이 문서에서는 Azure HDInsight 실행 방법에 대한 가장 일반적인 질문에 대한 답변을 제공합니다.
HDInsight 클러스터 만들기 또는 삭제
HDInsight 클러스터를 어떻게 프로비저닝하나요?
HDInsight 클러스터 유형 및 프로비저닝 방법을 검토하려면 Apache Hadoop, Apache Spark, Apache Kafka 등을 사용하여 HDInsight에서 클러스터 설정을 참조하세요.
기존 HDInsight 클러스터를 삭제하려면 어떻게 해야 하나요?
더 이상 사용하지 않는 클러스터를 삭제하는 방법에 대한 자세한 내용은 HDInsight 클러스터 삭제를 참조하세요.
만들기 작업과 삭제 작업 사이에 30~60분 이상 간격을 두세요. 그러지 않으면 다음 오류 메시지와 함께 작업이 실패할 수 있습니다.
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
워크로드에 대한 올바른 코어 또는 노드의 수는 어떻게 선택하나요?
적절한 코어의 수와 기타 구성 옵션은 다양한 요인에 따라 달라집니다.
자세한 내용은 HDInsight 클러스터에 대한 용량 계획을 참조하세요.
HDInsight 클러스터에는 어떤 다양한 유형의 노드가 있나요?
Azure HDInsight 클러스터의 리소스 종류를 참조하세요.
대규모 HDInsight 클러스터를 만드는 모범 사례는 무엇인가요?
- 클러스터 확장성을 개선하려면 사용자 지정 Ambari DB를 사용하여 HDInsight 클러스터를 설정하는 것이 좋습니다.
- Azure Data Lake Storage Gen2를 사용하여 HDInsight 클러스터를 만들면 Azure Data Lake Storage Gen2의 더 높은 대역폭과 기타 성능 특징을 활용할 수 있습니다.
- 헤드 노드는 이러한 노드에서 실행되는 여러 마스터 서비스를 수용할 만큼 충분히 커야 합니다.
- Interactive Query와 같은 일부 특정 워크로드에도 보다 큰 Zookeeper 노드가 필요합니다. 최소 8개의 코어 VM을 고려하세요.
- Hive 및 Spark의 경우 외부 Hive 메타스토어를 사용합니다.
개별 구성 요소
클러스터에 추가 구성 요소를 설치할 수 있나요?
예. 추가 구성 요소를 설치하거나 클러스터 구성을 사용자 지정하려면 다음을 사용합니다.
생성 중 또는 생성이 완료된 스크립트. 스크립트는 스크립트 동작을 통해 호출됩니다. 스크립트 동작은 Azure Portal, HDInsight Windows PowerShell cmdlet 또는 HDInsight .NET SDK에서 사용할 수 있는 구성 옵션입니다. 해당 구성 옵션은 Azure Portal, HDInsight Windows PowerShell cmdlet 또는 HDInsight .NET SDK에서 사용할 수 있습니다.
애플리케이션을 설치하기 위한 HDInsight 애플리케이션 플랫폼.
지원되는 구성 요소 목록은 HDInsight에서 사용할 수 있는 Apache Hadoop 구성 요소 및 버전은?을 참조하세요.
클러스터에 미리 설치된 개별 구성 요소를 업그레이드할 수 있나요?
클러스터에 미리 설치된 기본 제공 구성 요소 또는 애플리케이션을 업그레이드하는 경우, 그 결과로 만들어진 구성은 Microsoft에서 지원하지 않습니다. 이러한 시스템 구성은 Microsoft의 테스트를 거치지 않았습니다. 다른 버전의 HDInsight 클러스터를 사용하는 것을 고려해 보세요. 해당 구성 요소의 업그레이드 버전이 이미 설치되어 있을 수 있습니다.
예를 들어 Hive를 개별 구성 요소로 업그레이드하는 것은 지원되지 않습니다. HDInsight는 관리형 서비스이며 많은 서비스가 Ambari 서버와 통합되고 테스트를 거쳤습니다. Hive를 자체적으로 업그레이드하면 다른 구성 요소의 인덱싱된 이진 파일이 변경되며, 클러스터에서 구성 요소 통합 문제가 발생합니다.
