HDInsight Spark 클러스터에는 Apache Zeppelin Notebook이 포함되어 있습니다. 해당 Notebook을 사용하여 Apache Spark 작업을 실행합니다. 이 문서에서는 HDInsight 클러스터에서 Zeppelin Notebook을 사용하는 방법에 대해 알아 봅니다.
필수 조건
- HDInsight의 Apache Spark. 자세한 내용은 Azure HDInsight에서 Apache Spark 클러스터 만들기를 참조하세요.
- 클러스터 기본 스토리지에 대한 URI 체계입니다. 이 체계는
wasb://Azure Blob Storage,abfs://Azure Data Lake Storage Gen2 또는adl://Azure Data Lake Storage Gen1에 적용될 수 있습니다. Blob Storage에 대해 보안 전송이 사용 설정된 경우 URI는wasbs://입니다. 자세한 내용은 Azure Storage에서 보안 전송 필요를 참조하십시오.
Apache Zeppelin Notebook 시작
Spark 클러스터 개요에서 클러스터 대시보드의 Zeppelin Notebook을 선택합니다. 클러스터에 대한 관리자 자격 증명을 입력합니다.
참고 항목
또한 브라우저에서 다음 URL을 열어 클러스터에 대한 Zeppelin Notebook에 도달할 수 있습니다. CLUSTERNAME 을 클러스터의 이름으로 바꿉니다.
https://CLUSTERNAME.azurehdinsight.net/zeppelin새 Notebook을 만듭니다. 헤더 창에서 Notebook>새 참고 만들기로 이동합니다.
노트북의 이름을 입력한 다음 참고 만들기를 선택합니다.
노트북 헤더에 연결된 상태가 표시되는지 확인합니다. 오른쪽 상단 모서리에 녹색 점으로 표시됩니다.
샘플 데이터를 임시 테이블에 로드합니다. HDInsight에서 Spark 클러스터를 만들면 샘플 데이터 파일인
hvac.csv가\HdiSamples\SensorSampleData\hvac아래의 연결된 스토리지 계정에 복사됩니다.새 노트북에 기본적으로 만들어지는 빈 단락에 다음 코드 조각을 붙여넣습니다.
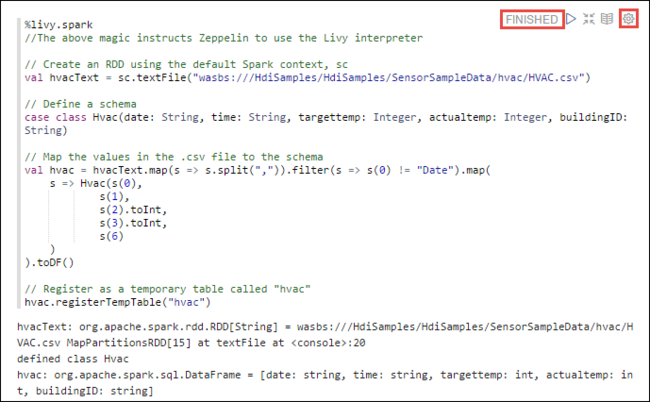
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")SHIFT + ENTER를 누르거나 단락에 대한 재생 단추를 선택하여 코드 조각을 실행합니다. 단락의 오른쪽 모서리 상태가 준비, 보류 중, 실행 중, 완료 순서로 진행됩니다. 출력은 같은 단락 하단에 표시됩니다. 스크린샷은 다음 이미지와 같습니다.
또한 각 단락에 제목을 제공할 수도 있습니다. 단락의 오른쪽 모서리에서 설정 아이콘(sprocket)을 선택한 다음 제목 표시를 선택합니다.
참고 항목
%spark2 인터프리터는 모든 HDInsight 버전에서 Zeppelin Notebook에서 지원되지 않으며, %sh 인터프리터는 HDInsight 4.0 이상에서 지원되지 않습니다.
