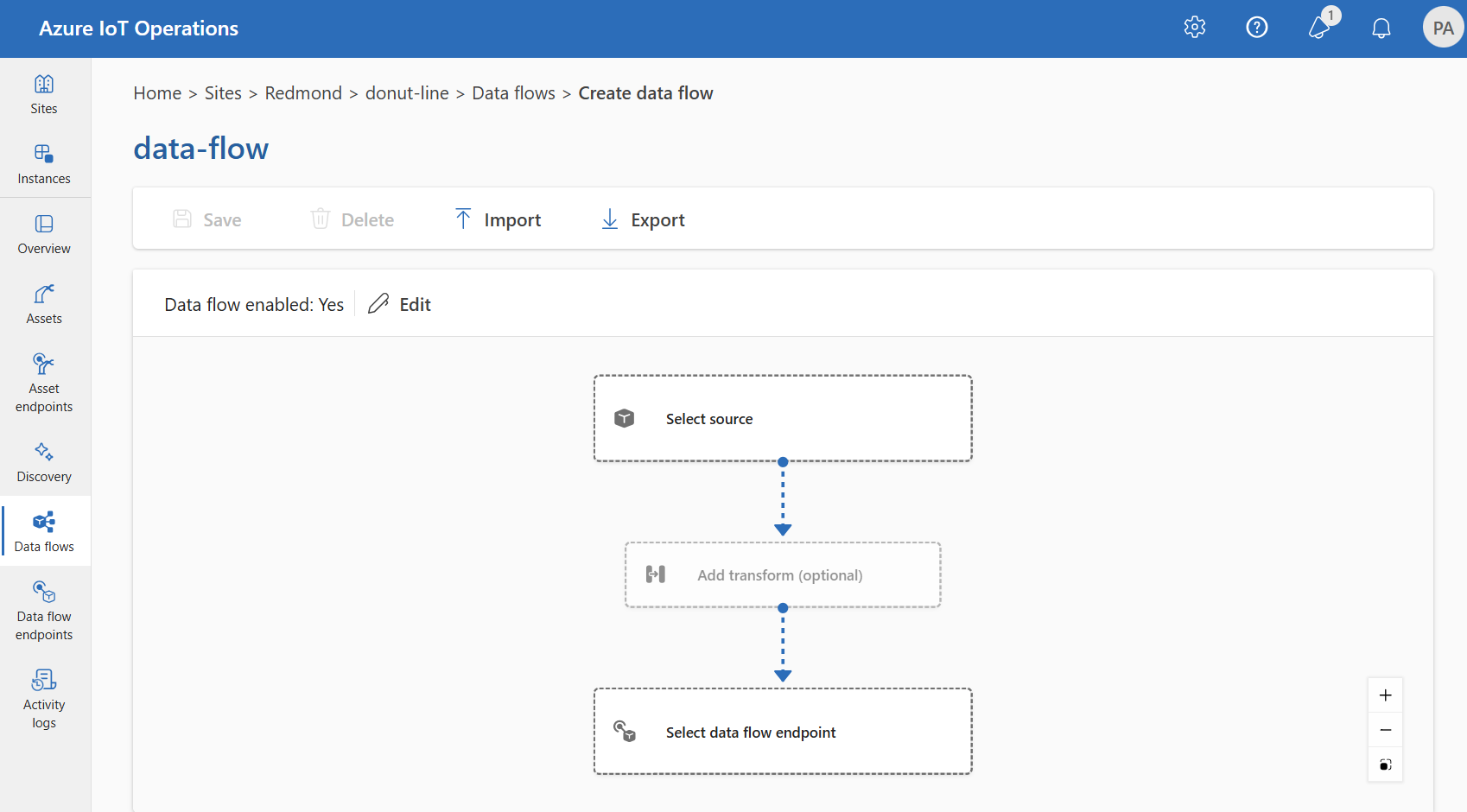
데이터 흐름은 선택적 변환을 통해 데이터가 원본에서 대상까지 이동하는 경로입니다. 데이터 흐름 사용자 지정 리소스를 만들거나 Azure IoT Operations Studio 포털을 사용하여 데이터 흐름을 구성할 수 있습니다. 데이터 흐름은 원본, 변환 및 대상의 세 부분으로 구성됩니다.
