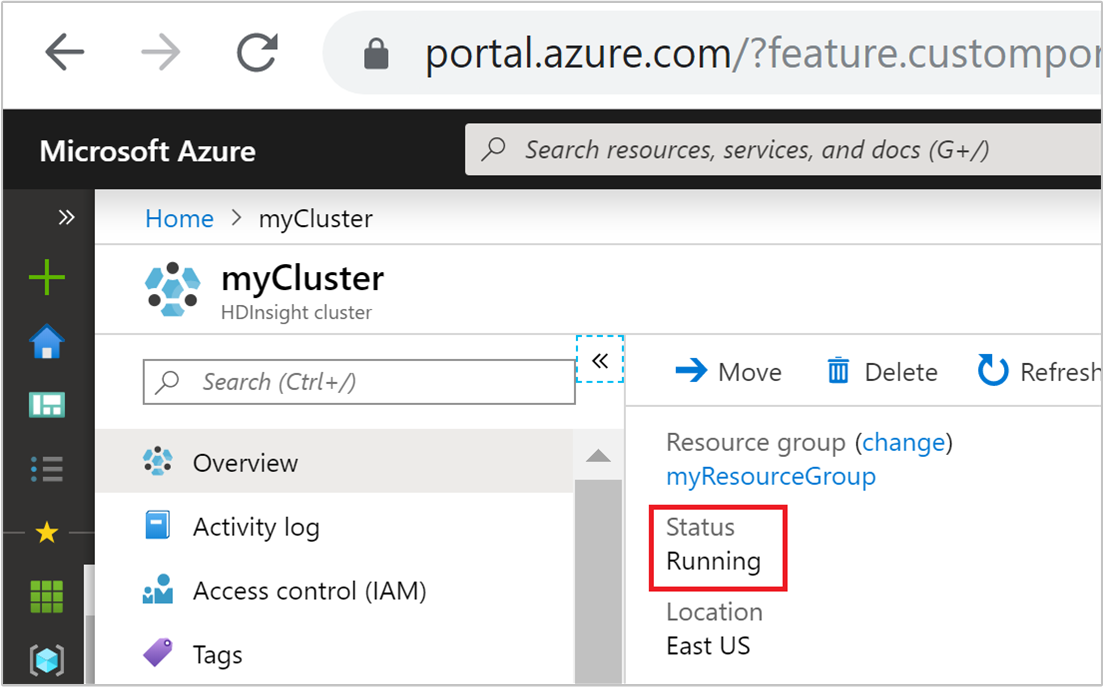
표시될 수 있는 모든 클러스터 상태 메시지는 다음 목록에 설명되어 있습니다.
| 클러스터 상태 | 설명 |
|---|---|
| 실행 중 | 클러스터가 정상적으로 작동하고 있습니다. 모든 이전 자동 크기 조정 작업이 성공적으로 완료 되었습니다. |
| 업데이트 | 클러스터 자동 크기 조정 구성을 업데이트하고 있습니다. |
| HDInsight 구성 | 클러스터 확대 또는 축소 작업이 진행 중입니다. |
| 업데이트 오류 | HDInsight에서 자동 크기 조정 구성 업데이트 중에 문제가 발생 했습니다. 고객은 업데이트를 다시 시도하거나 자동 크기 조정을 사용하지 않도록 선택할 수 있습니다. |
| 오류 | 클러스터에 문제가 있어 사용할 수 없습니다. 이 클러스터를 삭제하고 새 클러스터를 만듭니다. |
클러스터의 현재 노드 수를 보려면 클러스터의 개요 페이지에서 클러스터 크기 차트로 이동합니다. 또는 설정에서 클러스터 크기를 선택합니다.
