Azure HDInsight를 사용하여 Apache Hadoop YARN 문제를 해결합니다.
Apache Ambari에서 Apache Hadoop YARN 페이로드를 사용할 때의 주요 문제 및 해결 방법을 알아봅니다.
클러스터에서 새 YARN 큐를 만들려면 어떻게 하나요?
해결 단계
Ambari에서 다음 단계를 사용하여 새 YARN 큐를 만들고 모든 큐에 용량이 균형 있게 할당되도록 조정합니다.
이 예제에서는 기존 큐 두 개(default 및 thriftsvr) 모두 새 큐(spark)를 50% 용량으로 하여 50% 용량에서 25% 용량으로 변경됩니다.
| Queue | 용량 | 최대 생산 능력 |
|---|---|---|
| default | 25% | 50% |
| thrftsvr | 25% | 50% |
| spark | 50% | 50% |
Ambari 뷰 아이콘을 선택한 다음, 그리드 패턴을 선택합니다. 다음으로, YARN 큐 관리자를 선택합니다.
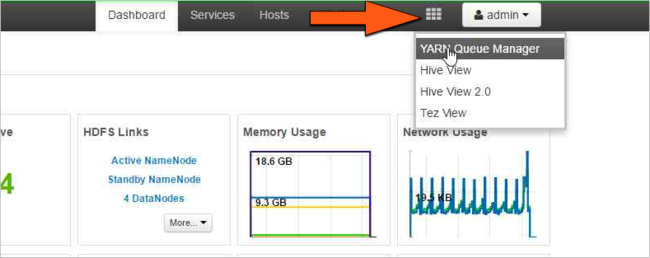
default 큐를 선택합니다.
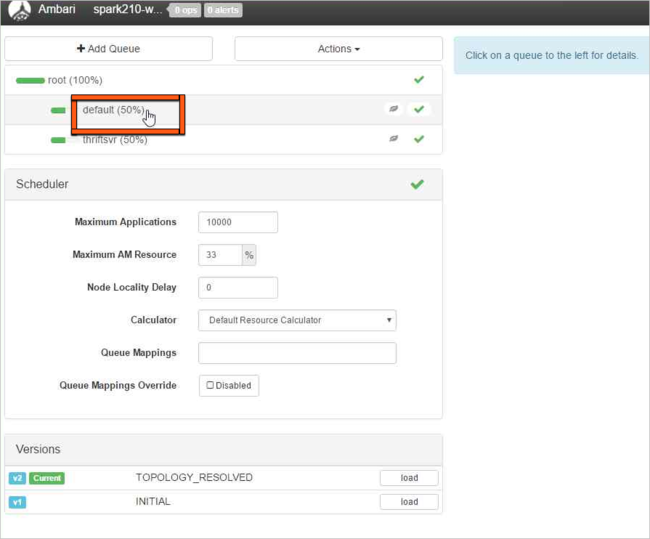
default 큐의 경우 용량을 50%에서 25%로 변경합니다. thriftsvr 큐의 경우 용량을 25%로 변경합니다.
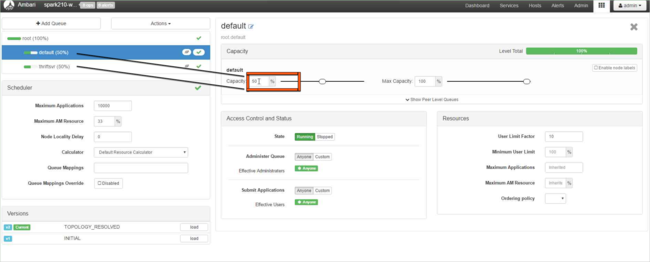
새 큐를 만들려면 큐 추가를 선택합니다.
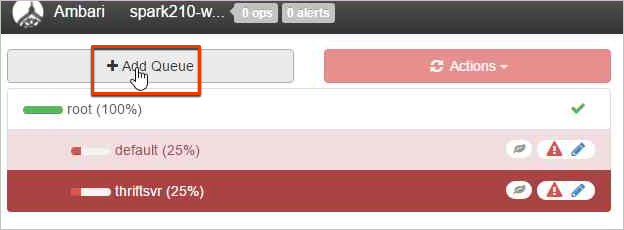
새 큐 이름을 지정합니다.
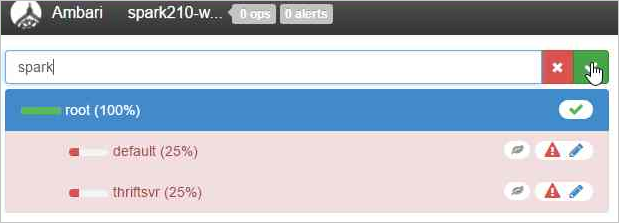
용량 값을 50%로 두고 작업 단추를 선택합니다.
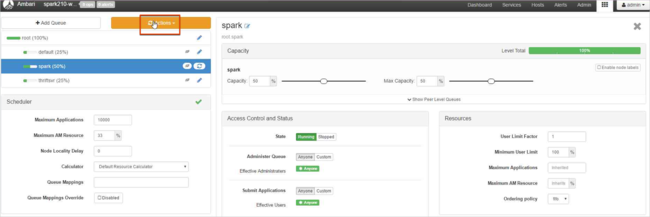
큐 저장 및 새로 고침을 선택합니다.
