이 자습서에서는 IntelliJ IDEA에서 Apache Maven을 사용하여 Scala로 작성한 Apache Spark 애플리케이션을 만드는 방법을 알아봅니다. 이 문서에서는 Apache Maven을 빌드 시스템으로 사용합니다. 그리고 IntelliJ IDEA에서 제공하는 Scala용 기존 Maven 원형으로 시작합니다. IntelliJ IDEA에서 Scala 애플리케이션 만들기는 다음 단계를 포함합니다.
- 빌드 시스템으로 Maven을 사용합니다.
- POM(프로젝트 개체 모델) 파일을 업데이트하여 Spark 모듈 종속성을 해결합니다.
- Scala에서 애플리케이션을 작성합니다.
- HDInsight Spark 클러스터에 제출할 수 있는 jar 파일을 생성합니다.
- Livy를 사용하여 Spark 클러스터에서 애플리케이션을 실행합니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- IntelliJ IDEA용 Scala 플러그 인 설치
- IntelliJ를 사용 하 여 Scala Maven 애플리케이션 개발
- 독립 실행형 Scala 프로젝트 만들기
필수 조건
HDInsight의 Apache Spark. 자세한 내용은 Azure HDInsight에서 Apache Spark 클러스터 만들기를 참조하세요.
Oracle Java Development 키트. 이 자습서에서는 Java 버전 8.0.202를 사용합니다.
Java IDE. 이 문서에서는 IntelliJ IDEA 커뮤니티 버전 2018.3.4를 사용합니다.
Azure Toolkit for IntelliJ. Azure Toolkit for IntelliJ 설치를 참조하세요.
IntelliJ IDEA용 Scala 플러그 인 설치
Scala 플러그 인을 설치하려면 다음 단계를 수행합니다.
IntelliJ IDEA를 엽니다.
시작 화면에서 구성>플러그인으로 이동하여 플러그인 창을 엽니다.
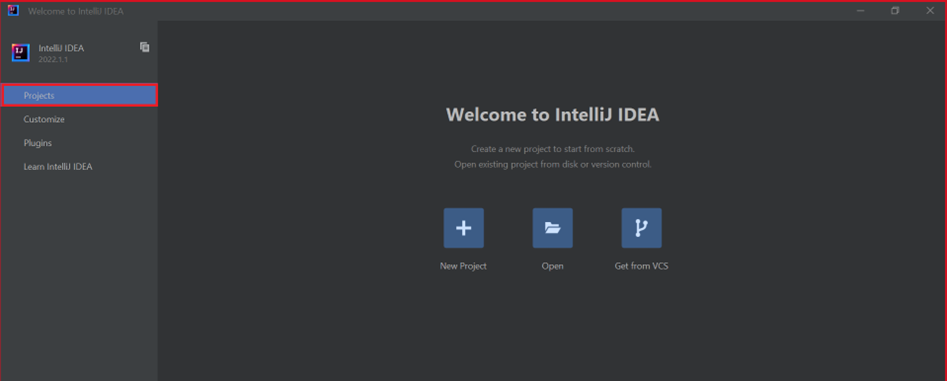
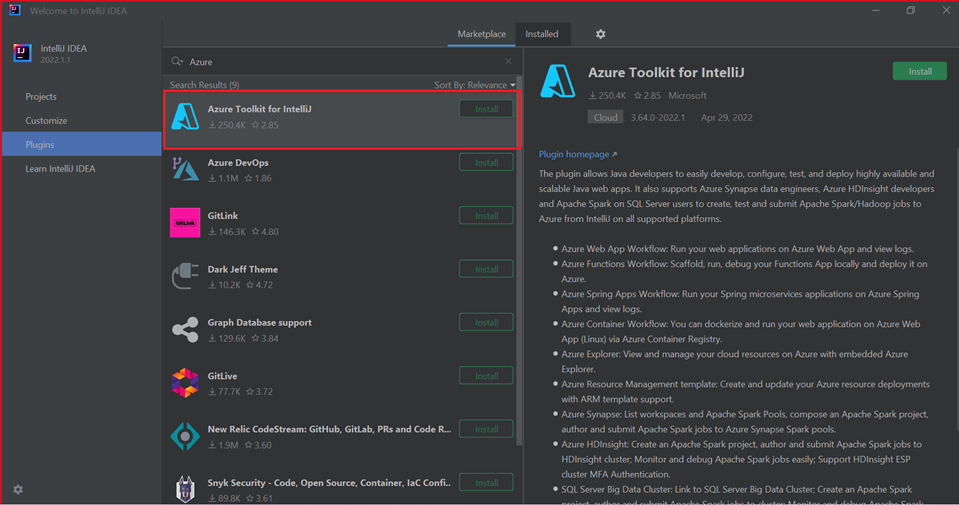
Azure Toolkit for IntelliJ에 대해 설치를 선택합니다.
