자습서 1: 신용 위험 예측 - Machine Learning Studio(클래식)
적용 대상:  Machine Learning Studio(클래식)
Machine Learning Studio(클래식)  Azure Machine Learning
Azure Machine Learning
Important
Machine Learning Studio(클래식)에 대한 지원은 2024년 8월 31일에 종료됩니다. 해당 날짜까지 Azure Machine Learning으로 전환하는 것이 좋습니다.
2021년 12월 1일부터 새로운 Machine Learning Studio(클래식) 리소스를 만들 수 없습니다. 2024년 8월 31일까지는 기존 Machine Learning Studio(클래식) 리소스를 계속 사용할 수 있습니다.
- ML Studio(클래식)에서 Azure Machine Learning으로 기계 학습 프로젝트 이동에 대한 정보를 참조하세요.
- Azure Machine Learning에 대해 자세히 알아보세요.
ML Studio(클래식) 설명서는 사용 중지되며 나중에 업데이트되지 않을 수 있습니다.
이 자습서에서는 예측 분석 솔루션을 개발하는 프로세스를 확장적으로 살펴봅니다. Machine Learning Studio(클래식)에서 간단한 모델을 개발합니다. 그런 다음, 모델을 Machine Learning 웹 서비스로 배포합니다. 배포된 이 모델은 새 데이터를 사용하여 예측을 수행할 수 있습니다. 이 자습서는 3부로 구성된 자습서 시리즈 중 제1부입니다.
신용대출 지원 시 애플리케이션에서 제공한 정보를 기반으로 개인의 신용 위험을 예측해야 한다고 가정합니다.
신용 위험 평가는 복잡한 문제이지만 이 자습서에서는 약간 간소화합니다. 이 신용 위험 평가는 Machine Learning Studio(클래식)를 사용하는 예측 분석 솔루션을 만드는 방법의 예로 사용합니다. 이 솔루션에는 aMachine Learning Studio(클래식) 및 Machine Learning 웹 서비스를 사용합니다.
이 세 부분으로 구성된 자습서에서는 공개적으로 사용 가능한 신용 위험 데이터로 시작합니다. 그런 다음 예측 모델을 개발하고 학습합니다. 마지막으로 모델을 웹 서비스로 배포합니다.
자습서의 이 부분에서는 다음을 수행합니다.
- Machine Learning Studio(클래식) 작업 영역 만들기
- 기존 데이터 업로드
- 실험 만들기
그런 다음 이 실험을 사용하여 2 부에서 모델을 학습한 다음 3부에 배포할 수 있습니다.
필수 조건
이 자습서에서는 이전에 Machine Learning Studio(클래식)를 한 번 이상 사용했으며 기계 학습 개념을 이해한다고 가정합니다. 그러나 어느 쪽이든 전문가는 아니라고 가정합니다.
이전에 Machine Learning Studio(클래식)를 사용한 적이 없는 경우 빠른 시작, Machine Learning Studio(클래식)에서 첫 번째 데이터 과학 실험 만들기를 시작할 수 있습니다. 빠른 시작에서는 처음으로 Machine Learning Studio(클래식)를 안내합니다. 모듈을 실험에 끌어서 놓고, 함께 연결하고, 실험을 실행하고, 결과를 살펴보는 방법의 기본 사항을 보여 줍니다.
팁
Azure AI 갤러리에서 이 자습서에서 개발한 실험의 작업 복사본을 찾을 수 있습니다. 자습서로 이동 - 신용 위험을 예측하고 Studio에서 열기를 클릭하여 실험의 복사본을 Machine Learning Studio(클래식) 작업 영역에 다운로드합니다.
Machine Learning Studio(클래식) 작업 영역 만들기
Machine Learning Studio(클래식)를 사용하려면 Machine Learning Studio(클래식) 작업 영역이 있어야 합니다. 이 작업 영역에는 실험을 만들고 관리, 게시하는 데 필요한 도구가 들어 있습니다.
작업 영역을 만들려면 Machine Learning Studio(클래식) 작업 영역 만들기 및 공유를 참조 하세요.
작업 영역을 만든 후 Machine Learning Studio(클래식)(https://studio.azureml.net/Home)를 엽니다. 둘 이상의 작업 영역이 있는 경우 창의 오른쪽 위 모서리에 있는 도구 모음에서 작업 영역을 선택할 수 있습니다.
