Apache Spark 기록 서버의 확장 기능을 사용하여 Spark 애플리케이션 디버그 및 진단
이 문서에서는 Apache Spark 기록 서버의 확장 기능을 사용하여 완료되거나 실행 중인 Spark 애플리케이션을 디버그 및 진단하는 방법을 보여 줍니다. 확장에는 데이터 탭, 그래프 탭, 진단 탭이 포함되어 있습니다. 데이터 탭에서 Spark 작업의 입출력 데이터를 확인할 수 있습니다. 그래프 탭에서는 데이터 흐름을 확인하고 작업 그래프를 다시 재생할 수 있습니다. 진단 탭에서는 데이터 기울이기, 시간 기울이기 및 실행기 사용량 분석을 참조할 수 있습니다.
Spark 기록 서버에 액세스
Spark 기록 서버는 완료되고 실행 중인 Spark 애플리케이션의 웹 UI입니다. Azure Portal 또는 URL에서 열 수 있습니다.
Azure Portal에서 Spark 기록 서버 웹 UI 열기
Azure Portal에서 Spark 클러스터를 엽니다. 자세한 내용은 클러스터 나열 및 표시를 참조하세요.
클러스터 대시보드에서 Spark 기록 서버를 선택합니다. 메시지가 표시되면 Spark 클러스터에 대한 관리자 자격 증명을 입력합니다.
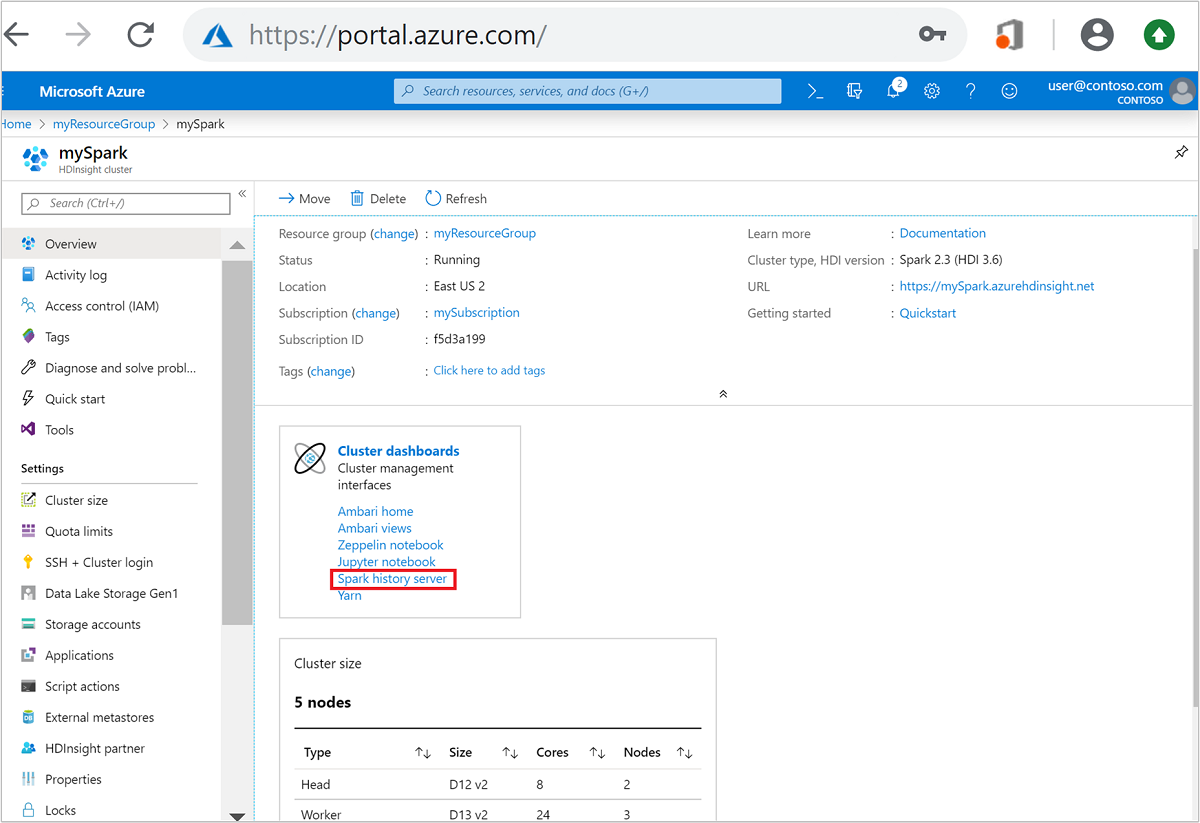 Azure Portal." border="true":::
Azure Portal." border="true":::
URL을 통해 Spark 기록 서버 웹 UI 열기
https://CLUSTERNAME.azurehdinsight.net/sparkhistory로 이동하여 Spark 기록 서버를 엽니다. 여기서 CLUSTERNAME은 Spark 클러스터의 이름입니다.
Spark 기록 서버 웹 UI는 다음 이미지와 유사하게 보일 수 있습니다.
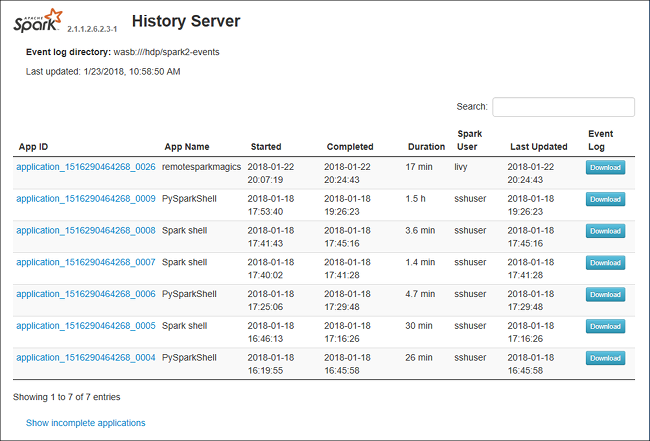
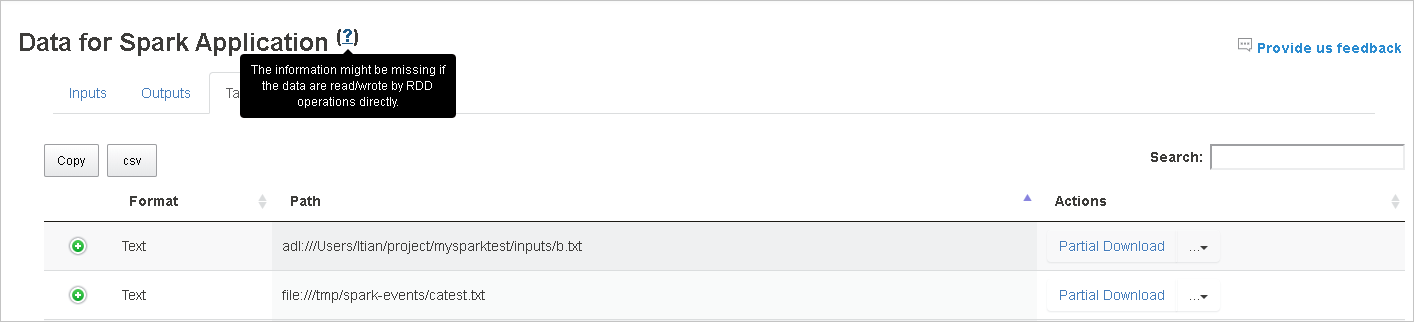
Spark 기록 서버에서 데이터 탭 열기
작업 ID를 선택한 다음 도구 메뉴에서 데이터를 선택하여 데이터 보기를 표시합니다.