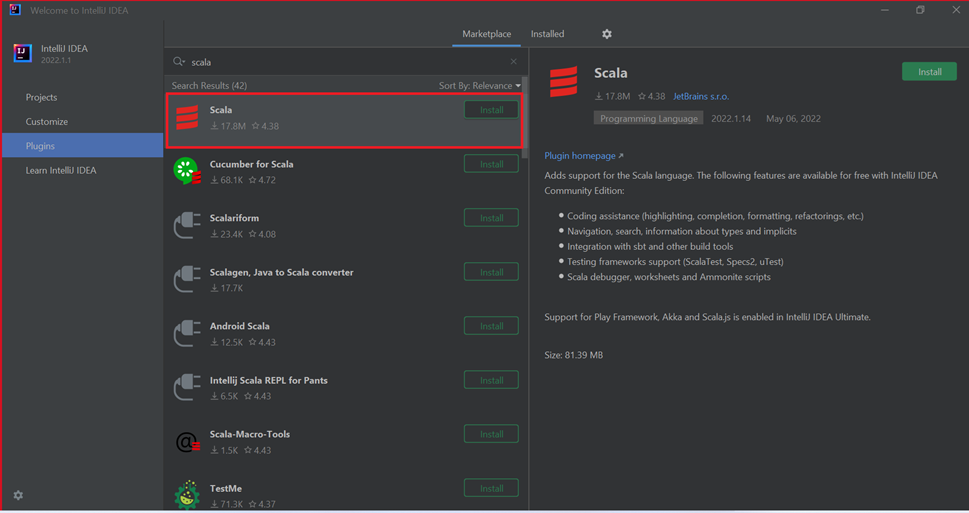
새 창에 제공되는 Scala 플러그인에 대해 설치를 선택합니다.
플러그 인이 성공적으로 설치된 후에 IDE를 다시 시작해야 합니다.
IntelliJ를 사용하여 애플리케이션 만들기
IntelliJ IDEA를 시작하고 새 프로젝트 만들기를 선택하여 새 프로젝트 창을 엽니다.
왼쪽 창에서 Apache Spark/HDInsight를 선택합니다.
주 창에서 Spark 프로젝트(Scala)를 선택합니다.
빌드 도구 드롭다운 목록에서 다음 값 중 하나를 선택합니다.
