Azure HDInsight란?
Azure HDInsight는 엔터프라이즈용 클라우드의 관리형 전체 스펙트럼 오픈 소스 분석 서비스입니다. HDInsight를 사용하면 Azure 환경에서 Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop 등과 같은 오픈 소스 프레임워크를 사용할 수 있습니다.
HDInsight 및 Hadoop 기술 스택이란?
Azure HDInsight는 Azure 환경에서 Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop 등과 같은 빅 데이터 프레임워크를 간편하게 실행할 수 있도록 하는 관리형 클러스터 플랫폼입니다. 대용량의 데이터를 빠르고 효율적으로 처리하도록 설계되었습니다.
Azure HDInsight를 사용해야 하는 이유는 무엇인가요?
| 기능 | 설명 |
|---|---|
| 클라우드 네이티브 | Azure HDInsight를 사용하면 Azure에서 Spark, 대화형 쿼리(LLAP), Kafka, HBase 및 Hadoop에 최적화된 클러스터를 만들 수 있습니다. 또한 HDInsight에서는 모든 프로덕션 워크로드에 엔드투엔드 SLA를 제공합니다. |
| 저렴한 비용 및 확장성 | HDInsight를 사용하면 워크로드의 크기를 조정할 수 있습니다. 주문형 클러스터를 만들어 사용한 양만큼만 요금을 지불하여 비용을 절감할 수 있습니다. 또한 작업을 운영하는 데이터 파이프라인을 작성할 수 있습니다. 컴퓨팅과 스토리지를 분리하므로 성능 및 유연성이 향상됩니다. |
| 보안 및 규정 준수 | HDInsight를 사용하면 Azure 가상 네트워크, 암호화, Microsoft Entra ID와의 통합을 통해 엔터프라이즈 데이터 자산을 보호할 수 있습니다. HDInsight는 가장 널리 사용되는 업계 및 정부 규격 표준을 충족합니다. |
| 모니터링 | Azure HDInsight는 Azure Monitor 로그와 통합하여 모든 클러스터를 모니터링할 수 있는 단일 인터페이스를 제공합니다. |
| 글로벌 가용성 | HDInsight는 다른 어떤 빅 데이터 분석 제품보다 많은 지역에서 사용할 수 있습니다. Azure HDInsight는 주요 통치 지역에서 엔터프라이즈 요구 사항을 충족할 수 있도록 Azure Government, 중국 및 독일에서도 사용할 수 있습니다. |
| 생산성 | Azure HDInsight를 사용하면 선호하는 개발 환경과 함께 Hadoop 및 Spark에 대한 풍부한 생산성 도구를 사용할 수 있습니다. 이러한 개발 환경에는 Scala, Python, Java, .NET 지원을 위한 Visual Studio, VS Code, Eclipse, IntelliJ가 포함됩니다. |
| 확장성 | 스크립트 작업을 사용하는 구성 요소(Hue, Presto 등)를 설치하거나, 에지 노드를 추가하거나, 다른 빅 데이터 인증 애플리케이션과 통합하여 HDInsight 클러스터를 확장할 수 있습니다. HDInsight를 사용하면 클릭 한 번으로 배포하여 가장 널리 사용되는 빅 데이터 솔루션과 원활히 통합할 수 있습니다. |
What is big data?
전에 없던 다양한 형식의 많은 양의 빅 데이터가 더 빠르게 수집되고 있습니다. 빅 데이터는 기록(저장됨) 또는 실시간(원본에서 스트리밍됨)일 수 있습니다. 빅 데이터에 대한 가장 일반적인 사용 사례에 대해 자세히 알아보려면 HDInsight를 사용하는 시나리오를 참조하세요.
HDInsight의 클러스터 형식
HDInsight에는 구성 요소, 유틸리티 및 언어 추가와 같은 특정 클러스터 형식 및 클러스터 사용자 지정 기능이 포함됩니다. HDInsight는 다음 클러스터 형식을 제공합니다.