원본 및 대상을 정의하려면 데이터 흐름 엔드포인트를 구성해야 합니다. 변환은 선택 사항이며 데이터 보강, 데이터 필터링 및 데이터를 다른 필드에 매핑하는 등의 작업을 포함할 수 있습니다.
Azure IoT Operations의 작업 환경을 사용하여 데이터 흐름을 만들 수 있습니다. 작업 환경은 데이터 흐름을 구성하는 시각적 인터페이스를 제공합니다. Bicep을 사용하여 Bicep 템플릿 파일을 사용하여 데이터 흐름을 만들거나 Kubernetes를 사용하여 YAML 파일을 사용하여 데이터 흐름을 만들 수도 있습니다.
원본, 변환 및 대상을 구성하는 방법을 알아보려면 계속 읽어보세요.
필수 조건
기본 데이터 흐름 프로필 및 엔드포인트를 사용하여 Azure IoT Operations Preview 인스턴스가 있는 즉시 데이터 흐름을 배포할 수 있습니다. 그러나 데이터 흐름을 사용자 지정하도록 데이터 흐름 프로필 및 엔드포인트를 구성할 수 있습니다.
데이터 흐름 프로필
데이터 흐름 프로필은 사용할 데이터 흐름의 인스턴스 수를 지정합니다. 크기 조정 설정이 다른 여러 데이터 흐름 그룹이 필요하지 않은 경우 기본 데이터 흐름 프로필을 사용할 수 있습니다. 데이터 흐름 프로필을 구성하는 방법을 알아보려면 데이터 흐름 프로필 구성을 참조 하세요.
데이터 흐름 엔드포인트
데이터 흐름의 원본 및 대상을 구성하려면 데이터 흐름 엔드포인트가 필요합니다. 빠르게 시작하려면 로컬 MQTT broker에 대한 기본 데이터 흐름 엔드포인트를 사용할 수 있습니다. Kafka, Event Hubs 또는 Azure Data Lake Storage와 같은 다른 유형의 데이터 흐름 엔드포인트를 만들 수도 있습니다. 각 유형의 데이터 흐름 엔드포인트를 구성하는 방법을 알아보려면 데이터 흐름 엔드포인트 구성을 참조 하세요.
Kubernetes 매니페스트 .yaml 파일을 만들어 데이터 흐름 만들기를 시작합니다. 이 예제에서는 원본, 변환 및 대상 구성을 포함하는 데이터 흐름의 구조를 보여 줍니다.
apiVersion: connectivity.iotoperations.azure.com/v1beta1
kind: Dataflow
metadata:
name: <DATAFLOW_NAME>
namespace: azure-iot-operations
spec:
# Reference to the default dataflow profile
# This field is required when configuring via Kubernetes YAML
# The syntax is different when using Bicep
profileRef: default
mode: Enabled
operations:
- operationType: Source
sourceSettings:
# See source configuration section
# Transformation optional
- operationType: BuiltInTransformation
builtInTransformationSettings:
# See transformation configuration section
- operationType: Destination
destinationSettings:
# See destination configuration section
다음 섹션을 검토하여 데이터 흐름의 작업 유형을 구성하는 방법을 알아봅니다.
Source
데이터 흐름에 대한 원본을 구성하려면 엔드포인트 참조 및 엔드포인트에 대한 데이터 원본 목록을 지정합니다.
여기서는 dataSources 엔드포인트 구성을 수정할 필요 없이 여러 MQTT 또는 Kafka 토픽을 지정할 수 있습니다. 이러한 유연성은 토픽이 달라도 여러 데이터 흐름에서 동일한 엔드포인트를 다시 사용할 수 있습니다. 자세한 내용은 데이터 원본 구성을 참조 하세요.
예를 들어 MQTT 엔드포인트와 두 개의 MQTT 토픽 필터를 사용하여 원본을 구성하려면 다음 구성을 사용합니다.
엔드포인트 구성을 수정하지 않고 MQTT 또는 Kafka 토픽을 지정할 수 있으므로 dataSources 토픽이 다르더라도 여러 데이터 흐름에 엔드포인트를 다시 사용할 수 있습니다. 자세한 내용은 데이터 원본 구성을 참조 하세요.
기본 엔드포인트가 원본으로 사용되지 않는 경우 대상으로 사용해야 합니다. 자세한 내용은 데이터 흐름이 로컬 MQTT broker 엔드포인트를 사용해야 하므로 참조하세요.