- Maven: Scala 프로젝트 만들기 마법사 지원의 경우
- SBT - 종속성 관리 및 Scala 프로젝트용 빌드의 경우
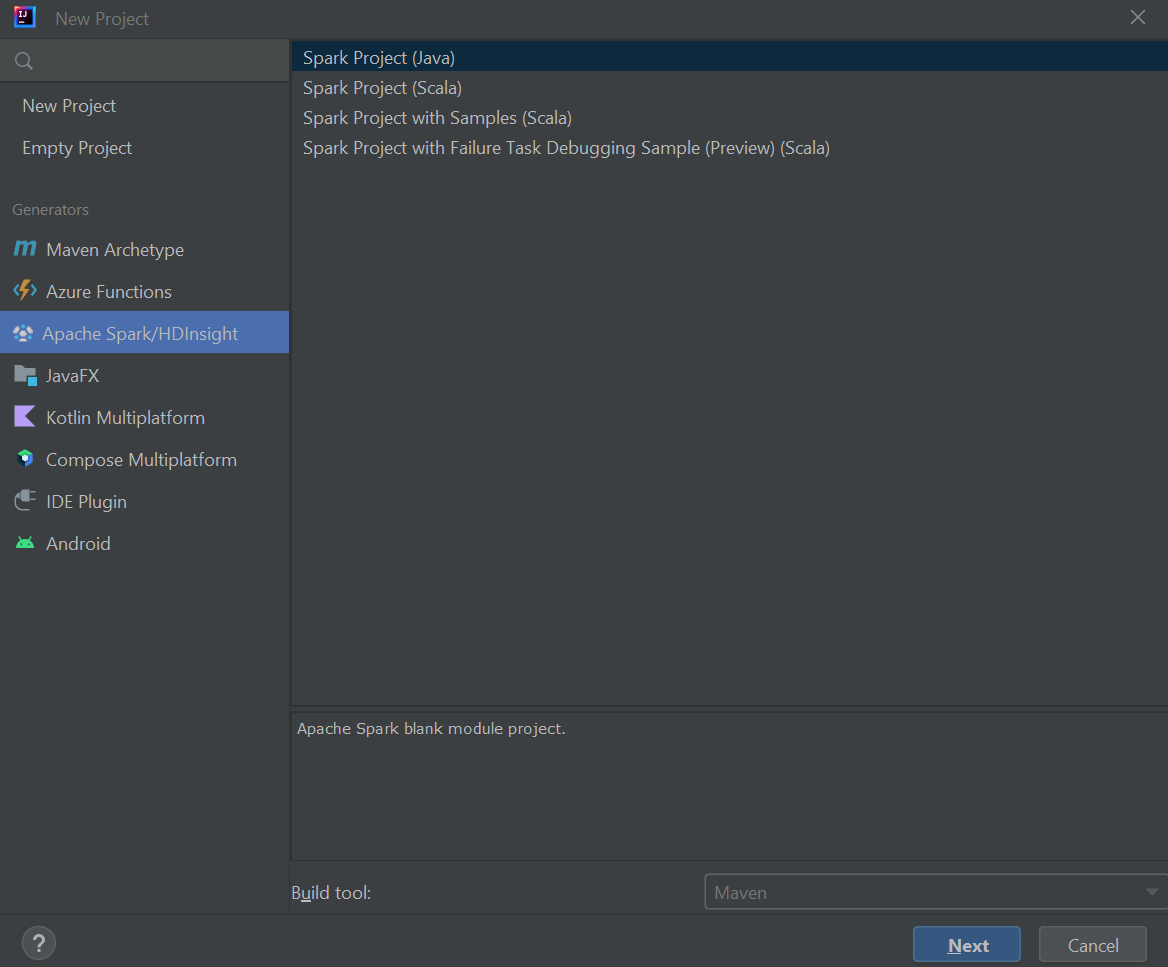
다음을 선택합니다.
새 프로젝트 창에서 다음 정보를 제공합니다.
속성 설명 프로젝트 이름 이름을 입력합니다. 프로젝트 위치 프로젝트를 저장할 위치를 입력합니다. 프로젝트 SDK IDEA를 처음 사용하는 경우에는 이 필드가 비어 있습니다. 새로 만들기...를 만들기 JDK로 이동합니다. Spark 버전 만들기 마법사는 Spark SDK 및 Scala SDK에 대해 적합한 버전을 통합합니다. Spark 클러스터 버전이 2.0 이전인 경우 Spark 1.x를 선택합니다. 그렇지 않으면 Spark2.x를 선택합니다. 이 예제에서는 Spark 2.3.0(Scala 2.11.8)을 사용합니다. 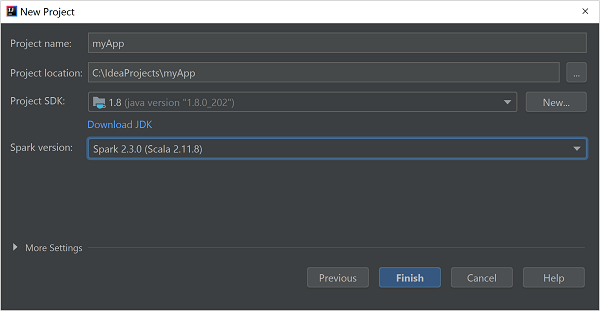
마침을 선택합니다.