팁
작업 영역의 소유자인 경우 작업 영역에 다른 사용자를 초대하여 작업 중인 실험을 공유할 수 있습니다. Machine Learning Studio(클래식)의 설정 페이지에서 이 작업을 할 수 있습니다. 각 사용자에 대한 Microsoft 계정 또는 조직 계정만 있으면 됩니다.
설정 페이지에서 사용자를 클릭한 다음 창 아래쪽에서 더 많은 사용자 초대를 클릭합니다.
기존 데이터 업로드
신용 위험에 대한 예측 모델을 개발하려면 모델을 학습한 다음 테스트하는 데 사용할 수 있는 데이터가 필요합니다. 이 자습서에서는 UC Irvine Machine Learning 리포지토리의 "UCI Statlog(독일 신용 데이터) 데이터 세트"를 사용합니다. 여기에서 찾을 수 있습니다.
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
german.data라는 파일을 사용합니다. 이 파일을 로컬 하드 드라이브에 다운로드합니다.
german.data 데이터 세트에는 1,000명의 과거 신청자에 대한 20개의 변수 행이 포함되어 있습니다. 이러한 20개 변수는 각 신용 신청자의 특징을 식별하는 데이터 세트의 기능 집합( 기능 벡터)을 나타냅니다. 각 행의 추가 열은 신청자의 계산된 신용 위험을 나타내며, 700명의 신청자는 낮은 신용 위험으로, 300개는 높은 위험으로 확인됩니다.
UCI 웹 사이트에서는 이 데이터에 대한 기능 벡터의 특성에 대한 설명을 제공합니다. 이 데이터에는 재무 정보, 신용 기록, 고용 상태 및 개인 정보가 포함됩니다. 각 신청자에 대해 신용 위험이 낮거나 높은지 여부를 나타내는 이진 등급이 부여되었습니다.
이 데이터를 사용하여 예측 분석 모델을 학습합니다. 완료되면 모델은 새 개인에 대한 기능 벡터를 수락하고 신용 위험이 낮거나 높은지 여부를 예측할 수 있어야 합니다.
여기에 흥미로운 트위스트입니다.
UCI 웹 사이트의 데이터 세트에 대한 설명은 사용자의 신용 위험을 잘못 분류하는 경우 어떤 비용이 드는지 설명합니다. 모델이 실제로 신용 위험이 낮은 사람에 대해 높은 신용 위험을 예측하는 경우 모델은 오분류를 만들었습니다.
하지만 역방향 오분류(모델이 실제로 신용 위험이 높은 개인에 대해 신용 위험을 낮게 예측하는 경우)는 금융 기관에 대해 5배의 비용이 더 듭니다.
따라서 이 후자의 오분류 비용이 다른 방법으로 잘못 분류되는 것보다 5배 더 높도록 모델을 학습하려고 합니다.
실험에서 모델을 학습할 때 이 작업을 수행하는 간단한 한 가지 방법은 신용 위험이 높은 사람을 나타내는 항목을 복제(5회)하는 것입니다.
그런 다음 모델이 실제로 위험이 높을 때 낮은 신용 위험으로 잘못 분류하는 경우 모델은 중복될 때마다 동일한 오분류를 5번 수행합니다. 이렇게 하면 학습 결과에서 이 오류의 비용이 증가합니다.
데이터 세트 형식 변환
원래 데이터 세트는 공백으로 구분된 형식을 사용합니다. Machine Learning Studio(클래식)는 CSV(쉼표로 구분된 값) 파일에서 더 잘 작동하므로 공백을 쉼표로 바꿔 데이터 세트를 변환합니다.
이 데이터를 변환하는 방법에는 여러 가지가 있습니다. 한 가지 방법은 다음 Windows PowerShell 명령을 사용하는 것입니다.
cat german.data | %{$_ -replace " ",","} | sc german.csv
또 다른 방법은 Unix sed 명령을 사용하는 것입니다.
sed 's/ /,/g' german.data > german.csv
두 경우 모두 실험에서 사용할 수 있는 german.csv 파일에 쉼표로 구분된 버전의 데이터를 만들었습니다.
Machine Learning Studio(클래식)에 데이터 세트 업로드
데이터가 CSV 형식으로 변환되면 Machine Learning Studio(클래식)에 업로드해야 합니다.