Spark와 Kafka를 동일한 HDInsight 클러스터에서 실행할 수 있나요?
아니요, Apache Kafka 및 Apache Spark는 동일한 HDInsight 클러스터에서 실행할 수 없습니다. 리소스 경합 문제를 방지하려면 Kafka와 Spark에 대해 별도의 클러스터를 만드세요.
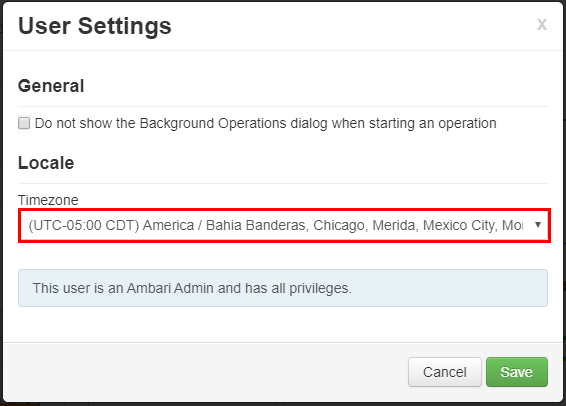
Ambari에서 표준 시간대를 변경하려면 어떻게 해야 하나요?
https://CLUSTERNAME.azurehdinsight.net에서 Ambari 웹 UI를 엽니다. 여기서 CLUSTERNAME은 클러스터의 이름입니다.오른쪽 위 모서리에서 관리자 | 설정을 선택합니다.
사용자 설정 창의 표준 시간대 드롭다운에서 새 표준 시간대를 선택하고 저장을 클릭합니다.
메타 저장소
기존 메타스토어에서 Azure SQL Database로 마이그레이션하려면 어떻게 해야 하나요?
SQL Server에서 Azure SQL Database로 마이그레이션하려면 자습서: DMS를 사용하여 SQL Server를 Azure SQL Database의 단일 데이터베이스 또는 풀링된 데이터베이스로 오프라인 마이그레이션을 참조하세요.
클러스터를 삭제하면 Hive 메타스토어도 삭제되나요?
클러스터에서 사용하도록 구성된 메타스토어 유형에 따라 다릅니다.
기본 메타스토어: 기본 메타스토어는 클러스터 수명 주기의 일부입니다. 클러스터를 삭제하면 해당하는 metastore와 메타데이터도 삭제됩니다.
사용자 지정 메타스토어: 메타스토어의 수명 주기는 클러스터의 수명 주기와 연결되어 있지 않습니다. 따라서 메타데이터의 손실 없이 클러스터를 만들고 삭제할 수 있습니다. HDInsight 클러스터를 삭제하고 다시 만든 후에도 Hive 스키마와 같은 메타데이터가 유지됩니다.
자세한 내용은 Azure HDInsight에서 외부 메타데이터 저장소 사용을 참조하세요.
Hive 메타스토어를 마이그레이션하면 Ranger 데이터베이스의 기본 정책도 함께 마이그레이션되나요?
아니요, 정책 정의는 Ranger 데이터베이스에 존재하기 때문에 Ranger 데이터베이스를 마이그레이션해야 정책이 마이그레이션됩니다.
Hive 메타스토어를 ESP(Enterprise Security Package) 클러스터에서 ESP가 아닌 클러스터로 마이그레이션할 수 있나요?
예, Hive 메타스토어는 ESP 클러스터에서 ESP가 아닌 클러스터로 마이그레이션할 수 있습니다.
Hive 메타스토어 데이터베이스의 크기를 추정하려면 어떻게 해야 하나요?
Hive 메타스토어는 Hive 서버에서 사용하는 데이터 원본에 대한 메타데이터를 저장하는 데 사용됩니다. 크기 요구 사항은 Hive 데이터 원본의 수와 복잡성에 따라 부분적으로 달라집니다. 이러한 항목은 미리 추정할 수 없습니다. Hive 메타스토어 지침에 설명된 대로 S2 계층으로 시작하는 것이 좋습니다. S2 계층은 50DTU 및 250GB의 스토리지를 제공하며, 병목 현상이 나타나면 데이터베이스를 스케일 업하세요.