독립 실행형 Scala 프로젝트 만들기
IntelliJ IDEA를 시작하고 새 프로젝트 만들기를 선택하여 새 프로젝트 창을 엽니다.
왼쪽 창에서 Maven을 선택합니다.
프로젝트 SDK를 지정합니다. 비어 있을 경우 새로 만들기...를 선택하고 Java 설치 디렉터리로 이동합니다.
원형으로부터 만들기 확인란을 선택합니다.
원형 목록에서
org.scala-tools.archetypes:scala-archetype-simple을 선택합니다. 이 원형은 올바른 디렉터리 구조를 만들고 Scala 프로그램 작성에 필요한 기본 종속성을 다운로드합니다.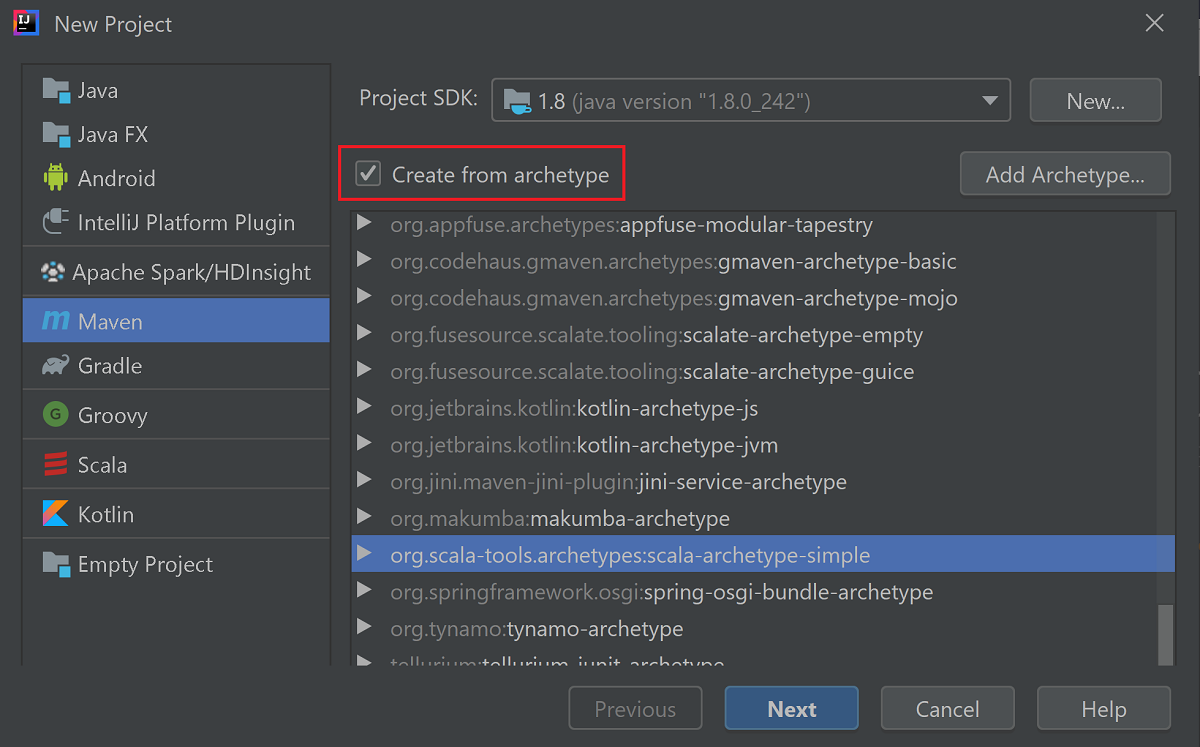
다음을 선택합니다.
아티팩트 좌표를 확장합니다. GroupId 및 ArtifactId에 관련 값을 제공합니다. 이름 및 위치는 자동으로 채워집니다. 이 자습서에서는 다음 값이 사용됩니다.