Machine Learning Studio(클래식) 홈페이지(https://studio.azureml.net)를 엽니다.
창의 왼쪽 위 모서리에 있는 메뉴를
 클릭하고, Azure Machine Learning을 클릭하고, Studio를 선택하고, 로그인합니다.
클릭하고, Azure Machine Learning을 클릭하고, Studio를 선택하고, 로그인합니다.창 아래쪽에서 +새로 만들기를 클릭합니다.
데이터 세트를 선택합니다.
로컬 파일에서 선택합니다.
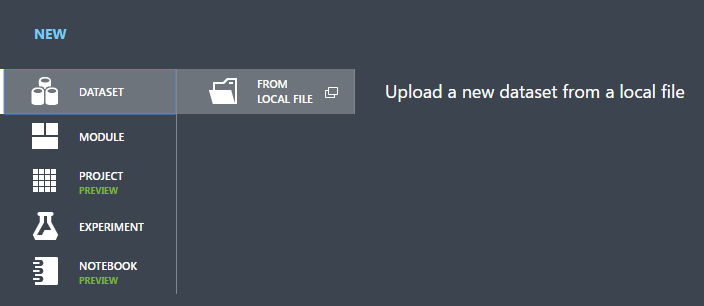
새 데이터 세트 업로드 대화 상자에서 [찾아보기]를 클릭하고 만든 german.csv 파일을 찾습니다.
데이터 세트의 이름을 입력합니다. 이 자습서에서는 "UCI 독일어 신용 카드 데이터"를 호출합니다.
데이터 형식으로 머리글 없는 일반 CSV 파일(.nh.csv)을 선택합니다.
원하는 경우 설명을 추가합니다.
확인 확인 표시를 클릭합니다.
그러면 데이터가 실험에 사용할 수 있는 데이터 세트 모듈에 업로드됩니다.
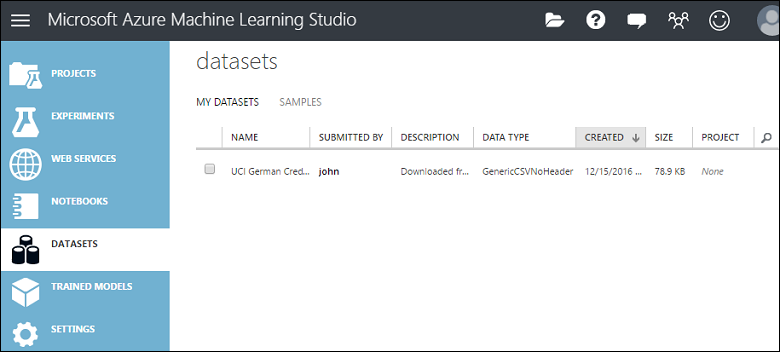
Studio(클래식) 창의 왼쪽에 있는 DATASETS 탭을 클릭하여 Studio(클래식)에 업로드한 데이터 세트를 관리할 수 있습니다.
다른 유형의 데이터를 실험으로 가져오는 방법에 대한 자세한 내용은 Machine Learning Studio(클래식)로 학습 데이터 가져오기를 참조하세요.
실험 만들기
이 자습서의 다음 단계는 업로드한 데이터 세트를 사용하는 Machine Learning Studio(클래식)에서 실험을 만드는 것입니다.
Studio(클래식)의 창 하단에 있는 +새로 만들기를 클릭합니다.
EXPERIMENT를 선택한 다음, "빈 실험"을 선택합니다.
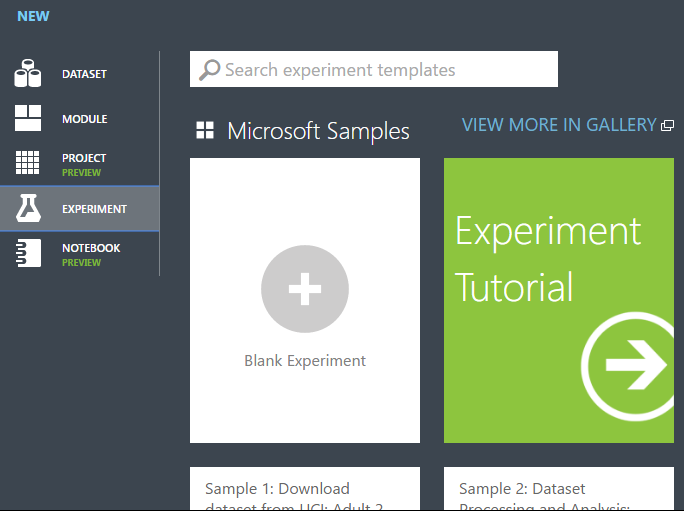
캔버스 위쪽에서 기본 실험 이름을 선택하고 이를 의미 있는 이름으로 바꿉니다.