이제
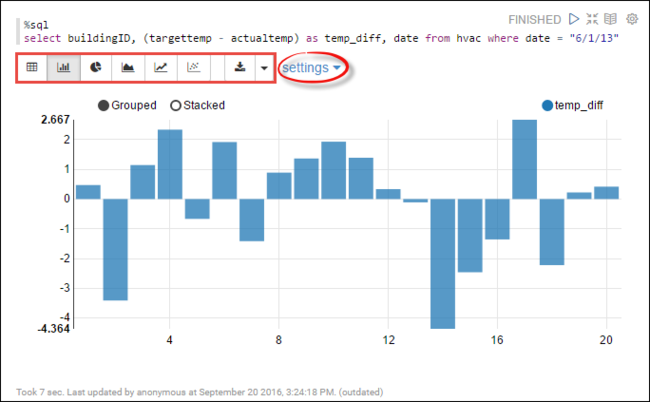
hvac테이블에서 Spark SQL 문을 실행할 수 있습니다. 새 단락에 다음 쿼리를 붙여넣습니다. 쿼리가 빌딩 ID를 검색합니다. 지정된 날짜의 각 빌딩의 대상 온도와 실제 온도 차이도 검색합니다. Shift + Enter를 누릅니다.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"%sql 문의 처음 부분은 Notebook에 Livy Scala 인터프리터를 사용하도록 지시합니다.
막대형 차트 아이콘을 선택하면 표시 내용을 변경할 수 있습니다. 설정은 가로 막대형 차트를 선택한 후 표시되며, 키 및 값을 선택할 수 있습니다. 다음 스크린샷은 출력을 보여 줍니다.
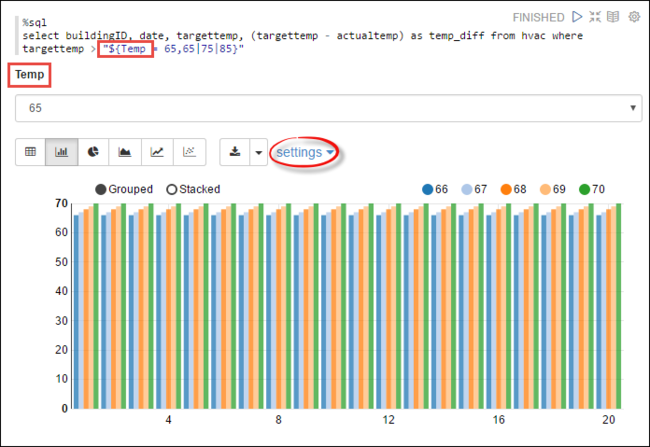
또한 쿼리에 변수를 사용하여 Spark SQL 문을 실행할 수도 있습니다. 다음 코드 조각은 쿼리할 수 있는 값이 포함된 쿼리에 변수
Temp를 정의하는 방법을 보여 줍니다. 쿼리를 처음 실행하면 드롭다운이 변수에 지정한 값으로 자동으로 채워집니다.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"새 단락에 이 코드 조각을 붙여넣고 Shift + Enter를 누릅니다. 그런 다음, Temp 드롭다운 목록에서 65를 선택합니다.
막대형 차트 아이콘을 선택하면 표시 내용을 변경할 수 있습니다. 그런 다음 설정을 선택하고 다음과 같이 변경합니다.
그룹:targettemp를 추가합니다.
값: 1. 날짜를 제거합니다. 2. temp_diff를 추가합니다. 3. 집계를 SUM에서 AVG로 변경합니다.
다음 스크린샷은 출력을 보여 줍니다.
Notebook에서 외부 패키지 사용 방법
HDInsight의 Apache Spark 클러스터에 있는 Zeppelin Notebook은 클러스터에 포함되지 않는 외부의 커뮤니티 제공 패키지를 사용할 수 있습니다. 사용할 수 있는 패키지의 전체 목록은 Maven 리포지토리를 검색해 확인할 수 있습니다. 다른 소스에서 사용 가능한 패키지 목록을 가져올 수도 있습니다. 예를 들어 커뮤니티 제공 패키지의 전체 목록은 Spark 패키지에서 사용할 수 있습니다.