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
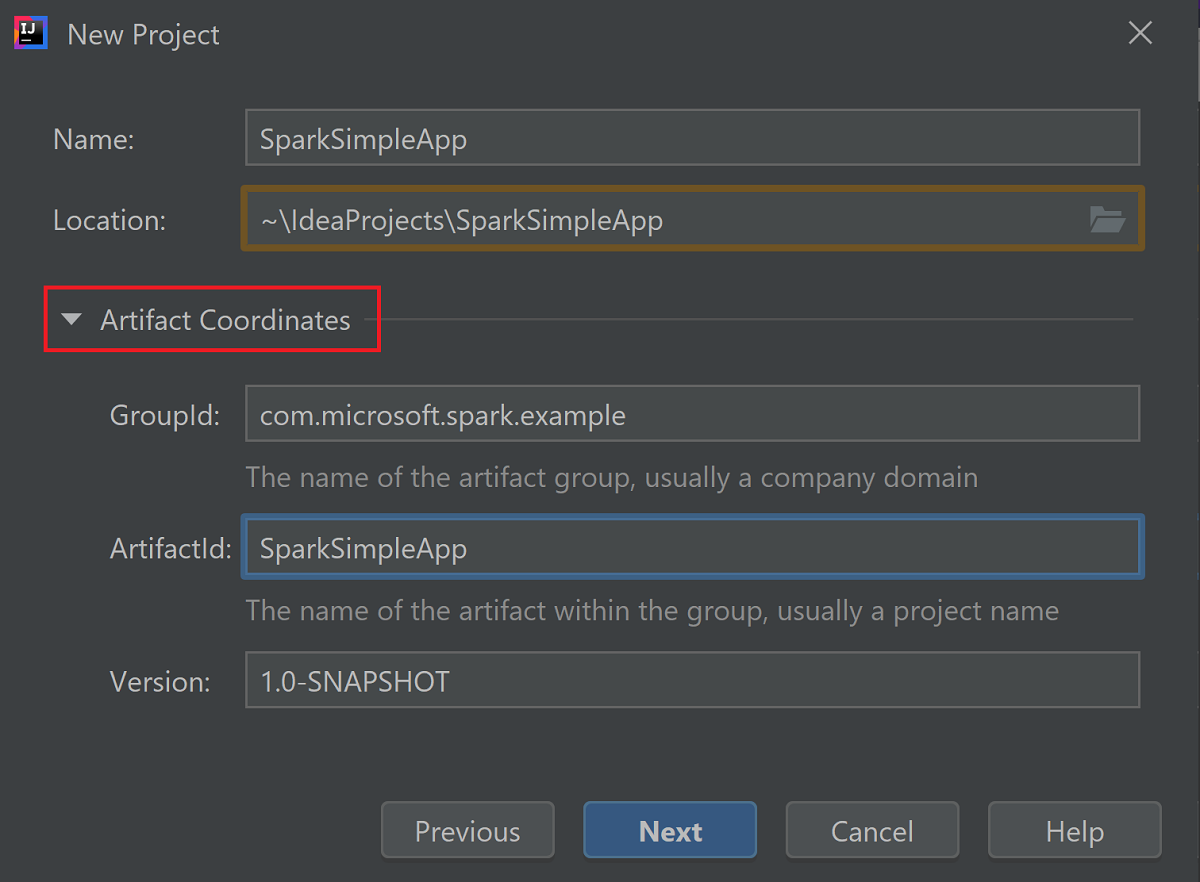
다음을 선택합니다.
설정을 검토한 후 다음을 선택합니다.
프로젝트 이름과 위치를 확인하고 마침을 선택합니다. 이 프로젝트는 가져오는 데 몇 분 정도 걸립니다.
프로젝트를 가져왔으면 왼쪽 창에서 SparkSimpleApp>src>test>scala>com>microsoft>spark>example로 이동합니다. MySpec을 마우스 오른쪽 단추로 클릭한 다음, 삭제...를 선택합니다. 애플리케이션에 이 파일이 필요하지는 않습니다. 대화 상자에서 확인을 선택합니다.
이후 단계에서는 pom.xml을 업데이트하여 Spark Scala 애플리케이션에 대한 종속성을 정의합니다. 다운로드되고 자동으로 해결되는 이러한 종속성의 경우 Maven을 구성해야 합니다.
파일 메뉴에서 설정을 선택하여 설정 창을 엽니다.