사용자 지정 MQTT 또는 Kafka 데이터 흐름 엔드포인트를 원본으로 사용
사용자 지정 MQTT 또는 Kafka 데이터 흐름 엔드포인트를 만든 경우(예: Event Grid 또는 Event Hubs와 함께 사용) 데이터 흐름의 원본으로 사용할 수 있습니다. Data Lake 또는 Fabric OneLake와 같은 스토리지 유형 엔드포인트는 원본으로 사용할 수 없습니다.
구성하려면 Kubernetes YAML 또는 Bicep을 사용합니다. 자리 표시자 값을 사용자 지정 엔드포인트 이름 및 토픽으로 바꿉니다.
사용자 지정 MQTT 또는 Kafka 엔드포인트를 원본으로 사용하는 것은 현재 작업 환경에서 지원되지 않습니다.
sourceSettings: {
endpointRef: '<CUSTOM_ENDPOINT_NAME>'
dataSources: [
'<TOPIC_1>'
'<TOPIC_2>'
// See section on configuring MQTT or Kafka topics for more information
]
}
sourceSettings:
endpointRef: <CUSTOM_ENDPOINT_NAME>
dataSources:
- <TOPIC_1>
- <TOPIC_2>
# See section on configuring MQTT or Kafka topics for more information
데이터 원본 구성(MQTT 또는 Kafka 항목)
데이터 흐름 엔드포인트 구성을 수정할 필요 없이 원본에서 여러 MQTT 또는 Kafka 토픽을 지정할 수 있습니다. 이러한 유연성은 토픽이 달라도 여러 데이터 흐름에서 동일한 엔드포인트를 다시 사용할 수 있습니다. 자세한 내용은 데이터 흐름 엔드포인트 재사용을 참조하세요.
MQTT 항목
원본이 MQTT(Event Grid 포함) 엔드포인트인 경우 MQTT 토픽 필터를 사용하여 들어오는 메시지를 구독할 수 있습니다. 토픽 필터에는 여러 항목을 구독하는 와일드카드가 포함될 수 있습니다. 예를 들어 자동 thermostats/+/telemetry/temperature/# 온도 조절기의 모든 온도 원격 분석 메시지를 구독합니다. MQTT 토픽 필터를 구성하려면 다음을 수행합니다.
데이터 흐름 프로필의 인스턴스 수가 1보다 크면 MQTT 원본을 사용하는 모든 데이터 흐름에 대해 공유 구독이 자동으로 사용하도록 설정됩니다. 이 경우 $shared 접두사를 추가하고 공유 구독 그룹 이름이 자동으로 생성됩니다. 예를 들어 인스턴스 수가 3인 데이터 흐름 프로필이 있고 데이터 흐름이 토픽 topic1topic2으로 구성된 원본으로 MQTT 엔드포인트를 사용하고 공유 구독 $shared/<GENERATED_GROUP_NAME>/topic1$shared/<GENERATED_GROUP_NAME>/topic2으로 자동 변환되는 경우 다른 공유 구독 그룹 ID를 사용하려는 경우 토픽에서 재정의할 수 있습니다(예: $shared/mygroup/topic1.).
Important
인스턴스 수가 1보다 클 때 공유 구독이 필요한 데이터 흐름은 공유 구독을 지원하지 않으므로 Event Grid MQTT broker를 원본 으로 사용할 때 중요합니다. 메시지 누락을 방지하려면 Event Grid MQTT broker를 원본으로 사용할 때 데이터 흐름 프로필 인스턴스 수를 1로 설정합니다. 데이터 흐름이 구독자이고 클라우드에서 메시지를 수신하는 경우입니다.
Kafka 토픽
원본이 Kafka(Event Hubs 포함) 엔드포인트인 경우 들어오는 메시지에 대해 구독할 개별 kafka 토픽을 지정합니다. 와일드카드는 지원되지 않으므로 각 토픽을 정적으로 지정해야 합니다.