각 탭을 선택하여 입력, 출력 및 테이블 작업을 검토합니다.
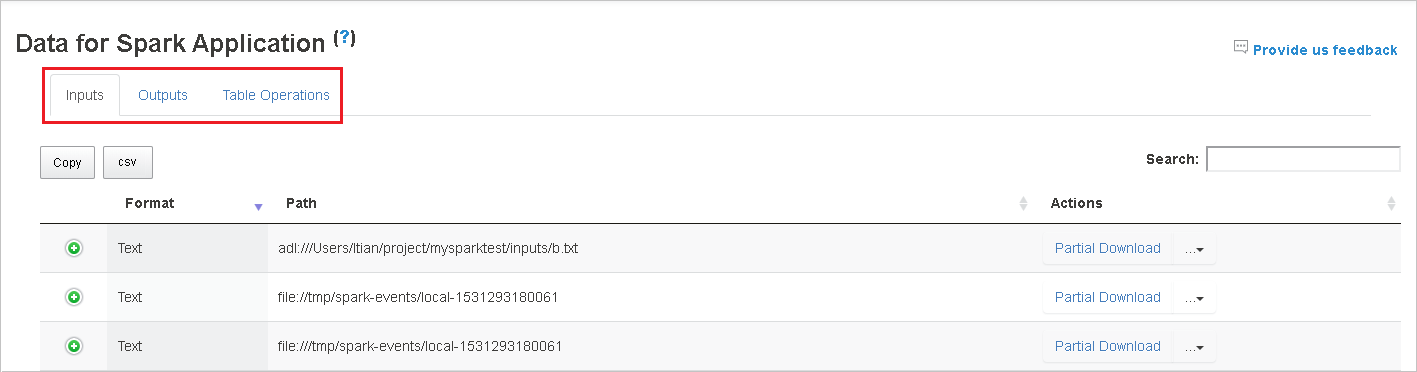
복사 단추를 선택하여 모든 행을 복사합니다.

csv 버튼을 선택하여 모든 데이터를 .CSV 파일로 저장합니다.
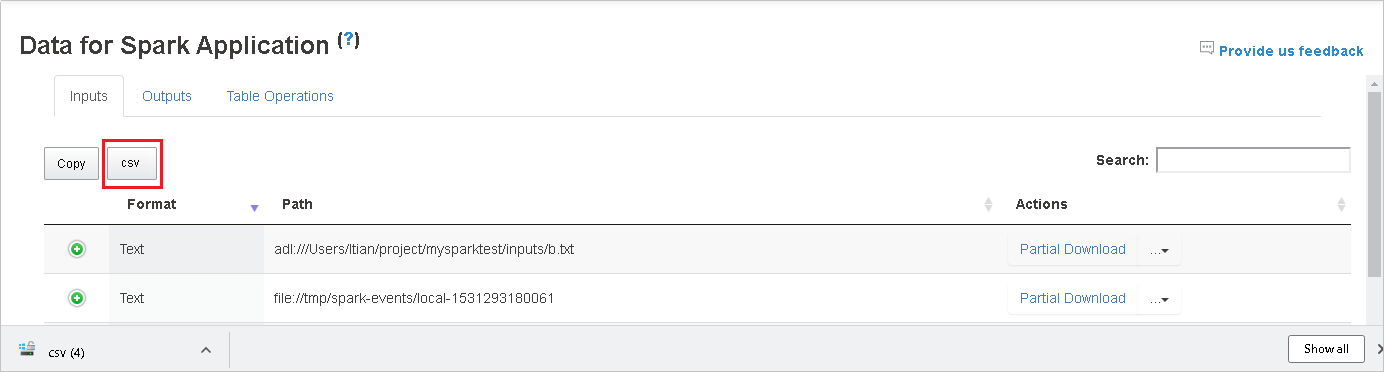
검색 필드에 키워드를 입력하여 데이터를 검색합니다. 검색 결과가 즉시 표시됩니다.
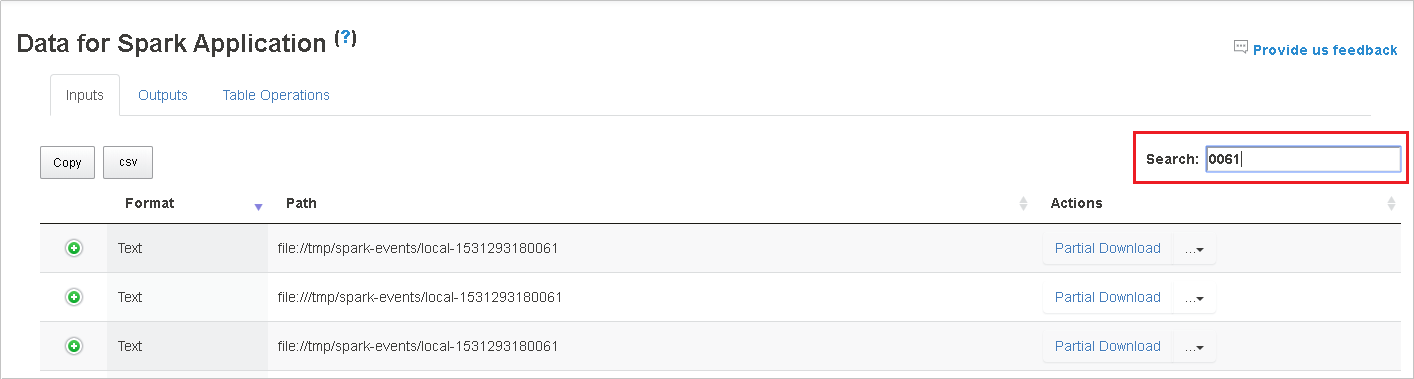
테이블을 정렬하려면 열 헤더를 선택합니다. 행을 펼치거나 자세한 정보를 표시하려면 더하기 기호를 선택합니다. 행을 접으려면 빼기 기호를 선택합니다.