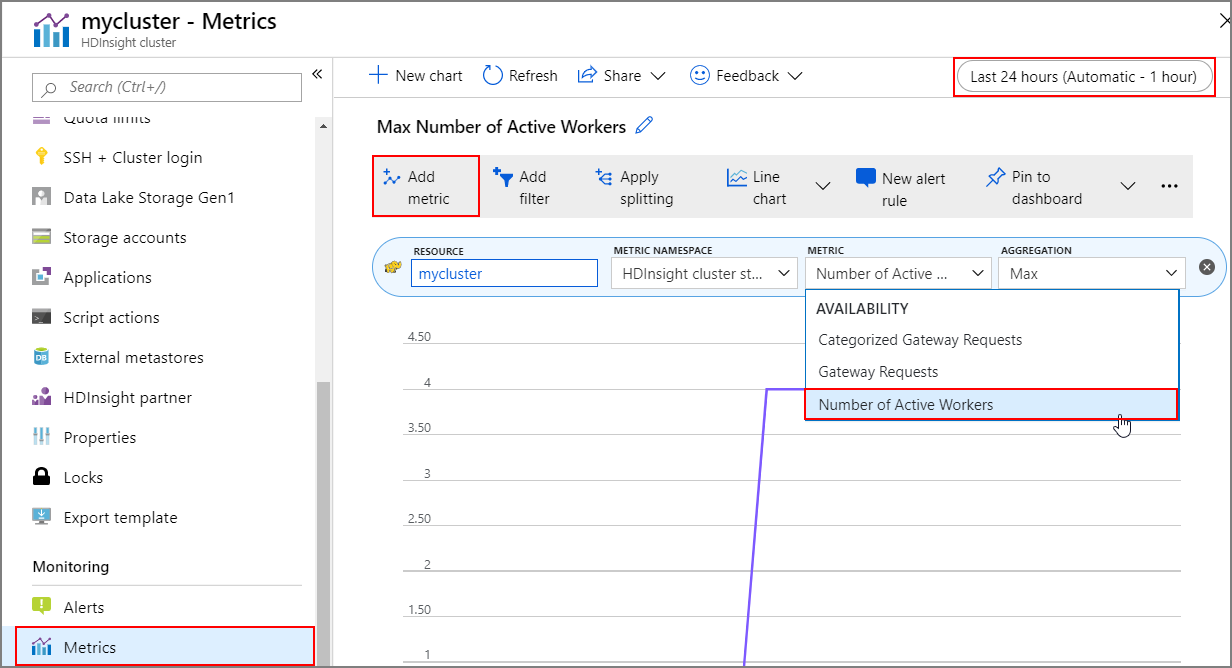
작업 기록
클러스터 메트릭의 일부로 클러스터 확대 및 축소 기록을 볼 수 있습니다. 어제, 지난주 또는 기타 기간의 크기 조정 작업도 모두 나열할 수 있습니다.
모니터링에서 메트릭을 선택합니다. 그런 다음 메트릭 드롭다운 상자에서 메트릭 추가 및 활성 작업자 수를 선택합니다. 오른쪽 위에 있는 단추를 선택하여 시간 범위를 변경합니다.
모범 사례
확대 또는 축소 작업의 대기 시간 고려
전체 크기 조정 작업을 완료하는 데 10~20분 정도 걸릴 수 있습니다. 사용자 지정 일정을 설정하는 경우, 이 지연 시간을 계획합니다. 예를 들어 오전 9:00에 클러스터 크기를 20으로 조정해야 하는 경우 크기 조정 작업이 오전 9:00까지 완료되도록 일정 트리거를 오전 8:30과 같은 이른 시간으로 설정합니다.
스케일 다운 준비
클러스터 크기를 축소하는 동안, 자동 크기 조정은 노드를 해제하여 대상 크기에 맞춥니다. 부하 기반 자동 크기 조정의 경우 작업이 해당 노드에서 실행 중이면 Spark 클러스터와 Hadoop 클러스터에 대한 작업이 완료될 때까지 자동 크기 조정이 대기합니다. 또한 각 작업자 노드는 HDFS에서 역할을 수행하므로 임시 데이터는 나머지 작업자 노드로 이동합니다. 나머지 노드에 모든 임시 데이터를 호스트할 수 있는 충분한 공간이 있는지 확인합니다.
참고 항목
일정 기반 자동 크기 조정 스케일 다운의 경우 정상적인 서비스 해제가 지원되지 않습니다. 이로 인해 스케일 다운 작업 중에 작업이 실패할 수 있으며 진행 중인 작업이 완료될 수 있는 충분한 시간이 포함되도록 일정을 예상 작업 일정 패턴에 따라 계획하는 것이 좋습니다. 작업이 실패하지 않도록 완료 시간의 기록 확산을 보면서 일정을 설정할 수 있습니다.
사용 패턴에 따라 일정 기반 자동 크기 조정 구성
일정 기반 자동 크기 조정을 구성할 때 클러스터 사용 패턴을 이해해야 합니다. Grafana 대시보드는 쿼리 부하 및 실행 슬롯을 이해하는 데 도움이 될 수 있습니다. 이 대시보드에서 사용 가능한 실행기 슬롯과 총 실행기 슬롯을 가져올 수 있습니다.
필요한 작업자 노드 수를 예측할 수 있는 방법은 다음과 같습니다. 워크로드의 변형을 처리하려면 10%의 다른 버퍼를 제공하는 것이 좋습니다.
