Azure HDInsight에서 Apache Ambari를 사용하여 Apache Hive 최적화
Apache Ambari는 HDInsight 클러스터를 관리하고 모니터링하는 웹 인터페이스입니다. Ambari Web UI에 대한 소개는 Apache Ambari Web UI로 HDInsight 클러스터 관리를 참조하세요.
다음 섹션에서는 전반적인 Apache Hive 성능을 최적화하기 위한 구성 옵션을 설명합니다.
- Hive 구성 매개 변수를 수정하려면 서비스 사이드바에서 Hive를 선택합니다.
- Configs(구성) 탭으로 이동합니다.
Hive 실행 엔진 설정
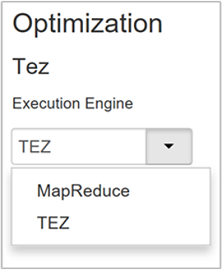
Hive는 두 개의 실행 엔진인 Apache Hadoop MapReduce 및 Apache TEZ를 제공합니다. Tez는 MapReduce보다 빠릅니다. HDInsight Linux 클러스터에는 Tez가 기본 실행 엔진으로 있습니다. 실행 엔진을 변경하려면:
Hive Configs(구성) 탭의 필터 상자에 실행 엔진을 입력합니다.
Optimization(최적화) 속성의 기본값은 Tez입니다.
매퍼 조정
Hadoop은 단일 파일을 여러 파일로 분할(매핑)하여 생성되는 파일을 병렬로 처리하려고 합니다. 매퍼의 수는 분할 수에 따라 달라집니다. 다음 두 가지 구성 매개 변수는 Tez 실행 엔진의 분할 수를 결정합니다.
tez.grouping.min-size: 그룹화된 분할 크기의 하한이며 기본값은 16MB(16,777,216바이트)입니다.tez.grouping.max-size: 그룹화된 분할 크기의 상한이며 기본값은 1GB(1,073,741,824바이트)입니다.
성능 지침에 따라 이 두 매개 변수를 모두 낮추어 대기 시간을 개선하고 처리량을 늘립니다.
예를 들어 크기가 128MB인 데이터에 매퍼 작업을 4개 설정하려면 두 매개 변수를 각각 32MB(33,554,432바이트)로 설정합니다.
제한 매개 변수를 수정하려면 Tez 서비스의 Configs(구성) 탭으로 이동합니다. 일반 패널을 확장하고
tez.grouping.max-size및tez.grouping.min-size매개 변수를 찾습니다.두 매개 변수를 모두 33,554,432 바이트(32MB)로 설정합니다.

이 변경 내용은 서버의 모든 Tez 작업에 영향을 미칩니다. 최적의 결과를 내려면 적절한 매개 변수 값을 선택합니다.
리듀서 조정
Apache ORC 및 Snappy는 모두 고성능을 제공합니다. 하지만 Hive는 기본적으로 리듀서가 너무 적어서 이로 인해 병목 상태가 발생합니다.
예를 들어 입력 데이터 크기가 50GB라고 가정하겠습니다. Snappy 압축을 통한 ORC 형식의 해당 데이터는 1GB입니다. Hive는 필요한 Reducer 수를 매퍼에 입력되는 바이트 수 /hive.exec.reducers.bytes.per.reducer로 예측합니다.
기본 설정을 사용하는 이 예에는 Reducer가 4개입니다.
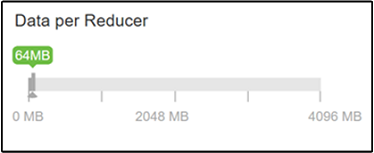
hive.exec.reducers.bytes.per.reducer 매개 변수는 리듀서당 처리되는 바이트 수를 지정합니다. 기본값은 64MB입니다. 이 값을 낮게 조정하면 병렬 처리가 증가하고 성능이 향상될 수 있습니다. 너무 낮게 조정하면 너무 리듀서가 너무 많이 생성되어 잠재적으로 성능이 저하될 수 있습니다. 이 매개 변수는 특정 데이터 요구 사항, 압축 설정 및 기타 환경 요인을 기반으로 합니다.
매개 변수를 수정하려면 Hive Configs(구성) 탭으로 이동하고 설정 페이지에서 Data per Reducer(리듀서당 데이터) 매개 변수를 찾습니다.
편집을 선택하여 값을 128MB(134,217,728바이트)로 수정한 다음 Enter를 눌러 저장합니다.
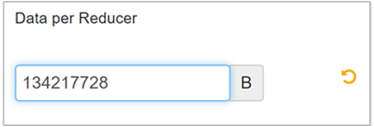
입력 크기가 1,024MB이고 Reducer당 데이터가 128MB인 경우 8개의 Reducer(1024/128)가 있습니다.