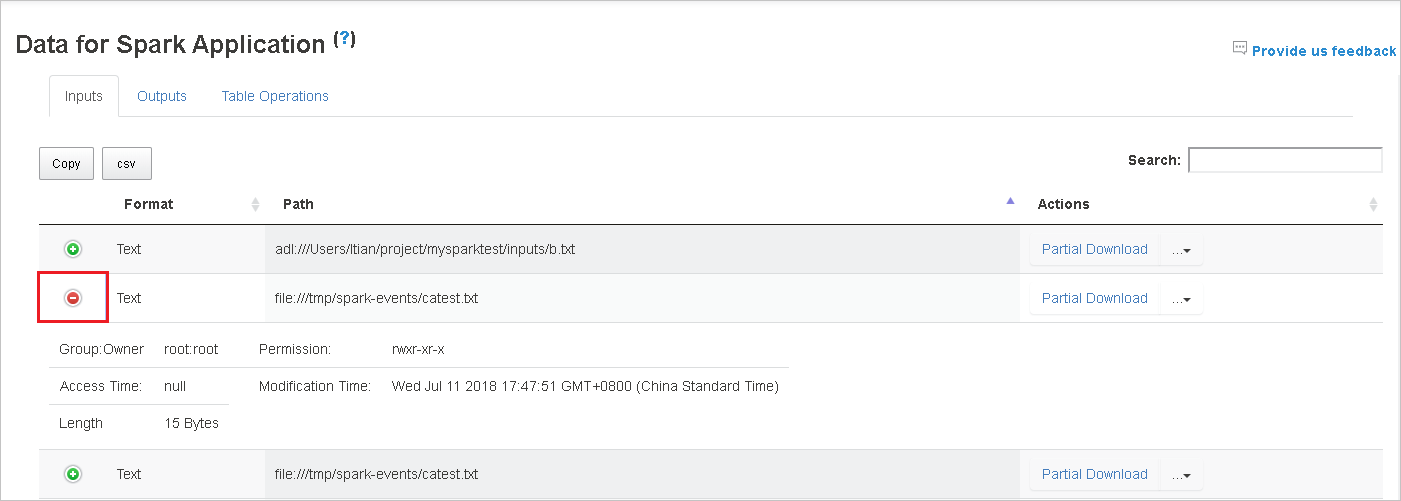
오른쪽의 부분 다운로드 단추를 선택하여 단일 파일을 다운로드합니다. 선택한 파일은 로컬에 다운로드됩니다. 파일이 더 이상 없는 경우 새 탭이 열리고 오류 메시지가 표시됩니다.
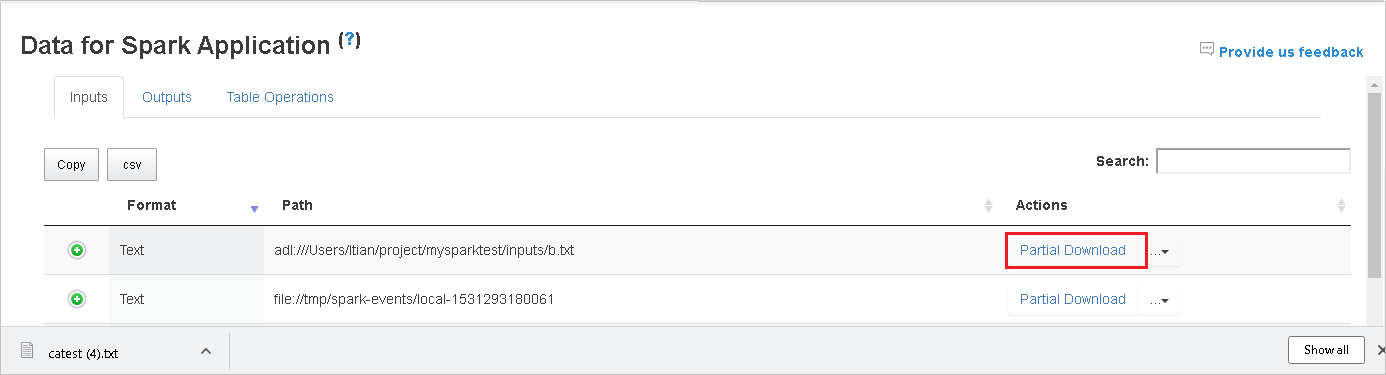
다운로드 메뉴에서 펼쳐지는 전체 경로 복사 또는 상대 경로 복사 옵션을 선택하여 전체 경로나 상대 경로를 복사합니다. Azure Data Lake Storage 파일의 경우 Azure Storage Explorer에서 열기를 선택하여 Azure Storage Explorer를 시작하고 로그인 후 해당 폴더를 찾습니다.
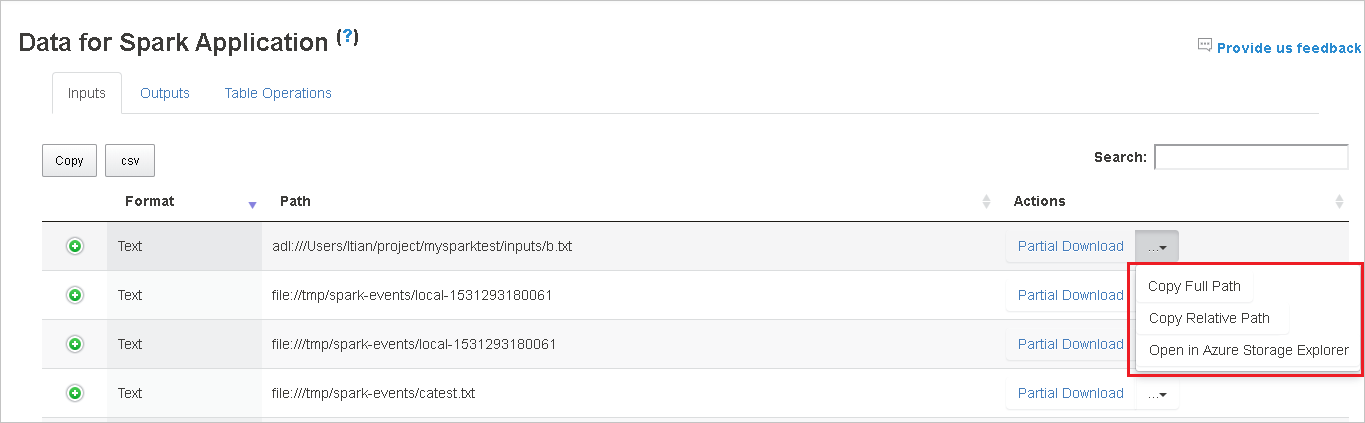
단일 페이지에 표시할 행이 너무 많으면 테이블 아래에 있는 페이지 번호를 선택하여 탐색합니다.

자세한 내용을 보려면 Spark 애플리케이션 데이터 옆에 있는 물음표 위에 마우스 포인터를 가져가거나 선택하여 도구 설명을 표시합니다.
문제에 대한 피드백을 보내려면 피드백 보내기를 선택합니다.