참고 항목
Kafka 엔드포인트를 통해 Event Hubs를 사용하는 경우 네임스페이스 내의 각 개별 이벤트 허브는 Kafka 토픽입니다. 예를 들어 두 개의 이벤트 허브가 있는 Event Hubs 네임스페이스가 thermostats 있는 humidifiers경우 각 이벤트 허브를 Kafka 토픽으로 지정할 수 있습니다.
sourceSettings: {
endpointRef: '<KAFKA_ENDPOINT_NAME>'
dataSources: [
'<KAFKA_TOPIC_1>'
'<KAFKA_TOPIC_2>'
// Add more Kafka topics as needed
]
}
sourceSettings:
endpointRef: <KAFKA_ENDPOINT_NAME>
dataSources:
- <KAFKA_TOPIC_1>
- <KAFKA_TOPIC_2>
# Add more Kafka topics as needed
데이터를 역직렬화하는 스키마 지정
원본 데이터에 다른 형식의 선택적 필드 또는 필드가 있는 경우 일관성을 보장하기 위해 역직렬화 스키마를 지정합니다. 예를 들어 데이터에는 모든 메시지에 없는 필드가 있을 수 있습니다. 스키마가 없으면 빈 값이 있으므로 변환에서 이러한 필드를 처리할 수 없습니다. 스키마를 사용하여 기본값을 지정하거나 필드를 무시할 수 있습니다.
스키마 지정은 MQTT 또는 Kafka 원본을 사용하는 경우에만 관련이 있습니다. 원본이 자산인 경우 스키마는 자산 정의에서 자동으로 유추됩니다.
원본에서 들어오는 메시지를 역직렬화하는 데 사용되는 스키마를 구성하려면 다음을 수행합니다.
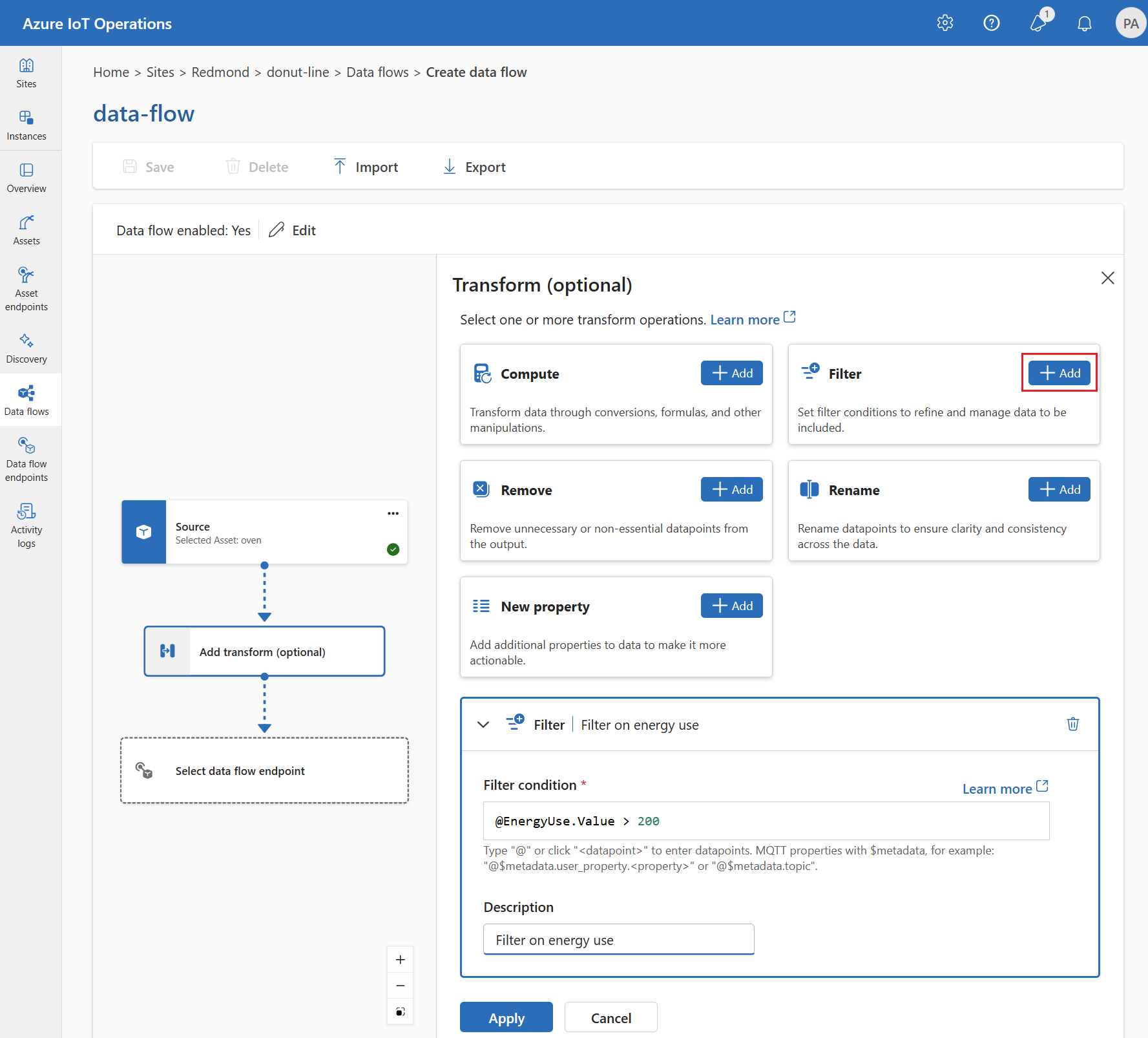
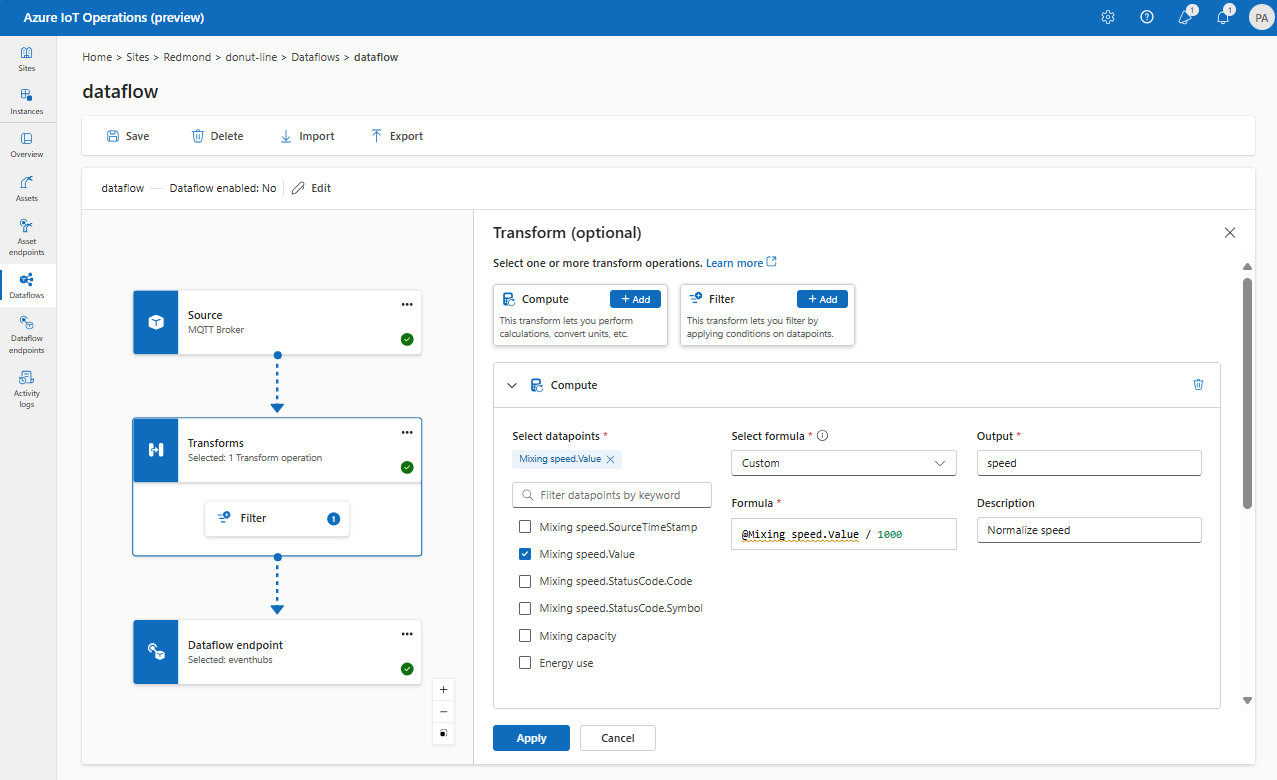
변환 작업은 데이터를 대상으로 보내기 전에 원본에서 데이터를 변환할 수 있는 위치입니다. 변환은 선택 사항입니다. 데이터를 변경할 필요가 없으면 데이터 흐름 구성에 변환 작업을 포함하지 마세요. 여러 변환은 구성에 지정된 순서에 관계없이 여러 변환이 단계별로 연결됩니다. 단계의 순서는 항상 다음과 같습니다.
