HDInsight Spark 클러스터를 사용하여 Data Lake Storage Gen1의 데이터 분석
이 문서에서는 HDInsight Spark 클러스터와 함께 제공되는 Jupyter Notebook을 사용하여 Data Lake Storage 계정에서 데이터를 읽는 작업을 실행합니다.
필수 조건
Azure Data Lake Storage Gen1 계정. Azure Portal을 사용하여 Azure Data Lake Storage Gen1 시작에 있는 지침을 따릅니다.
Data Lake Storage Gen1을 스토리지로 사용하는 Azure HDInsight Spark 클러스터. 빠른 시작: HDInsight에서 클러스터 설정의 지침을 따르세요.
데이터 준비
참고 항목
기본 스토리지로 Data Lake Storage를 사용하여 HDInsight 클러스터를 만든 경우 이 단계를 수행할 필요가 없습니다. 클러스터 만들기 프로세스는 클러스터를 만드는 동안 지정된 Data Lake Storage 계정에 몇 가지 샘플 데이터를 추가합니다. Data Lake Storage에서 HDInsight Spark 클러스터 사용 섹션으로 건너뜁니다.
Data Lake Storage를 추가 스토리지로, Azure Storage Blob을 기본 스토리지로 사용하여 HDInsight 클러스터를 만든 경우 먼저 몇 가지 샘플 데이터를 Data Lake Storage 계정에 복사해야 합니다. HDInsight 클러스터와 연결된 Azure Storage Blob의 샘플 데이터를 사용할 수 있습니다.
명령 프롬프트를 열고 AdlCopy가 설치된 디렉터리로 이동합니다(일반적으로
%HOMEPATH%\Documents\adlcopy).다음 명령을 실행하여 원본 컨테이너에서 Data Lake Storage로 특정 Blob을 복사합니다.
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>/HdiSamples/HdiSamples/SensorSampleData/hvac/의 HVAC.csv 샘플 데이터 파일을 Azure Data Lake Storage 계정에 복사합니다. 코드 조각은 다음과 같습니다.
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==Warning
파일 및 경로 이름이 적절한 대문자 표시를 사용하는지 확인합니다.
Data Lake Storage 계정이 있는 Azure 구독에 대한 자격 증명을 입력하라는 메시지가 표시됩니다. 다음 코드 조각과 유사한 결과가 표시됩니다.
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.데이터 파일(HVAC.csv)은 Data Lake Storage 계정의 /hvac 폴더에 복사됩니다.
Data Lake Storage Gen1을 포함한 HDInsight Spark 클러스터 사용
Azure Portal의 시작 보드에서 Apache Spark 클러스터에 대한 타일을 클릭합니다(시작 보드에 고정한 경우). 모두 찾아보기>HDInsight 클러스터에서 클러스터로 이동할 수도 있습니다.
Spark 클러스터 블레이드에서 빠른 연결을 클릭한 다음 클러스터 대시보드 블레이드에서 Jupyter Notebook을 클릭합니다. 메시지가 표시되면 클러스터에 대한 관리자 자격 증명을 입력합니다.
참고 항목
또한 브라우저에서 다음 URL을 열어 클러스터에 대한 Jupyter Notebook에 접근할 수 있습니다. CLUSTERNAME 을 클러스터의 이름으로 바꿉니다.
https://CLUSTERNAME.azurehdinsight.net/jupyter새 Notebook을 만듭니다. 새로 만들기를 클릭한 다음 PySpark를 클릭합니다.
PySpark 커널을 사용하여 노트북을 만들었기 때문에 컨텍스트를 명시적으로 만들 필요가 없습니다. 첫 번째 코드 셀을 실행하면 Spark 및 Hive 컨텍스트가 자동으로 만들어집니다. 이 시나리오에 필요한 형식을 가져와 시작할 수 있습니다. 이렇게 하려면 셀에 다음 코드 조각을 붙여 넣고 SHIFT + ENTER를 누릅니다.
from pyspark.sql.types import *Jupyter에서 작업을 실행할 때마다, 웹 브라우저 창 제목에 Notebook 제목과 함께 (사용 중) 상태가 표시됩니다. 또한 오른쪽 위 모서리에 있는 PySpark 텍스트 옆에 단색 원이 표시됩니다. 작업이 완료되면 속이 빈 원으로 변경됩니다.