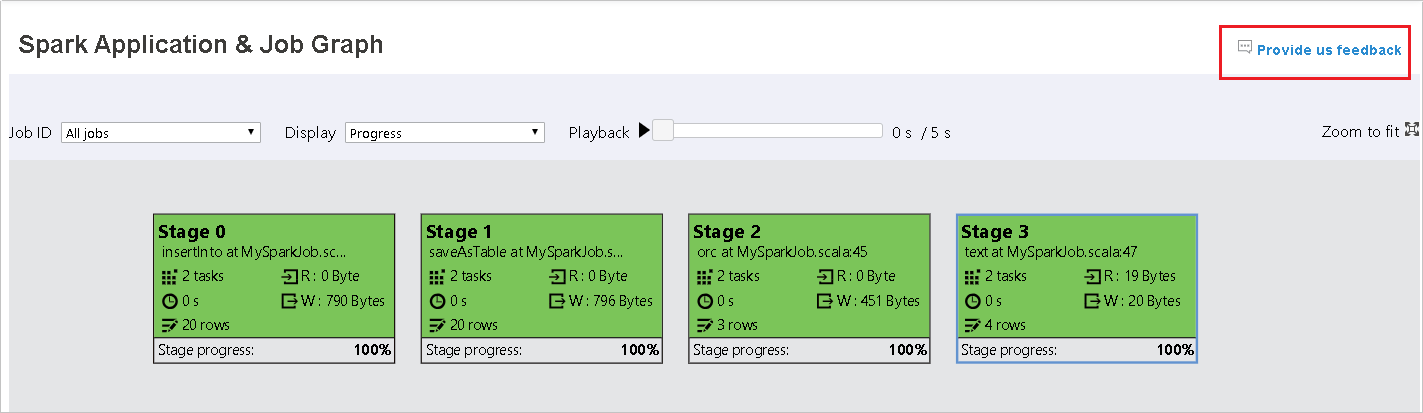
Spark 기록 서버에서 그래프 탭 열기
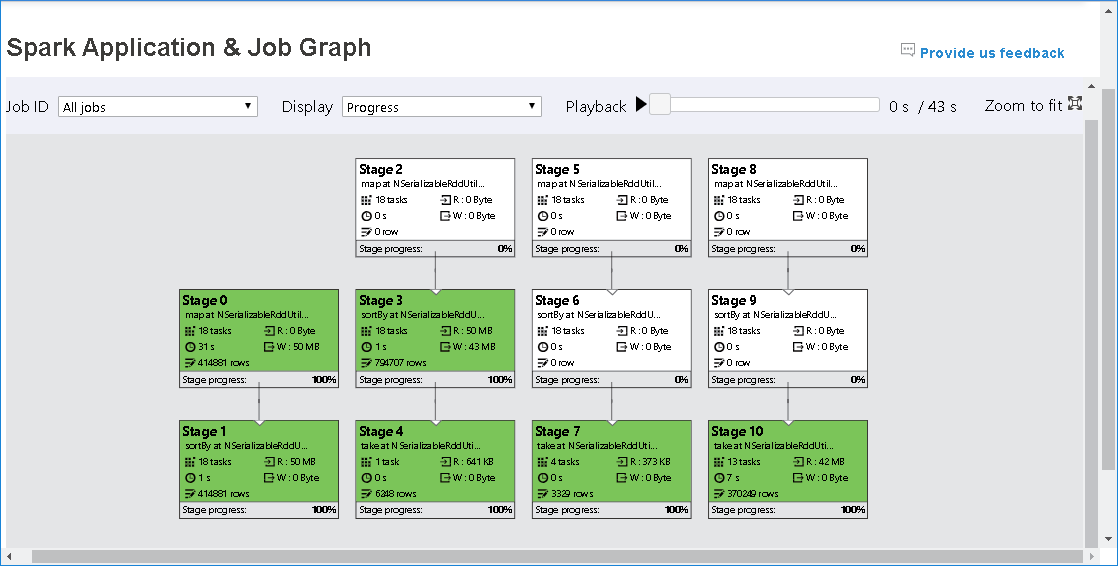
작업 ID를 선택한 다음 도구 메뉴에서 그래프를 선택하여 작업 그래프를 표시합니다. 기본적으로 그래프에는 모든 작업이 표시됩니다. 작업 ID 드롭다운 메뉴를 사용하여 결과를 필터링합니다.
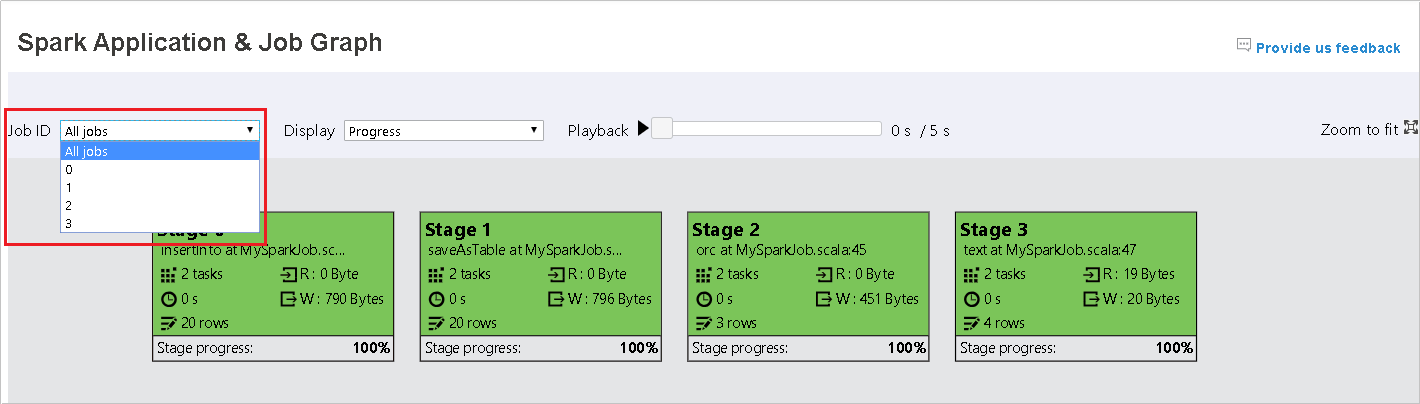
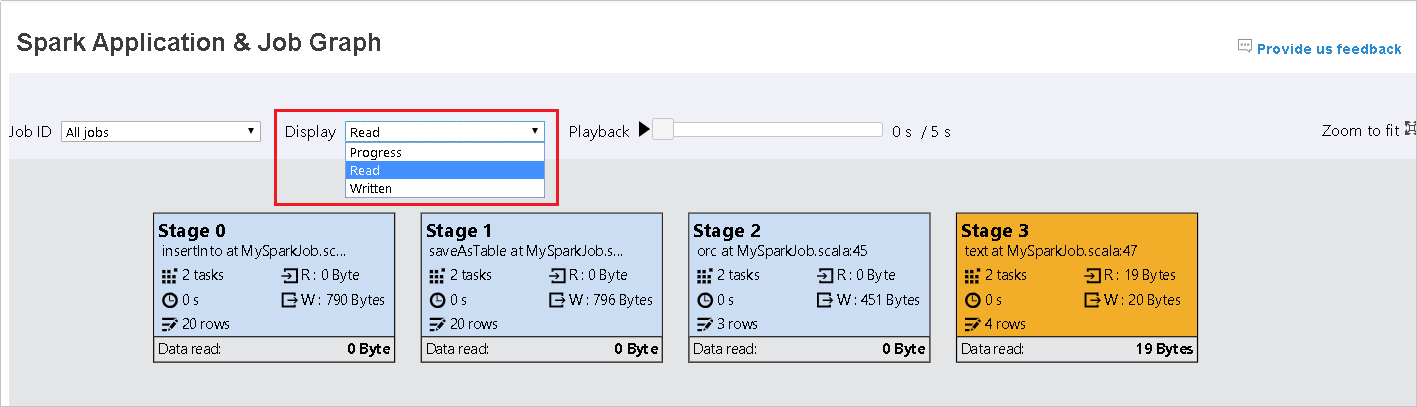
기본적으로 진행률이 선택되어 있습니다. 표시 드롭다운 메뉴에서 읽음 또는 기록함을 선택하여 데이터 흐름을 확인합니다.
각 작업의 배경색은 열 지도에 해당합니다.