팁
속성 창에 실험에 대한 요약 및 설명을 입력하는 것이 좋습니다. 이러한 속성을 사용하면 나중에 보는 모든 사용자가 목표와 방법론을 이해할 수 있도록 실험을 문서화할 수 있습니다.

실험 캔버스의 왼쪽에 있는 모듈 팔레트에서 저장된 데이터 세트를 확장합니다.
내 데이터 세트 아래에서 만든 데이터 세트를 찾아 캔버스로 끕니다. 색상표 위의 검색 상자에 이름을 입력하여 데이터 세트를 찾을 수도 있습니다.
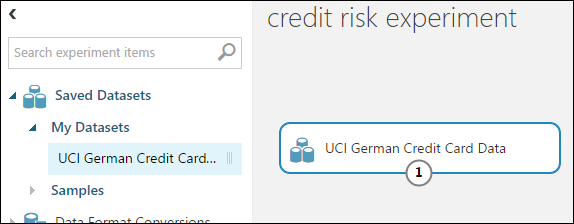
데이터 준비
데이터 세트(아래 작은 원)의 출력 포트를 클릭하고 시각화를 선택하여 데이터의 처음 100개 행 및 전체 데이터 세트에 대한 일부 통계 정보를 볼 수 있습니다.
데이터 파일에는 열 제목이 없으므로 Studio(클래식)에서 일반적인 제목(Col1, Col2 등)을 제공했습니다. 적합한 제목은 모델 작성 시 필수 사항은 아니지만 제목이 있으면 실험에서 데이터를 더 쉽게 사용할 수 있습니다. 또한 웹 서비스에 이 모델을 게시할 때 제목은 서비스 사용자에게 열을 식별하는 데 도움이 됩니다.
열 제목은 메타데이터 편집 모듈을 사용하여 추가할 수 있습니다.
메타데이터 편집 모듈을 사용하여 데이터 세트와 연결된 메타데이터를 변경합니다. 이 경우 열 머리글에 더 친숙한 이름을 제공하는 데 사용합니다.
메타데이터 편집을 사용하려면 먼저 수정할 열을 지정합니다(이 경우 모두). 다음으로 해당 열에서 수행할 작업을 지정합니다(이 경우 열 머리글 변경).
모듈 팔레트의 검색 상자에 "메타데이터"를 입력합니다. 메타데이터 편집이 모듈 목록에 나타납니다.
메타데이터 편집 모듈을 클릭하여 캔버스로 끌어서 이전에 추가한 데이터 세트 아래에 놓습니다.
데이터 세트를 메타데이터 편집에 연결합니다. 데이터 세트의 출력 포트(데이터 세트 맨 아래의 작은 원)를 클릭하여 메타데이터 편집의 입력 포트(모듈 맨 위의 작은 원)로 끌어 놓은 다음 마우스 단추를 놓습니다. 캔버스에서 이동해도 데이터 세트와 모듈은 연결된 상태로 유지됩니다.
이제 실험은 다음과 같이 표시됩니다.
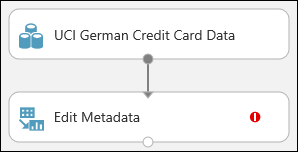
빨간색 느낌표는 이 모듈에 대한 속성이 아직 설정되지 않았음을 나타냅니다. 다음에 수행합니다.
팁
모듈을 두 번 클릭하고 텍스트를 입력하여 모듈에 주석을 추가할 수 있습니다. 이렇게 하면 모듈이 실험에서 수행하는 작업을 한눈에 볼 수 있습니다. 이 경우 메타데이터 편집 모듈을 두 번 클릭하고 "열 머리글 추가" 주석을 입력합니다. 캔버스의 다른 곳을 클릭하여 텍스트 상자를 닫습니다. 주석을 표시하려면 모듈의 아래쪽 화살표를 클릭합니다.