새 속성 보강, 이름 바꾸기 또는 추가: 일치시킬 데이터 세트 및 조건이 지정된 경우 원본 데이터에 추가 데이터를 추가합니다.
builtInTransformationSettings: {
datasets: [
// See section on enriching data
]
filter: [
// See section on filtering data
]
map: [
// See section on mapping data
]
}
builtInTransformationSettings:
datasets:
# See section on enriching data
filter:
# See section on filtering data
map:
# See section on mapping data
보강: 참조 데이터 추가
데이터를 보강하려면 Azure IoT Operations DSS(분산 상태 저장소)에서 참조 데이터 세트를 사용할 수 있습니다. 데이터 세트는 조건에 따라 원본 데이터에 추가 데이터를 추가하는 데 사용됩니다. 조건은 데이터 세트의 필드와 일치하는 원본 데이터의 필드로 지정됩니다.
DSS 집합 도구 샘플을 사용하여 샘플 데이터를 DSS에 로드할 수 있습니다. 분산 상태 저장소의 키 이름은 데이터 흐름 구성의 데이터 세트에 해당합니다.
데이터를 대상으로 보내기 전에 직렬화하려면 스키마 및 serialization 형식을 지정해야 합니다. 그렇지 않으면 데이터가 유추된 형식을 사용하여 JSON으로 직렬화됩니다. Microsoft Fabric 또는 Azure Data Lake와 같은 스토리지 엔드포인트에는 데이터 일관성을 보장하기 위한 스키마가 필요합니다. 지원되는 serialization 형식은 Parquet 및 Delta입니다.
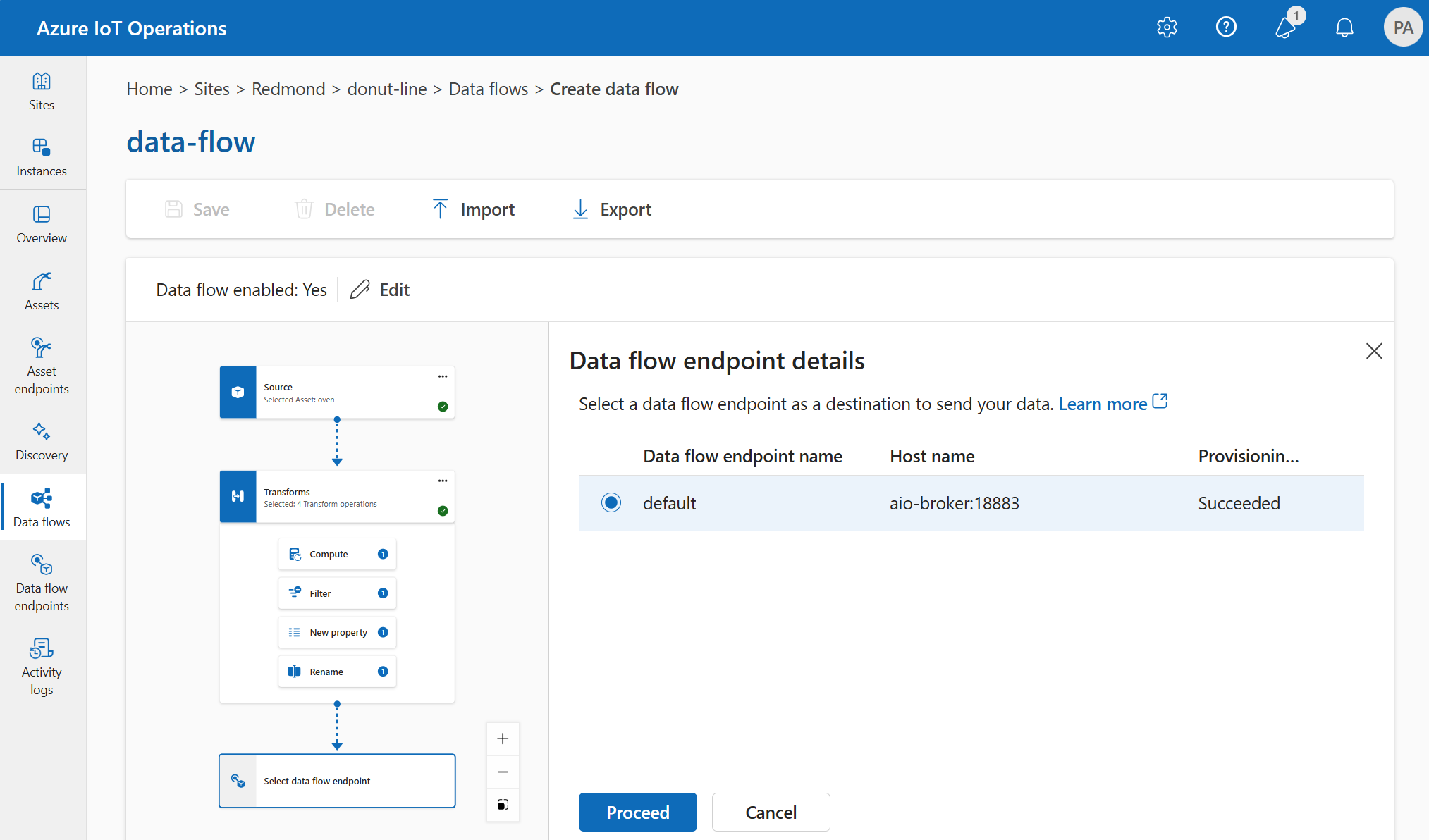
데이터 흐름의 대상을 구성하려면 엔드포인트 참조 및 데이터 대상을 지정합니다. 엔드포인트에 대한 데이터 대상 목록을 지정할 수 있습니다.
로컬 MQTT broker 이외의 대상으로 데이터를 보내려면 데이터 흐름 엔드포인트를 만듭니다. 방법을 알아보려면 데이터 흐름 엔드포인트 구성을 참조 하세요. 대상이 로컬 MQTT broker가 아닌 경우 원본으로 사용해야 합니다. 자세한 내용은 데이터 흐름이 로컬 MQTT broker 엔드포인트를 사용해야 하므로 참조하세요.