설정 창에서 빌드, 실행, 배포>빌드 도구>Maven>가져오기로 이동합니다.
Maven 프로젝트 자동으로 가져오기 확인란을 선택합니다.
적용을 선택한 다음 확인을 선택합니다. 그러면 프로젝트 창으로 돌아갑니다.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::왼쪽 창에서 src>main>scala>com.microsoft.spark.example로 이동하고 앱을 두 번 클릭하여 App.scala를 엽니다.
기존 샘플 코드를 다음 코드로 바꾸고 변경 내용을 저장합니다. 이 코드는 HVAC.csv(모든 HDInsight Spark 클러스터에서 사용 가능)에서 데이터를 읽습니다. 여섯 번째 열에 한 자리 수만 있는 행을 검색합니다. 그리고 클러스터의 기본 스토리지 컨테이너 아래에 /HVACOut에 출력을 씁니다.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }왼쪽 창에서 pom.xml을 두 번 클릭합니다.
<project>\<properties>에 다음 세그먼트를 추가합니다.<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version><project>\<dependencies>에 다음 세그먼트를 추가합니다.<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml..jar 파일을 만듭니다. IntelliJ IDEA는 프로젝트의 아티팩트로 JAR을 작성할 수 있습니다. 다음 단계를 수행하세요.
파일 메뉴에서 프로젝트 구조...를 선택합니다.
프로젝트 구조 창에서 아티팩트>더하기 기호 +>JAR>종속 항목이 있는 모듈에서...로 이동합니다.
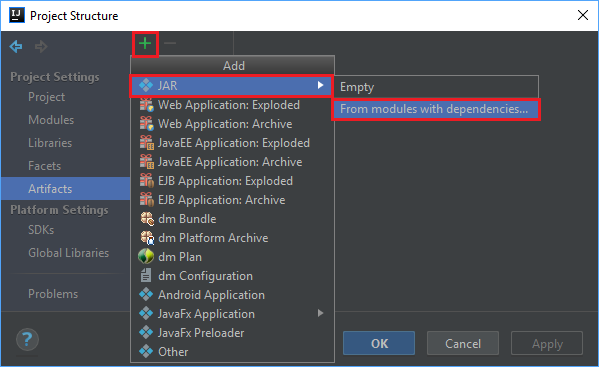
모듈에서 JAR 만들기 창의 주 클래스 텍스트 상자에서 폴더 아이콘을 선택합니다.
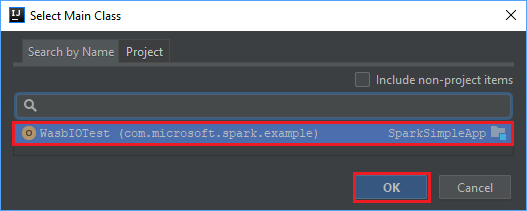
주 클래스 선택 창에서 기본적으로 표시되는 클래스를 선택한 다음, 확인을 선택합니다.
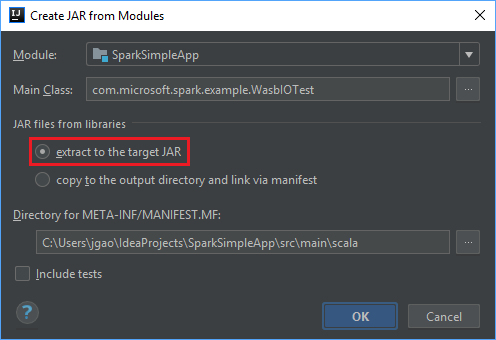
모듈에서 JAR 만들기 창에서 대상 JAR에 추출 옵션이 선택되었는지 확인한 다음, 확인을 선택합니다. 이 설정을 사용하면 모든 종속성이 있는 단일 JAR이 만들어집니다.
출력 레이아웃 탭에는 Maven 프로젝트의 일부분으로 포함된 jar이 모두 나열됩니다. 직접 종속성이 없는 Scala 애플리케이션을 선택하고 삭제할 수 있습니다. 여기에서 만드는 애플리케이션의 경우 마지막 것(SparkSimpleApp 컴파일 출력)을 제외한 모두를 제거할 수 있습니다. jar을 선택하여 삭제한 다음, 빼기 기호 -를 선택합니다.