Data per Reducer(리듀서당 데이터) 매개 변수의 값이 올바르지 않으면 많은 수의 리듀서가 생성되어 쿼리 성능에 악영향을 미칠 수 있습니다. 최대 리듀서 수를 제한하려면
hive.exec.reducers.max를 적절한 값으로 설정합니다. 기본값은 1009입니다.
병렬 실행 사용
Hive 쿼리는 하나 이상의 단계에서 실행됩니다. 독립적인 단계를 병렬로 실행할 수 있으면 쿼리 성능이 향상됩니다.
병렬 쿼리 실행을 사용하려면 Hive Config(구성) 탭으로 이동하여
hive.exec.parallel속성을 검색합니다. 기본값은 false입니다. 값을 true로 변경한 다음 Enter를 눌러서 값을 저장합니다.병렬로 실행할 작업 수를 제한하려면
hive.exec.parallel.thread.number속성을 수정합니다. 기본값은 8입니다.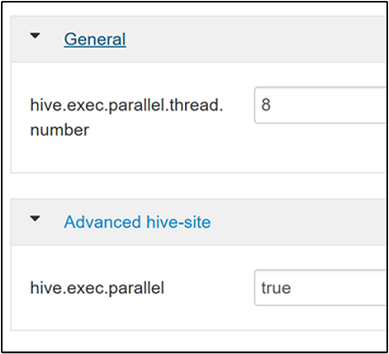
벡터화 사용
Hive는 데이터를 한 행씩 처리합니다. 벡터화는 Hive가 데이터를 한 번에 1개 행이 아니라 1,024개의 행 블록으로 처리하도록 지시합니다. 벡터화는 ORC 파일 형식에만 적용됩니다.
벡터화된 쿼리 실행을 사용하도록 설정하려면 Hive Configs(구성) 탭으로 이동하여
hive.vectorized.execution.enabled매개 변수를 검색합니다. Hive 0.13.0 이상에서는 기본값이 true입니다.쿼리의 리듀스 측에 대해 벡터화된 실행을 사용하도록 설정하려면
hive.vectorized.execution.reduce.enabled매개 변수를 true로 설정합니다. 기본값은 false입니다.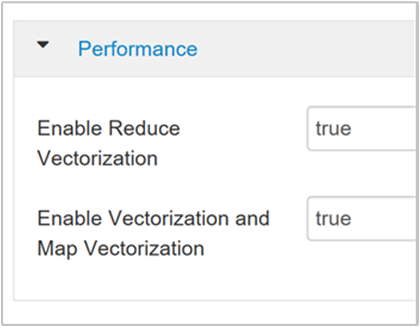
CBO(비용 기반 최적화) 사용
기본적으로 Hive는 일련의 규칙에 따라 하나의 최적 쿼리 실행 계획을 찾습니다. CBO(비용 기반 최적화)는 여러 계획을 평가하여 쿼리를 실행합니다. 그리고 각 계획에 비용을 할당한 다음 쿼리를 실행할 가장 저렴한 계획을 결정합니다.
CBO를 사용하려면 Hive>구성>설정으로 이동하여 비용 기반 최적화 프로그램 사용을 찾은 다음 토글 단추를 켜기로 전환합니다.

다음과 같은 추가적인 구성 매개 변수는 CBO를 사용할 때 Hive 쿼리 성능을 높입니다.
hive.compute.query.using.statstrue로 설정하면 Hive는 metastore에 저장된 통계를 사용하여
count(*)와 같은 간단한 쿼리에 응답합니다.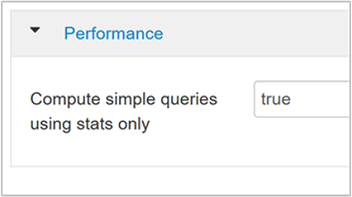
hive.stats.fetch.column.stats열 통계는 CBO를 사용하도록 설정한 경우 생성됩니다. Hive는 metastore에 저장된 열 통계를 사용하여 쿼리를 최적화합니다. 열의 수가 많을수록 각 열의 열 통계를 가져오는 시간이 길어집니다. false로 설정하면 metastore에서 열 통계 가져오기를 사용하지 않도록 설정됩니다.
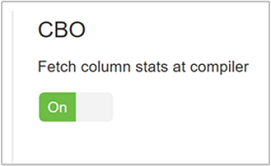
hive.stats.fetch.partition.stats행 수, 데이터 크기 및 파일 크기와 같은 기본 파티션 통계는 metastore에 저장됩니다. true로 설정되면 metastore에서 파티션 통계를 가져옵니다. false이면 파일 시스템에서 파일 크기를 가져옵니다. 행 스키마에서 행 수를 가져옵니다.