Important
스토리지 엔드포인트에는 스키마 참조가 필요합니다. Microsoft Fabric OneLake, ADLS Gen 2, Azure Data Explorer 및 Local Storage에 대한 스토리지 대상 엔드포인트를 만든 경우 스키마 참조를 지정해야 합니다.
데이터를 보낼 토픽 또는 테이블을 포함하여 대상에 필요한 설정을 입력합니다. 자세한 내용은 데이터 대상 구성(토픽, 컨테이너 또는 테이블)을 참조하세요.
destinationSettings: {
endpointRef: '<CUSTOM_ENDPOINT_NAME>'
dataDestination: '<TOPIC_OR_TABLE>' // See section on configuring data destination
}
destinationSettings:
endpointRef: <CUSTOM_ENDPOINT_NAME>
dataDestination: <TOPIC_OR_TABLE> # See section on configuring data destination
데이터 대상 구성(토픽, 컨테이너 또는 테이블)
데이터 원본과 마찬가지로 데이터 대상은 여러 데이터 흐름에서 데이터 흐름 엔드포인트를 재사용 가능한 상태로 유지하는 데 사용되는 개념입니다. 기본적으로 데이터 흐름 엔드포인트 구성의 하위 디렉터리를 나타냅니다. 예를 들어 데이터 흐름 엔드포인트가 스토리지 엔드포인트인 경우 데이터 대상은 스토리지 계정의 테이블입니다. 데이터 흐름 엔드포인트가 Kafka 엔드포인트인 경우 데이터 대상은 Kafka 토픽입니다.
엔드포인트 유형
데이터 대상 의미
설명
MQTT(또는 Event Grid)
항목
데이터가 전송되는 MQTT 항목입니다. 정적 토픽만 지원되며 와일드카드는 지원되지 않습니다.
Kafka(또는 Event Hubs)
항목
데이터가 전송되는 Kafka 토픽입니다. 정적 토픽만 지원되며 와일드카드는 지원되지 않습니다. 엔드포인트가 Event Hubs 네임스페이스인 경우 데이터 대상은 네임스페이스 내의 개별 이벤트 허브입니다.