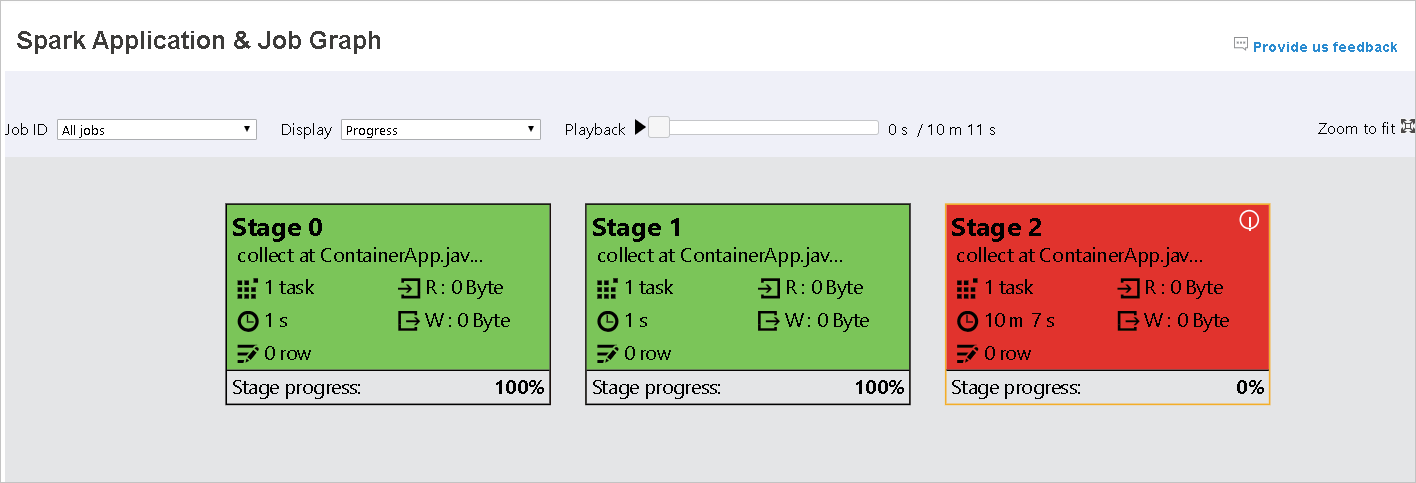
색 Description 녹색 작업이 완료되었습니다. Orange 작업이 실패했지만 작업의 최종 결과에는 영향을 주지 않습니다. 이러한 작업에는 나중에 성공할 수 있는 중복 또는 다시 시도 인스턴스가 있습니다. 파랑 작업이 실행 중입니다. 흰색 작업이 실행 대기 중이거나 단계를 건너뛰었습니다. 빨간색 작업이 실패했습니다. 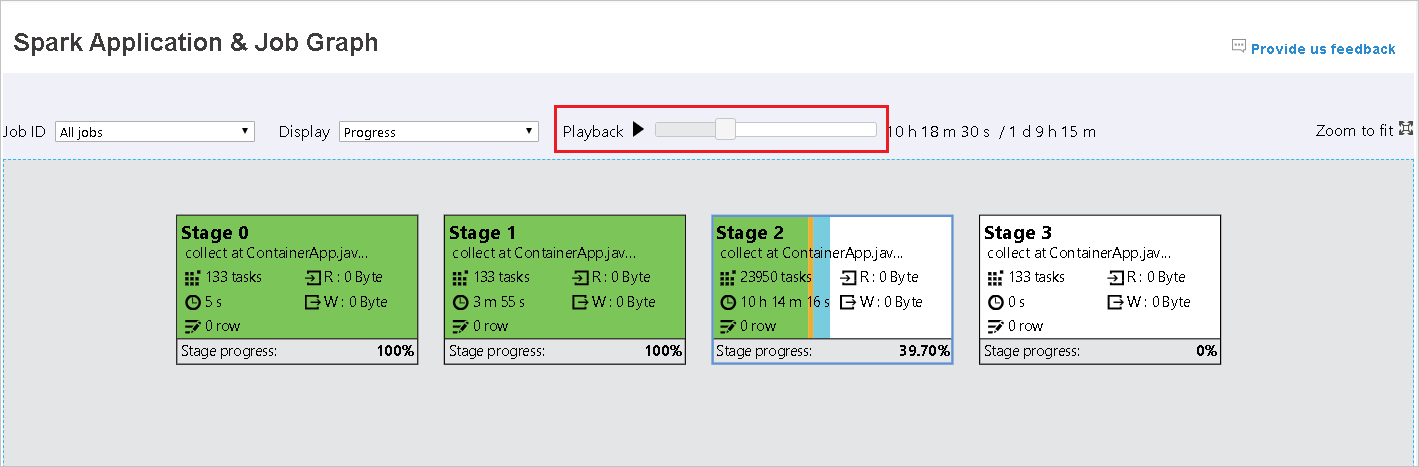
건너뛴 단계는 흰색으로 표시됩니다.
참고 항목
완료된 작업에는 재생을 사용할 수 있습니다. 재생 단추를 선택하여 작업을 재생합니다. 언제든지 중지 단추를 선택하여 작업을 중지합니다. 작업을 재생할 때 각 작업은 색으로 상태를 표시합니다. 완료되지 않은 작업에는 재생이 지원되지 않습니다.
작업 그래프를 확대하거나 축소하려면 스크롤하거나 크기에 맞게를 선택하여 화면에 맞게 조정합니다.
작업이 실패하면 그래프 노드 위에 마우스 포인터를 가져가서 도구 설명을 확인한 다음 단계를 선택하여 새 페이지에서 엽니다.
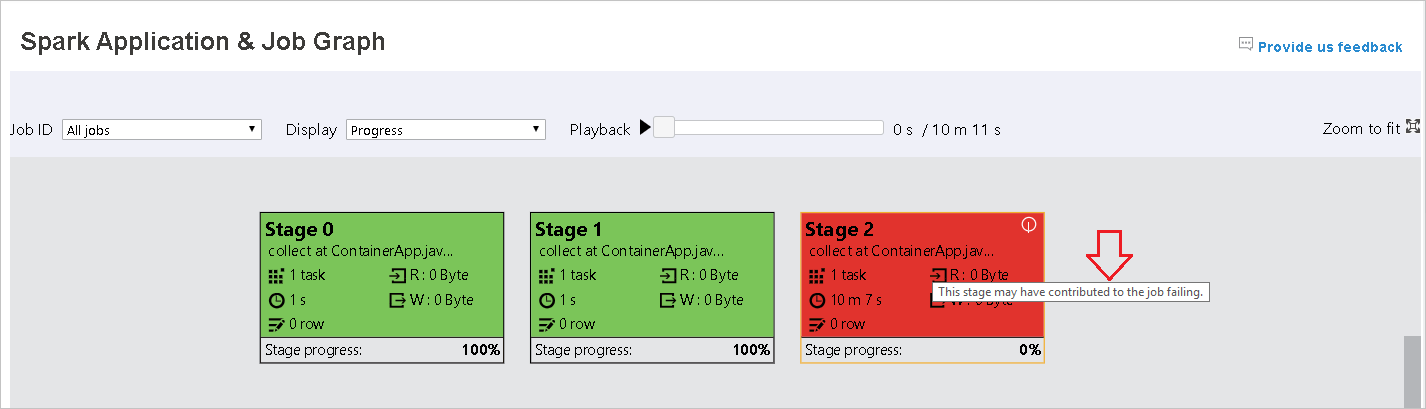
작업이 다음 조건을 충족하는 경우 Spark 애플리케이션 및 작업 그래프 페이지의 단계에 도구 설명 및 작은 아이콘이 표시됩니다.