Data Lake Storage Gen1 계정에 복사한 HVAC.csv 파일을 사용하여 샘플 데이터를 임시 테이블에 로드합니다. 다음 URL 패턴을 사용하여 Data Lake Storage 계정의 데이터에 액세스할 수 있습니다.
Data Lake Storage Gen1을 기본 스토리지로 사용하는 경우 HVAC.csv는 다음 URL과 비슷한 경로에 있습니다.
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv또는 다음과 같이 축약된 형식을 사용할 수도 있습니다.
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvData Lake Storage를 추가 스토리지로 사용하는 경우 HVAC.csv는 다음과 같이 복사한 위치에 있습니다.
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>빈 셀에 다음 코드 예제를 붙여넣습니다. 이때 MYDATALAKESTORE를 Data Lake Storage 계정 이름으로 바꾸고 Shift+Enter를 누릅니다. 이 코드 예제는 hvac라는 임시 테이블에 데이터로 등록됩니다.
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
PySpark 커널을 사용하기 때문에 이제
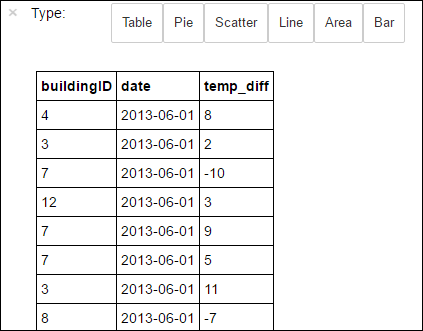
%%sql매직을 사용하여 방금 만든 임시 테이블 hvac에서 SQL 쿼리를 직접 실행할 수 있습니다.%%sql매직 및 PySpark 커널에서 사용 가능한 기타 매직에 대한 자세한 내용은 Apache Spark HDInsight 클러스터와 함께 Jupyter Notebook에서 사용 가능한 커널을 참조하세요.%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"작업이 성공적으로 완료되면 기본적으로 다음 테이블 형식의 출력이 표시됩니다.
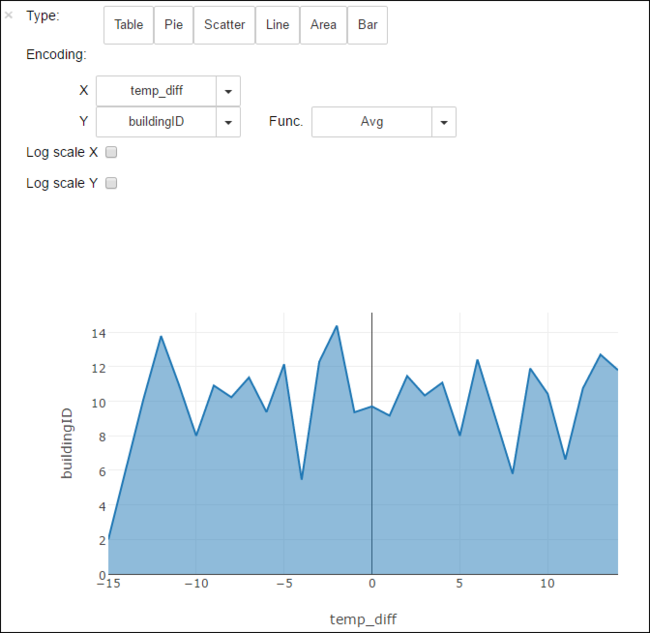
다른 시각화로 결과를 볼 수도 있습니다. 예를 들어 동일한 출력에 대한 영역 그래프는 다음과 같습니다.
애플리케이션 실행을 완료한 후 리소스를 해제하도록 노트북을 종료해야 합니다. 이렇게 하기 위해 Notebook의 파일 메뉴에서 닫기 및 중지를 클릭합니다. 그러면 Notebook이 종료되고 닫힙니다.