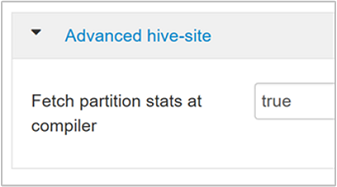
자세한 내용은 Azure Blog 분석에서 Hive 비용 기반 최적화 블로그 게시물을 참조하세요.
중간 압축 사용
맵 작업은 리듀서 작업에 사용되는 중간 파일을 만듭니다. 중간 압축은 중간 파일 크기를 축소합니다.
Hadoop 작업은 일반적으로 I/O 병목 상태가 됩니다. 데이터를 압축하면 I/O 및 전반적인 네트워크 전송 속도를 높일 수 있습니다.
사용 가능한 압축 유형은 다음과 같습니다.
| 형식 | 도구 | 알고리즘 | 파일 확장명 | 분할 가능? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
아니요 |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
예 |
| LZO | Lzop |
LZO | .lzo |
예(인덱싱된 경우) |
| Snappy | 해당 없음 | Snappy | Snappy | 아니요 |
일반적으로 압축 방법을 분할 가능하게 하는 것이 중요합니다. 그렇지 않으면 매퍼가 거의 생성되지 않습니다. 입력 데이터가 텍스트인 경우 bzip2가 최고 옵션입니다. ORC 형식의 경우 Snappy가 가장 빠른 압축 옵션입니다.
중간 압축을 사용하려면 Hive Configs(구성) 탭으로 이동한 다음
hive.exec.compress.intermediate매개 변수를 true로 설정합니다. 기본값은 false입니다.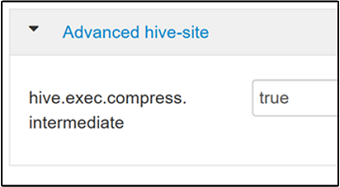
참고 항목
중간 파일을 압축하려면 코덱의 압축 출력이 높지 않더라도 CPU 비용이 낮은 압축 코덱을 선택합니다.
중간 압축 코덱을 설정하려면 사용자 지정 속성
mapred.map.output.compression.codec을hive-site.xml또는mapred-site.xml파일에 추가합니다.사용자 지정 설정을 추가하려면:
a. Hive>구성>고급>사용자 지정 hive-site로 이동합니다.
b. 사용자 지정 hive-site 창 하단에서 속성 추가 링크를 클릭합니다.
c. 속성 추가 창에서 키에
mapred.map.output.compression.codec을 입력하고 값에org.apache.hadoop.io.compress.SnappyCodec을 입력합니다.d. 추가를 선택합니다.
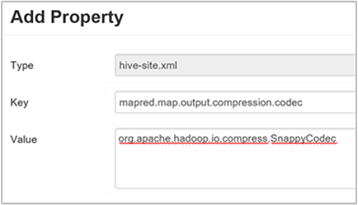
이 설정은 Snappy 압축을 사용하여 중간 파일을 압축합니다. 속성이 추가되면 사용자 지정 hive-site 창에 나타납니다.
참고 항목
이 프로시저는
$HADOOP_HOME/conf/hive-site.xml파일을 수정합니다.
압축 최종 출력
최종 Hive 출력도 압축될 수 있습니다.
최종 Hive 출력을 압축하려면 Hive Configs(구성) 탭으로 이동한 다음
hive.exec.compress.output매개 변수를 true로 설정합니다. 기본값은 false입니다.출력 압축 코덱을 선택하려면 이전 섹션 3단계의 설명에 따라 사용자 지정 hive-site 창에
mapred.output.compression.codec사용자 지정 속성을 추가합니다.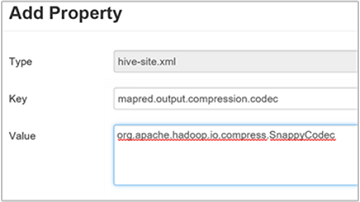
투기적 실행 사용
투기적 실행은 특정 수의 중복 작업을 시작하여 실행 속도가 느린 작업 추적기 목록을 감지하고 거부합니다. 개별 작업 결과를 최적화하여 전체 작업 실행을 개선합니다.
입력 양이 많고 오래 실행되는 MapReduce 작업에는 투기적 실행을 사용하지 말아야 합니다.