Azure SQL Database가 아닌 다른 데이터베이스도 외부 메타스토어로 지원하나요?
아니요, Microsoft는 외부 사용자 지정 메타스토어로 Azure SQL Database만 지원합니다.
여러 클러스터에서 메타스토어를 공유할 수 있나요?
예, 동일한 버전의 HDInsight를 사용하는 한 여러 클러스터에서 사용자 지정 메타스토어를 공유할 수 있습니다.
연결 및 가상 네트워크
네트워크에서 포트 22 및 23을 차단하면 어떻게 되나요?
포트 22 및 포트 23을 차단하는 경우 클러스터에 대한 SSH 액세스 권한을 얻지 못합니다. 해당 포트는 HDInsight 서비스에서 사용되지 않습니다.
자세한 내용은 다음 문서를 참조하십시오.
HDInsight 클러스터와 동일한 서브넷 내에 가상 머신을 추가로 배포할 수 있나요?
예, HDInsight 클러스터와 동일한 서브넷 내에 가상 머신을 추가로 배포할 수 있습니다. 다음과 같은 구성을 사용할 수 있습니다.
에지 노드: HDInsight의 Apache Hadoop 클러스터에서 빈 에지 노드 사용에 설명된 대로 클러스터에 다른 에지 노드를 추가할 수 있습니다.
독립 실행형 노드: 독립 실행형 가상 머신을 동일한 서브넷에 추가하고 프라이빗 엔드포인트
https://<CLUSTERNAME>-int.azurehdinsight.net을 사용하여 해당 가상 머신에서 클러스터에 액세스할 수 있습니다. 자세한 내용은 네트워크 트래픽 제어를 참조하세요.
에지 노드의 로컬 디스크에 데이터를 저장해야 하나요?
아니요, 로컬 디스크에 데이터를 저장하는 것은 좋지 않습니다. 노드가 실패하면 로컬에 저장된 모든 데이터가 손실됩니다. Azure Data Lake Storage Gen2 또는 Azure Blob Storage에 데이터를 저장하거나, 데이터 저장용으로 Azure Files 공유를 탑재하는 것이 좋습니다.
기존 HDInsight 클러스터를 다른 가상 네트워크에 추가할 수 있나요?
아니요, 확인할 수 없습니다. 가상 네트워크는 프로비저닝 시 지정해야 합니다. 프로비저닝 시 가상 네트워크가 지정되지 않은 경우, 배포는 외부에서 액세스할 수 없는 내부 네트워크를 만들게 됩니다. 자세한 내용은 기존 가상 네트워크에 HDInsight 추가를 참조하세요.
보안 및 인증서
Azure HDInsight 클러스터의 맬웨어 보호에 대한 권장 사항은 무엇인가요?
맬웨어 보호에 대한 자세한 내용은 Azure Cloud Services 및 Virtual Machines용 Microsoft Antimalware를 참조하세요.
HDInsight ESP 클러스터에 대한 keytab은 어떻게 만들 수 있나요?
도메인 사용자 이름에 대한 Kerberos keytab을 만듭니다. 나중에 이 keytab을 사용하여 암호를 입력하지 않고도 원격 도메인에 가입된 클러스터에 인증할 수 있습니다. 도메인 이름이 대문자입니다.
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
keytab을 만들 때 AES256 암호화에 솔팅이 필요한 경우는 언제인가요?
TenantName 및 DomainName이 다른 경우(예: TenantName – bob@CONTOSO.ONMICROSOFT.COM 및 DomainName – bob@CONTOSOMicrosoft.ONMICROSOFT.COM) -s 옵션을 사용하여 SALT 값을 추가해야 합니다.
적절한 SALT 값을 어떻게 확인할 수 있나요?
- 대화형 Kerberos 로그인을 사용하여 keytab에 대한 적절한 솔트 값을 확인합니다. 대화형 Kerberos 로그인은 기본적으로 가장 높은 암호화를 사용합니다. 솔트를 관찰하려면 추적을 사용하도록 설정해야 합니다. 다음은 샘플 Kerberos 로그인입니다.