이 문서에서는 Jupyter Notebook에서 spark-csv 패키지를 사용하는 방법을 알아보세요.
인터프리터 설정을 엽니다. 오른쪽 상단 모서리에서 로그인한 사용자 이름을 선택한 다음 인터프리터를 선택합니다.
livy2로 스크롤한 다음 편집을 선택합니다.
키
livy.spark.jars.packages로 이동하여 해당 값을 형식group:id:version로 설정합니다. 따라서 spark-csv 패키지를 사용하려면 키 값을com.databricks:spark-csv_2.10:1.4.0으로 설정해야 합니다.
저장을 선택한 다음 확인을 선택하여 Livy 인터프리터를 다시 시작합니다.
입력한 키의 값에 도착하는 방법을 이해하려면 방법은 다음과 같습니다.
a. Maven Repository에서 패키지를 찾습니다. 이 문서에서는 spark-csv를 사용했습니다.
b. 해당 리포지토리에서 GroupId, ArtifactId 및 Version 값을 수집합니다.
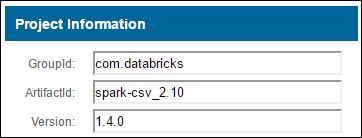
c. 콜론(:)으로 구분된 세 개의 값을 연결합니다.
com.databricks:spark-csv_2.10:1.4.0
Zeppelin Notebook 저장 위치
클러스터 헤드 노드에 저장된 Zeppelin Notebook입니다. 따라서 클러스터를 삭제하면 Notebook도 삭제됩니다. 나중에 다른 클러스터에서 사용할 수 있도록 Notebook을 유지하려면 작업 실행을 완료한 후 내보내야 합니다. 전자 필기장을 내보내려면 다음과 같이 이미지에 표시된 대로 내보내기 아이콘을 선택합니다.
이렇게 하면 Notebook이 다운로드 위치에 JSON 파일로 저장됩니다.
참고 항목
HDI 4.0에서 zeppelin Notebook 디렉터리 경로는
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/입니다.예: /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
반면 HDI 5.0에서는 이 경로가 다릅니다.
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/예: /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
HDI 5.0에서는 저장되는 파일 이름이 다릅니다. 다음으로 저장됩니다.
<notebook_name>_<sessionid>.zpln예: testzeppelin_2JJK53XQA.zpln
HDI 4.0에서 파일 이름은 session_id 디렉터리에 저장된 note.json입니다.
예: /2JMC9BZ8X/note.json
HDI Zeppelin은 항상 hn0 로컬 디스크의
/usr/hdp/<version>/zeppelin/notebook/경로에 Notebook을 저장합니다.클러스터 삭제 후에도 Notebook을 사용할 수 있도록 하려면 Azure 파일 스토리지(SMB 프로토콜 사용)를 사용하여 로컬 경로에 연결할 수 있습니다. 자세한 내용은 Linux에서 SMB Azure 파일 공유 탑재를 참조 하세요.
탑재한 후 zeppelin 구성 zeppelin.notebook.dir을 Ambari UI의 탑재된 경로로 수정할 수 있습니다.
- GitNotebookRepo 스토리지로서의 SMB 파일 공유는 zeppelin 버전 0.10.1에는 권장되지 않습니다.
Shiro를 사용하여 ESP(Enterprise Security Package) 클러스터에서 Zeppelin 인터프리터에 대한 액세스 구성
위에서 설명한 것처럼 %sh 인터프리터는 HDInsight 4.0 이상에서 지원되지 않습니다. 또한 %sh 인터프리터는 셸 명령을 통한 keytab 액세스와 같은 잠재적인 보안 문제를 도입하기 때문에 HDInsight 3.6 ESP 클러스터에서도 제거되었습니다. 즉, %sh 인터프리터는 새 참고 만들기를 클릭해도 사용할 수 없고 인터프리터 UI에도 기본적으로 존재하지 않습니다.