| 클러스터 유형 | 설명 | 시작하기 |
|---|---|---|
| Apache Hadoop | 프레임워크는 병렬로 일괄 처리 데이터를 처리하고 분석하기 위해 HDFS, YARN 리소스 관리 및 간단한 MapReduce 프로그래밍 모델을 사용합니다. | Apache Hadoop 클러스터 만들기 |
| Apache Spark | 메모리 내 처리를 지원하여 빅 데이터 분석 애플리케이션의 성능을 향상하는 오픈 소스 병렬 처리 프레임워크입니다. HDInsight의 Apache Spark란?을 참조하세요. | Apache Spark 클러스터 만들기 |
| Apache HBase | 비정형 및 반정형 대량 데이터(잠재적으로 수십억 개의 행과 수십억 개의 열로 구성됨)에 관해 임의 액세스 및 강력한 일관성을 제공하는 Hadoop 기반의 NoSQL 데이터베이스입니다. HDInsight의 HBase란?을 참조하세요. | Apache HBase 클러스터 만들기 |
| Apache 대화형 쿼리 | 더 빠른 대화형 Hive 쿼리를 위한 메모리 내 캐싱입니다. HDInsight에서 대화형 쿼리 사용을 참조하세요. | Interactive Query 클러스터 만들기 |
| Apache Kafka | 오픈 소스 플랫폼은 스트리밍 데이터 파이프라인과 애플리케이션을 구축하는 데 사용됩니다. 또한 Kafka는 데이터 스트림을 게시하고 구독할 수 있는 메시지 큐 기능을 제공합니다. HDInsight에서 Apache Kafka에 대한 소개를 참조하세요. | Apache Kafka 클러스터 만들기 |
HDInsight를 사용하는 시나리오
Azure HDInsight는 빅 데이터 처리의 다양한 시나리오에 사용할 수 있습니다. 기록 데이터(이미 수집되고 저장된 데이터) 또는 실시간 데이터(원본에서 직접 스트리밍된 데이터)일 수 있습니다. 이러한 데이터를 처리하는 시나리오는 다음과 같은 범주로 요약할 수 있습니다.
일괄 처리(ETL)
ETL(추출, 변환 및 로드)은 구조화되지 않았거나 구조화된 데이터를 유형이 다른 데이터 원본에서 추출하는 프로세스입니다. 그런 다음 구조화된 형식으로 변환하고, 데이터 저장소로 로드합니다. 데이터 과학 또는 데이터 웨어하우징에 변환된 데이터를 사용할 수 있습니다.
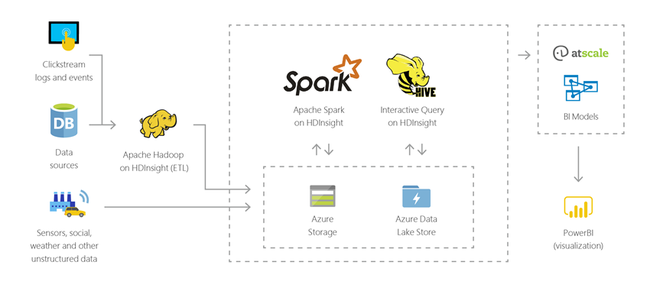
데이터 웨어하우징
어떤 형식의 구조화되거나 구조화되지 않은 데이터에 대해 페타바이트 규모의 대화형 쿼리를 수행하는 데 HDInsight를 사용할 수 있습니다. 모델을 BI 도구에 연결하여 작성할 수도 있습니다.
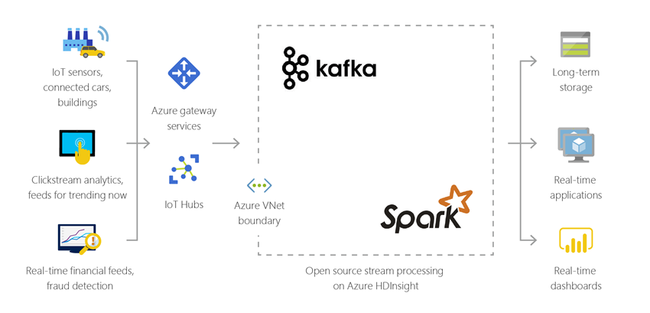
IoT(사물 인터넷)
HDInsight를 사용하여 다양한 종류의 디바이스에서 실시간으로 수신되는 스트리밍 데이터를 처리할 수 있습니다. 자세한 내용은 Azure에서 HDInsight에서 Azure Managed Disks를 통한 Apache Kafka의 공개 미리 보기를 알려주는 이 블로그 게시물을 읽어 보세요.