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- 출력에서 솔트 "......." 줄을 확인합니다.
- keytab을 만들 때 이 솔트 값을 사용합니다.
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
기존 Microsoft Entra 테넌트를 사용하여 ESP를 가지는 HDInsight 클러스터를 만들 수 있나요?
ESP를 사용하여 HDInsight 클러스터를 만들기 전에 Microsoft Entra Domain Services를 사용하도록 설정합니다. 오픈 소스 Hadoop은 인증에 Kerberos를 사용합니다(OAuth와 반대).
VM을 도메인에 연결하려면 도메인 컨트롤러가 있어야 합니다. Microsoft Entra Domain Services는 관리되는 도메인 컨트롤러이며 Microsoft Entra ID의 확장으로 간주됩니다. Microsoft Entra Domain Services는 관리형 방식으로 Hadoop 클러스터를 빌드하기 위한 모든 Kerberos 요구 사항을 제공합니다. 관리되는 서비스로서의 HDInsight는 Microsoft Entra Domain Services와 통합하여 보안을 제공합니다.
Microsoft Entra Domain Services 보안 LDAP 설정에서 자체 서명된 인증서를 사용하고 ESP 클러스터를 프로비전할 수 있나요?
인증 기관에서 발급한 인증서를 사용하는 것이 좋습니다. 하지만 ESP에서는 자체 서명된 인증서도 지원됩니다. 자세한 내용은 다음을 참조하세요.
ESP 클러스터로 DAS(Data Analytics Studio)를 설치할 수 있나요?
아니요, DAS는 ESP 클러스터에서 지원되지 않습니다.
Ranger에 표시된 로그인 작업은 어떻게 풀링하나요?
감사 요구 사항의 경우, Microsoft는 Azure Monitor 로그를 사용하여 HDInsight 클러스터 모니터링에 설명된 대로 Azure Monitor 로그를 사용하는 것을 권장합니다.
클러스터에서 'Clamscan'을 사용하지 않도록 설정할 수 있나요?
Clamscan은 HDInsight 클러스터에서 실행되며 Azure 보안(azsecd)이 클러스터를 바이러스의 공격으로부터 보호하기 위해 사용하는 바이러스 백신 소프트웨어입니다. Microsoft에서는 사용자가 기본 Clamscan 구성을 변경하지 않는 것을 강력하게 권장합니다.
해당 프로세스는 다른 프로세스를 방해하거나 다른 프로세스의 주기를 생략하지 않습니다. 항상 다른 프로세스가 먼저 실행됩니다. Clamscan으로 인해 CPU가 급증하는 상황은 시스템이 유휴 상태일 때만 발생해야 합니다.
일정을 제어해야만 하는 경우 다음 단계를 사용할 수 있습니다.
다음 명령을 사용하여 자동 실행을 사용하지 않도록 설정합니다.
sudo
usr/local/bin/azsecd config -s clamav -d Disabledsudo service azsecd restart루트로 다음 명령을 실행하는 cron 작업을 추가합니다.
/usr/local/bin/azsecd manual -s clamav
cron 작업을 설정 및 실행하는 방법에 대한 자세한 내용은 cron 작업을 설정하려면 어떻게 해야 하나요?를 참조하세요.
Spark ESP 클러스터에서 LLAP를 사용할 수 있는 이유는 무엇인가요?
LLAP는 성능이 아닌 보안상의 이유(Apache Ranger)로 사용 설정됩니다. LLAP의 리소스 사용량을 수용하려면 보다 대규모의 노드 VM을 사용하세요(예: 최소 D13V2).
ESP 클러스터를 만든 후 추가 Microsoft Entra 그룹을 추가하려면 어떻게 해야 하나요?
이렇게 하려면 두 가지 방법이 있습니다. 1- 클러스터를 다시 만들고 클러스터를 만들 때 추가 그룹을 추가합니다. Microsoft Entra Domain Services에서 범위가 지정된 동기화를 사용하는 경우 그룹 B가 범위가 지정된 동기화에 포함되어 있는지 확인하세요.