권한을 가진 도메인 사용자는 Shiro.ini 파일을 사용하여 인터프리터 UI에 대한 액세스를 제어할 수 있습니다. 권한을 가진 도메인 사용자만 새 %sh 인터프리터를 만들고 각각의 새 %sh 인터프리터에 대한 사용 권한을 설정할 수 있습니다.
shiro.ini 파일을 사용하여 액세스를 제어하는 방법은 다음과 같습니다.
기존 도메인 그룹 이름을 사용하여 새 역할을 정의합니다. 다음 예제
adminGroupName에서는 Microsoft Entra ID의 권한 있는 사용자 그룹입니다. 그룹 이름에 특수 문자나 공백을 사용하지 마십시오.=뒤의 문자는 이 역할에 대한 사용 권한을 부여합니다.*은 그룹에 모든 권한이 있음을 의미합니다.[roles] adminGroupName = *Zeppelin 인터프리터 액세스를 위한 새 역할을 추가합니다. 다음 예제에서는
adminGroupName의 모든 사용자가 Zeppelin 인터프리터에 대한 액세스 권한을 부여받고 새 인터프리터를 만들 수 있습니다.roles[]의 형태로 대괄호 사이에 여러 역할을 넣고 쉼표로 구분할 수 있습니다. 그런 다음 필요한 권한이 있는 사용자는 Zeppelin 인터프리터에 액세스할 수 있습니다.[urls] /api/interpreter/** = authc, roles[adminGroupName]
여러 도메인 그룹에 대한 예제 shiro.ini:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy 세션 관리
Zeppelin Notebook의 첫 번째 코드 단락으로 클러스터에 새 Livy 세션이 생성됩니다. 이 세션은 이후에 만드는 모든 Zeppelin Notebook에서 공유됩니다. 어떤 이유로든 Livy 세션이 종료되면 Zeppelin 노트북에서는 작업이 실행되지 않습니다.
이 경우 Zeppelin Notebook에서 작업 실행을 시작하기 전에 다음 단계를 수행해야 합니다.
Zeppelin Notebook에서 Livy 인터프리터를 다시 시작합니다. 그러려면 오른쪽 상단 모서리의 로그인한 사용자 이름을 선택하여 인터프리터 설정을 연 다음 인터프리터를 선택합니다.
livy2로 스크롤한 다음 다시 시작을 선택합니다.
기존 Zeppelin Notebook에서 코드 셀을 실행합니다. 이 코드로 HDInsight 클러스터에 새로운 Livy 세션이 생성됩니다.
일반 정보
서비스 유효성 검사
Ambari에서 서비스의 유효성을 검사하려면 https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary로 이동합니다. 여기서 CLUSTERNAME은 클러스터의 이름입니다.
명령줄에서 서비스의 유효성을 검사하려면 헤드 노드로 SSH를 수행합니다. 명령 sudo su zeppelin을 사용하여 사용자를 zeppelin으로 전환합니다. 상태 명령:
| 명령 | 설명 |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
서비스 상태. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
서비스 버전. |
ps -aux | grep zeppelin |
PID를 식별합니다. |
로그 위치
| 서비스 | Path |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| 서버 로그 | /var/log/zeppelin |
구성 해석기, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf 또는/etc/zeppelin/conf |
| PID 디렉터리 | /var/run/zeppelin |
디버그 로깅 활성화
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary으로 이동합니다. 여기서 CLUSTERNAME은 클러스터의 이름입니다.CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content로 이동합니다.
log4j.appender.dailyfile.Threshold = INFO을log4j.appender.dailyfile.Threshold = DEBUG로 수정합니다.log4j.logger.org.apache.zeppelin.realm=DEBUG를 추가합니다.변경 내용을 저장하고 서비스를 다시 시작합니다.