이 노트북에서는 HDInsight의 Apache Spark와 함께 사용자 지정 라이브러리를 사용하여 로그 데이터를 분석하는 방법을 보여줍니다. 사용하는 사용자 지정 라이브러리는 iislogparser.py라는 Python 라이브입니다.
필수 조건
HDInsight의 Apache Spark. 자세한 내용은 Azure HDInsight에서 Apache Spark 클러스터 만들기를 참조하세요.
RDD로 원시 데이터 저장
이 섹션에서는 HDInsight에서 Apache Spark 클러스터와 연결된 Jupyter Notebook을 사용하여 원시 샘플 데이터를 처리하고 Hive 테이블로 저장하는 작업을 실행합니다. 샘플 데이터는 기본적으로 모든 클러스터에서 사용 가능한 .csv 파일(hvac.csv)입니다.
데이터를 Apache Hive 테이블로 저장한 후에 다음 섹션에서 Power BI 및 Tableau와 같은 BI 도구를 사용하여 Hive 테이블에 연결합니다.
웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net/jupyter로 이동합니다. 여기서CLUSTERNAME은 클러스터의 이름입니다.새 Notebook을 만듭니다. 새로 만들기, PySpark를 차례로 선택합니다.
 Notebook" border="true":::
Notebook" border="true":::새 노트북이 만들어지고 Untitled.pynb 이름으로 열립니다. 맨 위에서 Notebook 이름을 선택하고 식별 이름을 입력합니다.
PySpark 커널을 사용하여 Notebook을 만들었기 때문에 컨텍스트를 명시적으로 만들 필요가 없습니다. 첫 번째 코드 셀을 실행하면 Spark 및 Hive 컨텍스트가 자동으로 만들어집니다. 이 시나리오에 필요한 형식을 가져와 시작할 수 있습니다. 빈 셀에 다음 코드 조각을 붙여넣은 다음, Shift+Enter를 누릅니다.
from pyspark.sql import Row from pyspark.sql.types import *클러스터에서 이미 사용할 수 있는 샘플 로그 데이터를 사용하는 RDD를 만듭니다.
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log에서 클러스터와 연결된 기본 스토리지 계정의 데이터에 액세스할 수 있습니다. 다음 코드를 실행합니다.logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')샘플 로그 설정을 검색하여 이전 단계가 성공적으로 완료되었는지 확인합니다.
logs.take(5)다음 텍스트와 유사한 출력이 표시됩니다.
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
사용자 지정 Python 라이브러리를 사용하여 로그 데이터 분석
위의 출력에서 처음 몇 줄은 헤더 정보를 포함하고 나머지 줄은 해당 헤더에 설명된 스키마와 일치합니다. 이러한 로그를 구문 분석하는 것은 복잡할 수 있습니다. 따라서 이러한 로그를 훨씬 쉽게 구문 분석하는 사용자 지정 Python 라이브러리(iislogparser.py)를 사용합니다. 기본적으로 이 라이브러리는
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py에 있는 HDInsight의 Spark 클러스터에 포함되어 있습니다.그러나 이 라이브러리는
PYTHONPATH에 있지 않으므로import iislogparser와 같은 import 문으로 사용할 수 없습니다. 이 라이브러리를 사용하려면 모든 작업자 노드에 배포해야 합니다. 다음 조각을 실행합니다.sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparser은(는) 로그 줄이 머리글 행인 경우 함수None을(를) 반환하고 로그 줄을 발견하는 경우LogLine클래스의 인스턴스를 반환하는 함수parse_log_line을(를) 제공합니다.LogLine클래스를 사용하여 RDD에서 로그 줄만을 추출합니다.def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()몇 가지 추출된 로그 줄을 검색하여 단계가 성공적으로 완료되었는지 확인합니다.
logLines.take(2)출력은 다음 텍스트와 유사하게 표시됩니다.