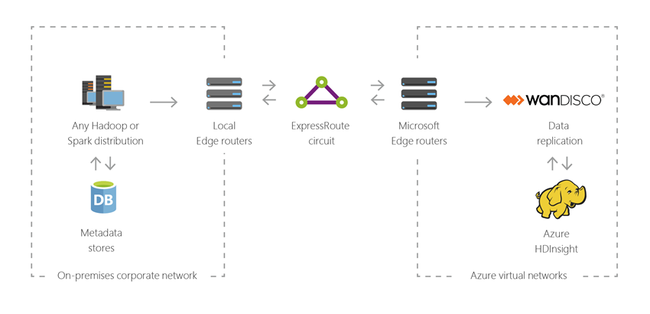
하이브리드
클라우드의 고급 분석 기능을 적용하기 위해 Azure로 기존 온-프레미스 빅 데이터 인프라를 확장하는 데 HDInsight를 사용할 수 있습니다.
HDInsight의 오픈 소스 구성 요소
Azure HDInsight를 사용하면 Spark, Hive, LLAP, Kafka, Hadoop 및 HBase와 같은 오픈 소스 프레임워크로 클러스터를 만들 수 있습니다. 기본적으로 이러한 클러스터에는 Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie, Apache ZooKeeper와 같은 다양한 오픈 소스 구성 요소가 포함되어 있습니다.
HDInsight의 프로그래밍 언어
HDInsight 클러스터, 즉 Spark, HBase, Kafka, Hadoop 및 기타 클러스터는 다양한 프로그래밍 언어를 지원합니다. 일부 프로그래밍 언어는 기본적으로 설치되지 않습니다. 기본적으로 설치되지 않은 라이브러리, 모듈 또는 패키지의 경우 스크립트 동작을 사용하여 구성 요소를 설치합니다.
| 프로그래밍 언어 | 정보 |
|---|---|
| 기본 프로그래밍 언어 지원 | 기본적으로 HDInsight 클러스터는 다음을 지원합니다.
|
| Java 가상 머신(JVM) 언어 | Java 이외의 여러 언어는 JVM(Java Virtual Machine)에서 실행할 수 있습니다. 그러나 이러한 언어 중 일부를 실행하는 경우 클러스터에 더 많은 구성 요소를 설치해야 할 수 있습니다. 이러한 JVM 기반 언어는 HDInsight 클러스터에서 지원됩니다.
|
| Hadoop 관련 언어 | HDInsight 클러스터는 Hadoop 기술 스택에만 적용되는 다음 언어를 지원합니다.
|
HDInsight에 대한 개발 도구
IntelliJ, Eclipse, Visual Studio Code 및 Visual Studio를 포함하여 HDInsight 개발 도구를 사용하여 Azure와의 원활한 통합으로 HDInsight 데이터 쿼리 및 작업을 작성하고 제출할 수 있습니다.
- IntelliJ 10용 Azure 도구 키트
- Eclipse 6용 Azure 도구 키트
- VS Code 13용 Azure HDInsight 도구
- Visual Studio 9용 Azure 데이터 레이크 도구
HDInsight의 비즈니스 인텔리전스
익숙한 BI(비즈니스 인텔리전스) 도구는 파워 쿼리 추가 기능이나 Microsoft Hive ODBC Driver를 사용하여 HDInsight와 통합된 데이터를 검색, 분석 및 보고합니다.
Azure HDInsight에서 Microsoft Power BI를 사용하여 Apache Hive 데이터 시각화
파워 쿼리로 Apache Hadoop에 Excel 연결(Windows 필요)
Microsoft Hive ODBC Driver로 Apache Hadoop에 Excel 연결(Windows 필요)
지역 내 데이터 보존
Spark, Hadoop 및 LLAP는 고객 데이터를 저장하지 않으므로 이러한 서비스는 신뢰 센터에 지정된 지역 내 데이터 보존 요구 사항을 자동으로 충족합니다.
Kafka 및 HBase는 고객 데이터를 저장합니다. 이 데이터는 단일 지역의 Kafka 및 HBase에 의해 자동으로 저장되므로 이 서비스는 신뢰 센터에 지정된 지역 내 데이터 보존 요구 사항을 충족합니다.
익숙한 BI(비즈니스 인텔리전스) 도구는 파워 쿼리 추가 기능이나 Microsoft Hive ODBC Driver를 사용하여 HDInsight와 통합된 데이터를 검색, 분석 및 보고합니다.