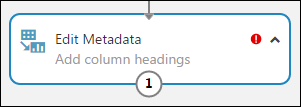
메타데이터 편집을 선택하고 캔버스 오른쪽의 속성 창에서 열 선택기 시작을 클릭합니다.
열 선택 대화 상자의 사용 가능한 열에서 모든 행을 선택하고 >를 클릭하여 선택한 열로 이동시킵니다. 대화 상자는 다음과 같습니다.
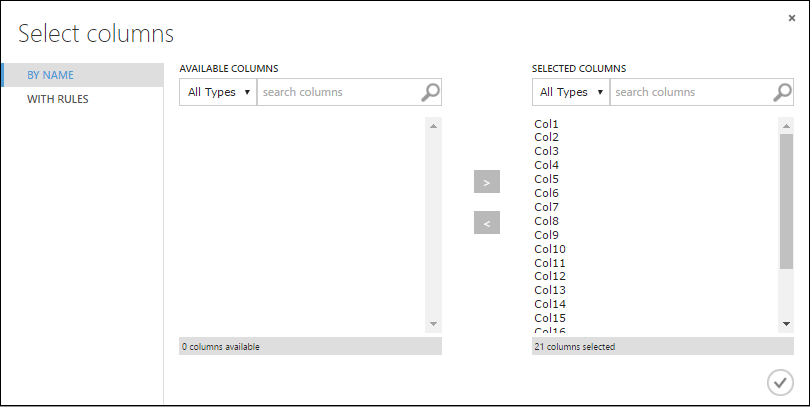
확인 확인 표시를 클릭합니다.
속성 창으로 돌아가서 새 열 이름 매개 변수를 찾습니다. 이 필드에 데이터 세트의 21개 열에 대한 이름 목록을 쉼표와 열 순서로 구분하여 입력합니다. UCI 웹 사이트의 데이터 세트 설명서에서 열 이름을 가져오거나 편의상 다음 목록을 복사하여 붙여넣을 수 있습니다.
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit risk속성 창은 다음과 같습니다.
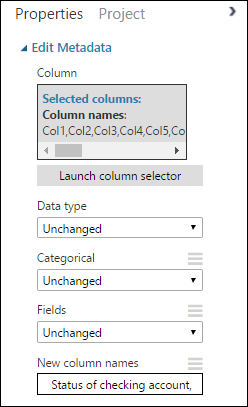
팁
열 머리글을 확인하려면 실험을 실행합니다(실험 캔버스 아래의 실행을 클릭). 실행이 완료되면(메타데이터 편집에 녹색 확인 표시가 표시됨) 메타데이터 편집 모듈의 출력 포트를 클릭하고 시각화를 선택합니다. 같은 방법으로 모듈의 출력을 표시하여 실험을 통해 데이터 진행률을 확인할 수 있습니다.
학습 및 테스트 데이터 세트 만들기
모델을 학습하려면 일부 데이터가 필요하고 일부는 테스트해야 합니다. 따라서 실험의 다음 단계에서는 데이터 세트를 두 개의 개별 데이터 세트(모델 학습용 및 테스트용)로 분할합니다.
이렇게 하려면 데이터 분할 모듈을 사용합니다.
기본적으로 분할 비율은 0.5이고 임의 분할 매개 변수는 설정됩니다. 이는 데이터의 임의 절반이 데이터 분할 모듈의 한 포트를 통해 출력되고 나머지 절반은 다른 포트를 통해 출력됨을 의미합니다. 이러한 매개 변수와 Random seed 매개 변수를 조정하여 학습 데이터와 테스트 데이터 간의 분할을 변경할 수 있습니다. 이 예제에서는 그대로 둡니다.
팁
첫 번째 출력 데이터 세트의 행 분수 속성은 왼쪽 출력 포트를 통해 출력되는 데이터의 양을 결정합니다. 예를 들어 비율을 0.7로 설정하면 데이터의 70%가 왼쪽 포트를 통해 출력되고 30%는 오른쪽 포트를 통해 출력됩니다.
데이터 분할 모듈을 두 번 클릭하고 주석 "데이터 분할 50% 학습/테스트"를 입력합니다.