데이터 기울이기: 데이터 읽기 크기 > 이 단계에 속한 모든 작업의 평균 데이터 읽기 크기 * 2 + 데이터 읽기 크기 > 10MB
시간 기울이기: 실행 시간 > 이 단계에 속한 모든 작업의 평균 실행 시간 * 2 + 실행 시간 > 2분
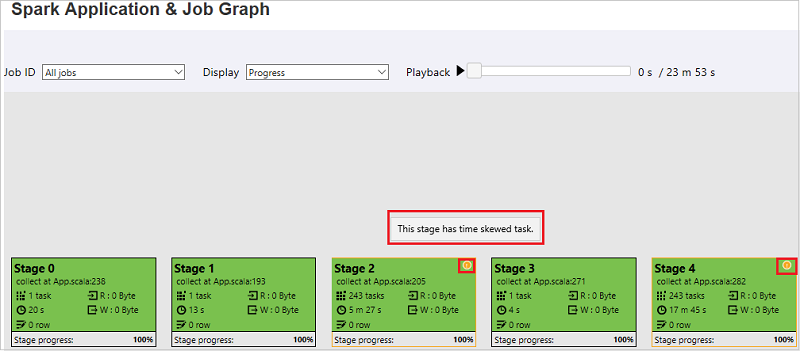
작업 그래프 노드에는 각 단계에 대한 다음 정보가 표시됩니다.
ID
이름 또는 설명
총 작업 수
읽은 데이터: 입력 크기 및 무작위 읽기 크기의 합
기록한 데이터: 출력 크기 및 무작위 쓰기 크기의 합
실행 시간: 첫 시도의 시작 시간과 마지막 시도의 완료 시간 사이의 시간
행 수: 입력 레코드, 출력 레코드, 무작위 읽기 레코드 및 무작위 쓰기 레코드의 합
진행률
참고 항목
기본적으로 작업 그래프 노드에는 단계 실행 시간을 제외하고 각 단계의 마지막 시도 정보가 표시됩니다. 그러나 재생 중에는 작업 그래프 노드에 각 시도의 정보가 표시됩니다.
참고 항목
읽은 데이터 및 기록한 데이터 크기에는 1MB = 1000KB = 1000 * 1000바이트를 사용합니다.
피드백 보내기를 선택하여 문제에 관한 피드백을 보냅니다.
Spark 기록 서버에서 진단 탭 열기
작업 ID를 선택한 다음 도구 메뉴에서 진단을 선택하여 작업 진단 보기를 표시합니다. 진단 탭에는 데이터 기울이기, 시간 기울이기 및 실행기 사용량 분석이 표시됩니다.
각 탭을 선택하여 데이터 기울이기, 시간 기울이기 및 실행기 사용량 분석을 검토합니다.
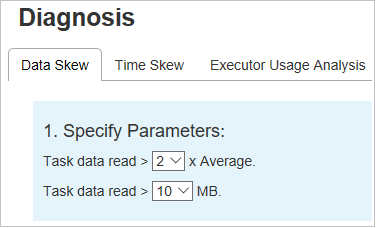
데이터 기울이기
데이터 기울이기 탭을 선택하면 지정한 매개 변수에 따라 해당 기울어진 작업이 표시됩니다.
매개 변수 지정
매개 변수 지정 섹션에는 데이터 기울이기를 검색하는 데 사용되는 매개 변수가 표시됩니다. 기본 규칙은 읽은 작업 데이터가 평균 읽은 작업 데이터의 3배보다 크고, 10MB를 초과하는 것입니다. 기울어진 작업에 대한 고유 규칙을 정의하려는 경우 매개 변수를 선택할 수 있습니다. 기울어진 단계 및 기울이기 차트 섹션은 선택한 매개 변수에 따라 업데이트됩니다.
기울어진 단계
기울어진 단계 섹션에는 지정된 조건을 충족하는 기울어진 작업이 있는 단계가 표시됩니다. 한 단계에 기울어진 작업이 여러 개 있을 경우 기울어진 단계 섹션에 가장 많이 기울어진 작업(예: 가장 큰 데이터 기울이기 관련 데이터)만 표시됩니다.
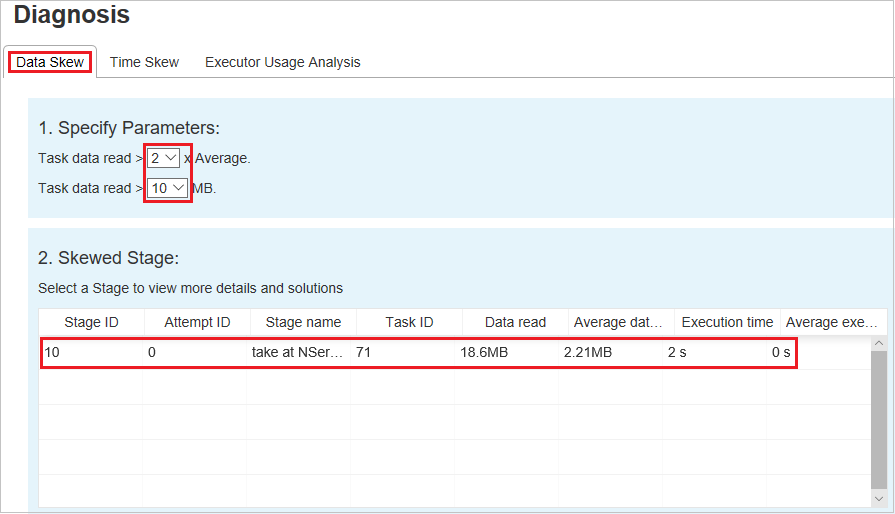
기울이기 차트
기울이기 단계 테이블에서 행을 선택하면 기울이기 차트에 읽은 데이터 및 실행 시간에 따라 더 상세한 작업 배포 정보가 표시됩니다. 기울어진 작업은 빨간색으로 표시되고 일반 작업은 파란색으로 표시됩니다. 성능을 고려하여 차트에는 최대 100개의 샘플 작업만 표시됩니다. 작업 세부 정보는 오른쪽 아래 패널에 표시됩니다.
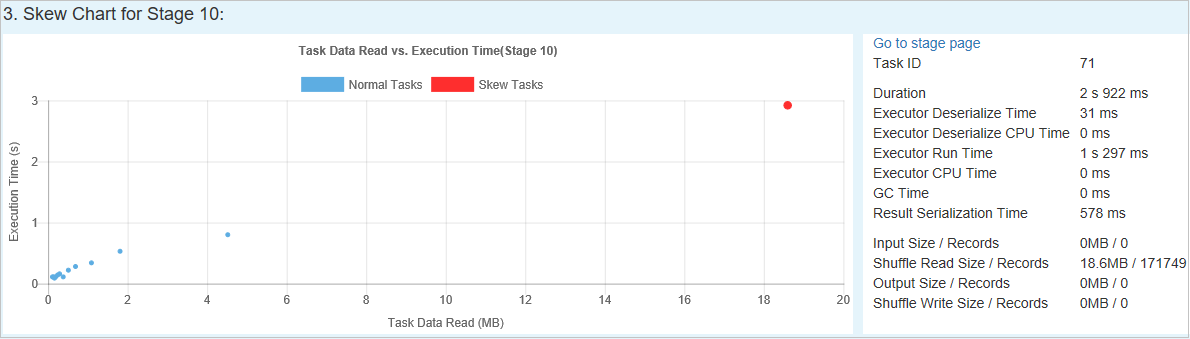
시간 기울이기
시간 기울이기 탭에는 작업 실행 시간을 기준으로 기울어진 작업이 표시됩니다.