투기적 실행을 사용하려면 Hive Configs(구성) 탭으로 이동한 다음
hive.mapred.reduce.tasks.speculative.execution매개 변수를 true로 설정합니다. 기본값은 false입니다.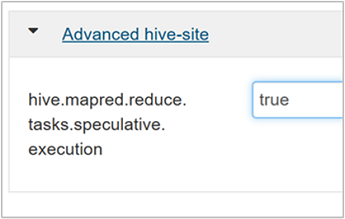
동적 파티션은 조정
Hive를 사용하면 모든 파티션을 미리 정의하지 않고도 테이블에 레코드를 삽입할 때 동적 파티션을 만들 수 있습니다. 이 기능은 강력한 기능입니다. 이를 통해 많은 수의 파티션을 만들 수 있습니다. 또한 각 파티션에 대해 많은 수의 파일을 만들 수 있습니다.
Hive가 동적 파티션을 수행하려면
hive.exec.dynamic.partition매개 변수 값이 true(기본값)여야 합니다.동적 파티션 모드를 strict로 변경합니다. strict 모드에서는 적어도 하나의 파티션이 static이어야 합니다. 이 설정은 WHERE 절에서 파티션 필터가 없는 쿼리를 방지합니다. 즉, strict는 모든 파티션을 검색하는 쿼리를 방지합니다. Hive Configs(구성) 탭으로 이동한 다음
hive.exec.dynamic.partition.mode를 strict로 설정합니다. 기본값은 nonstrict입니다.생성되는 동적 파티션 수를 제한하려면
hive.exec.max.dynamic.partitions매개 변수를 수정합니다. 기본값은 5000입니다.노드당 동적 파티션의 총 수를 제한하려면
hive.exec.max.dynamic.partitions.pernode를 수정합니다. 기본값은 2000입니다.
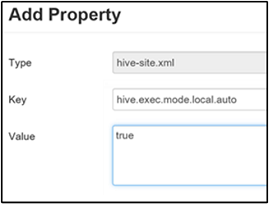
로컬 모드 사용
로컬 모드를 사용하면 Hive가 단일 머신에서 작업의 모든 작업을 수행할 수 있습니다. 또는 단일 프로세스에서 수행할 수 있는 경우도 있습니다. 이 설정은 입력 데이터가 작은 경우 쿼리 성능을 향상시킵니다. 그리고 쿼리에 대한 작업을 시작하는 오버 헤드는 전체 쿼리 실행의 상당 비율을 차지합니다.
로컬 모드를 사용하려면 중간 압축 사용 섹션의 3단계 설명에 따라 hive.exec.mode.local.auto 매개 변수를 사용자 지정 hive-site 패널에 추가합니다.
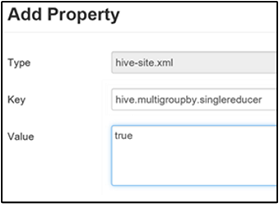
단일 MapReduce MultiGROUP BY 설정
이 속성을 true로 설정하면 공통 group-by 키가 있는 MultiGROUP BY 쿼리가 단일 MapReduce 작업을 생성합니다.
이 동작을 사용하려면 중간 압축 사용 섹션의 3단계 설명에 따라 hive.multigroupby.singlereducer 매개 변수를 사용자 지정 hive-site 창에 추가합니다.
추가적인 Hive 최적화
다음 섹션에서는 추가로 설정할 수 있는 Hive 관련 최적화를 설명합니다.
조인 최적화
Hive의 기본 조인 유형은 순서 섞기 조인입니다. Hive에서는 특수 매퍼가 입력을 읽어서 조인 키/값 쌍을 중간 파일로 내보냅니다. Hadoop은 이러한 쌍을 순서 섞기 단계에서 정렬하고 병합합니다. 순서 섞기 단계는 비용이 높습니다. 데이터를 기반으로 올바른 조인을 선택하면 성능이 상당히 향상될 수 있습니다.
| 조인 유형 | When | 방법 | Hive 설정 | 설명 |
|---|---|---|---|---|
| 순서 섞기 조인 |
|
|
특정 Hive 설정 필요 없음 | 매번 작동 |
| 맵 조인 |
|
|
hive.auto.confvert.join=true |
빠르지만 제한됨 |
| 병합 버킷 정렬 | 두 테이블이 모두:
|
각 프로세스가:
|
hive.auto.convert.sortmerge.join=true |
효율적인 경우 |
실행 엔진 최적화
Hive 실행 엔진을 최적화하기 위한 추가 권장 사항:
| 설정 | 권장 | HDInsight 기본값 |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = 더 안전하고 느림; false = 빠름 | false |
tez.am.resource.memory.mb |
대부분의 경우 4GB 상한 | 자동 튜닝 |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20,000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40,000+ | 20000 |
다음 단계
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기