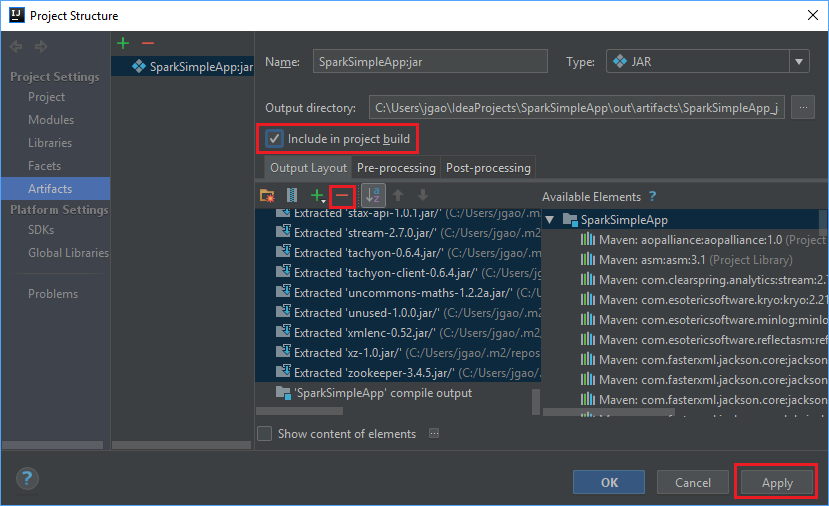
프로젝트 빌드에 포함 확인란이 선택되어 있는지 확인합니다. 이 옵션을 사용하면 프로젝트를 빌드하거나 업데이트할 때마다 jar이 생성됩니다. 적용을 선택한 다음, 확인을 선택합니다.
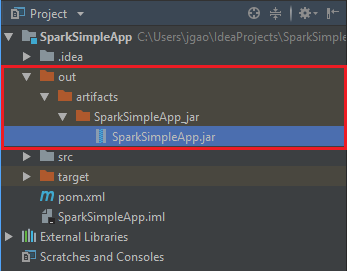
jar을 만들려면 빌드>빌드 아티팩트>빌드로 이동합니다. 프로젝트가 약 30초 후에 컴파일됩니다. \out\artifacts 아래에 출력 jar이 만들어집니다.
Apache Spark 클러스터에서 애플리케이션 실행
클러스터에서 애플리케이션을 실행하려면 다음 방법을 사용할 수 있습니다.
클러스터와 연결된 Azure Storage Blob에 애플리케이션 jar을 복사합니다. AzCopy 명령줄 유틸리티를 사용하면 이 작업을 수행할 수 있습니다. 데이터를 업로드하는 데 사용할 수 있는 다른 클라이언트도 많이 있습니다. HDInsight에서 Apache Hadoop 작업용 데이터 업로드에서 자세한 정보를 찾을 수 있습니다.
Apache Livy를 사용하여 애플리케이션 작업을 원격으로 Spark 클러스터에 제출합니다. HDInsight의 Spark 클러스터에는 Spark 작업을 원격으로 제출하는 REST 엔드포인트를 노출하는 Livy가 포함됩니다. 자세한 내용은 HDInsight의 Spark 클러스터와 함께 Apache Livy를 사용하여 원격으로 Apache Spark 작업 제출을 참조하세요.
리소스 정리
이 애플리케이션을 계속 사용할 계획이 없으면 다음 단계에 따라 생성된 클러스터를 삭제합니다.
Azure Portal에 로그인합니다.
맨 위에 있는 검색 상자에 HDInsight를 입력합니다.
서비스에서 HDInsight 클러스터를 선택합니다.
표시되는 HDInsight 클러스터 목록에서 이 자습서용으로 만든 클러스터 옆에 있는 ...를 선택합니다.
삭제를 선택합니다. 예를 선택합니다.
다음 단계
이 문서에서는 Apache Spark Scala 애플리케이션을 만드는 방법을 배웠습니다. 다음 문서를 진행하여 Livy를 사용하여 HDInsight Spark 클러스터에서 이 애플리케이션을 실행하는 방법에 대해 알아봅니다.