매개 변수 지정
매개 변수 지정 섹션에는 시간 기울이기를 검색하는 데 사용되는 매개 변수가 표시됩니다. 기본 규칙은 작업 실행 시간이 평균 실행 시간의 3배보다 크고 30초를 초과하는 것입니다. 필요에 따라 매개 변수를 변경할 수 있습니다. 기울어진 작업 및 기울이기 차트에는 데이터 기울이기 탭과 마찬가지로 해당 단계 및 작업 정보가 표시됩니다.
시간 기울이기를 선택하면 매개 변수 지정 섹션에 설정된 매개 변수에 따라 필터링된 결과가 기울어진 단계 섹션에 표시됩니다. 기울어진 단계 섹션에서 한 항목을 선택하면 해당 차트가 세 번째 섹션에서 초안으로 작성되고 오른쪽 아래 패널에 작업 세부 정보가 표시됩니다.
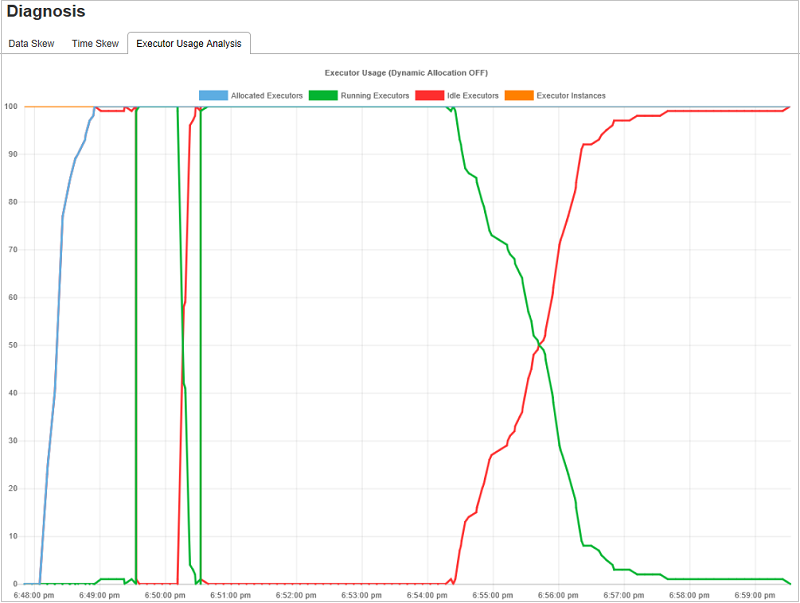
실행기 사용량 분석 그래프
실행기 사용량 그래프는 작업의 실제 실행기 할당 및 실행 상태를 표시합니다.
실행기 사용량 분석을 클릭하면 실행기 사용량에 관한 4가지 곡선(할당된 실행기, 실행 중인 실행기, 유휴 실행기 및 최대 실행기 인스턴스)이 초안으로 작성됩니다. 각 실행기 추가됨 또는 실행기 제거됨 이벤트는 할당된 실행기를 늘리거나 줄입니다. 자세한 비교를 위해 작업 탭에서 이벤트 타임라인을 확인할 수 있습니다.
색상 아이콘을 선택하여 모든 초안에서 해당 콘텐츠를 선택하거나 선택 취소합니다.
FAQ
커뮤니티 버전으로 되돌리는 방법은 무엇인가요?
커뮤니티 버전으로 되돌리려면 다음 단계를 수행합니다.
Ambari에서 클러스터를 엽니다.
Spark2>Configs로 이동합니다.
사용자 지정 spark2-defaults를 선택합니다.
속성 추가...를 선택합니다.
spark.ui.enhancement.enabled=false를 추가하고 저장합니다.
이제 속성을 false로 설정합니다.
저장을 선택하여 구성을 저장합니다.
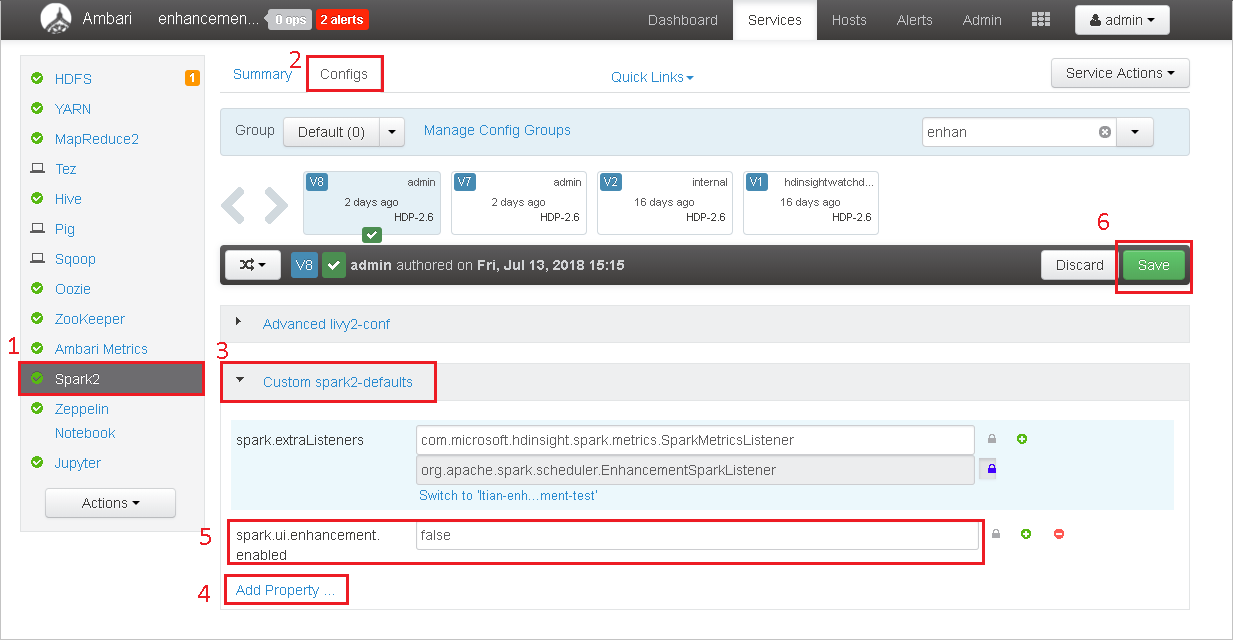
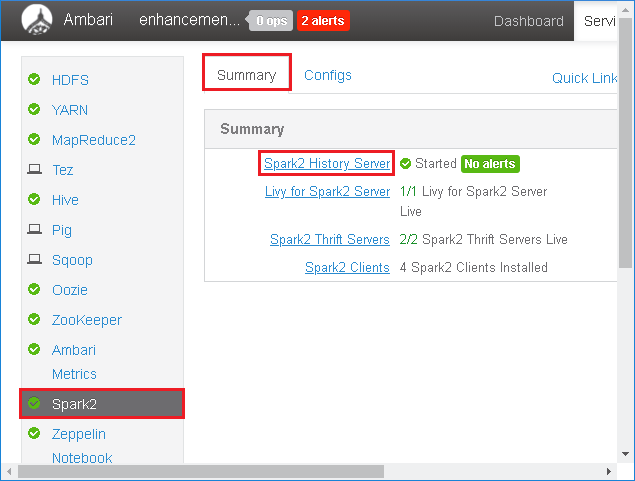
왼쪽 패널에서 Spark2를 선택합니다. 그런 다음 요약 탭에서 Spark2 기록 서버를 선택합니다.
