빠른 시작: Apache Zeppelin을 사용하여 Azure HDInsight에서 Apache Hive 쿼리 실행
이 빠른 시작에서는 Apache Zeppelin을 사용하여 Azure HDInsight에서 Apache Hive 쿼리를 실행하는 방법을 알아봅니다. HDInsight 대화형 쿼리 클러스터에는 대화형 Hive 쿼리를 실행하는 데 사용할 수 있는 Apache Zeppelin Notebook이 포함되어 있습니다.
Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
필수 조건
HDInsight 대화형 쿼리 클러스터. 클러스터 만들기를 참조하여 HDInsight 클러스터를 만듭니다. Interactive Query 클러스터 유형을 선택해야 합니다.
Apache Zeppelin 노트 만들기
CLUSTERNAME을 다음 URLhttps://CLUSTERNAME.azurehdinsight.net/zeppelin에서 클러스터의 이름으로 바꿉니다. 그런 다음, 웹 브라우저에 URL을 입력합니다.클러스터 로그인 사용자 이름 및 암호를 입력합니다. Zeppelin 페이지에서 새 노트를 만들거나 기존 노트를 열 수 있습니다. HiveSample에는 몇 가지 샘플 Hive 쿼리가 포함되어 있습니다.
새 메모 만들기를 선택합니다.
새 메모 만들기 대화 상자에서 다음 값을 입력하거나 선택합니다.
- 노트 이름: 노트의 이름을 입력합니다.
- 기본 인터프리터: 드롭다운 목록에서 jdbc를 선택합니다.
노트 만들기를 선택합니다.
코드 섹션에서 다음 Hive 쿼리를 입력한 다음, Shift + Enter 키를 누릅니다.
%jdbc(hive) show tables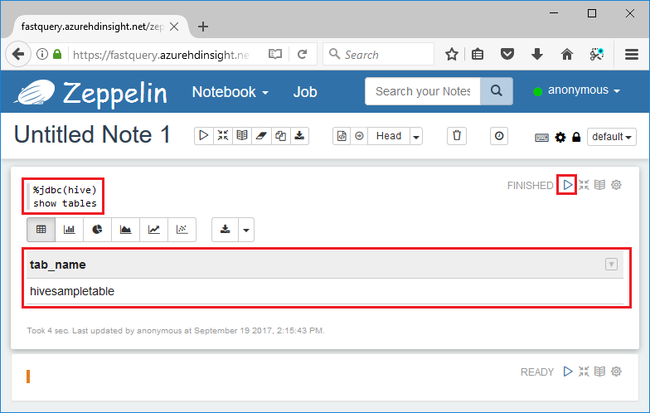
첫 번째 줄의 %jdbc(hive) 문은 노트북이 Hive JDBC 인터프리터를 사용한다는 것을 나타냅니다.
쿼리에서 hivesampletable이라는 하나의 Hive 테이블을 반환합니다.
다음은 hivesampletable에 대해 실행할 수 있는 두 가지 추가 Hive 쿼리입니다.
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}기존의 Hive에 비해 쿼리 결과를 반환하는 속도가 훨씬 빠릅니다.
추가 예제
테이블을 만듭니다. Zeppelin Notebook에서 아래 코드를 실행합니다.
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;새 테이블에 데이터를 로드합니다. Zeppelin Notebook에서 아래 코드를 실행합니다.
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;단일 레코드를 삽입합니다. Zeppelin Notebook에서 아래 코드를 실행합니다.
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
추가 구문은 Hive 언어 매뉴얼을 검토하세요.
리소스 정리
빠른 시작을 완료한 후 클러스터를 삭제하는 것이 좋습니다. HDInsight를 사용하면 데이터가 Azure Storage에 저장되기 때문에 클러스터를 사용하지 않을 때 안전하게 삭제할 수 있습니다. HDInsight 클러스터를 사용하지 않는 기간에도 요금이 청구됩니다. 클러스터에 대한 요금이 스토리지에 대한 요금보다 몇 배 더 많기 때문에, 클러스터를 사용하지 않을 때는 삭제하는 것이 경제적인 면에서 더 합리적입니다.
클러스터를 삭제하려면 브라우저, PowerShell 또는 Azure CLI를 사용하여 HDInsight 클러스터 삭제를 참조하세요.
다음 단계
이 빠른 시작에서는 Apache Zeppelin을 사용하여 Azure HDInsight에서 Apache Hive 쿼리를 실행하는 방법을 알아보았습니다. Hive 쿼리에 대해 자세히 알아보려면 다음 문서에 Visual Studio를 사용하여 쿼리를 실행하는 방법이 나와 있습니다.