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]그러면
LogLine클래스에는 로그 항목에 오류 코드가 있는지 여부를 반환하는is_error()와(과) 같은 몇 가지 유용한 메서드가 있습니다. 이 클래스를 사용하여 추출된 로그 줄의 오류 수를 계산한 다음, 다른 파일에 모든 오류를 기록합니다.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')출력에
There are 30 errors and 646 log entries가 명시됩니다.Matplotlib 를 사용하여 데이터의 시각화를 만들 수도 있습니다. 예를 들어 오랜 시간 동안 실행되는 요청의 원인을 격리하려는 경우 평균적으로 제공하는 데 가장 많은 시간이 걸리는 파일을 찾을 수 있습니다. 다음 코드 조각은 요청을 처리하는 데 가장 많은 시간이 걸리는 상위 25개의 리소스를 검색합니다.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])다음 텍스트와 같은 출력이 표시됩니다.
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]그림의 형식에 이 정보를 제공할 수도 있습니다. 플롯을 만드는 첫 번째 단계로, 먼저 임시 테이블 AverageTime을 만듭니다. 이 테이블은 특정 시간에 특수한 대기 시간 급증 현상이 없는지 확인하도록 시간으로 로그를 그룹화합니다.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')다음 SQL 쿼리를 실행하여 AverageTime 테이블의 모든 레코드를 가져올 수 있습니다.
%%sql -o averagetime SELECT * FROM AverageTime-o averagetime앞의%%sql매직은 쿼리 출력이 Jupyter 서버(일반적으로 클러스터의 헤드 노드)에서 로컬로 유지되도록 합니다. 출력은 averagetime 이라는 이름이 지정된 Pandas데이터 프레임으로 유지됩니다.다음 이미지와 같은 출력이 표시됩니다.
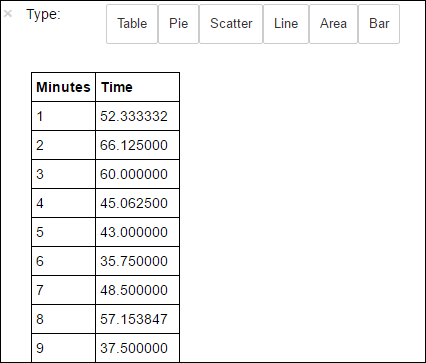 yter sql query output" border="true":::
yter sql query output" border="true":::%%sql매직에 대한 자세한 내용은 %%sql 매직에서 지원되는 매개 변수를 참조하세요.이제 데이터 시각화를 구성하는 데 사용되는 라이브러리인 Matplotlib를 사용하여 플롯을 만들 수 있습니다. 로컬로 유지되는 averagetime 데이터 프레임에서 플롯을 만들어야 하므로 코드 조각은
%%localmagic으로 시작해야 합니다. 그러면 코드가 Jupyter 서버에서 로컬로 실행됩니다.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')다음 이미지와 같은 출력이 표시됩니다.
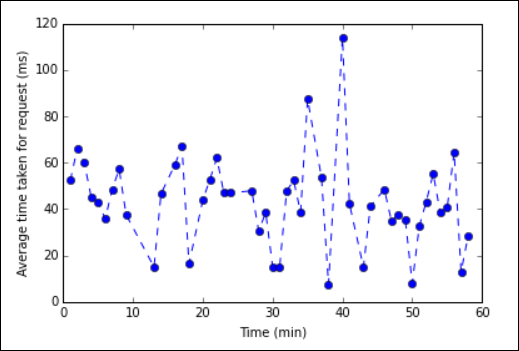 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::애플리케이션 실행을 완료한 후 리소스를 해제하도록 Notebook을 종료해야 합니다. 이렇게 하기 위해 Notebook의 파일 메뉴에서 닫기 및 중지를 선택합니다. 이 작업을 수행하면 Notebook이 종료되고 닫힙니다.
다음 단계
다음 문서를 살펴보세요.