2- 그룹을 ESP 클러스터를 만드는 데 사용된 이전 그룹의 중첩된 하위 그룹으로 추가합니다. 예를 들어 그룹 A로 ESP 클러스터를 만든 경우 나중에 그룹 A의 중첩된 하위 그룹으로 그룹 B를 추가할 수 있습니다. 이렇게 하면 약 1시간 후에 동기화되며 자동으로 클러스터에서 사용할 수 있습니다.
스토리지
기존 HDInsight 클러스터에 Azure Data Lake Storage Gen2를 추가 스토리지 계정으로 추가할 수 있나요?
아니요, 현재 Blob Storage를 기본 스토리지로 가지는 클러스터에 Azure Data Lake Storage Gen2 Storage 계정을 추가할 수 없습니다. 자세한 내용은 스토리지 옵션 비교를 참조하세요.
Data Lake 스토리지 계정에 대해 현재 연결된 서비스 주체를 찾으려면 어떻게 해야 하나요?
Azure Portal의 클러스터 속성 아래의 Data Lake Storage Gen1 액세스에서 설정을 찾을 수 있습니다. 자세한 내용은 클러스터 설정 확인을 참조하세요.
HDInsight 클러스터에 대한 스토리지 계정 및 Blob 컨테이너 사용량을 계산하려면 어떻게 해야 하나요?
다음 작업 중 하나를 수행합니다.
다음 명령줄을 사용하여 HDInsight 클러스터의 /user/hive/.Trash/ 폴더의 크기를 확인합니다.
hdfs dfs -du -h /user/hive/.Trash/
내 Blob Storage 계정에 대한 감사를 설정하려면 어떻게 해야 하나요?
Blob Storage 계정을 감사하려면 Azure Portal에서 스토리지 계정 모니터링 절차를 사용하여 모니터링을 구성합니다. HDFS 감사 로그는 로컬 HDFS 파일 시스템(hdfs://mycluster)에 대한 감사 정보만을 제공합니다. 원격 스토리지에서 수행되는 작업은 포함되지 않습니다.
Blob 컨테이너와 HDInsight 헤드 노드 간에 파일을 전송하려면 어떻게 해야 하나요?
헤드 노드에서 다음 셸 스크립트와 비슷한 스크립트를 실행합니다.
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
참고 항목
파일 filenames.txt는 Blob 컨테이너에 있는 파일의 절대 경로를 가집니다.
스토리지에 대한 Ranger 플러그 인이 있나요?
현재 Blob Storage 및 Azure Data Lake Storage Gen1 또는 Gen2에 대한 Ranger 플러그 인은 존재하지 않습니다. ESP 클러스터의 경우 Azure Data Lake Storage를 사용해야 합니다. HDFS 도구를 사용하여 파일 시스템 수준에서 미세 권한을 수동으로 설정하는 것은 가능합니다. 또한 Azure Data Lake Storage를 사용하는 경우 ESP 클러스터는 클러스터 수준에서 Microsoft Entra ID를 사용하여 파일 시스템 액세스 제어 중 일부를 수행합니다.
Azure Storage Explorer를 사용하여 사용자의 보안 그룹에 데이터 액세스 정책을 할당할 수 있습니다. 자세한 내용은 다음을 참조하세요.
작업자 노드의 디스크 크기를 늘리지 않고 클러스터에서 HDFS 스토리지를 늘릴 수 있나요?
아니요. 작업자 노드의 디스크 크기는 늘릴 수 없습니다. 따라서 디스크 크기를 늘리는 유일한 방법은 클러스터를 삭제한 다음 더 큰 작업자 VM으로 다시 만드는 것입니다. 클러스터를 삭제하는 경우 데이터가 삭제되므로 HDFS를 사용하여 HDInsight 데이터를 저장하지 마세요. 대신 Azure에 데이터를 저장하세요. 클러스터를 스케일링하는 방법으로 HDInsight 클러스터에 추가 용량을 추가할 수도 있습니다.
에지 노드
클러스터를 만든 후 에지 노드를 추가할 수 있나요?
에지 노드에 연결하려면 어떻게 해야 하나요?