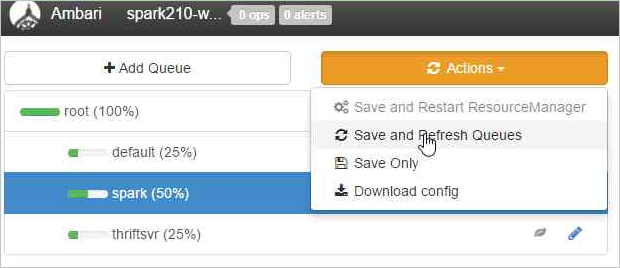
이러한 변경 내용은 YARN Scheduler UI에 즉시 표시됩니다.
추가 참고 자료
클러스터에서 YARN 로그를 다운로드하려면 어떻게 하나요?
해결 단계
SSH(Secure Shell) 클라이언트를 사용하여 HDInsight 클러스터에 연결합니다. 자세한 내용은 추가 정보를 참조하세요.
현재 실행 중인 YARN 애플리케이션의 모든 애플리케이션 ID를 나열하려면 다음 명령을 사용합니다.
yarn topID가 APPLICATIONID 열에 나열됩니다. APPLICATIONID 열에서 로그를 다운로드할 수 있습니다.
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC Server모든 애플리케이션 마스터에 대한 YARN 컨테이너 로그를 다운로드하려면 다음 명령을 사용합니다.
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtamlogs.txt라는 로그 파일이 만들어집니다.
최신 애플리케이션 마스터에 대한 YARN 컨테이너 로그만 다운로드하려면 다음 명령을 사용합니다.
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtlatestamlogs.txt라는 로그 파일이 만들어집니다.
처음 두 개 애플리케이션 마스터에 대한 YARN 컨테이너 로그를 다운로드하려면 다음 명령을 사용합니다.
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtfirst2amlogs.txt라는 로그 파일이 만들어집니다.
모든 YARN 컨테이너 로그를 다운로드하려면 다음 명령을 사용합니다.
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtlogs.txt라는 로그 파일이 만들어집니다.
특정 컨테이너에 대한 YARN 컨테이너 로그를 다운로드하려면 다음 명령을 사용합니다.
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtcontainerlogs.txt라는 로그 파일이 만들어집니다.
추가 자료
Yarn 애플리케이션 진단 정보를 확인하려면 어떻게 해야 하나요?
Yarn UI의 진단은 Yarn에서 실행되는 애플리케이션의 상태 및 로그를 볼 수 있는 기능입니다. 진단은 애플리케이션의 문제를 해결하고 디버깅하는 데 도움이 될 뿐만 아니라 애플리케이션의 성능과 리소스 사용량을 모니터링하는 데도 도움이 됩니다.
특정 애플리케이션의 진단을 보려면 애플리케이션 목록에서 애플리케이션 ID를 클릭하면 됩니다. 애플리케이션 세부정보 페이지에서는 애플리케이션을 실행하기 위해 시도한 모든 시도 목록도 볼 수 있습니다. 시도를 클릭하면 시도 ID, 컨테이너 ID, 노드 ID, 시작 시간, 완료 시간 및 진단과 같은 자세한 세부 정보를 볼 수 있습니다.