사용된 실행기 슬롯 수 = 총 실행기 슬롯 – 사용 가능한 총 실행기 슬롯.
필요한 작업자 노드 수 = 실제로 사용된 실행기 슬롯 수 / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size)
*hive.llap.daemon.num.executors는 구성 가능하며 기본값은 4입니다.
*hive.llap.daemon.task.scheduler.wait.queue.size는 구성 가능하며 기본값은 10입니다.
사용자 지정 스크립트 작업
사용자 지정 스크립트 작업은 고객이 자신이 사용하는 특정 라이브러리와 도구를 구성할 수 있게 해주는 노드(즉, HeadNode/WorkerNodes)를 사용자 지정하는 데 주로 사용됩니다. 일반적인 사용 사례 하나는 클러스터에서 실행되는 작업에 고객이 소유한 타사 라이브러리에 대한 일부 종속성이 있을 수 있으며 작업이 성공하려면 노드에서 사용할 수 있어야 한다는 점입니다. 자동 크기 조정의 경우 현재 Microsoft는 유지되는 사용자 지정 스크립트 작업을 지원하므로 스케일 업 작업의 일부로 새 노드가 클러스터에 추가될 때마다 이러한 지속형 스크립트 작업이 실행되고 컨테이너 또는 작업이 할당된다고 게시합니다. 사용자 지정 스크립트 작업은 새 노드를 부트스트랩하는 데 도움이 되지만 전체 스케일 업 대기 시간이 증가하고 예약된 작업이 영향을 받을 수 있으므로 최소화하는 것이 좋습니다.
최소 클러스터 크기를 알고 있어야 합니다.
클러스터를 3개 미만의 노드로 축소하지 마십시오. 클러스터를 3개 미만의 노드로 크기 조정하면 파일 복제가 충분하지 않기 때문에 안전 모드에서 중단될 수 있습니다. 자세한 내용은 안전 모드에서 중단을 참조하세요.
Microsoft Entra Domain Services 및 크기 조정 작업
Microsoft Entra Domain Services 관리되는 도메인에 조인된 ESP(Enterprise Security Package)와 함께 HDInsight 클러스터를 사용하는 경우 Microsoft Entra Domain Services에서 부하를 제한하는 것이 좋습니다. 복잡한 디렉터리 구조 범위 동기화의 경우 크기 조정 작업에 영향을 주지 않는 것이 좋습니다.
최대 사용량 시나리오에 대한 Hive 구성 최대 총 동시 쿼리 수 설정
자동 크기 조정 이벤트는 Ambari에서 Hive 구성의 최대 총 동시 쿼리를 변경하지 않습니다. 즉, Hive Server 2 Interactive Service는 부하 및 일정에 따라 Interactive Query 디먼 수가 확대 및 축소되는 경우에도 언제든지 지정된 수의 동시 쿼리를 처리할 수 있습니다. 일반적인 권장 사항은 수동 작업을 방지하기 위해 최고 사용량 시나리오에 대해 이 구성을 설정하는 것입니다.
그러나 적은 수의 작업자 노드만 있고 최대 총 동시 쿼리 수 값이 너무 높게 구성된 경우, Hive Server 2 재시작 실패가 발생할 수 있습니다. 최소한 지정된 수의 Tez Ams(최대 총 동시 쿼리 구성과 동일)를 수용할 수 있는 최소 작업자 노드 수와 동일해야 합니다.
제한 사항
Interactive Query 디먼 수
자동 크기 조정 가능 Interactive Query 클러스터의 경우, 자동 크기 조정 확대/축소 이벤트는 Interactive Query 디먼의 수를 활성 작업자 노드 수로 확장/축소합니다. 디먼 수의 변경 내용은 Ambari의 num_llap_nodes 구성에서 계속 유지되지 않습니다. Hive 서비스를 수동으로 다시 시작하는 경우, Ambari의 구성에 따라 Interactive Query 디먼 수가 다시 설정됩니다.
Interactive Query 서비스를 수동으로 다시 시작하는 경우, Advanced hive-interactive-env에서 현재 활성 작업자 노드 수와 일치하도록 num_llap_node 구성(Hive Interactive Query 디먼을 실행하는 데 필요한 노드 수)을 수동으로 변경해야 합니다. Interactive Query 클러스터에서는 일정 기반 자동 크기 조정만 지원합니다.
다음 단계
크기 조정 지침에서 클러스터 크기를 수동으로 조정하는 지침에 대해 알아보세요.