에지 노드를 만든 후 포트 22에서 SSH를 사용하여 연결할 수 있습니다. 클러스터 포털에서 에지 노드의 이름을 확인할 수 있습니다. 이름은 일반적으로 -ed로 끝납니다.
지속형 스크립트가 새로 생성된 에지 노드에서 자동으로 실행되지 않는 이유는 무엇인가요?
지속형 스크립트는 크기 조정 작업을 통해 클러스터에 추가되는 새 작업자 노드를 사용자 지정하는 데 사용됩니다. 지속형 스크립트는 에지 노드에 적용되지 않습니다.
REST API
클러스터에서 Tez 쿼리 뷰를 끌어오기 위한 REST API 호출은 무엇인가요?
다음 REST 엔드포인트를 사용하여 필요한 정보를 JSON 형식으로 가져올 수 있습니다. 기본 인증 헤더를 사용하여 요청을 만듭니다.
Tez Query View: https://<cluster name>.azurehdinsight.net/ws/v1/timeline/HIVE_QUERY_ID/Tez Dag View: https://<cluster name>.azurehdinsight.net/ws/v1/timeline/TEZ_DAG_ID/
Microsoft Entra 사용자를 사용하여 HDI 클러스터에서 구성 정보를 검색하려면 어떻게 해야 하나요?
Microsoft Entra 사용자와 적절한 인증 토큰을 협상하려면 다음 형식을 사용하여 게이트웨이를 진행합니다.
- https://
<cluster dnsname>.azurehdinsight.net/api/v1/clusters/testclusterdem/stack_versions/1/repository_versions/1
Ambari RESTful을 사용하여 YARN 성능을 모니터링하려면 어떻게 해야 하나요?
동일한 가상 네트워크 또는 피어링된 가상 네트워크에서 Curl 명령을 호출하려면 다음 명령을 사용합니다.
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
가상 네트워크 외부에서 또는 피어링되지 않은 가상 네트워크에서 명령을 호출하려면 명령 형식은 다음과 같습니다.
ESP가 아닌 클러스터의 경우:
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpuESP 클러스터의 경우:
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
참고 항목
Curl은 암호를 묻는 메시지를 표시합니다. 클러스터 로그인 사용자 이름에 대한 올바른 암호를 입력해야 합니다.
결제
HDInsight 클러스터를 배포하는 비용은 얼마인가요?
청구와 관련된 가격 책정 및 FAQ에 대한 자세한 내용은 Azure HDInsight 가격 페이지를 참조하세요.
HDInsight 청구가 시작되고 중지되는 시점은 언제인가요?
클러스터가 만들어지면 HDInsight 클러스터 청구가 시작되고 클러스터가 삭제되면 중지됩니다. 청구는 분당 비례 배분됩니다.
구독을 취소하려면 어떻게 해야 하나요?
구독을 취소하는 방법에 대한 자세한 내용은 Azure 구독 취소를 참조하세요.
종량제 구독의 경우 구독을 취소하면 어떻게 되나요?
구독이 취소된 후의 구독에 대한 자세한 내용은 구독을 취소한 후에는 어떻게 되나요?를 참조하세요.
Hive
HDInsight 3.6 클러스터를 실행하는 경우에도 Hive 버전이 Ambari UI에서 2.1 대신 1.2.1000으로 표시되는 이유는 무엇인가요?
Ambari UI에는 1.2만 표시되지만, HDInsight 3.6에는 Hive 1.2와 Hive 2.1이 모두 포함되어 있습니다.
기타 FAQ
HDInsight는 실시간 스트림 처리 기능에 대해 무엇을 제공하나요?
스트림 처리의 통합 기능에 대한 자세한 내용은 Azure에서 스트림 처리 기술 선택을 참조하세요.
클러스터가 특정 기간 동안 유휴 상태일 때 클러스터의 헤드 노드를 동적으로 종료하는 방법이 있나요?
HDInsight 클러스터에서는 이 작업을 수행할 수 없습니다. 이러한 시나리오에는 Azure Data Factory를 사용할 수 있습니다.
HDInsight에서 제공하는 규정 준수 제안은 무엇인가요?
규정 준수 정보는 Microsoft 보안 센터를 참조하세요.