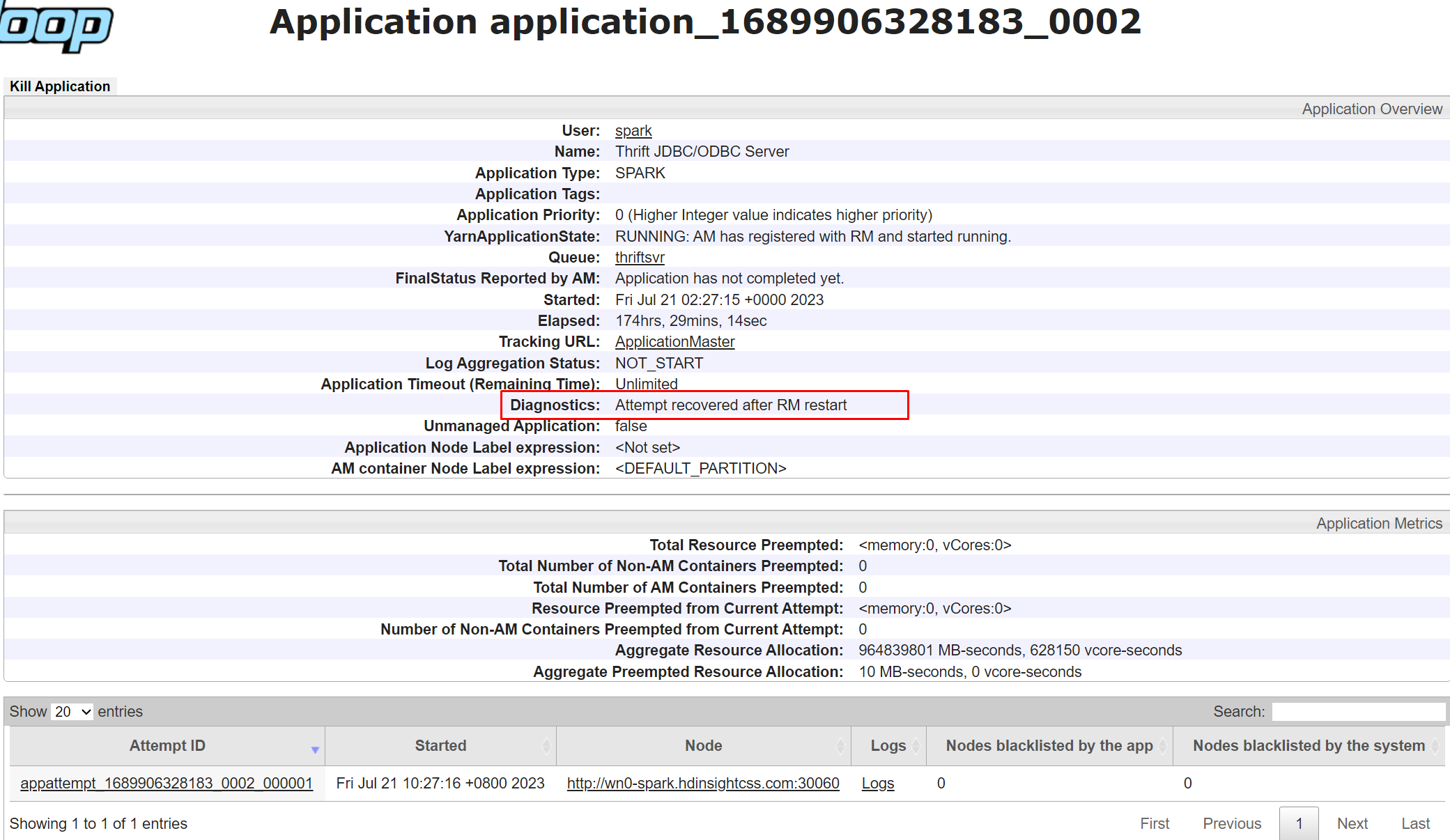
일반적인 YARN 문제를 해결하는 방법
Yarn UI가 로드되지 않음
YARN UI가 로드되지 않거나 연결할 수 없고 "HTTP 오류 502.3 - 잘못된 게이트웨이"를 반환하는 경우 Resource Manager 서비스가 비정상임을 나타냅니다. 문제를 완화하려면 다음 단계를 따릅니다.
- Ambari UI>YARN>SUMMARY로 이동하여 활성 Resource Manager만 시작됨 상태인지 확인합니다. 그렇지 않은 경우 비정상적이거나 중지된 Resource Manager를 다시 시작하여 완화해 보세요.
- 1단계로 문제가 해결되지 않으면 활성 Resource Manager 헤드 노드를 SSH로 연결하고
jstat -gcutil <Resource Manager pid> 1000 100을 사용하여 가비지 수집 상태를 확인합니다. 단 몇 초 만에 FGCT가 크게 증가하면 Resource Manager가 전체 GC에서 사용 중이며 다른 요청을 처리할 수 없음을 나타냅니다. - Ambari UI>YARN>구성>고급으로 이동하여
Resource Manager java heap size를 늘립니다. - Ambari UI에서 필수 서비스를 다시 시작합니다.
두 리소스 관리자가 모두 대기 상태임
- Resource Manager 로그를 확인하여 유사한 오류가 있는지 확인합니다.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
오류가 있는 경우 일부 파일이 복제 중인지 또는 HDFS에 누락된 블록이 있는지 확인합니다.
hdfs fsck hdfs://mycluster/를 실행할 수 있음hdfs fsck hdfs://mycluster/ -delete를 실행하여 HDFS를 강제로 정리하고 대기 RM 문제를 제거합니다. 또는 헤드 노드 중 하나에서 PatchYarnNodeLabel을 실행하여 클러스터를 패치합니다.
다음 단계
문제가 표시되지 않거나 문제를 해결할 수 없는 경우 다음 채널 중 하나를 방문하여 추가 지원을 받으세요.
Azure 커뮤니티 지원을 통해 Azure 전문가로부터 답변을 얻습니다.
사용자 환경을 개선하기 위한 공식 Microsoft Azure 계정인 @AzureSupport와 연결합니다. Azure 커뮤니티를 적절한 리소스(답변, 지원 및 전문가)에 연결합니다.
도움이 더 필요한 경우 Azure Portal에서 지원 요청을 제출할 수 있습니다. 메뉴 모음에서 지원을 선택하거나 도움말 + 지원 허브를 엽니다. 자세한 내용은 Azure 지원 요청을 만드는 방법을 참조하세요. 구독 관리 및 청구 지원에 대한 액세스 권한은 Microsoft Azure 구독에 포함되어 있으며, Azure 지원 플랜 중 하나를 통해 기술 지원이 제공됩니다.