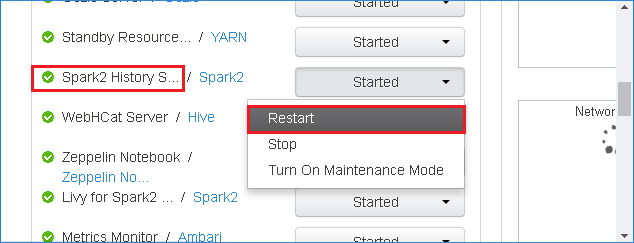
Spark 기록 서버를 다시 시작하려면 Spark2 기록 서버 오른쪽에 있는 시작됨 단추를 선택한 다음 드롭다운 메뉴에서 다시 시작을 선택합니다.
Spark 기록 서버 웹 UI를 새로 고칩니다. 그러면 커뮤니티 버전으로 되돌아갑니다.
Spark 기록 서버 이벤트를 업로드하여 문제로 보고하려면 어떻게 할까요?
Spark 기록 서버에서 오류가 발생하는 경우 다음 단계를 수행하여 이벤트를 보고합니다.
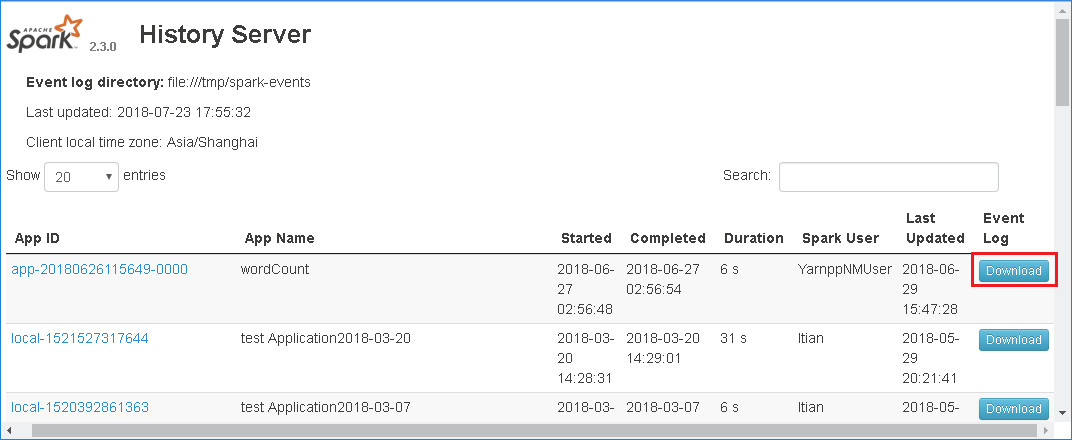
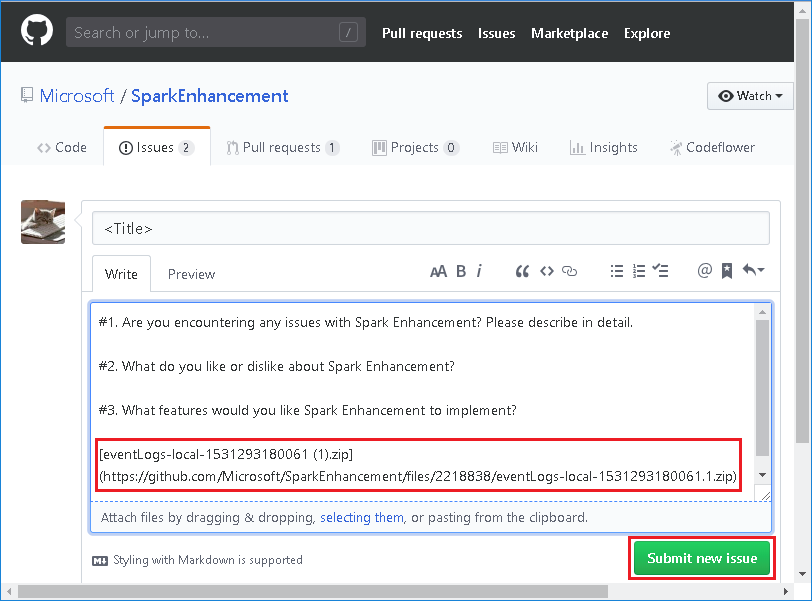
Spark 기록 서버 웹 UI에서 다운로드를 선택하여 이벤트를 다운로드합니다.
Spark 애플리케이션 및 작업 그래프 페이지에서 피드백 보내기를 선택합니다.
오류 제목 및 설명을 입력합니다. 그런 다음 .zip 파일을 편집 필드로 끌고 새 문제 제출을 선택합니다.
핫픽스 시나리오에서 jar 파일을 업그레이드하려면 어떻게 할까요??
핫픽스를 사용하여 업그레이드하려면 다음 스크립트를 사용합니다. 그러면 spark-enhancement.jar*가 업그레이드됩니다.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
사용
upgrade_spark_enhancement.sh https://${jar_path}
예시
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Azure Portal에서 Bash 파일 사용
Azure Portal을 시작하고 클러스터를 선택합니다.
다음 매개 변수를 사용하여 스크립트 작업을 완료합니다.
속성 값 스크립트 유형 - 사용자 지정 이름 UpgradeJar Bash 스크립트 URI https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.sh노드 유형 헤드, 작업자 매개 변수 https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar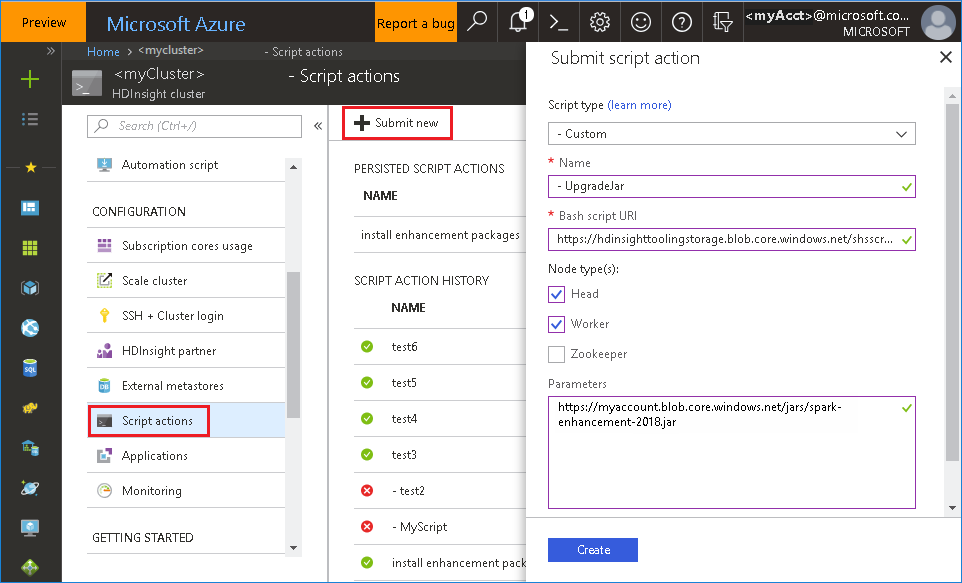
알려진 문제
현재 Spark 기록 서버는 Spark 2.3 및 2.4에서만 작동합니다.
RDD를 사용하는 입력 및 출력 데이터는 데이터 탭에 표시되지 않습니다.
다음 단계
제안
이 도구를 사용하면서 피드백이 있거나 문제가 발생하면 hdivstool@microsoft.com으로 이메일을 보내세요.