작업 환경을 사용하는 경우 데이터 대상 필드는 엔드포인트 유형에 따라 자동으로 해석됩니다. 예를 들어 데이터 흐름 엔드포인트가 스토리지 엔드포인트인 경우 대상 세부 정보 페이지에서 컨테이너 이름을 입력하라는 메시지를 표시합니다. 데이터 흐름 엔드포인트가 MQTT 엔드포인트인 경우 대상 세부 정보 페이지에서 토픽을 입력하라는 메시지를 표시합니다.
다음 예제는 원본 및 대상에 MQTT 엔드포인트를 사용하는 데이터 흐름 구성입니다. 원본은 MQTT 토픽에서 데이터를 필터링합니다 azure-iot-operations/data/thermostat. 변환은 온도를 화씨로 변환하고 습도를 곱한 온도가 1000000 미만인 데이터를 필터링합니다. 대상은 MQTT 토픽 factory으로 데이터를 보냅니다.
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
param dataflowName string = '<DATAFLOW_NAME>'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-09-15-preview' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
// Pointer to the default dataflow endpoint
resource defaultDataflowEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-09-15-preview' existing = {
parent: aioInstance
name: 'default'
}
// Pointer to the default dataflow profile
resource defaultDataflowProfile 'Microsoft.IoTOperations/instances/dataflowProfiles@2024-09-15-preview' existing = {
parent: aioInstance
name: 'default'
}
resource dataflow 'Microsoft.IoTOperations/instances/dataflowProfiles/dataflows@2024-09-15-preview' = {
// Reference to the parent dataflow profile, the default profile in this case
// Same usage as profileRef in Kubernetes YAML
parent: defaultDataflowProfile
name: dataflowName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
mode: 'Enabled'
operations: [
{
operationType: 'Source'
sourceSettings: {
// Use the default MQTT endpoint as the source
endpointRef: defaultDataflowEndpoint.name
// Filter the data from the MQTT topic azure-iot-operations/data/thermostat
dataSources: [
'azure-iot-operations/data/thermostat'
]
}
}
// Transformation optional
{
operationType: 'BuiltInTransformation'
builtInTransformationSettings: {
// Filter the data where temperature * "Tag 10" < 100000
filter: [
{
inputs: [
'temperature.Value'
'"Tag 10".Value'
]
expression: '$1 * $2 < 100000'
}
]
map: [
// Passthrough all values by default
{
inputs: [
'*'
]
output: '*'
}
// Convert temperature to Fahrenheit and output it to TemperatureF
{
inputs: [
'temperature.Value'
]
output: 'TemperatureF'
expression: 'cToF($1)'
}
// Extract the "Tag 10" value and output it to Humidity
{
inputs: [
'"Tag 10".Value'
]
output: 'Humidity'
}
]
}
}
{
operationType: 'Destination'
destinationSettings: {
// Use the default MQTT endpoint as the destination
endpointRef: defaultDataflowEndpoint.name
// Send the data to the MQTT topic factory
dataDestination: 'factory'
}
}
]
}
}
apiVersion: connectivity.iotoperations.azure.com/v1beta1
kind: Dataflow
metadata:
name: my-dataflow
namespace: azure-iot-operations
spec:
# Reference to the default dataflow profile
profileRef: default
mode: Enabled
operations:
- operationType: Source
sourceSettings:
# Use the default MQTT endpoint as the source
endpointRef: default
# Filter the data from the MQTT topic azure-iot-operations/data/thermostat
dataSources:
- azure-iot-operations/data/thermostat
# Transformation optional
- operationType: builtInTransformation
builtInTransformationSettings:
# Filter the data where temperature * "Tag 10" < 100000
filter:
- inputs:
- 'temperature.Value'
- '"Tag 10".Value'
expression: '$1 * $2 < 100000'
map:
# Passthrough all values by default
- inputs:
- '*'
output: '*'
# Convert temperature to Fahrenheit and output it to TemperatureF
- inputs:
- temperature.Value
output: TemperatureF
expression: cToF($1)
# Extract the "Tag 10" value and output it to Humidity
- inputs:
- '"Tag 10".Value'
output: 'Humidity'
- operationType: Destination
destinationSettings:
# Use the default MQTT endpoint as the destination
endpointRef: default
# Send the data to the MQTT topic factory
dataDestination: factory
데이터 흐름 구성의 더 많은 예제를 보려면 Azure REST API - 데이터 흐름 및 빠른 시작 Bicep을 참조하세요.