원하는 대로 데이터 분할 모듈의 출력을 사용할 수 있지만 왼쪽 출력을 학습 데이터로 사용하고 오른쪽 출력을 테스트 데이터로 사용하도록 선택해 보겠습니다.
이전 단계에서 언급했듯이 높은 신용 위험을 낮은 것으로 잘못 분류하는 비용은 낮은 신용 위험을 높은 것으로 잘못 분류하는 비용보다 5배 높습니다. 이를 고려하여 이 비용 함수를 반영하는 새 데이터 세트를 생성합니다. 새 데이터 세트에서는 위험 수준이 높은 각 예제가 5번 복제되지만, 위험 수준이 낮은 각 예제는 복제되지 않습니다.
R 코드를 사용하여 이 복제를 수행할 수 있습니다.
R 스크립트 실행 모듈을 찾아 실험 캔버스로 끌어다 놓습니다.
데이터 분할 모듈의 왼쪽 출력 포트를 R 스크립트 실행 모듈의 첫 번째 입력 포트("Dataset1")에 연결합니다.
R 스크립트 실행 모듈을 두 번 클릭하고 "비용 조정 설정"이라는 주석을 입력합니다.
속성 창에서 R 스크립트 매개 변수의 기본 텍스트를 삭제하고 다음 스크립트를 입력합니다.
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")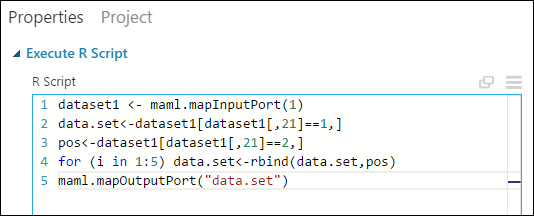
학습 및 테스트 데이터가 동일한 비용 조정을 갖도록 분할 데이터 모듈의 각 출력에 대해 동일한 복제 작업을 수행해야 합니다. 이 작업을 수행하는 가장 쉬운 방법은 방금 만든 R 스크립트 실행 모듈을 복제하고 데이터 분할 모듈의 다른 출력 포트에 연결하는 것입니다.
R 스크립트 실행 모듈을 마우스 오른쪽 단추로 클릭하고 복사를 선택합니다.
실험 캔버스를 마우스 오른쪽 단추로 클릭하고 붙여넣기를 선택합니다.
새 모듈을 해당 위치로 끌어 놓은 다음 데이터 분할 모듈의 오른쪽 출력 포트를 이 새로운 R 스크립트 실행 모듈의 첫 번째 입력 포트에 연결합니다.
캔버스 아래쪽에서 실행을 클릭합니다.
팁
R 스크립트 실행 모듈의 복사본에는 원래 모듈과 같은 스크립트가 포함됩니다. 캔버스에서 모듈을 복사하고 붙여넣으면 복사본에서 원본의 모든 속성이 유지됩니다.
이제 실험은 다음과 같이 표시됩니다.
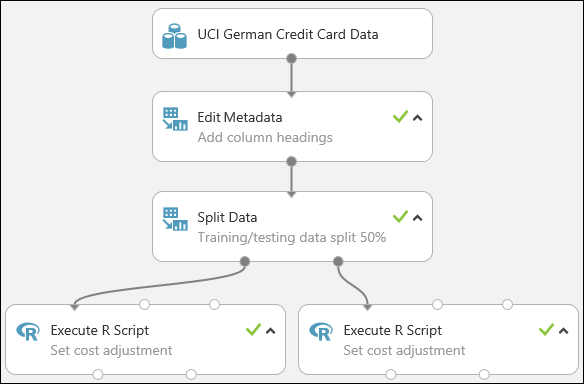
실험에서 R 스크립트를 사용하는 방법에 대한 자세한 내용은 R을 사용하여 실험 확장을 참조하세요.
리소스 정리
이 문서를 사용하여 만든 리소스가 더 이상 필요하지 않은 경우 요금이 발생하지 않도록 삭제합니다. 문서에서 제품 내 사용자 데이터 내보내기 및 삭제 방법을 알아봅니다.
다음 단계
이 자습서에서는 다음 단계를 완료했습니다.
- Machine Learning Studio(클래식) 작업 영역 만들기
- 작업 영역에 기존 데이터 업로드
- 실험 만들기
이제 이 데이터에 대한 모델을 학습하고 평가할 준비가 되었습니다.